Keras のステートレスLSTMとステートフルLSTMの勉強です。
ネット上の情報をかき集めて自分なりに実装しているので正確ではないところがある点はご了承ください。
追記:ステートフルLSTMと hidden state に関して記事を書きました。
Keras のステートフルLSTMと hidden state の関係を調査してみた
目次
- KerasのステートレスLSTMとステートフルLSTMについて
- 実験に使うモデルセットの説明(アルファベット予測)
- 実験1:「1 文字 => 1 文字」マッピング
- 実験2:「3 文字特徴ウィンドウ => 1 文字」マッピング
- 実験3:「3 文字タイムステップ・ウィンドウ => 1 文字」マッピング
- 実験4:バッチサイズ
- 実験5:hidden state の保存と設定
コード全体
本記事で作成したコードは以下です。
※1ファイル完結です。
※GoogleColaboratoryは実行結果付き
LSTM
RNN や LSTM の詳細は省略し、必要なところだけを解説します。詳細は参考資料を参照してください。
LSTMの構造は下記となります。
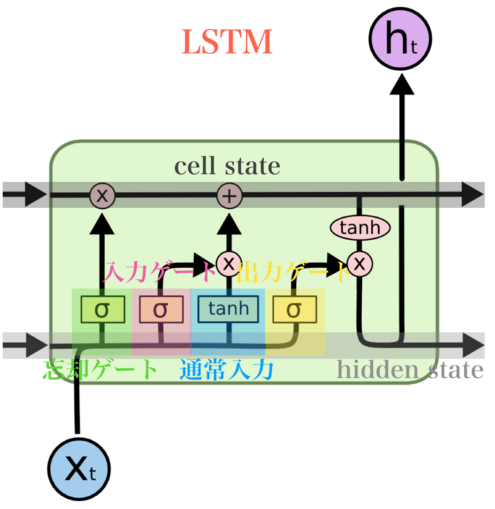

LSTMでは情報をどの程度通すかを3つのゲートで制御しています。
忘却ゲート(Forget Gate)では更新前の cell state をどの程度残すかを決めるゲート、
入力ゲート(Input Gate)は通常入力をどの程度 cell state に加えるかを決めるゲート、
出力ゲート(Output Gate)は cell state をどの程度 hidden state に加えるかを決めるゲートです。
また、ここで cell state は長期記憶を司どっており、hidden state は短期記憶を司どっています。
参考
・LSTMネットワークの概要
・わかるLSTM ~ 最近の動向と共に
・今更聞けないLSTMの基本
・論文解説 Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation (GNMT)
・Keras LSTM tutorial – How to easily build a powerful deep learning language model
・Exploring LSTMs
ステートレスLSTMとステートフルLSTM
Keras にはステートレスLSTMとステートフルLSTMがあり、デフォルトではステートレスLSTMとなります。
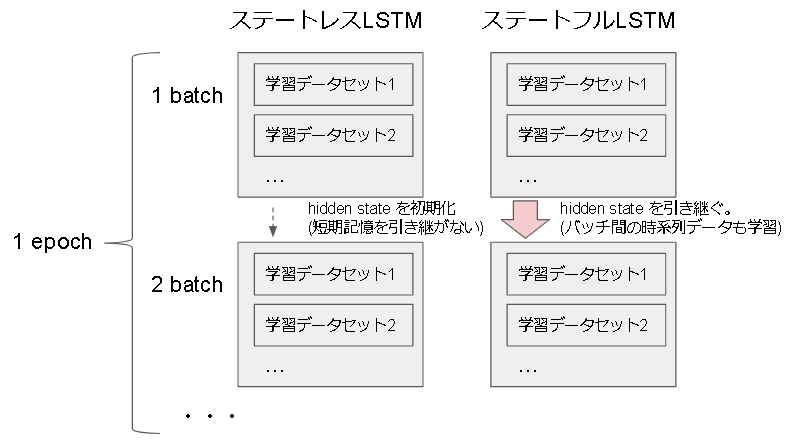
ここでいうステートとは、hidden state のことです。
ステートレスではバッチ処理毎に短期記憶の hidden state (正確には working memory)を 0 で初期化します。
これにより各batchが独立することになります。
ステートフルではこの 0 初期化をしない処理となり、バッチ間で hidden state を引き継ぎます。
これによりバッチ経由でも時系列データを学習することになります。
尚、ステートフル状態の hidden state は predict, fit, train_on_batch, predict_classes 等、学習関数だけではなく予測関数でも学習(更新)されるので注意が必要です。
Keras LSTM の入出力形式
入力:(batch_size, timesteps, input_dim)
出力:(batch_size, units)
※return_sequencesがTrueの場合は、出力が (batch_size, timesteps, units)となりLSTM層を連結する事が出来ます。
・入力データイメージ
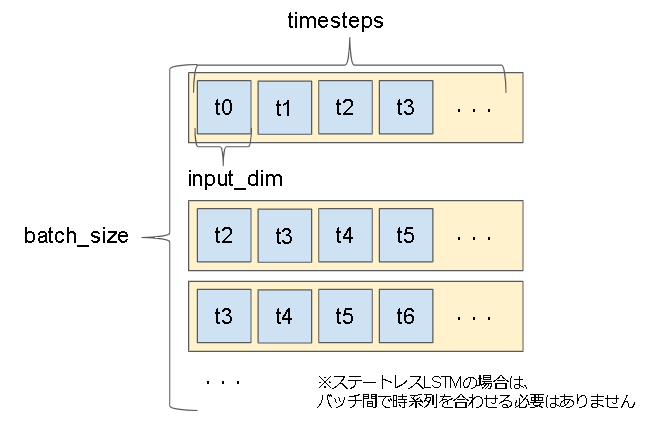
参考:https://keras.io/layers/recurrent/#lstm
ステートフル LSTM を理解するためのモデルセット
下記チュートリアルを参考に進めていきます。
Keras : Ex-Tutorials : ステートフル LSTM リカレント・ニューラルネットの理解
アルファベットの学習
単純なシークエンス予測問題で、アルファベットがきたら次のアルファベットを当てる問題です。
A -> B
B -> C
のような感じ。
チュートリアルではこのアルファベットの学習に対して条件を変更してどう学習が変化するかを見ています。
ので、同じように条件を変えた結果どうなるかを見ていきたいと思います。
条件定義
今回変更する条件は以下です。
- seq_length : 入力データの長さ。例えば 3 なら ABC や EFG 等。
- batch_size : 学習時のバッチサイズ
- model_type : 3種類比較します。Dense と StatelessLSTM と StatefulLSTMです。
- shape : 入力形式です。例えば (1,3) なら [[A,B,C],[B,C,D],...] など
- epochs : 学習回数です。
- shuffle : 学習時に シャッフルするかどうか。StatefulLSTMで重要となります。
- test_every_reset : テスト時に毎回 hidden state をリセットするか(ステートフルLSTMのみ影響)
データセットを定義
まずは生データを定義。
# 生データセットを定義します
alphabet = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
alphabet_int = [ i for i in range(len(alphabet))]
# 文字の数字 (0-25) へのマッピングとその逆を作成します。
char_to_int = dict((c, i) for i, c in enumerate(alphabet))
int_to_char = dict((i, c) for i, c in enumerate(alphabet))
次に学習用の時系列データを作成します。
作成には Keras に用意されている TimeseriesGenerator を使います。
from keras.preprocessing.sequence import TimeseriesGenerator
data = TimeseriesGenerator(alphabet_int, alphabet_int, length=seq_length)[0]
x_data = data[0]
y_data = data[1]
TimeseriesGenerator の第1引数がデータ、第2引数が結果で同じサイズの配列を指定します。
length がデータ数になり、時系列でデータを分割してくれます。
以下は seq_length=3 の場合の出力結果です。
>>> print(x_data)
[[ 0 1 2]
[ 1 2 3]
[ 2 3 4]
(省略)
[20 21 22]
[21 22 23]
[22 23 24]]
>>> print(y_data)
[ 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25]
x_data を正規化します。
x_data = x_data / float(len(alphabet)) # 0~1の範囲に
x_data の shape の形を変えます。
x_data = np.reshape(x_data, (len(x_data),) + shape)
shape=(3,1) なら (23, 3, 1) になります。
最後に y_data を one hot 表現にしてデータセットは完成です。
from keras.utils import np_utils
y_data = np_utils.to_categorical(y_data)
検証結果で必要になるので、表示用の入力データからアルファベットを返す関数 int_to_char_seq を作成しておきます。
※seq_lengthとalphabetはグローバル変数に依存
def int_to_char_seq(seq):
seq = seq.reshape(seq_length)
s = ""
for c in seq:
c = int(c * float(len(alphabet)))
s += int_to_char[c]
return s
モデルの作成
基本はチュートリアル通りですが、比較したいモデルがあるのでそこだけ作っています。
model = Sequential()
if model_type == "dense":
model.add(Flatten(input_shape=shape))
model.add(Dense(16))
elif model_type == "lstm":
model.add(LSTM(16, input_shape=shape))
elif model_type == "lstm_ful":
model.add(LSTM(16, batch_input_shape=(batch_size,) + shape, stateful=True))
else:
raise ValueError("model type error.")
model.add(Dense(y_data.shape[1], activation="softmax"))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
Units数が 16 なのは、意図的に学習難易度を上げるためです。
(どのモデルも学習回数を大きくすれば案外学習できてしまい、比較できなくなるため)
Dense層モデルですが、LSTMみたいに時系列の構造を持つ必要がないので、
一度 Flatten して Dense に渡しています。
LSTM層モデルはチュートリアルと同じです。
StatefulLSTM層のモデル作成について
入力形式にバッチサイズまで指定する必要があります。
バッチサイズが 1 の場合は問題ないのですが、そうじゃない場合予測する時にもバッチサイズ分指定する必要があり、不都合が生じます。
学習
StatefulLSTMの場合は学習方法が変わります。
また、一応時間も計測。
import time
t0 = time.time()
if model_type == "lstm_ful":
for _ in range(epochs):
model.reset_states()
model.fit(np.asarray(x_data), np.asarray(y_data), epochs=1, batch_size=batch_size, shuffle=shuffle)
else:
model.fit(np.asarray(x_data), np.asarray(y_data), epochs=epochs, batch_size=batch_size, shuffle=shuffle)
print("fit time : ", time.time()-t0)
StatefulLSTM の学習方法は fit の epochs を 1 、shuffle を False にして fit 全体をepochs の for ループで回す形となります。
また、fit の前に(公式では後だけど)model.reset_states()を呼び出して hidden state を 0 にする必要があります。(動作については後述)
結果の測定方法
3種類行います。
1、 順列予測
順番にデータを入力し、結果があっているか見ます。
seq_length 3 の場合は以下です。
ABC -> Dかどうか
BCD -> Eかどうか
CDE -> Fかどうか
…
t0 = time.time()
if model_type == "lstm_ful": # stateful はリセット
model.reset_states()
scores = model.evaluate(np.asarray(x_data), np.asarray(y_data), batch_size=batch_size, verbose=0)
print("Model Accuracy: %.2f%%" % (scores[1]*100))
2、 逆順予測
逆順にデータを入力し、結果があっているか見ます。
seq_length 3 の場合は以下です。
VWY -> Zかどうか
UVW -> Yかどうか
TUV -> Wかどうか
…
これはある意味ランダム入力に近い結果になります。
if model_type == "lstm_ful": # stateful はリセット
model.reset_states()
# データ分ループ
pred1_ok = 0
for i in reversed(range(len(x_data))):
x = x_data[i] # 入力データ
y = y_data[i] # 出力データ
# stateful の batch_size 対処
t = np.asarray([x for _ in range(batch_size)])
# モデルを予測
if test_every_reset:
model.reset_states()
pre = model.predict(t)[0]
# 結果と同じか
if np.argmax(pre) == np.argmax(y):
pred1_ok += 1
# 一応出力
print(int_to_char_seq(x), "->", int_to_char[np.argmax(pre)])
print("Test1 Accuracy: %.2f%%" % (pred1_ok/len(x_data)*100))
入力データですが、batch_size 分同じデータを増やしています。
これが stateful のモデルで batch_size を指定しないといけない弊害です。
解決策を探したのですが見つけられなかったのでとりあえず同じデータで埋めてみることにしました。
一応 Stateless LSTM で1つのデータと同じデータをbatch_size増やした場合の結果を見比べて同じだったので問題はないと思います。
3、ループ予測
入力に対し、予測の出力結果を次の入力にするテストです。
seq_length 3 の場合は以下です。
ABC -> Dかどうか(Dと予測)
BCD -> Eかどうか(Fと予測)
CDF -> Fかどうか
…
if model_type == "lstm_ful": # stateful はリセット
model.reset_states()
# データ分ループ
pred2_ok = 0
x = x_data[0] # 最初の入力
for i in range(len(x_data)):
y = y_data[i] # 答え
# stateful の batch_size 対処
t = np.asarray([x for _ in range(batch_size)])
# モデルを予測
if test_every_reset:
model.reset_states()
pre = model.predict(t)[0]
# 表示
print(int_to_char_seq(x), "->", int_to_char[np.argmax(pre)])
# 結果と同じか
if np.argmax(pre) == np.argmax(y):
pred2_ok += 1
# x のデータを更新
x = x.reshape(seq_length) # まずは1次元に戻す
x = np.delete(x, 0) # 最初を削除
x = np.append(x, np.argmax(pre) / float(len(alphabet))) # 最後に追加
x = x.reshape(shape) # shape に戻す
print("Test2 Accuracy: %.2f%%" % (pred2_ok/len(x_data)*100))
print("test time : ", time.time()-t0)
テストにかかった時間も出力しています。
実験1:「1 文字 => 1 文字」マッピング
チュートリアルでは結果を要約すると以下のような事を言っています。
- ステートレスLSTMでは時系列に関する情報がないので標準的な多層パーセプトロンと変わらない(LSTMとしては誤用)
- ステートフルLSTMでは時系列の情報が保持されるので学習できる。(ただし、時系列順のみ)
実際にやってみます。
seq_length = 1
batch_size = 1
shape = (1,1)
epochs = 500
test_every_reset = False
| model_type | shuffle | 順列予測 | 逆順予測 | ループ予測 | 学習時間 | 予測時間 |
|---|---|---|---|---|---|---|
| dense | True | 68% | 68% | 4% | 18.0s | 0.19s |
| lstm | True | 72% | 72% | 4% | 28.3s | 0.31s |
| lstm_ful | False | 68% | 4% | 68% | 25.5s | 0.38s |
| lstm_ful | True | 12% | 8% | 4% | 49.0s | 0.34s |
dense と lstm はチュートリアル通り同じ結果ですね。
逆順も予測できているのは A->B といった対応のみを学習しており、時系列情報が学習できていないからです。
逆に lstm_ful は時系列情報を学習しているので逆順予測はできませんが、ループ予測ができています。
lstm_ful で shuffle を True にした場合は時系列情報がなくなるので学習できなくなっています。
実験2:「3 文字特徴ウィンドウ => 1 文字」マッピング
多層パーセプトロンで時系列情報を付加する典型的な手法です。
要するに情報自体に時系列情報を埋め込む方法ですね。
["A", "B", "C"] -> "D"
["B", "C", "D"] -> "E"
これもLSTMとしては誤用となります。
実際にやってみます。
seq_length = 3 # 変更
batch_size = 1
shape = (1,3) # 変更
epochs = 500
test_every_reset = False
| model_type | shuffle | 順列予測 | 逆順予測 | ループ予測 | 学習時間 | 予測時間 |
|---|---|---|---|---|---|---|
| dense | True | 78% | 78% | 74% | 17.5s | 0.15s |
| lstm | True | 83% | 83% | 83% | 26.9s | 0.35s |
| lstm_ful | False | 78% | 4% | 78% | 24.2s | 0.34s |
dense と lstm がいい結果を出していますがこれは時系列情報は覚えておらず、全てのパターンを学習しているだけとなります。
(それでも精度がでるのはデータセットが単純だからですね)
lstm_ful も実験1と変わらずです。
実験3:「3 文字タイムステップ・ウィンドウ => 1 文字」マッピング
これがKeras LSTMで想定された使い方です。
データに時系列情報を持たせるのではなく、時系列のデータを渡します。
[["A"], ["B"], ["C"]] -> "D"
[["B"], ["C"], ["D"]] -> "E"
実際にやってみます。
seq_length = 3
batch_size = 1
shape = (3,1) # 変更
epochs = 500
test_every_reset = False
| model_type | shuffle | 順列予測 | 逆順予測 | ループ予測 | 学習時間 | 予測時間 |
|---|---|---|---|---|---|---|
| dense | True | 78% | 78% | 30.4% | 17.5s | 0.13s |
| lstm | True | 97% | 97% | 97% | 37.3s | 0.3s |
| lstm_ful | False | 96% | 0% | 96% | 30.8s | 0.34s |
lstm が時系列として学習できていそうですね。
lstm_ful はデータ間の時系列も学習しているため逆順での学習はできていません。
実験4:バッチサイズ
ここからはチュートリアルにはありません。
バッチサイズの影響を見ていきます。
Keras ではバッチサイズ分訓練し、その結果でモデルを1回更新します。
"sample","batch","epoch" の意味は?
まずはバッチサイズを変えるとどう変化するかです。
seq_length = 3
shape = (3,1)
epochs = 1000 # 変更
batch_size = 23 # 変更
| model_type | shuffle | test_every_reset | 順列予測 | 逆順予測 | ループ予測 | 学習時間 | 予測時間 |
|---|---|---|---|---|---|---|---|
| lstm | True | - | 96% | 96% | 96% | 5.9s | 0.41s |
| lstm_ful | True | True | 96% | 96% | 96% | 6.6s | 0.38s |
| lstm_ful | False | False | 96% | 4% | 4% | 6.3s | 0.33s |
バッチサイズが入力数と同じ場合、ステートフルLSTMとステートレスLSTMがほぼ同じ挙動となります。
シャッフルをTrueにしても学習できている点、テスト時に reset_state をしないと正確に予測できない点より合っていると思います。
(バッチサイズ1以外の情報は全くなかったので手探りです)
実験5:hidden state の保存と設定
資料を探しても全然出てこなかったので試行錯誤した結果です。
実験としてアルファベット予測の結果を途中から学習してみます。
コードは続けて書いています。
from keras import backend as K
# --------------------------------------
# 同じ model を作成
model2 = Sequential()
model2.add(LSTM(16, batch_input_shape=(batch_size,) + shape, stateful=True, name="lstm"))
model2.add(Dense(y_data.shape[1], activation="softmax"))
model2.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# -------------------------------
# train
t0 = time.time()
for _ in range(epochs):
# まず K まで model の短期記憶を進める。
model.reset_states()
for i in range(len(x_data)):
if i >= 11:
break
x = x_data[i]
model.predict(np.asarray([x]))[0]
# hidden state を取得
lstm = model.get_layer("lstm")
state = [K.get_value(lstm.states[0]), K.get_value(lstm.states[1])]
# model2 の lstm の初期状態を state にする
model2.get_layer("lstm").reset_states(state)
# 学習
model2.fit(np.asarray(x_data), np.asarray(y_data), epochs=1, batch_size=1, shuffle=False, verbose=0)
print("fit time : ", time.time()-t0)
# -------------------------------
# test1 普通に始めた場合
pred1_ok = 0
model2.reset_states()
for i in range(len(x_data)):
x = x_data[i]
y = y_data[i]
pre = model2.predict(np.asarray([x]))[0]
if np.argmax(pre) == np.argmax(y):
pred1_ok += 1
print(int_to_char_seq(x), "->", int_to_char[np.argmax(pre)])
print("Test1 Accuracy: %.2f%%" % (pred1_ok/len(x_data)*100))
# -------------------------------
# test2 K から始めた場合
pred2_ok = 0
model2.reset_states()
for i in range(11, len(x_data)):
x = x_data[i]
y = y_data[i]
pre = model2.predict(np.asarray([x]))[0]
if np.argmax(pre) == np.argmax(y):
pred2_ok += 1
print(int_to_char_seq(x), "->", int_to_char[np.argmax(pre)])
print("Test2 Accuracy: %.2f%%" % (pred2_ok/len(x_data)*100))
# -------------------------------
# test3 学習と同じ条件
pred3_ok = 0
# まず K まで model の短期記憶を進める。
model.reset_states()
for i in range(len(x_data)):
if i >= 11:
break
x = x_data[i]
model.predict(np.asarray([x]))[0]
# hidden state を取得
lstm = model.get_layer("lstm")
state = [K.get_value(lstm.states[0]), K.get_value(lstm.states[1])]
# model2 の lstm の初期状態を state にする
model2.get_layer("lstm").reset_states(state)
for i in range(len(x_data)):
x = x_data[i]
y = y_data[i]
pre = model2.predict(np.asarray([x]))[0]
if np.argmax(pre) == np.argmax(y):
pred3_ok += 1
print(int_to_char_seq(x), "->", int_to_char[np.argmax(pre)])
print("Test3 Accuracy: %.2f%%" % (pred3_ok/len(x_data)*100))
出力結果
ABC -> Z
BCD -> P
CDE -> V
DEF -> K
EFG -> L
FGH -> L
GHI -> M
HIJ -> O
IJK -> U
JKL -> Z
KLM -> Z
LMN -> Z
MNO -> Z
NOO -> Z
OOQ -> Z
OQR -> Z
QRS -> Z
RST -> Z
STU -> Z
TUV -> Z
UVW -> Z
VWX -> Z
WXY -> Z
Test1 Accuracy: 4.35%
LMN -> Z
MNO -> P
NOO -> Q
OOQ -> Z
OQR -> Z
QRS -> Z
RST -> Y
STU -> Y
TUV -> Z
UVW -> Z
VWX -> Z
WXY -> Z
Test2 Accuracy: 13.04%
ABC -> D
BCD -> E
CDE -> F
DEF -> G
EFG -> H
FGH -> I
GHI -> J
HIJ -> K
IJK -> L
JKL -> M
KLM -> N
LMN -> O
MNO -> P
NOO -> Q
OOQ -> R
OQR -> S
QRS -> T
RST -> U
STU -> V
TUV -> W
UVW -> X
VWX -> Y
WXY -> Z
Test3 Accuracy: 100.00%
あとがき
LSTM の使い方のベストプラクティスみたいなものがあれば早かったのですが見つかりませんでした。
仕方がなくチュートリアルをやりつつ勉強してみた感じです。
ステートフルLSTMの情報や特に Keras の hidden state に関する情報はほとんどなかったので誰かの助けになったら幸いです。