前回の記事ではRaspberry Pi Zero で収集した気象データ(SQLiteデータベース)からローカルPCのDockerコンテナ上で稼働する influxdb にデータをマイグレーションしました。
InfluxDB v2 (OSS版) SQLite3データベースのマイグレーション (Qiita@pipito-yukio)
今回は influxdata社 が提供する python ライブラリを使って、マイグレーションしたデータを pandas で読み込む方法を解説します。
現在 Raspberry Pi 4 では気象データベース(PostgreSQL) からFlaskアプリを通してAndroidスマホ向けに気象データの可視化画像を提供しています。

参考ドキュメント
-
influxdata 社 Api documents
Python client library
Query InfluxDB with Flux -
その他参考ドキュメント
InfluxDB 2.0 python client
PostgreSQLと influxdb(v2)の対比
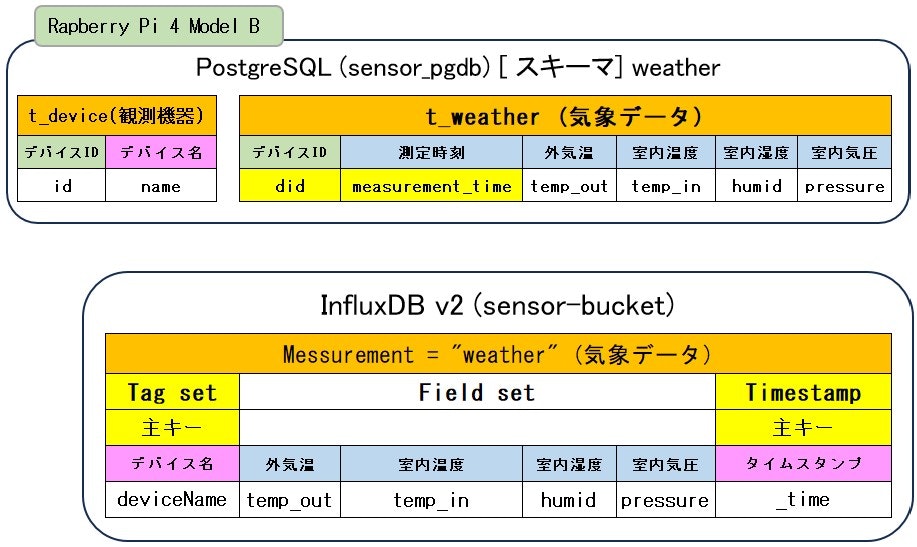
- PostgreSQLのDDL
CREATE SCHEMA IF NOT EXISTS weather;
CREATE TABLE IF NOT EXISTS weather.t_device(
id INTEGER NOT NULL,
name VARCHAR(20) UNIQUE NOT NULL,
CONSTRAINT pk_device PRIMARY KEY (id)
);
CREATE TABLE IF NOT EXISTS weather.t_weather(
did INTEGER NOT NULL,
measurement_time timestamp NOT NULL,
temp_out REAL,
temp_in REAL,
humid REAL,
pressure REAL
);
- Influxdb(v2)のスキーマ定義
#constant measurement,weather
#datatype tag,dateTime:number,double,double,double,double
deviceName,time,temp_out,temp_in,humid,pressure
PostgreSQLとInfluxdbの検索クエリーの対比

検証環境
-
OS: Ubuntu 22-04
※ 本番環境は Raspberry Pi 4 Model B を想定 (Python3.9) -
python仮想環境を作成し、必要なライブラリをインストールする
- PostgreSQLの例で必要なライブラリ
(py39_raspi4) $ pip install psycopg2-binary pandas- Influxdb の例で必要なライブラリ
(py39_influxdb) $ pip install influxdb-client pandas
influxdb-client-python ソースコード
※サンプルも含んでいます
$ git clone https://github.com/influxdata/influxdb-client-python.git
1. 気象データからpandasのDataFrameを生成する
指定した日付の1日分のデータを pandas の DataFrame にロードする
※インデックスとフィールド名は下記の通りとします
measurement_time temp_out temp_in humid pressure
measurement_time
2024-01-01 00:00:51 2024-01-01 00:00:51 -2.9 14.0 51.7 1009.6
2024-01-01 00:10:35 2024-01-01 00:10:35 -2.7 13.8 51.7 1009.8
... ... ... ... ... ...
2024-01-01 23:42:23 2024-01-01 23:42:23 -5.7 14.1 47.4 1018.6
2024-01-01 23:52:08 2024-01-01 23:52:08 -5.8 13.8 47.6 1018.5
1-1. PostgreSQLの例
1-1-(1) ライブラリのインポートとデータベース接続情報
from io import StringIO
from typing import List, Tuple, Dict, Optional
import pandas as pd
from pandas.core.frame import DataFrame
import psycopg2
from psycopg2.extensions import connection, cursor
"""
ラズパイ4の気象センサーデータベースから指定日のデータをpandasに読むこむ
"""
# PostgreSQLサーバー接続情報
DB_CONF: Dict = {
"host": "raspi-4.local",
"port": "5432",
"database": "sensors_pgdb",
"user": "developer",
"password": "[mypassword]"
}
1-1-(2) 検索クエリー定義
# 指定日の1日分のデータを取得する検索クエリー
QUERY_FIND_DATE: str = """
SELECT
to_char(measurement_time,'YYYY-MM-DD HH24:MI:SS') as measurement_time,
temp_out, temp_in, humid, pressure
FROM
weather.t_weather tw INNER JOIN weather.t_device td ON tw.did = td.id
WHERE
td.name='esp8266_1'
AND (
measurement_time >= to_timestamp('2024-01-01', 'YYYY-MM-DD HH24::MI:SS')
AND
measurement_time < to_timestamp('2024-01-02', 'YYYY-MM-DD HH24:MI:SS')
)
ORDER BY measurement_time;
"""
1-1-(3) データベースから取得したデータをStringIOバッファに溜め込む関数
※1 StringIOオブジェクトは read_csv 関数で読み込むことができます。
※2 SQLiteデータベース以外のデータベースでSQLAlchemyを使わない場合に使用
def _tuple_list_to_stringIO(
data_list: List[Tuple[str, float, float, float, float]]) -> StringIO:
str_buffer = StringIO()
str_buffer.write('"measurement_time","temp_out","temp_in","humid","pressure"\n')
for (m_time, temp_in, temp_out, humid, pressure) in data_list:
line = f'"{m_time}",{temp_in},{temp_out},{humid},{pressure}\n'
str_buffer.write(line)
# StringIO need Set first position
str_buffer.seek(0)
return str_buffer
1-1-(4) メイン処理
- PostgreSQLデータベース接続オブジェクト取得
- 検索クエリーを実行し全てのレコードを取得する
※ Tuple(測定時刻,外気温,室内気温,室内湿度,気圧)のリストになります - 全てのレコードから CSV形式の文字列バッファを生成する
- CSV形式の文字列バッファを read_csv 関数に設定し DataFrameを生成
if __name__ == '__main__':
conn: Optional[connection] = None
try:
conn = psycopg2.connect(**DB_CONF)
cur: cursor
with conn.cursor() as cur:
cur.execute(QUERY_FIND_DATE)
tuple_list = cur.fetchall()
if len(tuple_list) > 0:
_strIO: StringIO = _tuple_list_to_stringIO(tuple_list)
df: DataFrame = pd.read_csv(_strIO, parse_dates=["measurement_time"])
df.index = df["measurement_time"]
print(df)
else:
print("Record not found!")
except psycopg2.Error as db_err:
print(db_err)
finally:
if conn is not None:
conn.close()
上記スクリプトのDataFrameの出力結果
(raspi4_apps) $ python ReadWeather_psycopg.py
measurement_time temp_out temp_in humid pressure
measurement_time
2024-01-01 00:00:51 2024-01-01 00:00:51 -2.9 14.0 51.7 1009.6
2024-01-01 00:10:35 2024-01-01 00:10:35 -2.7 13.8 51.7 1009.8
2024-01-01 00:20:19 2024-01-01 00:20:19 -2.8 13.6 51.8 1009.9
2024-01-01 00:30:02 2024-01-01 00:30:02 -3.0 13.4 51.4 1010.1
2024-01-01 00:39:46 2024-01-01 00:39:46 -3.0 13.2 50.9 1010.4
... ... ... ... ... ...
2024-01-01 23:13:12 2024-01-01 23:13:12 -6.1 14.9 46.9 1019.0
2024-01-01 23:22:56 2024-01-01 23:22:56 -5.8 14.6 47.0 1019.0
2024-01-01 23:32:39 2024-01-01 23:32:39 -5.8 14.4 47.2 1018.8
2024-01-01 23:42:23 2024-01-01 23:42:23 -5.7 14.1 47.4 1018.6
2024-01-01 23:52:08 2024-01-01 23:52:08 -5.8 13.8 47.6 1018.5
[148 rows x 5 columns]
※ measurement_time 列は pandasのタイムスタンプオブジェクト(ローカル時刻)
1-2. influxdb クライアントの例
1-2-0. GitHubから取得したソースコードのサンプル
このソースの最後の Query: using Pandas DataFrame 部分の処理を流用します
import datetime as datetime
from influxdb_client import InfluxDBClient, Point, Dialect
from influxdb_client.client.write_api import SYNCHRONOUS
with InfluxDBClient(url="http://localhost:8086", token="my-token", org="my-org", debug=False) as client:
write_api = client.write_api(write_options=SYNCHRONOUS)
"""
Prepare data
"""
_point1 = Point("my_measurement").tag("location", "Prague").field("temperature", 25.3)
_point2 = Point("my_measurement").tag("location", "New York").field("temperature", 24.3)
write_api.write(bucket="my-bucket", record=[_point1, _point2])
query_api = client.query_api()
"""
Query: using Table structure
"""
tables = query_api.query('from(bucket:"my-bucket") |> range(start: -10m)')
for table in tables:
print(table)
for record in table.records:
print(record.values)
print()
print()
"""
Query: using Bind parameters
"""
p = {"_start": datetime.timedelta(hours=-1),
"_location": "Prague",
"_desc": True,
"_floatParam": 25.1,
"_every": datetime.timedelta(minutes=5)
}
tables = query_api.query('''
from(bucket:"my-bucket") |> range(start: _start)
|> filter(fn: (r) => r["_measurement"] == "my_measurement")
|> filter(fn: (r) => r["_field"] == "temperature")
|> filter(fn: (r) => r["location"] == _location and r["_value"] > _floatParam)
|> aggregateWindow(every: _every, fn: mean, createEmpty: true)
|> sort(columns: ["_time"], desc: _desc)
''', params=p)
for table in tables:
print(table)
for record in table.records:
print(str(record["_time"]) + " - " + record["location"] + ": " + str(record["_value"]))
print()
print()
"""
Query: using Stream
"""
records = query_api.query_stream('''
from(bucket:"my-bucket")
|> range(start: -10m)
|> filter(fn: (r) => r["_measurement"] == "my_measurement")
''')
for record in records:
print(f'Temperature in {record["location"]} is {record["_value"]}')
"""
Interrupt a stream after retrieve a required data
"""
large_stream = query_api.query_stream('''
from(bucket:"my-bucket")
|> range(start: -100d)
|> filter(fn: (r) => r["_measurement"] == "my_measurement")
''')
for record in large_stream:
if record["location"] == "New York":
print(f'New York temperature: {record["_value"]}')
break
large_stream.close()
print()
print()
"""
Query: using csv library
"""
csv_result = query_api.query_csv('from(bucket:"my-bucket") |> range(start: -10m)',
dialect=Dialect(header=False, delimiter=",", comment_prefix="#", annotations=[],
date_time_format="RFC3339"))
for csv_line in csv_result:
print(f'Temperature in {csv_line[9]} is {csv_line[6]}')
print()
print()
"""
Query: using Pandas DataFrame
"""
data_frame = query_api.query_data_frame('''
from(bucket:"my-bucket")
|> range(start: -10m)
|> filter(fn: (r) => r["_measurement"] == "my_measurement")
|> pivot(rowKey:["_time"], columnKey: ["_field"], valueColumn: "_value")
|> keep(columns: ["_time","location", "temperature"])
''')
print(data_frame.to_string())```
1-2-0 (1). query_data_frameメソッドを使ってみる
マイグレーションした気象データのスキーマに合わせて取得するカラムを変更します
- 検索期間の日付は RFC3339 の UTC タイムスタンプ
-
pivot() function 上記サンプルをそのまま使っています
- influxdata 社 ブログサイト
Python, Pandas Dataframes, and InfluxDB - APIドキュメント
pivot() function
- influxdata 社 ブログサイト
from pandas.core.frame import DataFrame
from influxdb_client import InfluxDBClient
from influxdb_client.client.query_api import QueryApi
if __name__ == '__main__':
client: InfluxDBClient = InfluxDBClient(
url="http://localhost:8086", org="raspi-influxdb", token="0123456789abcdef"
)
query_api: QueryApi = client.query_api()
data_frame: DataFrame = query_api.query_data_frame('''
from(bucket: "sensor-bucket")
|> range(start: 2023-12-31T15:00:00Z, stop: 2023-12-31T15:30:00Z)
|> filter(fn:(r) => r._measurement == "weather" and r.deviceName == "esp8266_1")
|> pivot(rowKey: ["_time"], columnKey: ["_field"], valueColumn: "_value")
|> keep(columns: ["_time", "temp_out", "temp_in", "humid", "pressure"])
''')
print(data_frame.to_string())
client.close()
上記スクリプトを実行した結果は以下のとおりです
(py39_influxdb) $ python ReadWeather_samplePanda.py
result table _time humid pressure temp_in temp_out
0 _result 0 2023-12-31 15:00:51+00:00 51.7 1009.6 14.0 -2.9
1 _result 0 2023-12-31 15:10:35+00:00 51.7 1009.8 13.8 -2.7
2 _result 0 2023-12-31 15:20:19+00:00 51.8 1009.9 13.6 -2.8
上記のデータでは matplotlib を使った既存の可視化処理でそのまま使えません
※1 取得したタイムスタンプが UTC なので ローカル時刻に変換しなければならない
※2 必要のないカラム(result, table)がありこのカラムは削除できない
1-2-1. 既存の可視化処理に投入可能なDataFramを生成する
query_data_frame() メソッドは使わず、query()メソッドを使用します
※Pythonのバージョンは 3.9以上
from datetime import datetime, timezone
from io import StringIO
from typing import Dict, List, Tuple
# Require python 3.9
from zoneinfo import ZoneInfo
import pandas as pd
from pandas.core.frame import DataFrame
from influxdb_client import InfluxDBClient
from influxdb_client.client.query_api import QueryApi
from influxdb_client.client.flux_table import FluxTable, FluxRecord, TableList
# 指定期間の検索クエリー
QRY_BODY: str = """from(bucket: "sensor-bucket")
|> range(start: {from_time}, stop: {to_time})
|> filter(fn:(r) => r._measurement == "weather" and r.deviceName == "esp8266_1")
|> pivot(rowKey: ["_time"], columnKey: ["_field"], valueColumn: "_value")
|> keep(columns: ["_time", "temp_out", "temp_in", "humid", "pressure"])
"""
# pandas DataFrame: ["measurement_time","temp_out","temp_in","humid","pressure"]
# "measurement_time" is pandas DataFrame index
QRY_RENAME: str = """|> rename(columns: {_time: "measurement_time"})
"""
1-2-(1) InfluxClientから取得したデータをStringIOバッファに溜め込む関数
※ PostgreSQLスクリプトと同一です
def _tuple_list_to_stringIO(
tuple_list: List[Tuple[str, float, float, float, float]]) -> StringIO:
str_buffer = StringIO()
str_buffer.write('"measurement_time","temp_out","temp_in","humid","pressure"\n')
for (m_time, temp_in, temp_out, humid, pressure) in tuple_list:
line = f'"{m_time}",{temp_in},{temp_out},{humid},{pressure}\n'
str_buffer.write(line)
# StringIO need Set first position
str_buffer.seek(0)
return str_buffer
1-2-(2) influxdbクライアント特有の変換関数
- ローカル日付を RFC3339形式 の UTC タイムスタンプに変換
# ローカル日付をRFC3339形式に変換する
def date_to_utc_timezone(iso_date: str, dt_format: str=None) -> str:
dt_local: datetime
if dt_format is None:
dt_local = datetime.strptime(iso_date, "%Y-%m-%d")
else:
dt_local = datetime.strptime(iso_date, dt_format)
# Change timestamp with timezone UTC
dt_utc: datetime = dt_local.astimezone(timezone.utc)
return dt_utc.strftime("%Y-%m-%dT%H:%M:%SZ")
- RFC3339形式のタイムスタンプをローカル時刻に変換
# UTCタイムスんタプをローカル時刻に変換する
def utc_datetime_to_local(dt_utc: datetime) -> str:
# To JST Time
dt = dt_utc.astimezone(ZoneInfo('Asia/Tokyo'))
return dt.strftime("%Y-%m-%d %H:%M:%S")
1-2-(3) メイン処理
- InfluxDBClientオブジェクトの生成
- クエリーパラメータの辞書オブジェクトを生成しクエリーテンプレートと結合する
- 検索開始時刻: RFC3339形式の UTC タイムスタンプ
- 検索終了時刻: RFC3339形式の UTC タイムスタンプ
- "_time"カラムを"measurement_time"にリネームする処理を末尾に追加
if __name__ == '__main__':
client: InfluxDBClient = InfluxDBClient(
url="http://localhost:8086", org="raspi-influxdb", token="0123456789abcdef"
)
params: Dict = {
"from_time": date_to_utc_timezone("2024-01-01 00:00:00", "%Y-%m-%d %H:%M:%S"),
"to_time": date_to_utc_timezone("2024-01-01 23:59:59", "%Y-%m-%d %H:%M:%S"),
}
query: str = QRY_BODY.format(**params)
# Rename _time to "measurement_time"
query += QRY_RENAME
print(query)
- QueryApiオブジェクト取得
- QueryApiオブジェクトの query メソッドを実行してレスポンスを取得
※レスポンスは Generator: レコードが存在すれば 1、存在しなければ 0 になります - レスポンスを1レコードずつ取り出す: table
- tableのレコードを取得する: rec
- 測定時間列 (UTC) をローカル時刻に変換
- 測定時間列と測定時刻以外のデータのタプル生成
- データリストに追加
- tableのレコードを取得する: rec
- データリストから StringIOオブジェクトを生成
- StringIOオブジェクトを read_csv関数に引き渡して DataFrameを生成
- 測定時間列をDataFrameのインデックスに設定
query_api: QueryApi = client.query_api()
# TableList is Generator (0|1)
tables: TableList = query_api.query(query=query)
print(f"tables.len: {len(tables)}")
if len(tables) > 0:
record: FluxRecord
table: FluxTable
data_list: List[Tuple[str, float, float, float, float]] = []
for table in tables:
for rec in table.records:
# UTC Timestamp: _time
# dt: datetime = rec.get_time()
# Rename: _time -> "measurement_time"
local_time: str = utc_datetime_to_local(rec["measurement_time"])
data_list.append(
(local_time, rec["temp_out"], rec["temp_in"], rec["humid"], rec["pressure"])
)
# pandas dataframe
_strIO: StringIO = _tuple_list_to_stringIO(data_list)
df: DataFrame = pd.read_csv(_strIO, parse_dates=["measurement_time"])
df.index = df["measurement_time"]
print(df)
else:
print("Record not found!")
client.close()
参考までにDEBUGコンソールでの FluxRecordは以下のとおりです
rec = {FluxRecord} <FluxRecord: field=None, value=None>
row = {list: 7} ['_result', 0, datetime.datetime(2023, 12, 31, 15, 0, 51, tzinfo=tzutc()), 51.7, 1009.6, 14.0, -2.9]
0 = {str} '_result'
1 = {int} 0
2 = {datetime} datetime.datetime(2023, 12, 31, 15, 0, 51, tzinfo=tzutc())
3 = {float} 51.7
4 = {float} 1009.6
5 = {float} 14.0
6 = {float} -2.9
__len__ = {int} 7
table = {int} 0
values = {dict: 7} {'humid': 51.7, 'measurement_time': datetime.datetime(2023, 12, 31, 15, 0, 51, tzinfo=tzutc()), 'pressure': 1009.6, 'result': '_result', 'table': 0, 'temp_in': 14.0, 'temp_out': -2.9}
'result' = {str} '_result'
'table' = {int} 0
'measurement_time' = {datetime} datetime.datetime(2023, 12, 31, 15, 0, 51, tzinfo=tzutc())
'humid' = {float} 51.7
'pressure' = {float} 1009.6
'temp_in' = {float} 14.0
'temp_out' = {float} -2.9
__len__ = {int} 7
上記スクリプトを実行した結果は以下のとおりです
※startとendがRFC3339形式の UTCタイムスタンプになっています
(py39_influxdb) $ python ReadWeather_panda.py
from(bucket: "sensor-bucket")
|> range(start: 2023-12-31T15:00:00Z, stop: 2024-01-01T14:59:59Z)
|> filter(fn:(r) => r._measurement == "weather" and r.deviceName == "esp8266_1")
|> pivot(rowKey: ["_time"], columnKey: ["_field"], valueColumn: "_value")
|> keep(columns: ["_time", "temp_out", "temp_in", "humid", "pressure"])
|> rename(columns: {_time: "measurement_time"})
tables.len: 1
measurement_time temp_out temp_in humid pressure
measurement_time
2024-01-01 00:00:51 2024-01-01 00:00:51 -2.9 14.0 51.7 1009.6
2024-01-01 00:10:35 2024-01-01 00:10:35 -2.7 13.8 51.7 1009.8
2024-01-01 00:20:19 2024-01-01 00:20:19 -2.8 13.6 51.8 1009.9
2024-01-01 00:30:02 2024-01-01 00:30:02 -3.0 13.4 51.4 1010.1
2024-01-01 00:39:46 2024-01-01 00:39:46 -3.0 13.2 50.9 1010.4
... ... ... ... ... ...
2024-01-01 23:13:12 2024-01-01 23:13:12 -6.1 14.9 46.9 1019.0
2024-01-01 23:22:56 2024-01-01 23:22:56 -5.8 14.6 47.0 1019.0
2024-01-01 23:32:39 2024-01-01 23:32:39 -5.8 14.4 47.2 1018.8
2024-01-01 23:42:23 2024-01-01 23:42:23 -5.7 14.1 47.4 1018.6
2024-01-01 23:52:08 2024-01-01 23:52:08 -5.8 13.8 47.6 1018.5
[148 rows x 5 columns]
作成したpythonスクリプトの全体を再掲します
from datetime import datetime, timezone
from io import StringIO
from typing import Dict, List, Tuple
# Require python 3.9
from zoneinfo import ZoneInfo
import pandas as pd
from pandas.core.frame import DataFrame
from influxdb_client import InfluxDBClient
from influxdb_client.client.query_api import QueryApi
from influxdb_client.client.flux_table import FluxTable, FluxRecord, TableList
"""
気象データDB for InfluxDB v2
influxdb into pandas DataFrame
"""
QRY_BODY: str = """from(bucket: "sensor-bucket")
|> range(start: {from_time}, stop: {to_time})
|> filter(fn:(r) => r._measurement == "weather" and r.deviceName == "esp8266_1")
|> pivot(rowKey: ["_time"], columnKey: ["_field"], valueColumn: "_value")
|> keep(columns: ["_time", "temp_out", "temp_in", "humid", "pressure"])
"""
# pandas DataFrame: ["measurement_time","temp_out","temp_in","humid","pressure"]
# "measurement_time" is pandas DataFrame index
QRY_RENAME: str = """|> rename(columns: {_time: "measurement_time"})
"""
def _tuple_list_to_stringIO(
tuple_list: List[Tuple[str, float, float, float, float]]) -> StringIO:
str_buffer = StringIO()
str_buffer.write('"measurement_time","temp_out","temp_in","humid","pressure"\n')
for (m_time, temp_in, temp_out, humid, pressure) in tuple_list:
line = f'"{m_time}",{temp_in},{temp_out},{humid},{pressure}\n'
str_buffer.write(line)
# StringIO need Set first position
str_buffer.seek(0)
return str_buffer
def date_to_utc_timezone(iso_date: str, dt_format: str=None) -> str:
dt_local: datetime
if dt_format is None:
dt_local = datetime.strptime(iso_date, "%Y-%m-%d")
else:
dt_local = datetime.strptime(iso_date, dt_format)
# Change timestamp with timezone UTC
dt_utc: datetime = dt_local.astimezone(timezone.utc)
return dt_utc.strftime("%Y-%m-%dT%H:%M:%SZ")
def utc_datetime_to_local(dt_utc: datetime) -> str:
# To JST Time
dt = dt_utc.astimezone(ZoneInfo('Asia/Tokyo'))
return dt.strftime("%Y-%m-%d %H:%M:%S")
if __name__ == '__main__':
client: InfluxDBClient = InfluxDBClient(
url="http://localhost:8086", org="raspi-influxdb", token="0123456789abcdef"
)
params: Dict = {
"from_time": date_to_utc_timezone("2024-01-01 00:00:00", "%Y-%m-%d %H:%M:%S"),
"to_time": date_to_utc_timezone("2024-01-01 23:59:59", "%Y-%m-%d %H:%M:%S"),
}
query: str = QRY_BODY.format(**params)
# Rename _time to "measurement_time"
query += QRY_RENAME
print(query)
query_api: QueryApi = client.query_api()
# TableList is Generator (0|1)
tables: TableList = query_api.query(query=query)
print(f"tables.len: {len(tables)}")
if len(tables) > 0:
record: FluxRecord
table: FluxTable
data_list: List[Tuple[str, float, float, float, float]] = []
for table in tables:
for rec in table.records:
# UTC Timestamp: _time
# dt: datetime = rec.get_time()
# Rename: _time -> "measurement_time"
local_time: str = utc_datetime_to_local(rec["measurement_time"])
data_list.append(
(local_time, rec["temp_out"], rec["temp_in"], rec["humid"], rec["pressure"])
)
# pandas dataframe
_strIO: StringIO = _tuple_list_to_stringIO(data_list)
df: DataFrame = pd.read_csv(_strIO, parse_dates=["measurement_time"])
df.index = df["measurement_time"]
print(df)
else:
print("Record not found!")
client.close()
結論
influxdata社で提供しているソースコードには豊富なサンプルも付属しており、今回はそのサンプル元にpythonクライアントでのマイグレーション方法を解説しました。
examples 直下に サンプルコードの説明を記載した README.md があります。 関心のあるサンプルを実際に動かすことで登録・検索処理における時系列データベースの扱い方を理解することができるのではないでしょうか。
ちょっと実装に困った時は influxdb_client 配下のソースコードを眺めてみるのも解決のヒントになるかもしれません。