DataFrameでCSVをXMLで出力するジョブを作る
ジョブの内容
Glue、というか多分DynamicFrameが、
XMLの入力には対応していますが、出力には対応していません。
現在、AWS Glue は出力用に "xml" をサポートしていません。
DataFrameを使ってXML出力するにはdatabricksが作ったライブラリなどが必要です。DataFrameを使ってのXML出力をやってみます
※"Glueの使い方的な①(GUIでジョブ実行)"(以後①とだけ書きます)とほぼ同じ処理
"今回は出力をXML形式にします"
その際に以下のjarを使う
spark-xml_2.11-0.5.0.jar
Glueのv0.9はSpark2.2、v1.0はSpark2.4
| Glue | Spark | Python |
|---|---|---|
| 0.9 | 2.2.1 | 2.7 |
| 1.0 | 2.4.3 | 3.6 |
https://github.com/databricks/spark-xml
今回はGlueのv0.9(Sparkバージョンは2.2.1)を使うので、requirement通りspark-xmlはv0.5.xを使います
Requirements
| spark-xml | Spark |
|---|---|
| 0.6.x+ | 2.3.x+ |
| 0.5.x | 2.2.x - 2.4.x |
| 0.4.x | 2.0.x - 2.1.x |
| 0.3.x | 1.x |
ジョブ名
se2_job26
全体の流れ
- 前準備
- ジョブ作成と修正
- ジョブ実行と確認
前準備
jarファイルダウンロード
このあたりからdatabricksのspark-xml_2.11-0.5.0.jarをダウンロードし、s3の s3://test-glue00/se2/lib/ にアップロードしておく。
ここにあるものを使いました。
https://repo1.maven.org/maven2/com/databricks/spark-xml_2.11/0.5.0/
ソースデータ(19件)
※①と同じデータ
deviceid,uuid,appid,country,year,month,day,hour
iphone,11111,001,JP,2017,12,14,12
android,11112,001,FR,2017,12,14,14
iphone,11113,009,FR,2017,12,16,21
iphone,11114,007,AUS,2017,12,17,18
other,11115,005,JP,2017,12,29,15
iphone,11116,001,JP,2017,12,15,11
pc,11118,001,FR,2017,12,01,01
pc,11117,009,FR,2017,12,02,18
iphone,11119,007,AUS,2017,11,21,14
other,11110,005,JP,2017,11,29,15
iphone,11121,001,JP,2017,11,11,12
android,11122,001,FR,2017,11,30,20
iphone,11123,009,FR,2017,11,14,14
iphone,11124,007,AUS,2017,12,17,14
iphone,11125,005,JP,2017,11,29,15
iphone,11126,001,JP,2017,12,19,08
android,11127,001,FR,2017,12,19,14
iphone,11128,009,FR,2017,12,09,04
iphone,11129,007,AUS,2017,11,30,14
ジョブ作成と修正
ジョブ作成の細かい手順は②をご参照ください。以下の部分を修正します。
- 依存jarパス:s3://test-glue00/se2/lib/

処理内容は"S3の指定した場所に配置したcsvデータを、パーティション化し、指定した場所にXMLとして出力する"です。結果としてパーティション化はできませんでした(後述します)。
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
## @params: [JOB_NAME]
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
### add
sc._jsc.hadoopConfiguration().set("mapred.output.committer.class", "org.apache.hadoop.mapred.FileOutputCommitter")
datasource0 = glueContext.create_dynamic_frame.from_catalog(database = "se2", table_name = "se2_in0", transformation_ctx = "datasource0")
applymapping1 = ApplyMapping.apply(frame = datasource0, mappings = [("deviceid", "string", "deviceid", "string"), ("uuid", "long", "uuid", "long"), ("appid", "long", "appid", "long"), ("country", "string", "country", "string"), ("year", "long", "year", "long"), ("month", "long", "month", "long"), ("day", "long", "day", "long"), ("hour", "long", "hour", "long")], transformation_ctx = "applymapping1")
resolvechoice2 = ResolveChoice.apply(frame = applymapping1, choice = "make_struct", transformation_ctx = "resolvechoice2")
dropnullfields3 = DropNullFields.apply(frame = resolvechoice2, transformation_ctx = "dropnullfields3")
df = dropnullfields3.toDF()
partitionby=['year','month','day','hour']
output='s3://test-glue00/se2/out19/'
### Add
df.write.format('com.databricks.spark.xml').partitionBy(partitionby).option('rootTag', 'root').option('rowTag', 'item').mode("overwrite").save(output)
job.commit()
以下の部分を修正します。
Hadoopの設定を追加しています。
"mapred.output.committer.class"にFileOutputCommitterを使用する
これを入れないと"Class org.apache.hadoop.mapred.DirectOutputCommitter not found"というエラーが出ます。
#### add
sc._jsc.hadoopConfiguration().set("mapred.output.committer.class", "org.apache.hadoop.mapred.FileOutputCommitter")
formatを'com.databricks.spark.xml'としています
optionでrootTagとrowTagを指定しています
partitionByでパーティション化しようとしましたができませんでした(後述します)
df.write.format('com.databricks.spark.xml').partitionBy(partitionby).option('rootTag', 'root').option('rowTag', 'item').mode("overwrite").save(output)
ジョブ実行と確認
ジョブ実行
対象ジョブにチェックを入れ、ActionからRun jobをクリックしジョブ実行します。
ファイルもXMLとして出力されていますが、パーティション分割はされませんでした。
以下のIssueにあるようにspark-xmlがパーティションには対応していないようです。(20191126,最新の0.7とかでもダメでした)
https://github.com/databricks/spark-xml/issues/327
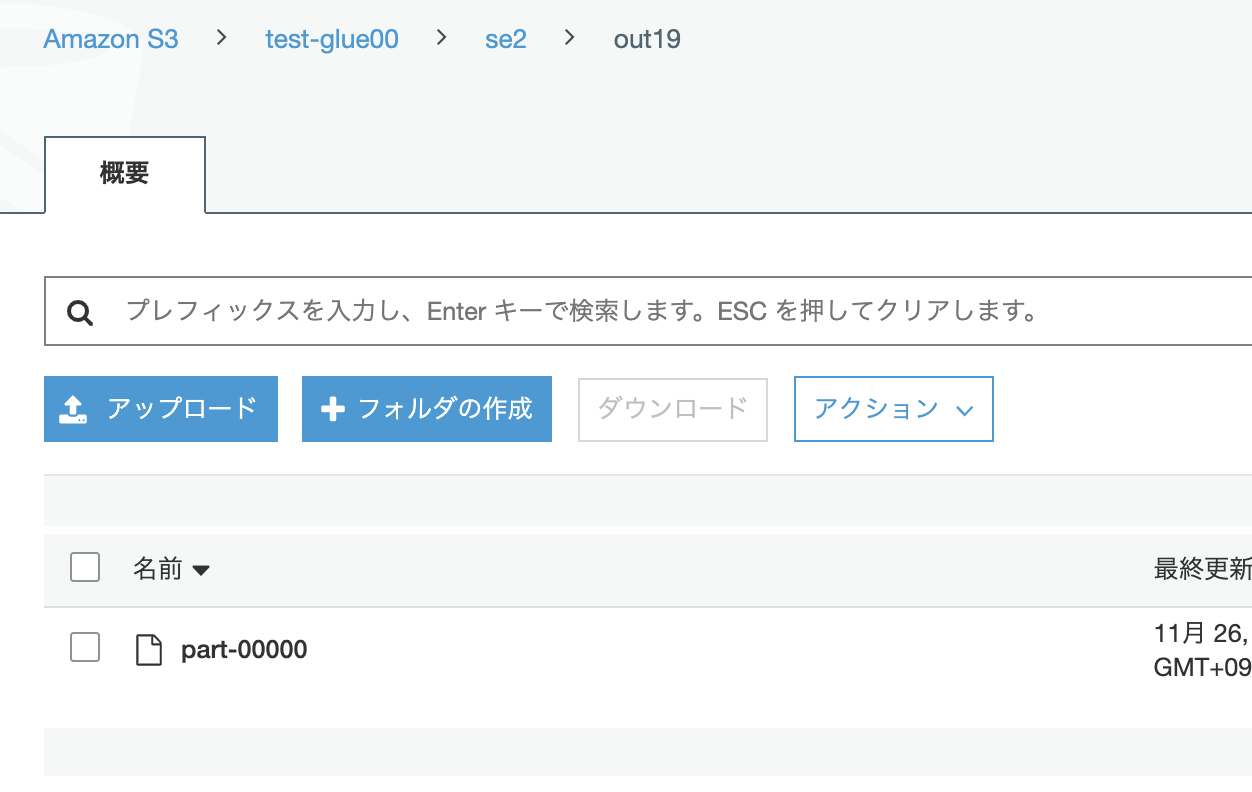
ファイルをダウンロードしてエディタで開きXMLファイルとして出力はされています

こちらも是非
Glueの使い方まとめ
https://qiita.com/pioho07/items/32f76a16cbf49f9f712f