はじめに
前回『教師あり学習とは』の続きです。今回は実践編です。
scikit-learnに入っている、ワインのデータセットで教師あり学習を動かしてみます。
ゴール
ワインの特徴( 度数, 色, 成分, ... )から、3種類のワインの銘柄( 詳細は不明 )を分類します。
実装
実行環境
Google Colabでの実行を想定しています。詳しくはこちらを参照してください。
ライブラリの読み込み
まずは使うライブラリを読み込みます。今回はNumPy, PyTorch, Pandas, scikit-learnを使います。
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
import pandas as pd
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
ライブラリのざっくり説明
・NumPy
数字を扱うときによく使います。いろいろな計算ができます。
・PyTorch
ニューラルネットワークのモデルが簡単に定義できます。
・Pandas
データフレームが使えます。万単位の大きなデータでもExcelのように扱えます。
・scikit-learn
機械学習に欲しい機能がいろいろ入っています。データセットもいろいろあります。
データフレームの作成
wine = load_wine()
wine_df = pd.DataFrame(wine.data, columns=wine.feature_names)
wine_class = pd.DataFrame(wine.target, columns=["class"])
load_wine() でワインのデータを読み込みます。
pd.DataFrame(読み込むデータ, index="行の名前", columns="列の名前") でデータフレームを作成します。
index と columns は省略すると通し番号が振られます。
wine_df では indexを省略しているため、行には0からの通し番号が振られています。
反対に、 columns には wine.feature_names が指定されています。
wine.feature_names の中身は、['alcohol', 'malic_acid', ...] のようなリストになっています。
下の図を見ての通り、リストがそのまま列の名前になっています。
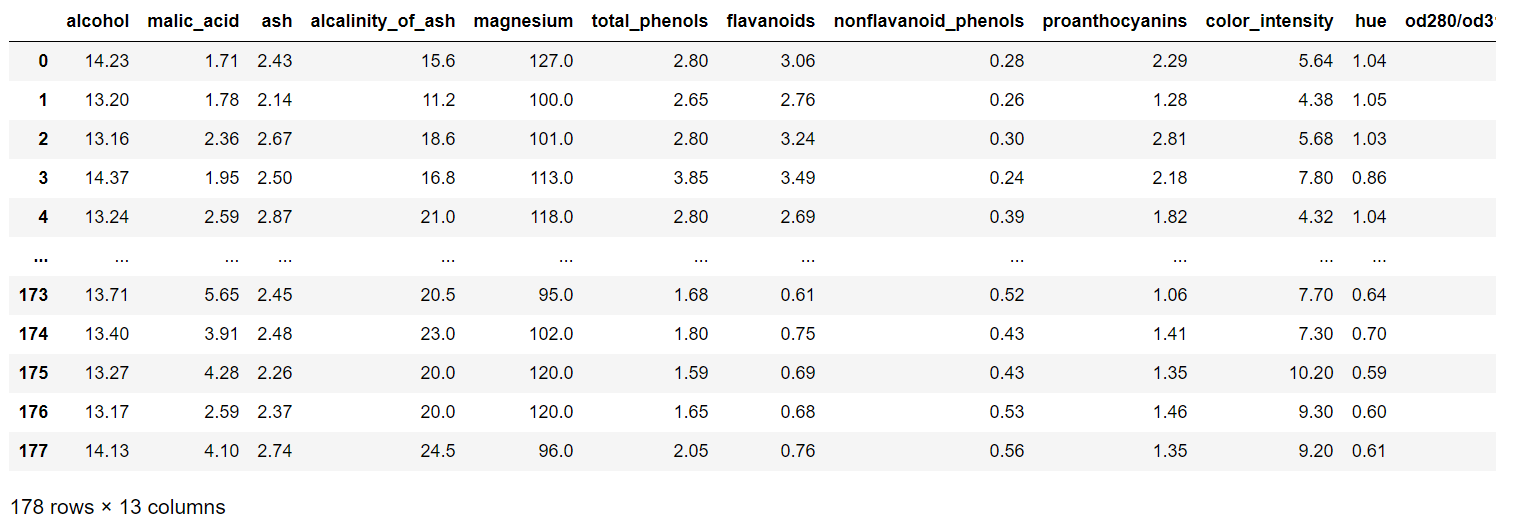
同様に、wine_class というデータフレームも作成。columns には classという名前をつけました。
wine.target にはワインの種類の情報が入っています。確かに、0, 1, 2 という3種類のワインがあるようです。

今更かもしれませんが、データフレームの行を index(インデックス)、列を columns(カラム)といいます。
行列の行と列はrowとcolumnsなんですが、謎です。
学習データの準備
wine_cat = pd.concat([wine_df, wine_class], axis=1)
wine_cat.drop(wine_cat[wine_cat["class"] == 2].index, inplace=True)
ここではデータフレームの結合と削除をやっています。
pd.concat([データフレームA, データフレームB], axis = 1) で、データフレームAとでデータフレームBを結合します。
axis = 1 は横(右端)に縦方向の結合をさせるという意味です。
axis = 0 なら縦(下端)にくっつくイメージです。
pd.concat([wine_df, wine_class], axis = 1) を実行すると、先ほどの wine_df の右端に wine_class が追加されます。それを wine_cat に代入します。
下の図をみると、先ほどの wine_df の右端に class が追加されていることがわかります。
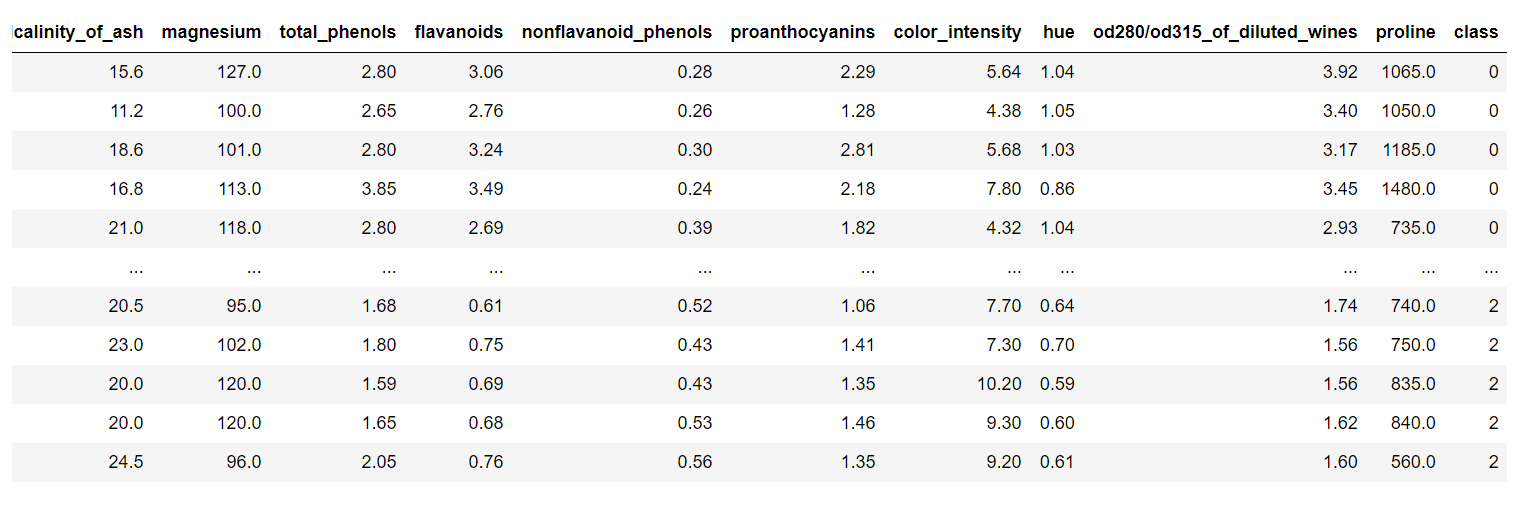
データセットの分割
wine_data = wine_cat.values[:, :13]
wine_target = wine_cat.values[:,13]
Train_X, Test_X, Train_Y, Test_Y = train_test_split(wine_data, wine_target, test_size=0.25)
wine_cat.values[:, :13] で wine_cat の12列目までのすべて( 成分などの情報 )を参照し、wine_data に代入。
wine_cat.values[:,13] は wine_cat の13列目( 種類 )を参照し、wine_target に代入しています。
train_test_split(データ, ラベル, 検証データの数) で学習用データとテスト用データを分割します。
test_size=0.25 ということは、テスト用データが 25% で、75% が学習用データということです。
PyTorchテンソルに変換
train_X = torch.FloatTensor(Train_X)
train_Y = torch.LongTensor(Train_Y)
test_X = torch.FloatTensor(Test_X)
test_Y = torch.LongTensor(Test_Y)
train = TensorDataset(train_X, train_Y)
test = TensorDataset(test_X, test_Y)
分割したデータセットをそれぞれ"学習用"と"テスト用"の変数に代入。学習用データは train に代入しておきます。
テンソルとは?
行列のようなものです。詳しくはこちらを参照してください。
「機械学習で使う数学を学ぶなら覚えておこう!「テンソル」とは」
https://aizine.ai/tensor-0917/
train_loader = DataLoader(train, batch_size=16, shuffle=False)
test_loader = DataLoader(test, batch_size=16, shuffle=False)
DataLoader(データ, バッチサイズ, shuffle) でデータの読み込み。
引数は順にデータ、バッチサイズ、シャッフルの有無です。
それを train_loader に代入しています。
バッチとは?
平たく言うと、「ひとつにまとめる」イメージです。バッチ処理とは、まとめて一気に処理するというイメージです。batch_size=16 ということは、16個をまとめて扱います。
ニューラルネットワークモデルの定義
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(13, 32)
self.fc2 = nn.Linear(32, 8)
self.fc3 = nn.Linear(8, 3)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001)
入力層, 隠れ層, 出力層の3層からなるニューラルネットワークを定義しています。
self.fc1 = nn.Linear(13, 32) の 13 は入力データの次元数です。ワインの特徴量(アルコール度数, 色, ...)が13種類あるため、13次元となっています。
self.fc3 = nn.Linear(8, 3) の 3 は出力データの次元数です。推定するワインの銘柄が3種類なので 3 となっています。
criterion とは?
誤差を計算する関数です。ここでは CrossEntropyLoss( 交差エントロピー誤差 )で誤差を計算します。
ほかには二乗和誤差などもあります。
optimizer とは?
最適化手法です。ここでは SGD( 確率的勾配降下法 )を使います。
画像の分類には Adam( 適応モーメント推定 )なども使います。
class Net(nn.Module):
nn.Module はニューラルネットワークの親クラスです。それを継承した子クラスの Net クラスを定義します。
学習
for epoch in range(5000):
total_loss = 0
for train_x, train_label in train_loader:
optimizer.zero_grad()
loss = criterion(net(train_x), train_label)
loss.backward()
optimizer.step()
total_loss += loss.data
if(epoch+1)%1000 == 0:
print(epoch+1, ":", total_loss)
ここの書き方はお作法的な側面が強いです。
for epoch in range(5000): で学習回数を指定しています。ここでは5000エポック学習します。
if 以下は誤差の出力です。1000回ずつ出力するよう設定しています。
検証
net.eval()
with torch.no_grad():
correct = 0
total = 0
for train_x, train_label in train_loader:
outputs = net(train_x)
_, predicted = torch.max(outputs.data, 1)
total += train_label.size(0)
correct += (predicted == train_label).sum().item()
train_accuracy = correct / total
with torch.no_grad():
correct = 0
total = 0
for test_x, test_label in test_loader:
outputs = net(test_x)
_, predicted = torch.max(outputs.data, 1)
total += test_label.size(0)
correct += (predicted == test_label).sum().item()
test_accuracy = correct / total
print(f"学習用データの正解率:{100 * train_accuracy:.2f}%")
print(f"テスト用データの正解率:{100 * test_accuracy:.2f}%")
net.eval() で学習モデルを検証モードにします。
学習用データとテスト用データの正解率をそれぞれ計算しています。

私の環境で試した結果はこうなりました。
大体7割の正解率といったところでしょうか。
おわりに
だいぶ駆け抜けた気がしますが、教師あり学習の実装はこのような流れになります。
次回は画像の分類( MNIST )をやってみます。
次回