Glueから、RDSやRDB on EC2にJDBC接続してデータを読み込む際、必要なデータをwhere句で指定して読み込む
今回実施する構成図は以下のような感じになります。RedshiftをRDSに置き換えて見てください。
GlueからRDSのデータを読み込みCSVにしてS3に出力します。
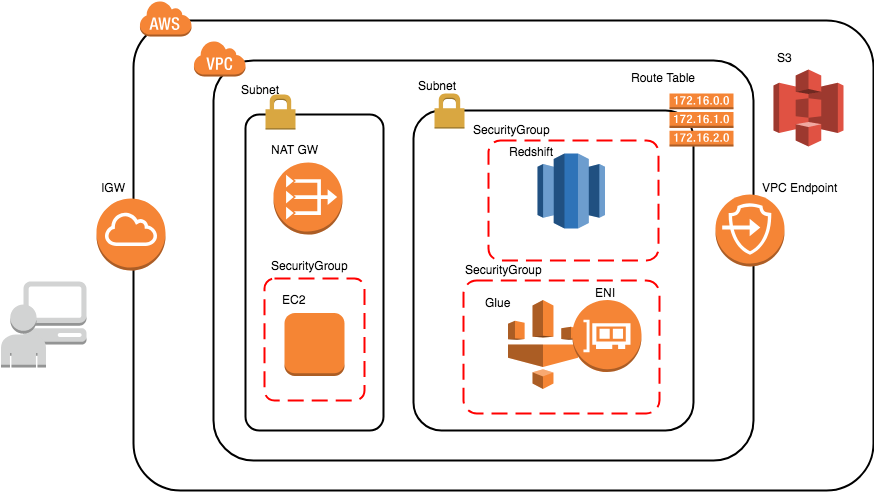
全体の流れ
- 前準備
- Glueジョブ作成
- 出力確認
前準備
自己参照セキュリティグループとClue Connectionの作成。これらの作り方や意味合いはこちらを参照ください。
https://qiita.com/pioho07/items/05c912333e88788a1391
https://qiita.com/pioho07/items/3a07cf6dccb8dfe046ff
RDSを作成し、テーブル、スキーマ、データインポート。作業は割愛します。クエリの確認が必要ならRDSのパラメータグループでgeneral_logを1にしておく。
インポートデータは以下
- カラム情報
deviceid,uuid,appid,country,year,month,day,hour
deviceid,uuid,appid,country,year,month,day,hour
iphone,11111,001,JP,2017,12,14,12
android,11112,001,FR,2017,12,14,14
iphone,11113,009,FR,2017,12,16,21
iphone,11114,007,AUS,2017,12,17,18
other,11115,005,JP,2017,12,29,15
iphone,11116,001,JP,2017,12,15,11
pc,11118,001,FR,2017,12,01,01
pc,11117,009,FR,2017,12,02,18
iphone,11119,007,AUS,2017,11,21,14
other,11110,005,JP,2017,11,29,15
iphone,11121,001,JP,2017,11,11,12
android,11122,001,FR,2017,11,30,20
iphone,11123,009,FR,2017,11,14,14
iphone,11124,007,AUS,2017,12,17,14
iphone,11125,005,JP,2017,11,29,15
iphone,11126,001,JP,2017,12,19,08
android,11127,001,FR,2017,12,19,14
iphone,11128,009,FR,2017,12,09,04
iphone,11129,007,AUS,2017,11,30,14
RDS側でselectして確認
MySQL [db]> select * from cvlog;
+----------+-------+-------+---------+------+-------+------+------+
| deviceid | uuid | appid | country | year | month | day | hour |
+----------+-------+-------+---------+------+-------+------+------+
| iphon | 11111 | 1 | JP | 2017 | 12 | 14 | 12 |
| andro | 11112 | 1 | FR | 2017 | 12 | 14 | 14 |
| iphon | 11113 | 9 | FR | 2017 | 12 | 16 | 21 |
| iphon | 11114 | 7 | AUS | 2017 | 12 | 17 | 18 |
| other | 11115 | 5 | JP | 2017 | 12 | 29 | 15 |
| iphon | 11116 | 1 | JP | 2017 | 12 | 15 | 11 |
| pc | 11118 | 1 | FR | 2017 | 12 | 1 | 1 |
| pc | 11117 | 9 | FR | 2017 | 12 | 2 | 18 |
| iphon | 11119 | 7 | AUS | 2017 | 11 | 21 | 14 |
| other | 11110 | 5 | JP | 2017 | 11 | 29 | 15 |
| iphon | 11121 | 1 | JP | 2017 | 11 | 11 | 12 |
| andro | 11122 | 1 | FR | 2017 | 11 | 30 | 20 |
| iphon | 11123 | 9 | FR | 2017 | 11 | 14 | 14 |
| iphon | 11124 | 7 | AUS | 2017 | 12 | 17 | 14 |
| iphon | 11125 | 5 | JP | 2017 | 11 | 29 | 15 |
| iphon | 11126 | 1 | JP | 2017 | 12 | 19 | 8 |
| andro | 11127 | 1 | FR | 2017 | 12 | 19 | 14 |
| iphon | 11128 | 9 | FR | 2017 | 12 | 9 | 4 |
| iphon | 11129 | 7 | AUS | 2017 | 11 | 30 | 14 |
+----------+-------+-------+---------+------+-------+------+------+
MySQL [db]> show create table cvlog\G
*************************** 1. row ***************************
Table: cvlog
Create Table: CREATE TABLE `cvlog` (
`deviceid` varchar(5) DEFAULT NULL,
`uuid` int(11) DEFAULT NULL,
`appid` int(11) DEFAULT NULL,
`country` varchar(5) DEFAULT NULL,
`year` int(11) DEFAULT NULL,
`month` int(11) DEFAULT NULL,
`day` int(11) DEFAULT NULL,
`hour` int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1
MySQL JDBC Driverをこの辺からダウンロード
http://central.maven.org/maven2/mysql/mysql-connector-java/5.1.38/
mysql-connector-java-5.1.38.jar
S3の任意の場所にアップロードしておく
S3://test-glue00/se2/lib/
Glueジョブ作成
ジョブ作成時にドライバのjarファイルを指定
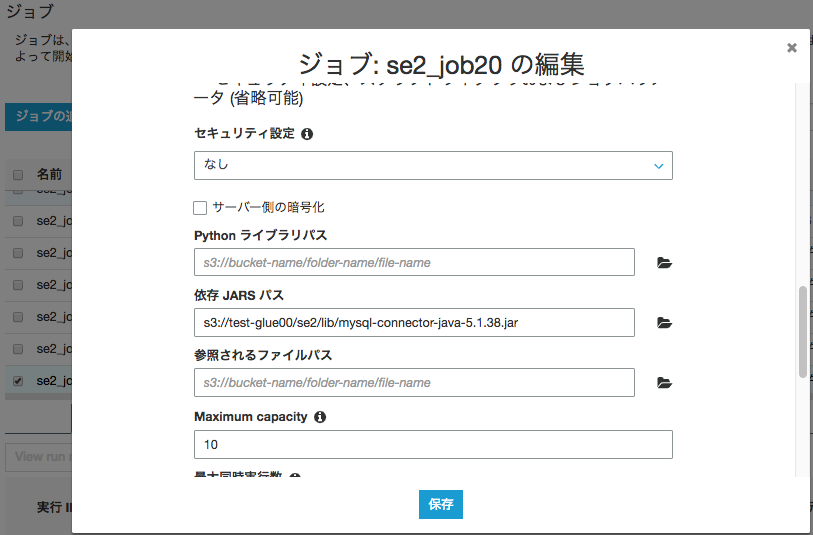
以下のコードでジョブを作成し実行します。
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from pyspark.sql import SQLContext
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
sqlContext = SQLContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
query = "(select * from cvlog where country = 'JP') t1_alias"
df1 = sqlContext.read.format('jdbc').options(
url='jdbc:mysql://<RDSのエンドポイント>/db',
driver='com.mysql.jdbc.Driver',
dbtable=query,
user='admin',
password='<password>').load()
df1.write.mode('overwrite').csv("s3://test-glue00/se2/out16/")
job.commit()
出力確認
CSVファイルが出力される

S3 Selectで確認。Whereで指定したcountry=JPの行だけ出力されている。

ログ確認
クエリログにも指定したwhere句でクエリが実行されてた
MySQL [(none)]> select event_time, argument from mysql.general_log order by event_time desc \G
*************************** 92. row ***************************
event_time: 2019-02-11 08:28:55
argument: SELECT `deviceid`,`uuid`,`appid`,`country`,`year`,`month`,`day`,`hour` FROM (select * from cvlog where country = 'JP') t1_alias
こちらも是非
Glueの使い方的な㉕(S3からRedshiftにロード_実行編)
https://qiita.com/pioho07/items/3a07cf6dccb8dfe046ff
JDBC データストアに接続するための VPC の設定
https://docs.aws.amazon.com/ja_jp/glue/latest/dg/setup-vpc-for-glue-access.html
Glueの使い方まとめ
https://qiita.com/pioho07/items/32f76a16cbf49f9f712f