DynamicFrameのmergeDynamicFrameを使ってデータのマージ
2つのDynamicFrameをマージするというだけです。同じ意味を持つデータで、別ファイルとして行われた更新をマージしたい場合によいかもしれません。
ジョブの内容
JupyterNotebookで、2つのDynamicFrameをマージします。
全体の流れ
- 前準備
- ジョブ実行
- 確認
前準備
ソースデータ
(uuidをキーとしてこの後のジョブを実施します)
cvlog1.csv
19件のデータ
deviceid,uuid,appid,country,year,month,day,hour
iphone,11111,001,JP,2017,12,14,12
android,11112,001,FR,2017,12,14,14
iphone,11113,009,FR,2017,12,16,21
iphone,11114,007,AUS,2017,12,17,18
other,11115,005,JP,2017,12,29,15
iphone,11116,001,JP,2017,12,15,11
pc,11118,001,FR,2017,12,01,01
pc,11117,009,FR,2017,12,02,18
iphone,11119,007,AUS,2017,11,21,14
other,11110,005,JP,2017,11,29,15
iphone,11121,001,JP,2017,11,11,12
android,11122,001,FR,2017,11,30,20
iphone,11123,009,FR,2017,11,14,14
iphone,11124,007,AUS,2017,12,17,14
iphone,11125,005,JP,2017,11,29,15
iphone,11126,001,JP,2017,12,19,08
android,11127,001,FR,2017,12,19,14
iphone,11128,009,FR,2017,12,09,04
iphone,11129,007,AUS,2017,11,30,14
cvlog2.csv
csvlog1.csvを元にした17件のデータ
csvlog1.csvとの変更点は以下3つ
cvlog1.csvにはないデータ(cvlog2.csvからuuidが11110,11121の2件削除)
other,11110,005,JP,2017,11,29,15
iphone,11121,001,JP,2017,11,11,12
cvlog1.csvとcvlog2.csv両方に同じuuidで他の値が異なるデータ(cvlog2.csvからuuidが11122,11123の2件のdeviceidをn/aに修正)
n/a,11122,001,FR,2017,11,30,20
n/a,11123,009,FR,2017,11,14,14
cvlog1.csvにないデータ(cvlog2.csvからuuidが11124-11129の6件を21124-21129に修正)
n/a,21124,007,AUS,2017,12,17,14
n/a,21125,005,JP,2017,11,29,15
n/a,21126,001,JP,2017,12,19,08
n/a,21127,001,FR,2017,12,19,14
n/a,21128,009,FR,2017,12,09,04
n/a,21129,007,AUS,2017,11,30,14
deviceid,uuid,appid,country,year,month,day,hour
iphone,11111,001,JP,2017,12,14,12
android,11112,001,FR,2017,12,14,14
iphone,11113,009,FR,2017,12,16,21
iphone,11114,007,AUS,2017,12,17,18
other,11115,005,JP,2017,12,29,15
iphone,11116,001,JP,2017,12,15,11
pc,11118,001,FR,2017,12,01,01
pc,11117,009,FR,2017,12,02,18
iphone,11119,007,AUS,2017,11,21,14
n/a,11122,001,FR,2017,11,30,20
n/a,11123,009,FR,2017,11,14,14
n/a,21124,007,AUS,2017,12,17,14
n/a,21125,005,JP,2017,11,29,15
n/a,21126,001,JP,2017,12,19,08
n/a,21127,001,FR,2017,12,19,14
n/a,21128,009,FR,2017,12,09,04
n/a,21129,007,AUS,2017,11,30,14
S3にアップロード
両ファイルをS3にアップロード
Glueクローラーなどでテーブル作成
手順はこの辺を参考にしてもらえたらと
https://qiita.com/pioho07/items/c9ce1d0677777f974ffe
ジョブ実行
【参考】公式ページから引用↓
mergeDynamicFrame(stage_dynamic_frame, primary_keys, transformation_ctx = "", options = {}, info = "", stageThreshold = 0, totalThreshold = 0)
JupyterNotebookの起動します。
手順はこの辺を参考にしてもらえたらと
https://qiita.com/pioho07/items/29bd779f84b4add9cf2c
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
datasource0 = glueContext.create_dynamic_frame.from_catalog(database = "se2", table_name = "se2_in12", transformation_ctx = "datasource0")
datasource1 = glueContext.create_dynamic_frame.from_catalog(database = "se2", table_name = "se2_in13", transformation_ctx = "datasource1")
merged_frame = datasource0.mergeDynamicFrame(datasource1, ["uuid"], transformation_ctx = "merged_frame", options = {}, info = "", stageThreshold = 0, totalThreshold = 0)
df = merged_frame.toDF()
df.show(100)
df.count()
+--------+-----+-----+-------+----+-----+---+----+
|deviceid| uuid|appid|country|year|month|day|hour|
+--------+-----+-----+-------+----+-----+---+----+
| iphone|11124| 7| AUS|2017| 12| 17| 14|
| iphone|11128| 9| FR|2017| 12| 9| 4|
| iphone|11125| 5| JP|2017| 11| 29| 15|
| iphone|11121| 1| JP|2017| 11| 11| 12|
| other|11110| 5| JP|2017| 11| 29| 15|
| iphone|11126| 1| JP|2017| 12| 19| 8|
| iphone|11129| 7| AUS|2017| 11| 30| 14|
| android|11127| 1| FR|2017| 12| 19| 14|
| iphone|11111| 1| JP|2017| 12| 14| 12|
| android|11112| 1| FR|2017| 12| 14| 14|
| iphone|11113| 9| FR|2017| 12| 16| 21|
| iphone|11114| 7| AUS|2017| 12| 17| 18|
| other|11115| 5| JP|2017| 12| 29| 15|
| iphone|11116| 1| JP|2017| 12| 15| 11|
| pc|11118| 1| FR|2017| 12| 1| 1|
| pc|11117| 9| FR|2017| 12| 2| 18|
| iphone|11119| 7| AUS|2017| 11| 21| 14|
| n/a|11122| 1| FR|2017| 11| 30| 20|
| n/a|11123| 9| FR|2017| 11| 14| 14|
| n/a|21124| 7| AUS|2017| 12| 17| 14|
| n/a|21125| 5| JP|2017| 11| 29| 15|
| n/a|21126| 1| JP|2017| 12| 19| 8|
| n/a|21127| 1| FR|2017| 12| 19| 14|
| n/a|21128| 9| FR|2017| 12| 9| 4|
| n/a|21129| 7| AUS|2017| 11| 30| 14|
+--------+-----+-----+-------+----+-----+---+----+
25
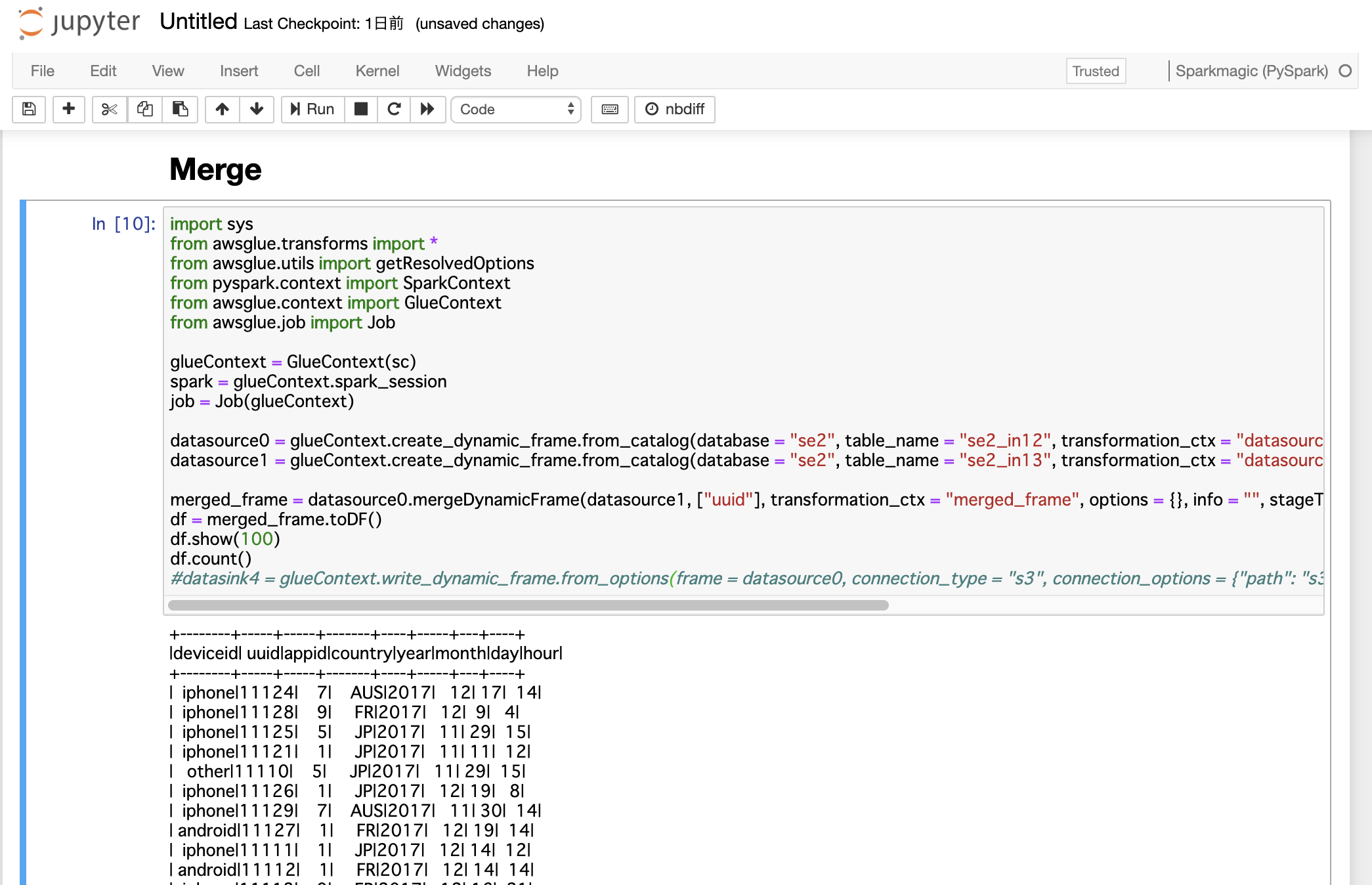
ジョブの確認
動きとしては2つ目のデータ(cvlog2.csv)の値で上書かれるようになります。
cvlog1.csvにしかないデータ(cvlog2.csvからuuidが11110,11121の2件削除)
1つ目のcvlog1.csvにしかないデータは保持されます
cvlog1.csvとcvlog2.csv両方に同じuuidで他の値が異なるデータ(cvlog2.csvからuuidが11122,11123の2件のdeviceidをn/aに修正)
1つ目のcvlog1.csvと2つ目cvlog2.csvに同一キーがあり他のカラムの値が異なっている場合、2つ目の値で上書きされます
cvlog1.csvにないデータ(cvlog2.csvからuuidが11124-11129の6件を21124-21129に修正)
2つ目のcvlog2.csvにしかないデータはそのままマージされます
こちらも是非
Glueの使い方まとめ
https://qiita.com/pioho07/items/32f76a16cbf49f9f712f