この記事では,自然言語処理をする時にはこういう作業をするんだよ,というアウトラインを紹介します.
形態素解析
形態素解析というのは,文章を単語に切り刻む作業です.品詞を調べたり,活用形を原形に戻します.例えば「身の丈に合った受験」というフレーズは,こう解析されます.
身の丈 名詞,一般,,,,,身の丈,ミノタケ,ミノタケ
に 助詞,格助詞,一般,,,,に,ニ,ニ
合っ 動詞,自立,,,五段・ワ行促音便,連用タ接続,合う,アッ,アッ
た 助動詞,,,,特殊・タ,基本形,た,タ,タ
受験 名詞,サ変接続,,,,,受験,ジュケン,ジュケン
形態素解析にはMeCabを使っています.
https://taku910.github.io/mecab/
これは広く使われていますが,「管理栄養士試験」を「管理/栄養/士/試験」にしてしまうなど必要以上に単語を分割するため,新語や専門用語には弱い面もあります.新語についてはmecab-ipadic-NEologdという頻繁に更新されている辞書が公開されており,MeCabの弱点を補うことができます.
https://github.com/neologd/mecab-ipadic-neologd
わたしはこれ以外に,解析対象の新語辞書をローカルに作成して,いろいろ追加して使っています.
精度の高さではJUMAN++も使ってみたいと思っています.
http://nlp.ist.i.kyoto-u.ac.jp/index.php?JUMAN++
「外国人参政権」をMeCabで処理すると,「外国/人参/政権」となりますが,JUMAN++だと「外国人/参政権」と解析します.機械学習で解析の腕を上げることができるのが特徴です.しかしJUMAN++をboostでbuildするところでエラーを解決できず今に至ります.このままMeCabを使うのかなあ.
前処理
HTMLタグがついているようなテキストの場合は,タグを除去する必要があります.それ以外にも形態素解析に掛ける前に前処理をしておかないと,頻出キーワードに①やⅰが登場したり,同じ意味の単語が別々に集計されたりしてしまいます.
顔文字
何気に鬼門です.顔文字研究は実は,数十年の歴史がある奥深いものです.興味のある人は,人工知能学会誌 Vol. 32 No. 3 (2017/05)で特集が組まれているので読んでみてください.
https://www.ai-gakkai.or.jp/vol32_no3/
わたしは顔文字辞書を適当に拾って,自分の辞書に付け加えてお茶を濁していますが,カバー率は高くありません.解析対象テキストによっては,顔文字と真っ向から取り組む必要があるかもしれません.
正規化
同じ意味の類似した単語が別々に集計されることを防ぐための処理です.
<例>
全角半角,大文字小文字(例: Qiita,QIITA,Qiita,QIITA)
記法を揃える(例: 高3,高3,高校三年生,高三,高三生)
略語を揃える(例: 広大,広島大,広島大学)
数字
数字の扱いについては,文書の種類にもよるかもしれません.通常の文脈であれば数値はすべて削除でもいいかもしれません.一方,スポーツの記録など,数字がキーワードになるものは,数字は数字として扱えた場合が良いでしょう.この場合に面倒なのは,MeCabは小数点の入った数字を,整数部・ピリオド・小数部と,それぞれ別の単語に区切ってしまいます.この場合,いっぺん形態素解析を実施した後に,数値を復元するような処理が必要になります.
ストップワードの除去
ストップワードとは,「私」「です」のように,どこの文書にも顔を出すような単語のことです.わたしは,非自立語と,分析対象文書に登場頻度の高い単語を,ストップワードとして解析対象からはずしています.
その他
化学式,数学や物理の公式,URL,商品コードや型番などは,字句解析対象外とした方がよいでしょう.例えばフェノール(C6H5OH)の化学式を単純にMeCabに与えるとこうなってしまいます.
C 名詞,一般,*,*,*,*,*
6 名詞,数,*,*,*,*,*
H 名詞,一般,*,*,*,*,*
5 名詞,数,*,*,*,*,*
OH 名詞,固有名詞,組織,*,*,*,*
これでは全然フェノールと認識できません.また,英文やプログラムコードを日本語と同等の手法で解析しても,意味のないことも多いでしょう.
文書のベクトル化
文書に含まれている単語を手掛かりに,文書をベクトル化します(Doc2Vec).
似たような文書であれば,似たようなベクトルになるはずです.
Doc2Vecはgensimというライブラリに含まれています.
https://radimrehurek.com/gensim/
いったんベクトルにしてしまえば,似た文書をまとめることも可能です.
似た文書をまとめるには,後述するトピック分析という手法もあります.
トピック分析と,ベクトル化を併用する場合もあります.
このあたりもいろいろ試行錯誤したいところです.
トピック分析
形態素解析済みの文書を自動的に分類し,指定したトピック数に分割するものです.
これまたgensimでできてしまいます.gensimおそるべし.
-
LDA(Latent Dirichlet Allocation):
文書群を与えると,指定したトピック群に話題を分割してくれます.問題はいくつに分割したらいいかがわかりにくい.perplexityとかcoherenceとか指標はありますが,使ってみてそれっぽい形になりませんでした.
Rのtopicmodelsパッケージを使ってperplexityとcoherenceを出してみました.
https://cran.r-project.org/web/packages/topicmodels/index.html
文書の量が多すぎたのか,グラフ一本描くのに二週間連続実行しても足りませんでした.
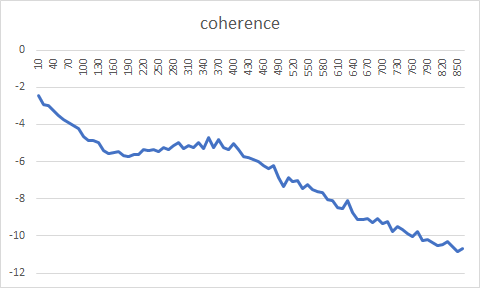
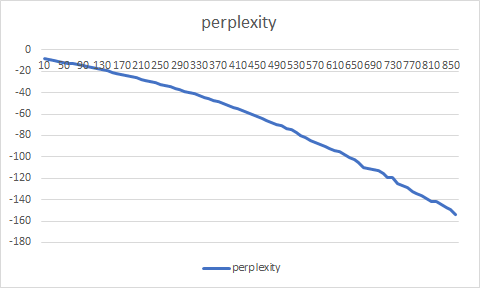
-
DTM(Dynamic Topic Model):
LDAを拡張し,SNS上の一定期間の話題を解析する場合のように,新しいニュースが飛び込んできて話題が遷移する時に使うモデルです. -
HDP(Hierarchical Dirichlet Process):
LDAを拡張し,文書をいくつのトピックに分割すればいいかご託宣をくれるはず,なのですが,手持ちのデータセットを食わせたところ,トピックの半分以上が似たり寄ったりの内容で,妥当なトピック分けができていませんでした.
BERT
Googleが昨年発表した自然言語処理モデルです。使ってみたいといいつつ,全然調べていません.これから勉強します.