はじめに
solr7.0でAutoscalingという機能が追加されました。
その後のリリースでも順調に機能強化が行われているようで、
まずはどういった機能かを調査、検証してみたのでまとめます。
Autoscalingとは
ノードがクラスタに参加、脱退したりするなどのクラスタ変更イベントが発生した際に、
安定してバランスの取れた状態を維持することを目的とした機能で、下記の要素で構成されています。
- Cluster Preferences
- Cluster Policy
- Triggers
- Trigger Actions
- Listeners
- Autoscaling APIs
例えば、ノードプロセスが起動するサーバが突然落ちたとしても、別サーバにレプリカを自動追加したり、
予め定義したインデックスサイズをオーバーしたら自動でSPLITSHARDを行ってデータ分散したりといったことが可能なようです。
各構成要素について
Cluster Preferences
Solrに各ノードの負荷を評価する方法を定義します。
レプリカ数を増やす操作の場合は負荷が一番少ないノード、
逆にレプリカ数を減らす操作の場合は負荷が一番高いノードが選択されます。
デフォルトの設定では「{minimize:cores},{maximize:freedisk}」となっており、
core数が少なく、ディスクサイズが一番多いノードが負荷が少ないノードとして選択されます。
minimizeやmaximizeに指定するソートパラメータには、ロードアベレージやヒープ使用量といった値も指定できるようです。
詳細についてはこちらを参考にしてください
Cluster Policy
クラスタポリシーはノード、シャード、またはコレクションが満たす必要がある規則を定義します。
例えば、{"cores":"<10", "node":"#ANY"}というポリシーはどのノードに関わらず、コア数が10未満である必要を意味します。
またクラスタポリシーがクラスタ全体に対するポリシーに対して、コレクション単位でポリシーを設定することも可能です。
コレクション単位のポリシーはクラスタポリシーで設定した内容の上書きが可能で、
先程のクラスタポリシーに対して、{"cores":"<5", "node":"#ANY"}というポリシーを特定のコレクションに設定した場合、
該当のコレクションのみ、1ノードあたりのコア数が5未満である制約が付きます。
また、クラスタ設定と同様にルールのベースとなるメトリクスにはロードアベレージ、ヒープ使用量など複数あり、
詳細についてはこちらを参考にしてください。
Triggers
トリガーは、ノードの参加やクラスタからの退出などのイベントを監視するために使用されます。
イベントが発生するとトリガーはプランを計算して実行する一連のアクション(クラスター変更)を行います。
Trigger Actions
トリガーに応答して何をすべきかをSolrに知らせるアクションを実行します。
solrにはデフォルトで全てのトリガーに2つのアクションが追加されます。
- ComputePlanAction
- クラスタを安定させるために必要なクラスタ管理操作を計算する
- ExecutePlanAction
- クラスタ上で実際にアクションを実行する
Listeners
- トリガーによって実行されたアクションの前後にリスナーを呼び出すことができます。
- リスナーは、イベントのログ記録や外部システムへの通知などのタスクを実行するためのコールバックメカニズムとして機能します
API
Autoscaling機能の設定内容の確認や、クラスターポリシーの設定などはAPIを介して行います。
検証してみる
なんとなく、機能の概要が理解できたところで実際に検証してみて、理解を深めたいと思います。
今回下記の環境で確認しました。
- EC2(CentOS7.3) × 4
- solr-7.6
- zookeeper-3.4.10
- java-1.8.0_162
自動レプリカ追加
- コレクション作成
まず自動レプリカ追加を有効にしたコレクションを作成します
$ curl -XGET 'http://localhost:8983/solr/admin/collections?action=CREATE&name=autoscaling_test1&numShards=1&replicationFactor=2&collection.configName=test_config&autoAddReplicas=true
* 1シャード、2レプリカ構成で「autoscaling_test1」という名前のコレクションを作成します。
* 「autoAddReplicas=true」を指定することで自動レプリカ追加が有効になります。

- solrプロセス停止
自動レプリカ追加が機能することを確認するために、任意のノードでsolrプロセスを停止します。

-
replicaが自動追加される
solrプロセスの停止から約2分後、別ノードにreplicaが追加されました
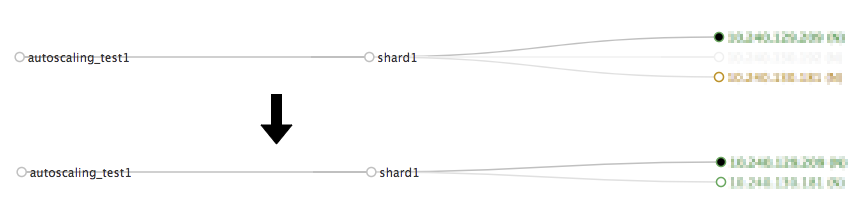
-
設定内容を確認してみる
ここでAPI経由でautoscalingの設定内容を確認してみます。
$ curl 'http://localhost:8983/api/cluster/autoscaling'
* トリガー
コレクション作成時に「autoAddReplicas=true」を指定することで下記のトリガーが自動設定されていることが確認できます
"triggers":{
".auto_add_replicas":{
"name":".auto_add_replicas",
"event":"nodeLost",
"waitFor":120,
"actions":[{
"name":"auto_add_replicas_plan",
"class":"solr.AutoAddReplicasPlanAction"},
{
"name":"execute_plan",
"class":"solr.ExecutePlanAction"}],
"enabled":true},
* リスナー
リスナーも同様にデフォルトで下記の内容で設定されます
"listeners":{
".auto_add_replicas.system":{
"beforeAction":[],
"afterAction":[],
"trigger":".auto_add_replicas",
"stage":["STARTED",
"ABORTED",
"SUCCEEDED",
"FAILED",
"BEFORE_ACTION",
"AFTER_ACTION",
"IGNORED"],
"class":"org.apache.solr.cloud.autoscaling.SystemLogListener"},
自動シャード追加
続いてメトリクス監視によるAutoscalingの挙動について見ていきたいと思います。
今回は挙動の確認がメインなので、登録ドキュメントが0の状態で10を超えたら自動でシャーディングが行われることを確認してみたいと思います。
- Cluster Preferencesの設定
クラスタ環境設定についてはデフォルトのままとします。 - Cluster Policyの設定
- グローバルルール
クラスタ全体の設定として、全てのノードにおいてcore数が4未満とするルールを適用します
- グローバルルール
$ curl -X POST -d '{"set-cluster-policy": [{"cores": "<4", "node": "#ANY"}]}' http://localhost:8983/api/cluster/autoscaling
- Triggers &Trigger Actionsの設定
ドキュメント数が10を超えたら実行されるトリガーを設定します。
$ curl -X POST -d '{"set-trigger":{
"name": "document_count_trigger",
"event": "indexSize",
"collections": "autoscaling_test1",
"aboveDocs": 10,
"belowDocs": 0,
"waitFor": "10s",
"enabled": true,
"actions":[
{
"name": "compute_plan",
"class": "solr.ComputePlanAction"},
{
"name": "execute_plan",
"class": "solr.ExecutePlanAction"}]
}}' http://localhost:8983/api/cluster/autoscaling
- ドキュメント登録
トリガーが実行されるように、11個のドキュメントを登録する - 自動でSPLITSHARDが実行される

注意事項
- 自動シャーディングを考慮してポリシーに指定するcoresなどは最大値を見越して設定する
- 先ほどの例でいうと、自動シャーディングにより1シャードが最終的に2シャードになりました。
- ポリシーに指定する値はinactiveとなっている数を含めた数にする必要があるようです。
- 当初は{"cores": "<3", "node": "#ANY"}というポリシーを設定していましたが、いくら待ってもSPLITSHARDが行われずはまりました。
- maxShardsPerNodeも考慮する
- コレクション作成時にmaxShardsPerNodeを明示的に指定しない場合は「1」となる
- クラスタ変更にはポリシールールと合わせてmaxShardsPerNodeの条件も満たす必要があるので要注意
まとめ
- 概ね期待した通りの動作をしてくれましたが、予めサーバリソースは確保されている前提なので、使い所は難しいなという印象です。
- 数百規模のサーバをプライベートクラウドとして運用しているケースでは余剰リソースをいい感じに利用できそう
- パプリッククラウドを利用して、kubernetesのように動的にサーバリソースが追加できるとベスト
- まだ未実装な機能(自動でのMERGESHARDSなど)があったりするので、今後の機能強化に期待したいところです。