Glue Data Catalogのバックアップとリストアをしてみる
概要
githubで公開している上記ツールを使うと以下ができます。
- "Hive on EMRかHive on EC2のメタストア"を"RDSやEC2のMySQL"に保存しているデータ <==> Glue Data Catalog上のメタストアのデータ
(MySQLに直接接続パターンとS3に一度出力するパターンがあります) - Data Catalogを他のAWSアカウントのData Catalogに移行
よくあるケースとしては、既存のEMRのHiveメタ情報をGlue Data Catalogに移行やその逆方向で使うのですが、
Glue Data CatalogからS3にデータ出力ができるので、これはバックアップにも使えるではないかと思い試してみました。
このツールの制約
- データベース、テーブル、およびパーティションだけを移行できます。列統計、特権、ロール、ファンクション、トランザクションなどの他のエンティティは移行できません。
- レプリみたいな使い方はできない
- バックアップ時に静止点は取れない
ジョブ名
- se2_bk
(se2のデータベースをS3にバックアップ) - se2_restore
(S3に取得したse2のデータベースのバックアップをリストア)
バックアップリストア対象Database名
- se2
全体の流れ
- 事前準備
- バックアップジョブ作成と実行
- リストアジョブ作成と実行
前準備
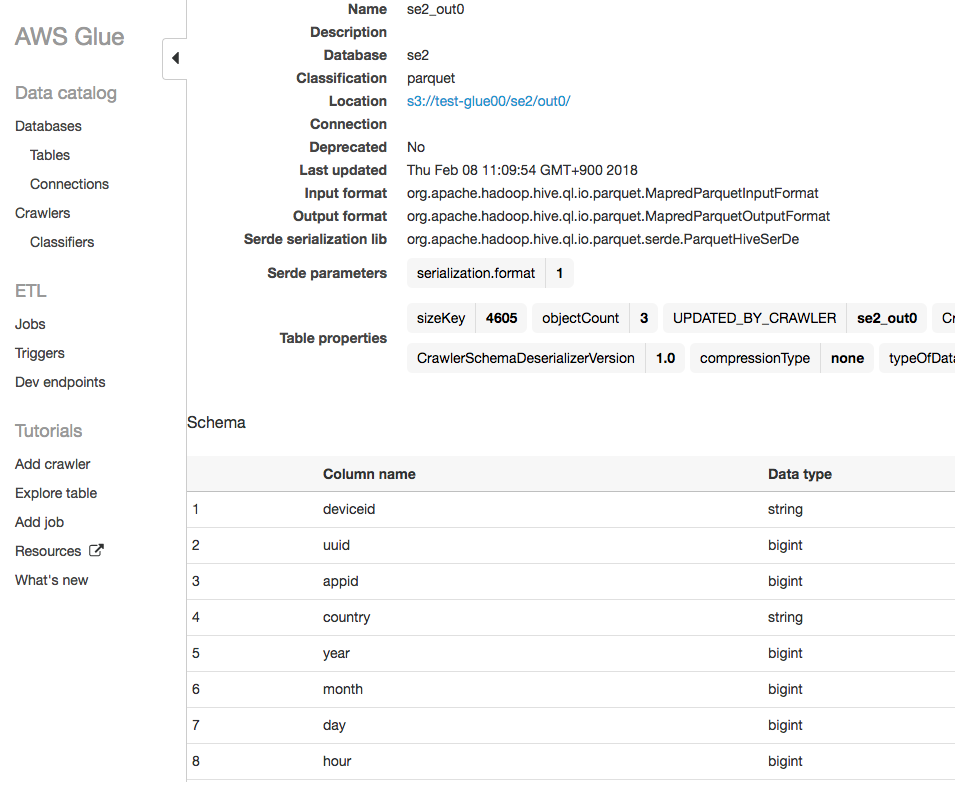
現在のテーブルの内容を確認
以下のような情報です
Database:se2
Table:se2_out0
この状態でバックアップを取得し、Schema情報に修正を加え、バックアップからのリストアで復元できることを確認します。
コードをS3にアップしておく
https://github.com/awslabs/aws-glue-samples/tree/master/utilities/Hive_metastore_migration
ここにある以下のコードをS3の任意の場所にアップロードしておきます。
export_from_datacatalog.py
hive_metastore_migration.py
import_into_datacatalog.py
git cloneしてスクリプトをアップ
$ git clone https://github.com/awslabs/aws-glue-samples.git
$ cd aws-glue-samples/utilities/Hive_metastore_migration/src
$ ls
__init__.py hive_metastore_migration.py
export_from_datacatalog.py import_into_datacatalog.py
$ aws s3 cp ./ s3://test-glue00/script/ --exclude "*" --include "*.py" --recursive
バックアップジョブの作成と実行
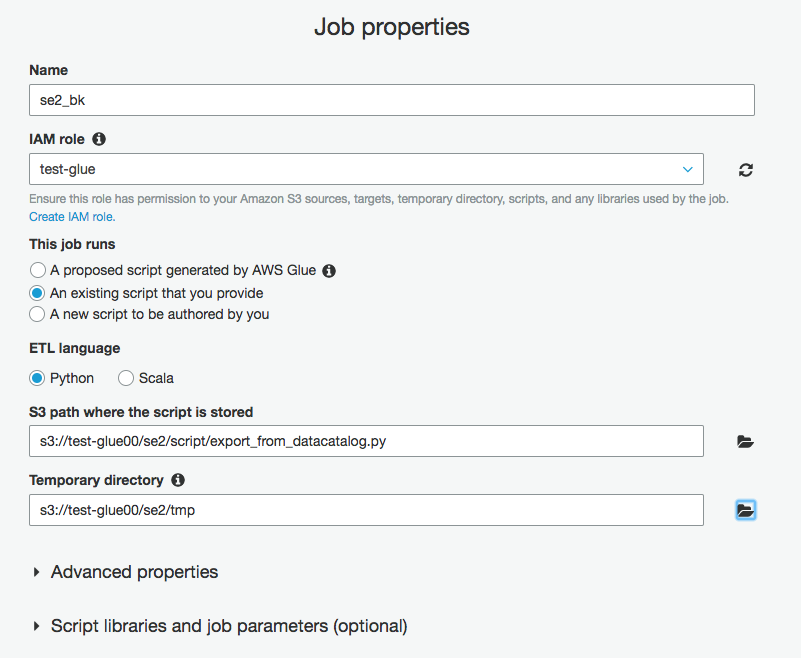
GlueメニューのJobsから"Add job"をクリックし
ジョブ名をse2_bk
IAMロールは権限があるものを選択。なければ作成しておく。
※不明な場合は以下参考ください
https://qiita.com/pioho07/items/c9ce1d0677777f974ffe
This job runsを"An existing script that you provide"にチェックを入れ、
アップロードしたコードで、以下のData Catalogからエクスポートするコードのパスを入力
s3://test-glue00/se2/script/export_from_datacatalog.py
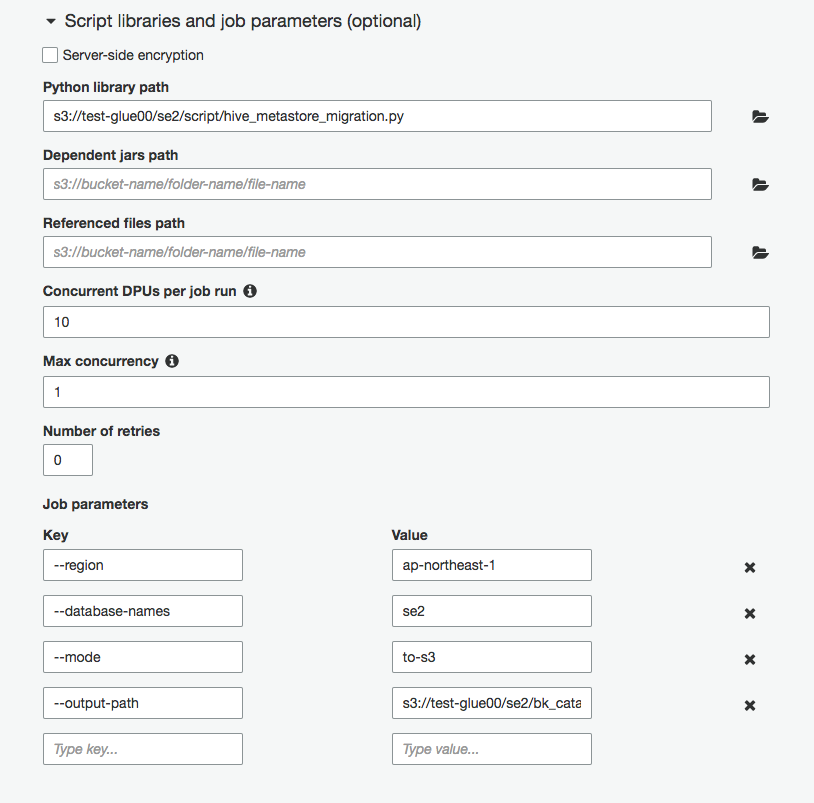
画面下部の"Script libraries and job parameters (optional)"をクリックし、
Python library pathに以下のパスを入力
s3://test-glue00/se2/script/hive_metastore_migration.py
ジョブ実行時の引数を付ける
--mode: to-s3
--region: ap-northeast-1
--database-names: se2
--output-path: s3://test-glue00/se2/bk_catalog/
こちらは補足としてオプションの内容
--mode set to to-s3, which means the migration is to S3.
--region the AWS region for Glue Data Catalog, for example, us-east-1. You can find a list of Glue supported regions here: http://docs.aws.amazon.com/general/latest/gr/rande.html#glue_region. If not provided, us-east-1 is used as default.
--database-names set to a semi-colon(;) separated list of database names to export from Data Catalog.
--output-path set to the S3 destination path that you configured with cross-account access.
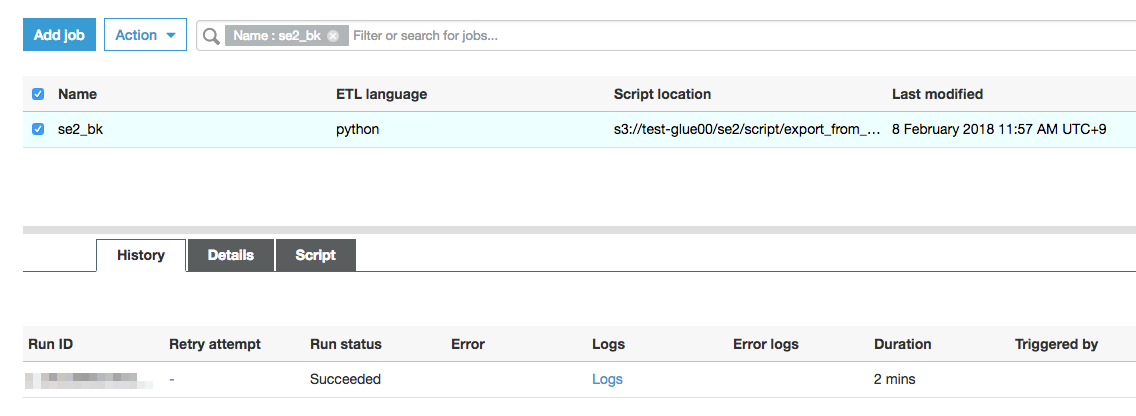
"Next"->"Next"->"Finish"、これでジョブ実行します。
ジョブ成功
S3出力確認
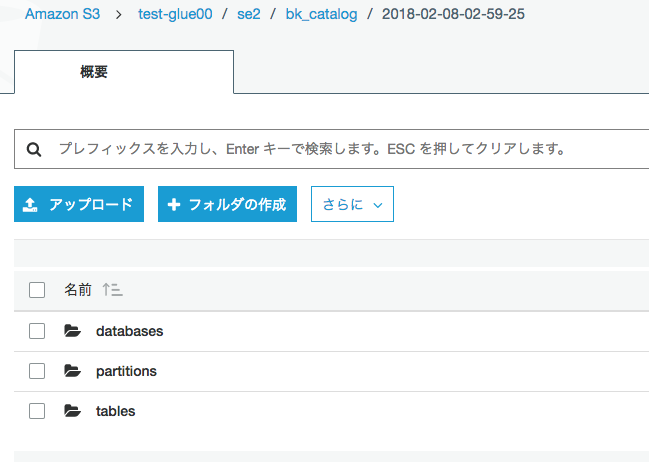
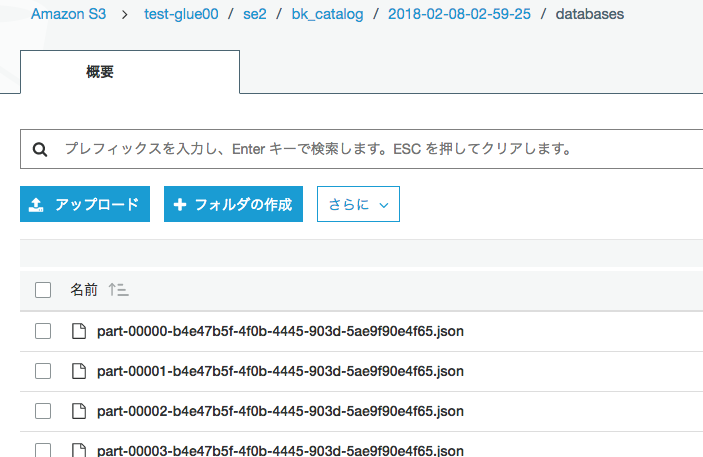
リストアジョブ作成と実行
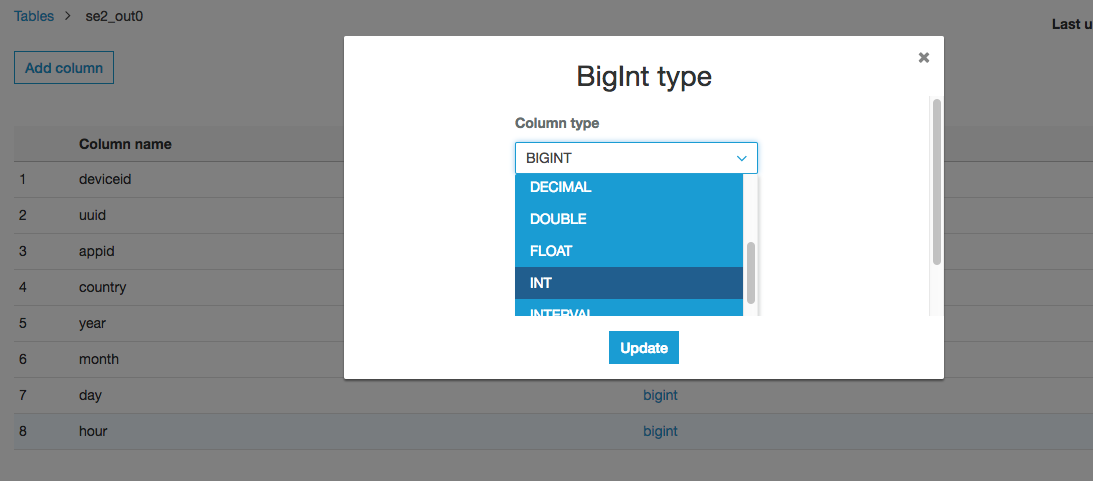
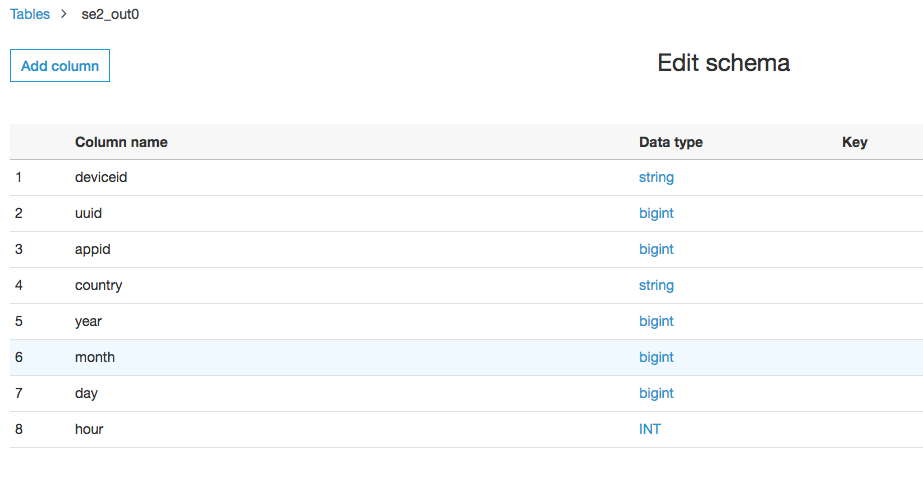
リストアを確認するためにスキーマの一部を変更しておきます。
Database:se2
Table:se2_out0
hourのカラムをbitint->intに変更しました。
リストアジョブ作成
GlueメニューのJobsから"Add job"をクリックし
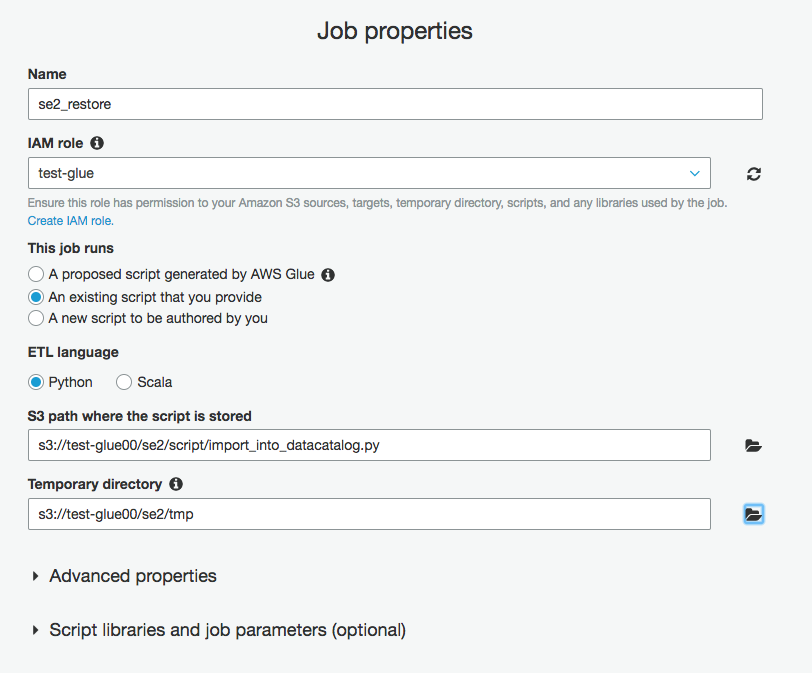
ジョブ名をse2_restore
IAMロールは権限があるものを選択。なければ作成しておく。
※不明な場合は以下参考ください
https://qiita.com/pioho07/items/c9ce1d0677777f974ffe
This job runsを"An existing script that you provide"にチェックを入れ、
アップロードしたコードで、以下のData Catalogからエクスポートするコードのパスを入力
s3://test-glue00/se2/script/import_into_datacatalog.py
画面下部の"Script libraries and job parameters (optional)"をクリックし、
Python library pathに以下のパスを入力
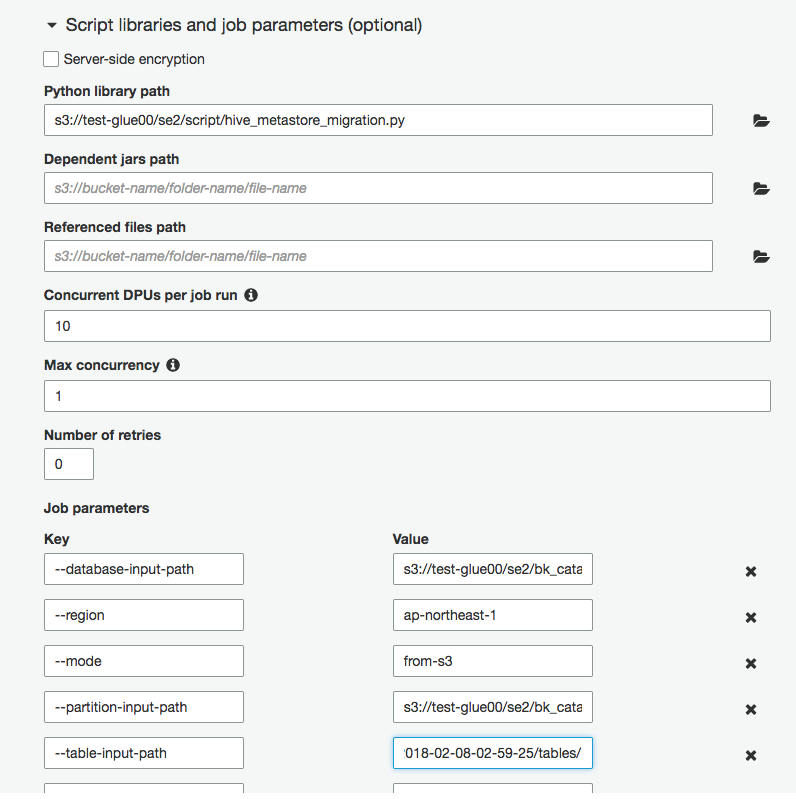
s3://test-glue00/se2/script/hive_metastore_migration.py
ジョブ実行時の引数を付ける
--mode: from-s3
--region: ap-northeast-1
--database-input-path: s3://test-glue00/se2/bk_catalog/2018-02-08-02-59-25/databases/
--partition-input-path: s3://test-glue00/se2/bk_catalog/2018-02-08-02-59-25/partitions/
--table-input-path: s3://test-glue00/se2/bk_catalog/2018-02-08-02-59-25/tables/
こちらは補足としてオプションの内容
--mode set to from-s3
--region the AWS region for Glue Data Catalog, for example, us-east-1. You can find a list of Glue supported regions here: http://docs.aws.amazon.com/general/latest/gr/rande.html#glue_region. If not provided, us-east-1 is used as default.
--database-input-path set to the S3 path containing only databases.
--table-input-path set to the S3 path containing only tables.
--partition-input-path set to the S3 path containing only partitions.
"Next"->"Next"->"Finish"、これでジョブ実行します。
ジョブ成功
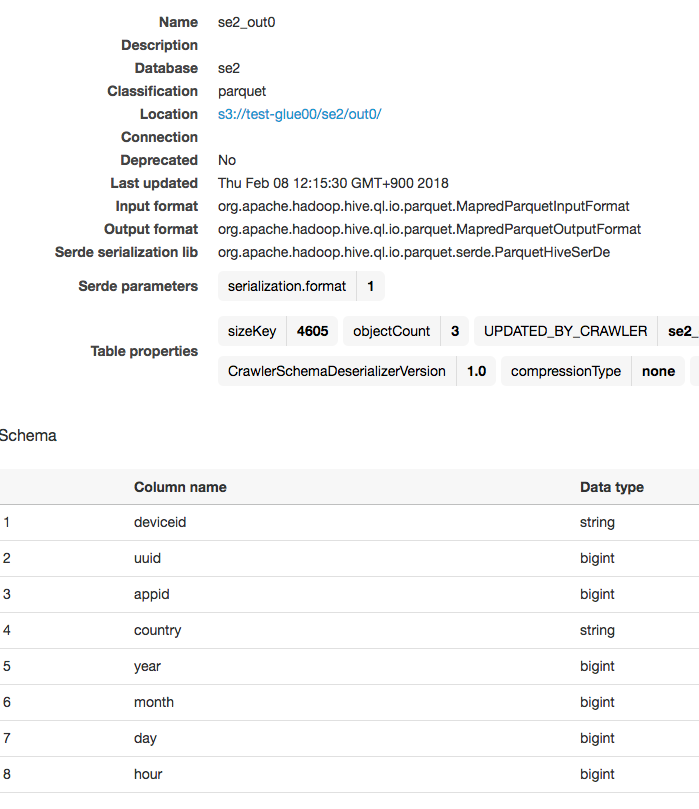
確認
hourの型がintからbigintに戻っていてリストアが成功しています。パパっとできたわりになんだかうれしいです。
こういう時は"Compare versions"で

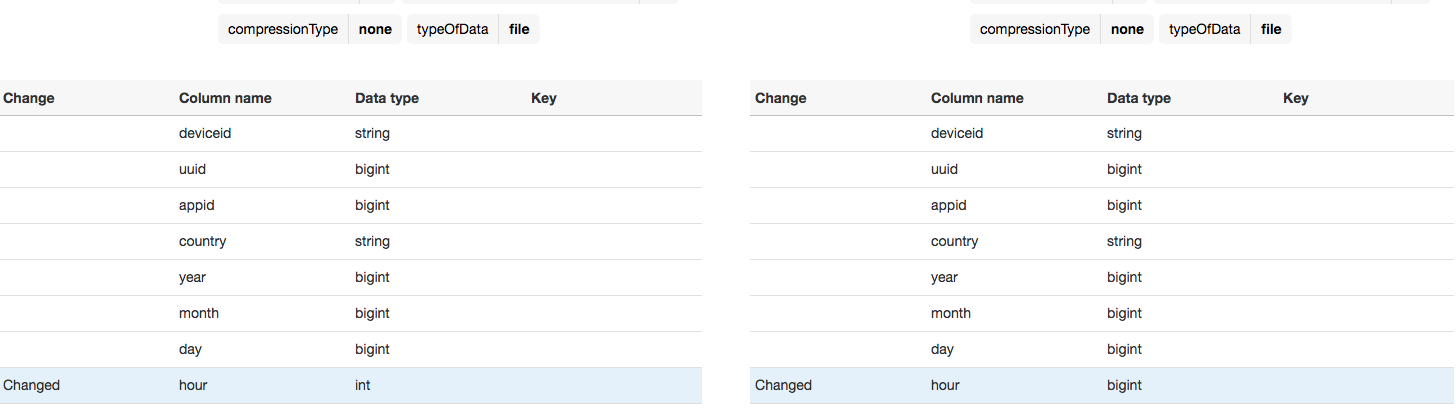
Databaseのse2ごと消しても問題なくリストアできました
To Be Continue
TODO
参考資料
Glueの使い方まとめ
https://qiita.com/pioho07/items/32f76a16cbf49f9f712f