GlueでRDSから読み取りはデフォでは1つのExecutorで実行され、もしメモリ超過する場合は並列化しよう
今回実施する構成図は以下のような感じになります。RedshiftをRDSに置き換えて見てください。
GlueからRDSのデータを読み込みparquetにしてS3に出力します。
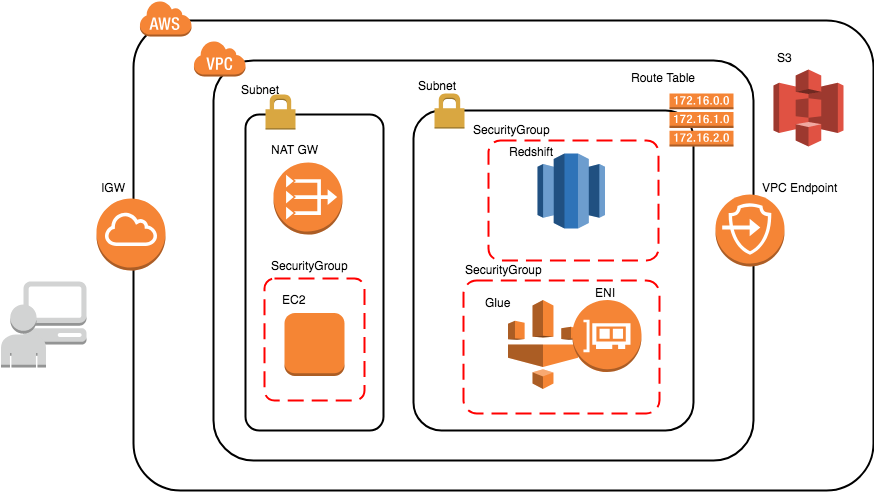
全体の流れ
- 前準備
- Glueジョブ作成(デフォルト)
- ログ確認
- Glueジョブ作成(並列化)
- ログ確認
- 出力確認
前準備
自己参照セキュリティグループなどの作り方や意味合いはこちらを参照ください。
GlueのConnectionの作成もこちらをご参照ください
https://qiita.com/pioho07/items/05c912333e88788a1391
https://qiita.com/pioho07/items/3a07cf6dccb8dfe046ff
RDSを作成し、テーブル、スキーマ、データインポート。作業は割愛します。クエリの確認のためRDSのパラメータグループでgeneral_logを1にしておく。
インポートデータは以下
- カラム情報
deviceid,uuid,appid,country,year,month,day,hour
※RDSはGlueの使い方的な㉟と同じものを利用
iphone,11111,001,JP,2017,12,14,12
android,11112,001,FR,2017,12,14,14
iphone,11113,009,FR,2017,12,16,21
iphone,11114,007,AUS,2017,12,17,18
other,11115,005,JP,2017,12,29,15
iphone,11116,001,JP,2017,12,15,11
pc,11118,001,FR,2017,12,01,01
pc,11117,009,FR,2017,12,02,18
iphone,11119,007,AUS,2017,11,21,14
other,11110,005,JP,2017,11,29,15
iphone,11121,001,JP,2017,11,11,12
android,11122,001,FR,2017,11,30,20
iphone,11123,009,FR,2017,11,14,14
iphone,11124,007,AUS,2017,12,17,14
iphone,11125,005,JP,2017,11,29,15
iphone,11126,001,JP,2017,12,19,08
android,11127,001,FR,2017,12,19,14
iphone,11128,009,FR,2017,12,09,04
iphone,11129,007,AUS,2017,11,30,14
RDS側でselectして確認
MySQL [db]> select * from cvlog;
+----------+-------+-------+---------+------+-------+------+------+
| deviceid | uuid | appid | country | year | month | day | hour |
+----------+-------+-------+---------+------+-------+------+------+
| iphon | 11111 | 1 | JP | 2017 | 12 | 14 | 12 |
| andro | 11112 | 1 | FR | 2017 | 12 | 14 | 14 |
| iphon | 11113 | 9 | FR | 2017 | 12 | 16 | 21 |
| iphon | 11114 | 7 | AUS | 2017 | 12 | 17 | 18 |
| other | 11115 | 5 | JP | 2017 | 12 | 29 | 15 |
| iphon | 11116 | 1 | JP | 2017 | 12 | 15 | 11 |
| pc | 11118 | 1 | FR | 2017 | 12 | 1 | 1 |
| pc | 11117 | 9 | FR | 2017 | 12 | 2 | 18 |
| iphon | 11119 | 7 | AUS | 2017 | 11 | 21 | 14 |
| other | 11110 | 5 | JP | 2017 | 11 | 29 | 15 |
| iphon | 11121 | 1 | JP | 2017 | 11 | 11 | 12 |
| andro | 11122 | 1 | FR | 2017 | 11 | 30 | 20 |
| iphon | 11123 | 9 | FR | 2017 | 11 | 14 | 14 |
| iphon | 11124 | 7 | AUS | 2017 | 12 | 17 | 14 |
| iphon | 11125 | 5 | JP | 2017 | 11 | 29 | 15 |
| iphon | 11126 | 1 | JP | 2017 | 12 | 19 | 8 |
| andro | 11127 | 1 | FR | 2017 | 12 | 19 | 14 |
| iphon | 11128 | 9 | FR | 2017 | 12 | 9 | 4 |
| iphon | 11129 | 7 | AUS | 2017 | 11 | 30 | 14 |
+----------+-------+-------+---------+------+-------+------+------+
MySQL [db]> show create table cvlog\G
*************************** 1. row ***************************
Table: cvlog
Create Table: CREATE TABLE `cvlog` (
`deviceid` varchar(5) DEFAULT NULL,
`uuid` int(11) DEFAULT NULL,
`appid` int(11) DEFAULT NULL,
`country` varchar(5) DEFAULT NULL,
`year` int(11) DEFAULT NULL,
`month` int(11) DEFAULT NULL,
`day` int(11) DEFAULT NULL,
`hour` int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1
Glueジョブ作成
以下のコードでジョブを作成し実行します。
RDS->S3
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
## @params: [JOB_NAME]
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
datasource0 = glueContext.create_dynamic_frame.from_catalog(database = "se2", table_name = "se2_36_db_cvlog", transformation_ctx = "datasource0" )
applymapping1 = ApplyMapping.apply(frame = datasource0, mappings = [("country", "string", "country", "string"), ("month", "int", "month", "int"), ("hour", "int", "hour", "int"), ("year", "int", "year", "int"), ("appid", "int", "appid", "int"), ("deviceid", "string", "deviceid", "string"), ("uuid", "int", "uuid", "int"), ("day", "int", "day", "int")], transformation_ctx = "applymapping1")
resolvechoice2 = ResolveChoice.apply(frame = applymapping1, choice = "make_struct", transformation_ctx = "resolvechoice2")
dropnullfields3 = DropNullFields.apply(frame = resolvechoice2, transformation_ctx = "dropnullfields3")
datasink4 = glueContext.write_dynamic_frame.from_options(frame = dropnullfields3, connection_type = "s3", connection_options = {"path": "s3://test-glue00/se2/out17"}, format = "parquet", transformation_ctx = "datasink4")
job.commit()
ログ確認
MySQL側のクエリログを確認すると、Glueから全件SELECTしている
MySQL [(none)]> select event_time, argument from mysql.general_log order by event_time desc \G
*************************** 32. row ***************************
event_time: 2019-03-10 08:57:02
argument: SELECT `deviceid`,`uuid`,`appid`,`country`,`year`,`month`,`day`,`hour` FROM cvlog
Glueジョブ確認(並列化)
DynamicFrameReaderクラスのfrom_catalogのAdditional optionで、hashfieldを使う。
additional_options – AWS Glue に指定する追加のオプション。並列読み込みを実行する JDBC 接続を使用するには、hashfield、hashexpression、または hashpartitions オプションを設定できます。
今回はhashefieldキーに"country"を指定。(均等に分散しているキーが望ましい)
修正は、以下のオプションを追加したのみ
additional_options = {"hashfield": "country"} )
- hashfield:文字列など数値以外の、指定したカラムをキーにして、ハッシュ化した値をwhereのキーにする
- hashexpression:数値の、指定したカラムをキーにして、ハッシュ化した値をwhereのキーにする
- hashpartitions:JDBC テーブルの並列読み込みの数を hashpartitions に設定します。このプロパティが設定されていない場合、デフォルト値は7
※末尾に公式ドキュメントのリンクあり
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
## @params: [JOB_NAME]
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
datasource0 = glueContext.create_dynamic_frame.from_catalog(database = "se2", table_name = "se2_36_db_cvlog", transformation_ctx = "datasource0", additional_options = {"hashfield": "country"} )
applymapping1 = ApplyMapping.apply(frame = datasource0, mappings = [("country", "string", "country", "string"), ("month", "int", "month", "int"), ("hour", "int", "hour", "int"), ("year", "int", "year", "int"), ("appid", "int", "appid", "int"), ("deviceid", "string", "deviceid", "string"), ("uuid", "int", "uuid", "int"), ("day", "int", "day", "int")], transformation_ctx = "applymapping1")
resolvechoice2 = ResolveChoice.apply(frame = applymapping1, choice = "make_struct", transformation_ctx = "resolvechoice2")
dropnullfields3 = DropNullFields.apply(frame = resolvechoice2, transformation_ctx = "dropnullfields3")
datasink4 = glueContext.write_dynamic_frame.from_options(frame = dropnullfields3, connection_type = "s3", connection_options = {"path": "s3://test-glue00/se2/out17"}, format = "parquet", transformation_ctx = "datasink4")
job.commit()
本オプションはGlueのテーブルプロパティからの適用できる。DynamicFrameでなくても使えるということになる。

ログ確認
MySQL側のクエリログを確認すると、Glueからハッシュ化されたクエリを実行している(並列化されている)
MySQL [(none)]> select event_time, argument from mysql.general_log order by event_time desc \G
*************************** 116. row ***************************
event_time: 2019-03-10 12:53:11
argument: SELECT `deviceid`,`uuid`,`appid`,`country`,`year`,`month`,`day`,`hour` FROM (select * from cvlog WHERE CONV(SUBSTRING(MD5(CONCAT('',country)), -8, 8), 16, 10) % 7 = 2) as cvlog
*************************** 117. row ***************************
event_time: 2019-03-10 12:53:11
argument: SELECT `deviceid`,`uuid`,`appid`,`country`,`year`,`month`,`day`,`hour` FROM (select * from cvlog WHERE CONV(SUBSTRING(MD5(CONCAT('',country)), -8, 8), 16, 10) % 7 = 3) as cvlog
*************************** 118. row ***************************
event_time: 2019-03-10 12:53:11
argument: SELECT `deviceid`,`uuid`,`appid`,`country`,`year`,`month`,`day`,`hour` FROM (select * from cvlog WHERE CONV(SUBSTRING(MD5(CONCAT('',country)), -8, 8), 16, 10) % 7 = 1) as cvlog
*************************** 119. row ***************************
event_time: 2019-03-10 12:53:11
argument: SELECT `deviceid`,`uuid`,`appid`,`country`,`year`,`month`,`day`,`hour` FROM (select * from cvlog WHERE CONV(SUBSTRING(MD5(CONCAT('',country)), -8, 8), 16, 10) % 7 = 0) as cvlog
*************************** 139. row ***************************
event_time: 2019-03-10 12:53:11
argument: SELECT `deviceid`,`uuid`,`appid`,`country`,`year`,`month`,`day`,`hour` FROM (select * from cvlog WHERE CONV(SUBSTRING(MD5(CONCAT('',country)), -8, 8), 16, 10) % 7 = 4) as cvlog
*************************** 143. row ***************************
event_time: 2019-03-10 12:53:11
argument: SELECT `deviceid`,`uuid`,`appid`,`country`,`year`,`month`,`day`,`hour` FROM (select * from cvlog WHERE CONV(SUBSTRING(MD5(CONCAT('',country)), -8, 8), 16, 10) % 7 = 6) as cvlog
*************************** 155. row ***************************
event_time: 2019-03-10 12:53:11
argument: SELECT `deviceid`,`uuid`,`appid`,`country`,`year`,`month`,`day`,`hour` FROM (select * from cvlog WHERE CONV(SUBSTRING(MD5(CONCAT('',country)), -8, 8), 16, 10) % 7 = 5) as cvlog
*************************** 165. row ***************************
event_time: 2019-03-10 12:53:07
argument: SELECT * FROM (select * from cvlog WHERE CONV(SUBSTRING(MD5(CONCAT('',country)), -8, 8), 16, 10) % 7 = 1) as cvlog WHERE 1=0
*************************** 166. row ***************************
event_time: 2019-03-10 12:53:07
argument: SELECT * FROM (select * from cvlog WHERE CONV(SUBSTRING(MD5(CONCAT('',country)), -8, 8), 16, 10) % 7 = 1) as cvlog WHERE 1=0
*************************** 176. row ***************************
event_time: 2019-03-10 12:53:07
argument: SELECT * FROM (select * from cvlog WHERE CONV(SUBSTRING(MD5(CONCAT('',country)), -8, 8), 16, 10) % 7 = 2) as cvlog WHERE 1=0
*************************** 177. row ***************************
event_time: 2019-03-10 12:53:07
argument: SELECT * FROM (select * from cvlog WHERE CONV(SUBSTRING(MD5(CONCAT('',country)), -8, 8), 16, 10) % 7 = 2) as cvlog WHERE 1=0
*************************** 187. row ***************************
event_time: 2019-03-10 12:53:07
argument: SELECT * FROM (select * from cvlog WHERE CONV(SUBSTRING(MD5(CONCAT('',country)), -8, 8), 16, 10) % 7 = 3) as cvlog WHERE 1=0
*************************** 188. row ***************************
event_time: 2019-03-10 12:53:07
argument: SELECT * FROM (select * from cvlog WHERE CONV(SUBSTRING(MD5(CONCAT('',country)), -8, 8), 16, 10) % 7 = 3) as cvlog WHERE 1=0
*************************** 198. row ***************************
event_time: 2019-03-10 12:53:07
argument: SELECT * FROM (select * from cvlog WHERE CONV(SUBSTRING(MD5(CONCAT('',country)), -8, 8), 16, 10) % 7 = 4) as cvlog WHERE 1=0
*************************** 199. row ***************************
event_time: 2019-03-10 12:53:07
argument: SELECT * FROM (select * from cvlog WHERE CONV(SUBSTRING(MD5(CONCAT('',country)), -8, 8), 16, 10) % 7 = 4) as cvlog WHERE 1=0
*************************** 209. row ***************************
event_time: 2019-03-10 12:53:07
argument: SELECT * FROM (select * from cvlog WHERE CONV(SUBSTRING(MD5(CONCAT('',country)), -8, 8), 16, 10) % 7 = 5) as cvlog WHERE 1=0
*************************** 210. row ***************************
event_time: 2019-03-10 12:53:07
argument: SELECT * FROM (select * from cvlog WHERE CONV(SUBSTRING(MD5(CONCAT('',country)), -8, 8), 16, 10) % 7 = 5) as cvlog WHERE 1=0
*************************** 220. row ***************************
event_time: 2019-03-10 12:53:07
argument: SELECT * FROM (select * from cvlog WHERE CONV(SUBSTRING(MD5(CONCAT('',country)), -8, 8), 16, 10) % 7 = 6) as cvlog WHERE 1=0
*************************** 221. row ***************************
event_time: 2019-03-10 12:53:07
argument: SELECT * FROM (select * from cvlog WHERE CONV(SUBSTRING(MD5(CONCAT('',country)), -8, 8), 16, 10) % 7 = 6) as cvlog WHERE 1=0
*************************** 231. row ***************************
event_time: 2019-03-10 12:53:06
argument: SELECT * FROM (select * from cvlog WHERE CONV(SUBSTRING(MD5(CONCAT('',country)), -8, 8), 16, 10) % 7 = 0) as cvlog WHERE 1=0
*************************** 232. row ***************************
event_time: 2019-03-10 12:53:06
argument: SELECT * FROM (select * from cvlog WHERE CONV(SUBSTRING(MD5(CONCAT('',country)), -8, 8), 16, 10) % 7 = 0) as cvlog WHERE 1=0
件数が少なすぎて分かりづらいが分散してる
MySQL [db]> SELECT `deviceid`,`uuid`,`appid`,`country`,`year`,`month`,`day`,`hour` FROM (select * from cvlog WHERE CONV(SUBSTRING(MD5(CONCAT('',country)), -8, 8), 16, 10) % 7 = 0) as cvlog
-> ;
+----------+-------+-------+---------+------+-------+------+------+
| deviceid | uuid | appid | country | year | month | day | hour |
+----------+-------+-------+---------+------+-------+------+------+
| andro | 11112 | 1 | FR | 2017 | 12 | 14 | 14 |
| iphon | 11113 | 9 | FR | 2017 | 12 | 16 | 21 |
| iphon | 11114 | 7 | AUS | 2017 | 12 | 17 | 18 |
| pc | 11118 | 1 | FR | 2017 | 12 | 1 | 1 |
| pc | 11117 | 9 | FR | 2017 | 12 | 2 | 18 |
| iphon | 11119 | 7 | AUS | 2017 | 11 | 21 | 14 |
| andro | 11122 | 1 | FR | 2017 | 11 | 30 | 20 |
| iphon | 11123 | 9 | FR | 2017 | 11 | 14 | 14 |
| iphon | 11124 | 7 | AUS | 2017 | 12 | 17 | 14 |
| andro | 11127 | 1 | FR | 2017 | 12 | 19 | 14 |
| iphon | 11128 | 9 | FR | 2017 | 12 | 9 | 4 |
| iphon | 11129 | 7 | AUS | 2017 | 11 | 30 | 14 |
+----------+-------+-------+---------+------+-------+------+------+
12 rows in set (0.00 sec)
MySQL [db]> SELECT * FROM (select * from cvlog WHERE CONV(SUBSTRING(MD5(CONCAT('',country)), -8, 8), 16, 10) % 7 = 1) as cvlog WHERE 1=0;
Empty set (0.00 sec)
MySQL [db]> SELECT `deviceid`,`uuid`,`appid`,`country`,`year`,`month`,`day`,`hour` FROM (select * from cvlog WHERE CONV(SUBSTRING(MD5(CONCAT('',country)), -8, 8), 16, 10) % 7 = 1) as cvlog;
+----------+-------+-------+---------+------+-------+------+------+
| deviceid | uuid | appid | country | year | month | day | hour |
+----------+-------+-------+---------+------+-------+------+------+
| iphon | 11111 | 1 | JP | 2017 | 12 | 14 | 12 |
| other | 11115 | 5 | JP | 2017 | 12 | 29 | 15 |
| iphon | 11116 | 1 | JP | 2017 | 12 | 15 | 11 |
| other | 11110 | 5 | JP | 2017 | 11 | 29 | 15 |
| iphon | 11121 | 1 | JP | 2017 | 11 | 11 | 12 |
| iphon | 11125 | 5 | JP | 2017 | 11 | 29 | 15 |
| iphon | 11126 | 1 | JP | 2017 | 12 | 19 | 8 |
+----------+-------+-------+---------+------+-------+------+------+
7 rows in set (0.00 sec)
MySQL [db]> SELECT * FROM (select * from cvlog WHERE CONV(SUBSTRING(MD5(CONCAT('',country)), -8, 8), 16, 10) % 7 = 2) as cvlog WHERE 1=0;
Empty set (0.00 sec)
MySQL [db]> SELECT `deviceid`,`uuid`,`appid`,`country`,`year`,`month`,`day`,`hour` FROM (select * from cvlog WHERE CONV(SUBSTRING(MD5(CONCAT('',country)), -8, 8), 16, 10) % 7 = 2) as cvlog;
出力確認
Athenaで確認し、どちらのGlueジョブでも結果は変わらない

こちらも是非
JDBC テーブルから並列読み取り
https://docs.aws.amazon.com/ja_jp/glue/latest/dg/run-jdbc-parallel-read-job.html
DynamicFrameReader クラス
https://docs.aws.amazon.com/ja_jp/glue/latest/dg/aws-glue-api-crawler-pyspark-extensions-dynamic-frame-reader.html
Glueの使い方まとめ
https://qiita.com/pioho07/items/32f76a16cbf49f9f712f