KerasのステートフルLSTM(RNN)の hidden state についてもう一度調査してみました。
ネット上の情報をかき集めて自分なりに実装しているので正確ではない点はご了承ください。
また、ステートレスLSTMとステートフルLSTMの違いに関しては以前書いた記事も参考にしてください。
・KerasのステートレスLSTMとステートフルLSTMの違いについて
概要
そもそもの目的はR2D2で使われている Burn-in の実装で、それに向けて試行錯誤した軌跡みたいなものです。
やりたい事は hidden_states の保存と復元で、その為に model.predict を実行した際の hidden_states の変化を確認してみました。
各種情報
データセット
データセットは重要ではないので以下のデータセットをそのまま使います。
参考:Keras : Ex-Tutorials : ステートフル LSTM リカレント・ニューラルネットの理解
以下のようなイメージです。
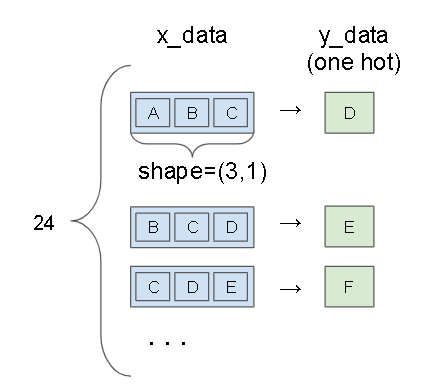
パラメータ
使用するデータ数 : 24
batch_size : 6
Model
今回使用する model は以下です。
c = input_ = Input(batch_shape=(batch_size,) + shape) #(batch_size,data)
c = LSTM(lstm_units, stateful=True, name="lstm")(c)
c = Dense(y_data.shape[1], activation="softmax")(c)
model = Model(input_, c)
LSTMレイヤーを後で取得しやすいように "lstm" と名前を付けています。
また、ステートフルLSTMを使う場合は以下の制約があります。
- batch_sizeは固定です。
なので Input を使う場合は shape 引数は使えず、batch_shape 引数を使う必要があります。
(Sequentialモデルの場合は、input_shape 引数ではなく、batch_input_shape 引数を使います) - LSTM の stateful を True にします。
hidden_states の取得と設定
hidden_states の取得は keras では多分実装されていないので直接取得しています。
from keras import backend as K
def get_hidden_states(model):
lstm = model.get_layer("lstm")
hidden_states = [K.get_value(lstm.states[0]), K.get_value(lstm.states[1])]
return hidden_states
def set_hidden_states(model, hidden_states):
model.get_layer("lstm").reset_states(hidden_states)
hidden_states は以下のようなデータ構造です。
shapeとしては (2, batch_size, lstm_unit数) となります。
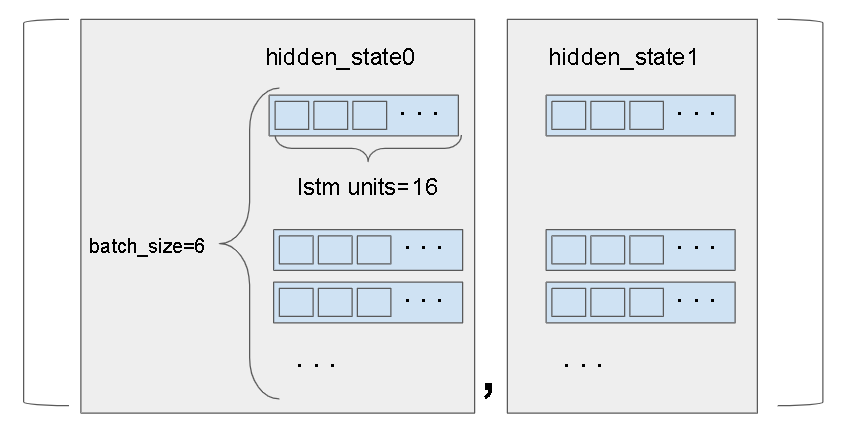
学習
学習自体に意味はないので適当です。
model.fit(x_data, y_data, epochs=2, batch_size=batch_size, verbose=0)
テスト用のデータ
ステートフルの場合、バッチサイズを変える事が出来ないのでテスト用データもバッチサイズ分必要になります。
同じデータ(x_data[0])をバッチサイズ分増やします。
# create test data
x_test = np.asarray([x_data[0] for _ in range(batch_size)])
調査結果の出力
predict のイメージは以下です。
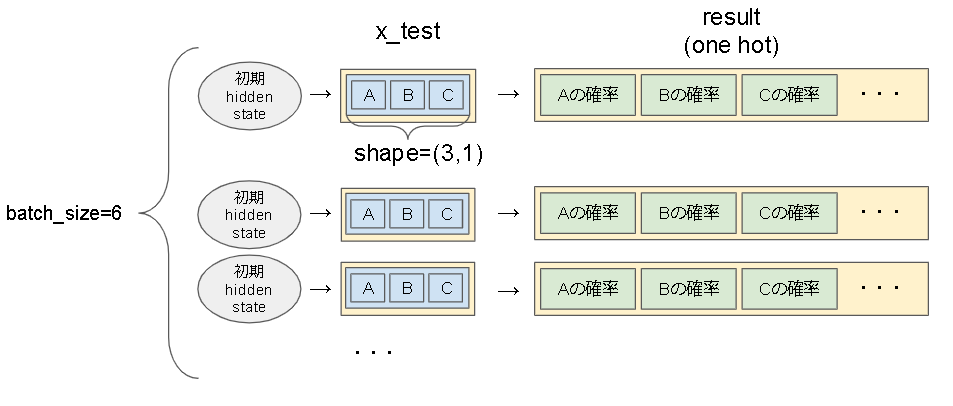
知りたいのは hidden_state を変えたときにバッチ間で結果が変わっているかどうかです。
なので出力は、各バッチに対して 0 番目の値(Aの確率)だけを出力しています。
def print_result(result):
for i, r in enumerate(result):
print("{}: {}".format(i, r[0]))
調査
Case1: hidden_statesをリセットしないで出力
リセットしないので学習で使われた hidden_states がそのまま使われます。
各hidden_stateはばらばらなので、予測としてはバッチ内のすべての結果が変わる想定です。
test1_hs はこの時点での hidden_states を保存しています。(この後使うので)
print("--- (1) no reset")
test1_hs = get_hidden_states(model)
print_result( model.predict(x_test, batch_size=batch_size) )
--- (1) no reset
0: 0.03929901123046875
1: 0.03843347728252411
2: 0.03823704645037651
3: 0.03934086859226227
4: 0.03969535231590271
5: 0.03939886391162872
予想通りバラバラですね。
Case2: hidden_statesをリセットしないで出力2回目
Case1 と同じですが、もう一度リセットせずに実行する場合です。
Case1 とは違う値になるはずです。
print("--- (2) no reset 2")
print_result( model.predict(x_test, batch_size=batch_size) )
--- (2) no reset 2
0: 0.038682691752910614
1: 0.03798734396696091
2: 0.03784516826272011
3: 0.03870406746864319
4: 0.038950104266405106
5: 0.03872624412178993
Case3: Case1のhidden_statesを復元
Case1 で保存した hidden_states を復元します。
Case1 と同じ値になるはずです。
print("--- (3) restore hidden_state(1)")
set_hidden_states(model, test1_hs)
print_result( model.predict(x_test, batch_size=batch_size) )
--- (3) restore hidden_state(1)
0: 0.03929901123046875
1: 0.03843347728252411
2: 0.03823704645037651
3: 0.03934086859226227
4: 0.03969535231590271
5: 0.03939886391162872
Case4: hidden_statesをリセット
hidden_statesを0で初期化します。
全部同じ値になるはずです。
print("--- (4) reset_states")
model.reset_states()
print_result( model.predict(x_test, batch_size=batch_size) )
--- (4) reset_states
0: 0.03676648437976837
1: 0.03676648437976837
2: 0.03676648437976837
3: 0.03676648437976837
4: 0.03676648437976837
5: 0.03676648437976837
Case5: Case1の 0 番目のバッチのhidden_statesで初期化
Case1の 0 番目のバッチのhidden_statesで初期化します。
Case1の 0 番目と同じ値が返ってくるはずです。
hidden_states はちょっと強引に変換しています…。
# case5
# hidden_statesを(1)のhidden_statesの[0]で統一します。
print("--- (5) all same hidden_states")
states0 = []
states1 = []
for i in range(len(test1_hs[0])):
states0.append(test1_hs[0][0])
states1.append(test1_hs[1][0])
hidden_states = [np.asarray(states0),np.asarray(states1)]
set_hidden_states(model, hidden_states)
print_result( model.predict(x_test, batch_size=batch_size) )
--- (5) all same hidden_states
0: 0.03929901123046875
1: 0.03929901123046875
2: 0.03929901123046875
3: 0.03929901123046875
4: 0.03929901123046875
5: 0.03929901123046875
まとめ
予想通りの結果でした。
これでステートフルLSTMでもバッチ処理ができるようになったかな…。
コード全体
from keras.models import Model
from keras.layers import *
from keras.preprocessing.sequence import TimeseriesGenerator
from keras.utils import np_utils
import keras
from keras import backend as K
import numpy as np
import random
import os
import tensorflow as tf
# copy from https://qiita.com/okotaku/items/8d682a11d8f2370684c9
def seed_everything(seed):
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
np.random.seed(seed)
tf.random.set_seed(seed)
session_conf = tf.compat.v1.ConfigProto(
intra_op_parallelism_threads=1,
inter_op_parallelism_threads=1
)
sess = tf.compat.v1.Session(graph=tf.compat.v1.get_default_graph(), config=session_conf)
tf.compat.v1.keras.backend.set_session(sess)
seed_everything(42)
# define
seq_length = 3
batch_size = 6
lstm_units = 16
shape=(3,1)
# reference: http://torch.classcat.com/2018/06/26/keras-ex-tutorials-stateful-lstm/
# 生データセットを定義します
alphabet = "ABCDEFGHIJKLMNOPQRSTUVWXYZA"
alphabet_int = [ i for i in range(len(alphabet))]
# 文字の数字 (0-25) へのマッピングとその逆を作成します。
char_to_int = dict((c, i) for i, c in enumerate(alphabet))
int_to_char = dict((i, c) for i, c in enumerate(alphabet))
def int_to_char_seq(seq):
seq = seq.reshape(seq_length)
s = ""
for c in seq:
c = int(c * float(len(alphabet)))
s += int_to_char[c]
return s
# https://keras.io/ja/preprocessing/sequence/
data = TimeseriesGenerator(alphabet_int, alphabet_int, length=seq_length)[0]
x_data = data[0]
y_data = data[1]
# normalize
x_data = x_data / float(len(alphabet))
x_data = np.reshape(x_data, (len(x_data),) + shape ) #(batch_size,len,data)
# one hot encode the output variable
y_data = np_utils.to_categorical(y_data)
# create model
c = input_ = Input(batch_shape=(batch_size,) + shape) #(batch_size,data)
c = LSTM(lstm_units, stateful=True, name="lstm")(c)
c = Dense(y_data.shape[1], activation="softmax")(c)
model = Model(input_, c)
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.summary()
# train
model.fit(x_data, y_data, epochs=2, batch_size=batch_size, verbose=0)
def get_hidden_states(model):
lstm = model.get_layer("lstm")
hidden_states = [K.get_value(lstm.states[0]), K.get_value(lstm.states[1])]
return hidden_states
def set_hidden_states(model, hidden_states):
model.get_layer("lstm").reset_states(hidden_states)
def print_result(result):
# result_shape: (batch_size, y_data.shape[1])
# 量が多いので参考に0番目のデータのみ表示
for i, r in enumerate(result):
print("{}: {}".format(i, r[0]))
# create test data
# x_data[0] をバッチサイズ分増やします
x_test = np.asarray([x_data[0] for _ in range(batch_size)])
# case1
print("--- (1) no reset")
test1_hs = get_hidden_states(model)
print_result( model.predict(x_test, batch_size=batch_size) )
# case2
print("--- (2) no reset 2")
print_result( model.predict(x_test, batch_size=batch_size) )
# case3
print("--- (3) restore hidden_state(1)")
set_hidden_states(model, test1_hs)
print_result( model.predict(x_test, batch_size=batch_size) )
# case4
print("--- (4) reset_states")
model.reset_states()
print_result( model.predict(x_test, batch_size=batch_size) )
# case5
# hidden_statesを(1)のhidden_statesの[0]で統一します。
print("--- (5) all same hidden_states")
states0 = []
states1 = []
for i in range(len(test1_hs[0])):
states0.append(test1_hs[0][0])
states1.append(test1_hs[1][0])
hidden_states = [np.asarray(states0),np.asarray(states1)]
set_hidden_states(model, hidden_states)
print_result( model.predict(x_test, batch_size=batch_size) )