概要
DynamicFrameのPre-Filtering機能でS3からロードする入力データを特定パーティションだけに絞る。
https://docs.aws.amazon.com/glue/latest/dg/aws-glue-programming-etl-partitions.html
特定パーティションだけロードするジョブを作る
ジョブの内容
S3から特定パーティションだけデータをロードし、それ以外のフォーマットやパーティションなども入力時のまま出力する
※"Glueの使い方的な②(csvデータをパーティション分割したparquetに変換)"(以後②とだけ書きます)の出力データを入力データに使います。
この時の出力データは、year,month,day,hourでパーティションされた入力データをcountry,year,month,day,hourでパーティションし出力している。フォーマットはparquetにしている。(データの内容は後述する)
ジョブ名
se2_job8
クローラー名
se2_in5
se2_out7
全体の流れ
- 前準備
- ジョブ作成
- ジョブ実行と確認
- 出力データのクローラー作成、実行、Athenaで確認
- 複数パーティションで試す
前準備
ソースデータ(19件)
※データの内容は以下の通りですが、②で行った処理によりcountry,year,month,day,hourでパーティションが切られています。
deviceid,uuid,appid,country,year,month,day,hour
iphone,11111,001,JP,2017,12,14,12
android,11112,001,FR,2017,12,14,14
iphone,11113,009,FR,2017,12,16,21
iphone,11114,007,AUS,2017,12,17,18
other,11115,005,JP,2017,12,29,15
iphone,11116,001,JP,2017,12,15,11
pc,11118,001,FR,2017,12,01,01
pc,11117,009,FR,2017,12,02,18
iphone,11119,007,AUS,2017,11,21,14
other,11110,005,JP,2017,11,29,15
iphone,11121,001,JP,2017,11,11,12
android,11122,001,FR,2017,11,30,20
iphone,11123,009,FR,2017,11,14,14
iphone,11124,007,AUS,2017,12,17,14
iphone,11125,005,JP,2017,11,29,15
iphone,11126,001,JP,2017,12,19,08
android,11127,001,FR,2017,12,19,14
iphone,11128,009,FR,2017,12,09,04
iphone,11129,007,AUS,2017,11,30,14
Athenaで確認するとこう
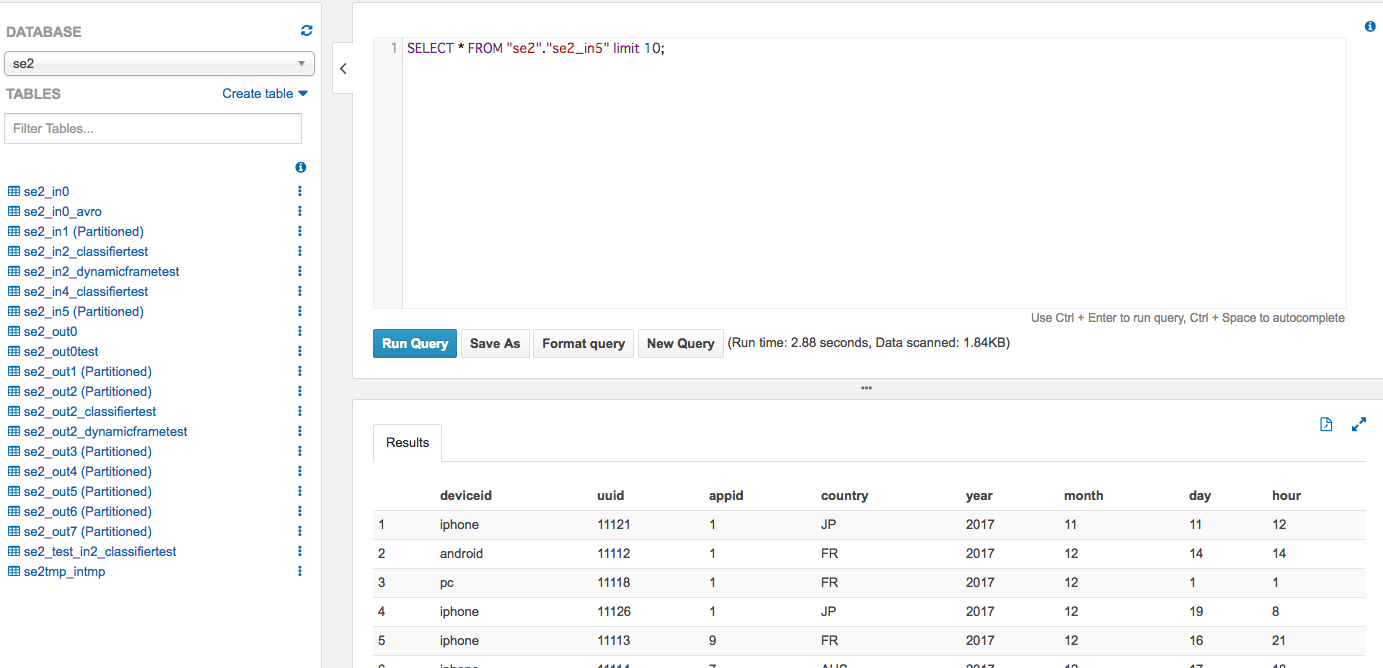
Glueでテーブルの内容確認するとこう
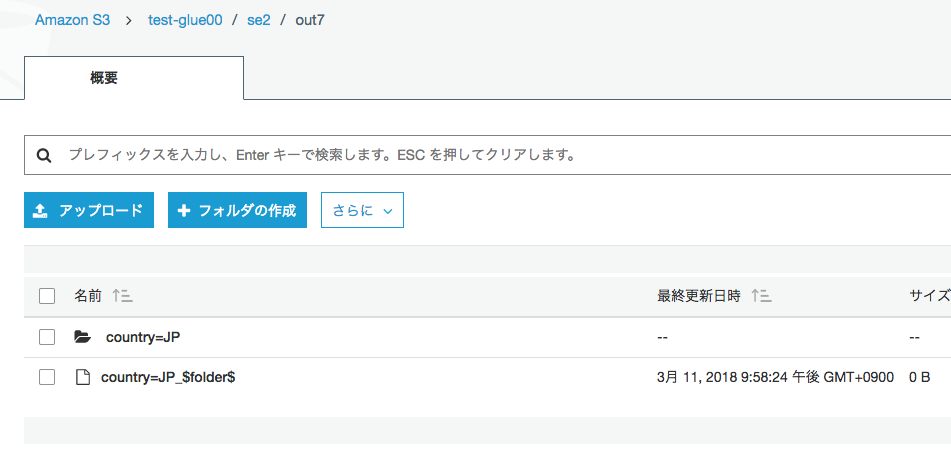
S3で確認するとこう
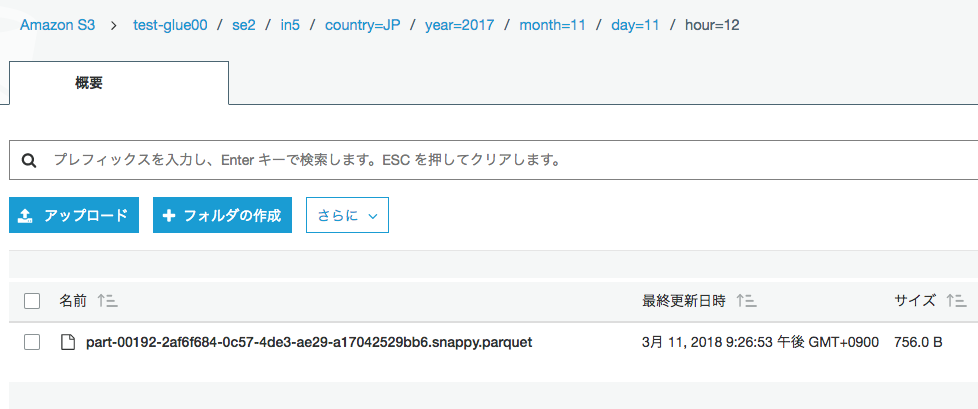
データの配置
$ aws s3 ls s3://test-glue00/se2/in5/
PRE country=AUS/
PRE country=FR/
PRE country=JP/
2018-03-10 21:08:48 0
2018-03-11 21:26:49 417 _common_metadata
2018-03-11 21:26:49 9350 _metadata
2018-03-11 21:26:49 0 country=AUS_$folder$
2018-03-11 21:26:49 0 country=FR_$folder$
2018-03-11 21:26:49 0 country=JP_$folder$
S3のディレクトリ構成
Glueジョブの入力データは"in0"ディレクトリ配下、出力は"out7"ディレクトリ配下(表示は一部省略しています)
$ aws s3 ls s3://test-glue00/se2/
PRE in5/
PRE out7/
PRE out1/
PRE script/
PRE tmp/
入力テーブルのクローラー
以下の手順で、"s3://test-glue00/se2/in5/"をクロールするクローラーを作成します。
Crawler nameに"se2_in5"を入力
入力データのS3パスを入力
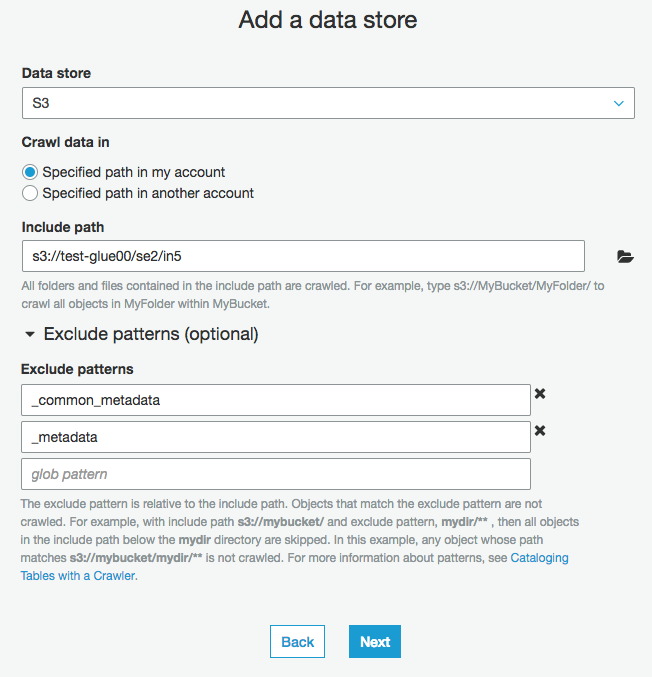
そのまま"Next"をクリック
IAM roleに”test-glue"を選択

そのまま"Next"をクリック
Databaseを選択(今回はse2)
Prefixを入力(今回はse2_)
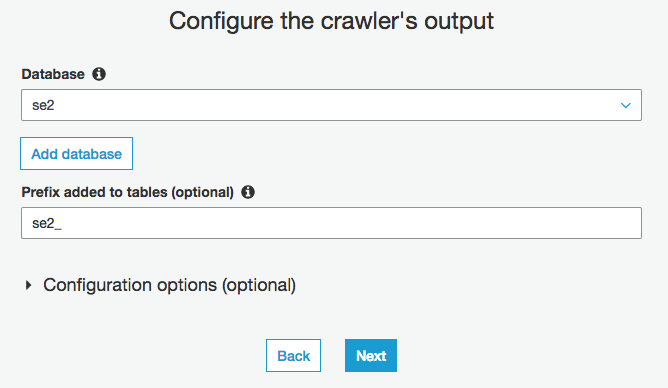
作成したクローラーにチェックを入れ、"Run crawler"をクリックしクローリングしてテーブルを作成します。
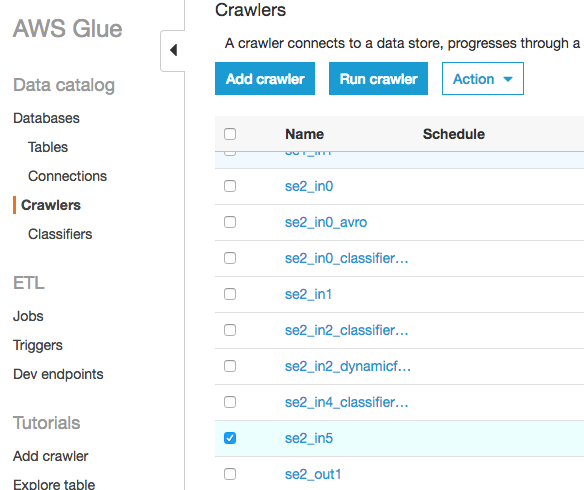
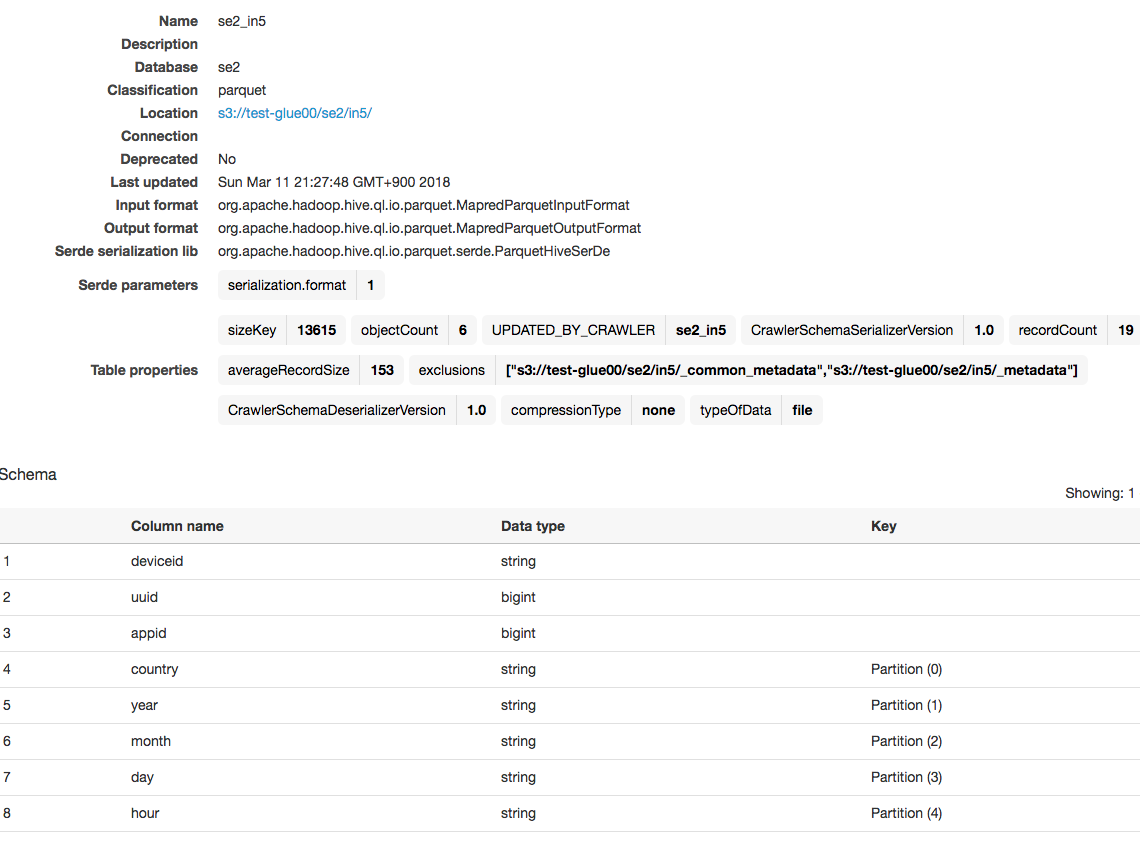
作成されたテーブルを確認
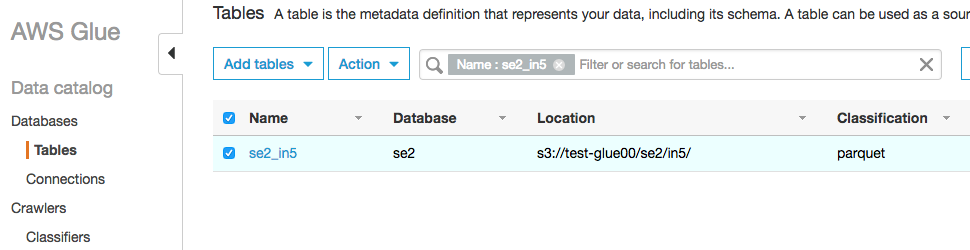
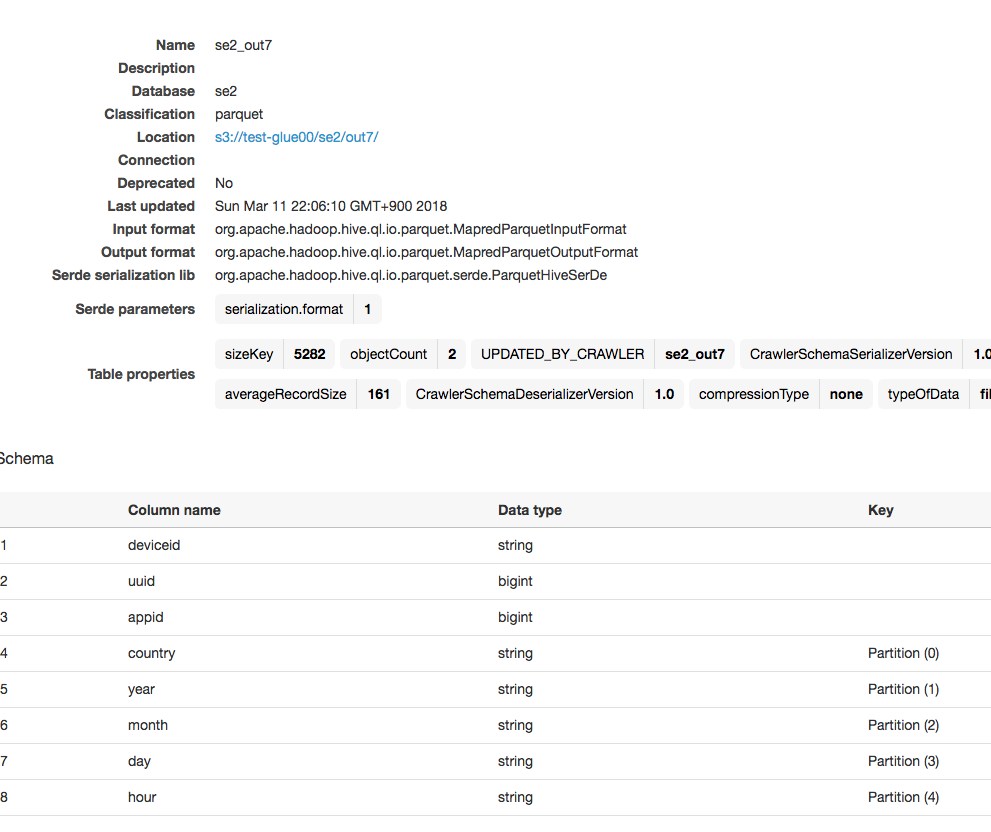
作成されたテーブルのスキーマも確認
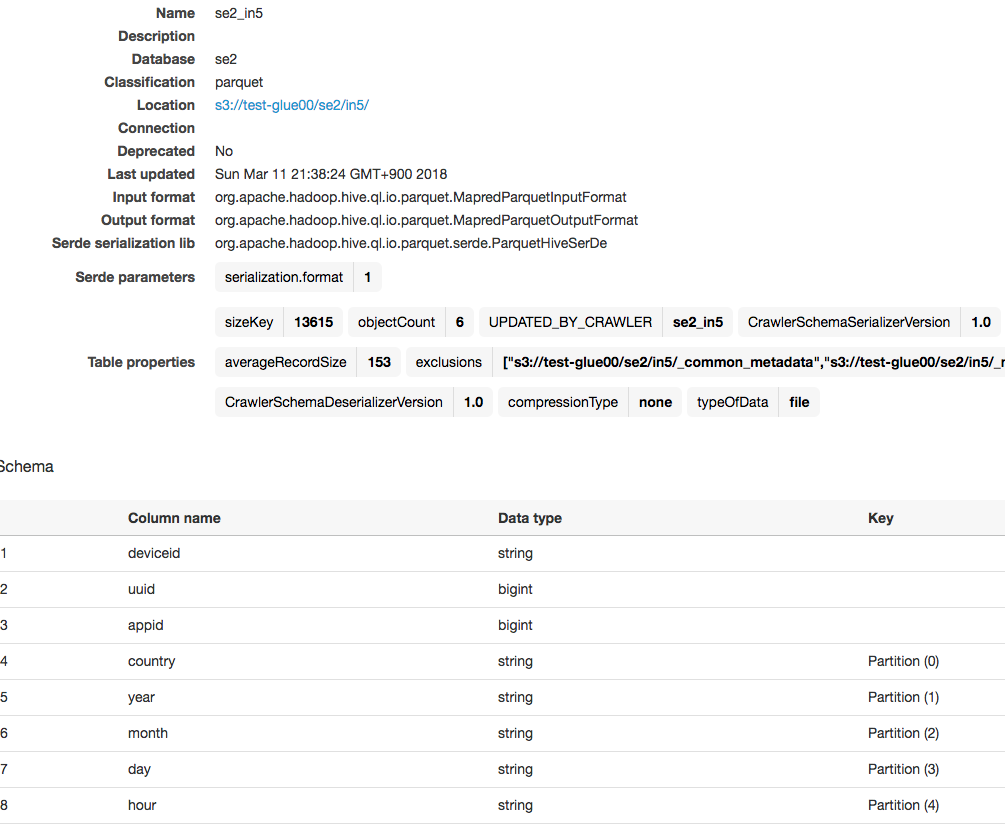
ジョブ作成
ジョブは以下のスクリプトを実行するように適宜作成します。
※適当なジョブを作って、ジョブ内のスクリプトに以下をコピペして上書く感じで構いません
create_dynamic_frameのオプションに"push_down_predicate = my_partition_predicate"を追加しています。
処理内容は"country=JPだけをS3からロードし、parquetのままcountry,year,month,day,hourでパーティション分割したまま出力する"です。
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
## @params: [JOB_NAME]
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
datasource0 = glueContext.create_dynamic_frame.from_catalog(database = "se2", table_name = "se2_in5",push_down_predicate = "country='JP'", transformation_ctx = "datasource0")
resolvechoice2 = ResolveChoice.apply(frame = datasource0, choice = "make_struct", transformation_ctx = "resolvechoice2")
dropnullfields3 = DropNullFields.apply(frame = resolvechoice2, transformation_ctx = "dropnullfields3")
datasink4 = glueContext.write_dynamic_frame.from_options(frame = dropnullfields3, connection_type = "s3", connection_options = {"path": "s3://test-glue00/se2/out7", "partitionKeys": ["country","year","month","day","hour"]}, format = "parquet", transformation_ctx = "datasink4")
job.commit()
ジョブ実行と確認
ジョブ実行
対象ジョブにチェックを入れ、ActionからRun jobをクリックしジョブ実行します
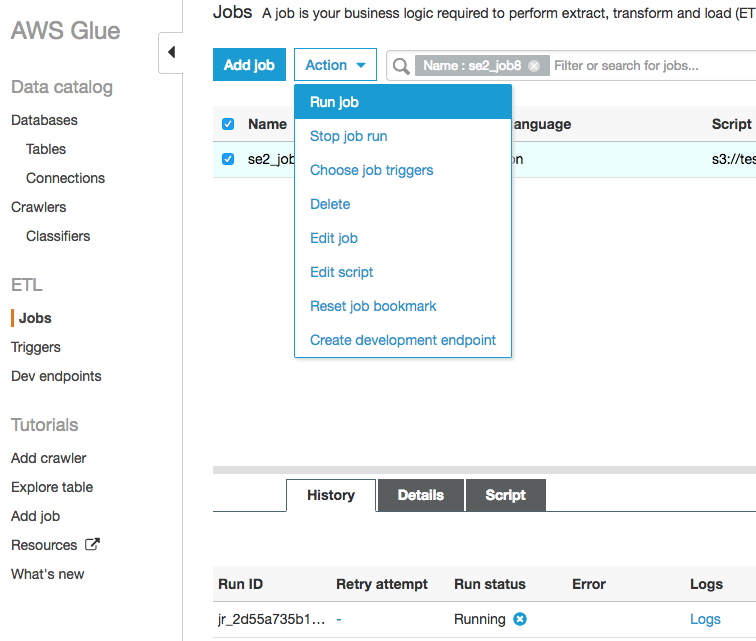
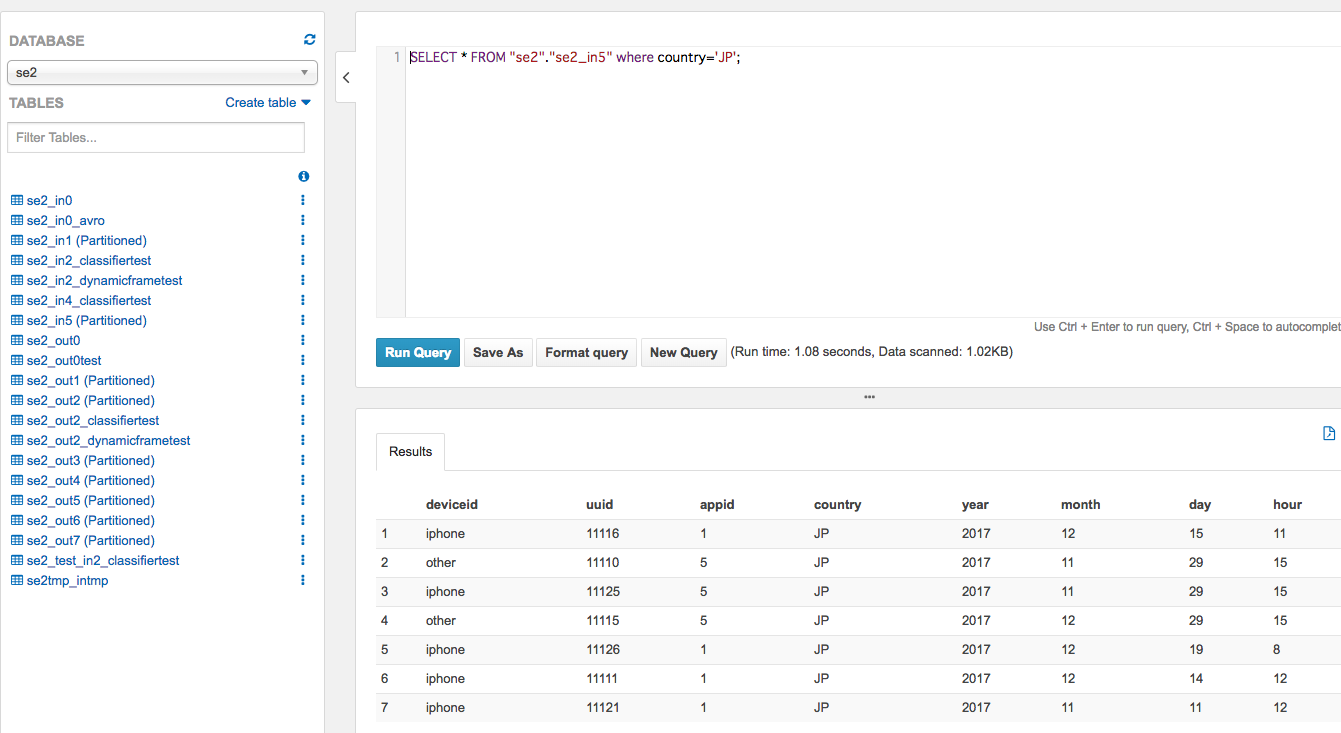
出力が指定したcountry='JP'のデータだけになっている
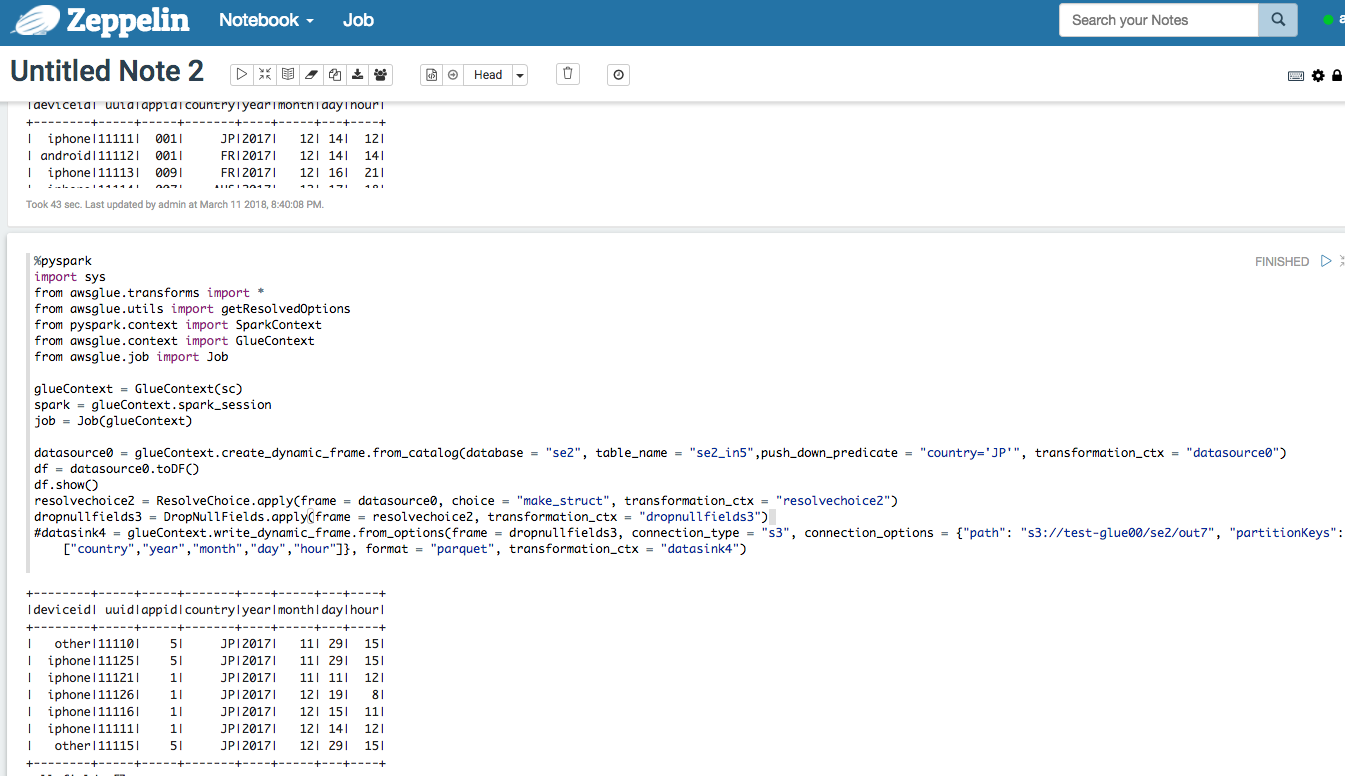
これだけだと入力時にcountry='JP'だけにしぼったかはわからにので、Zeppelinで確認
出力データのクローラー作成、実行、Athenaで確認
se2_out6でクローラー作成
GlueのCrawlersをクリックし、"Add crawler"をクリック
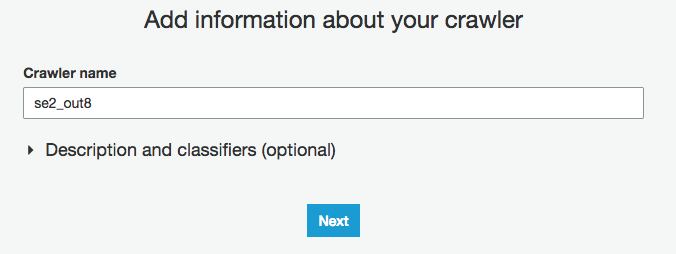
Crawler nameに"se2_out8"を入力
出力データのS3パスを入力
そのまま"Next"をクリック
IAM roleに”test-glue"を選択

そのまま"Next"をクリック
Databaseを選択(今回はse2)
Prefixを入力(今回はse2_)
クローラー実行
作成したクローラーにチェックを入れ、"Run crawler"をクリック
テーブルが作成され、スキーマ情報にも、country,year,month,day,hourなどで分割したパーティションを認識している
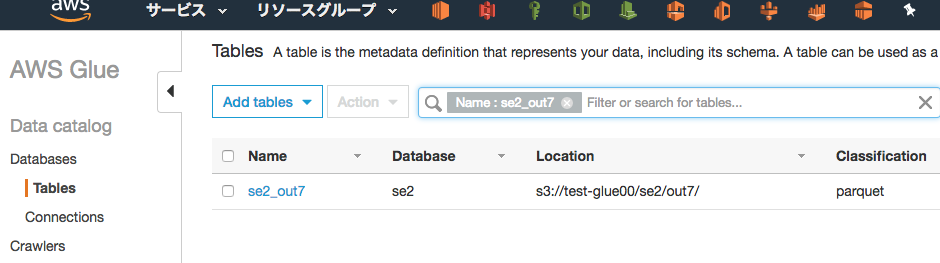
Athenaから確認
左メニューからse2_out7のスキーマ情報確認、クエリ実行
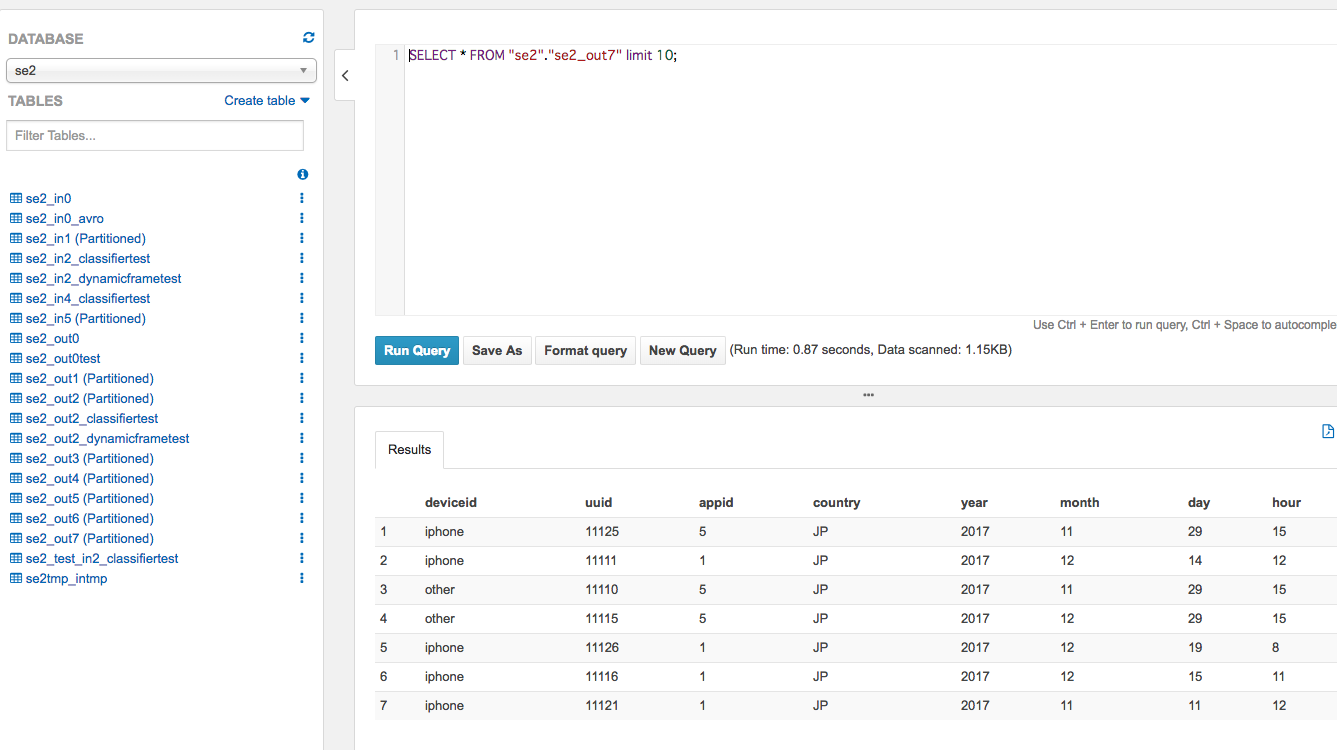
入力データをwhere country='JP'でクエリした結果とも合っている
複数パーティションでpre-filtering
先程は1つのパーティションでしたが、複数パーティションで指定したい場合もあると思います。
S3からyear=2017,month=12,day=14だけをロードしたいなどはあるんじゃないでしょうか?
今回は同じ入力データを使いcountry=JP,year=2017,month=11,day=29だけロードしてみます。
流れは一緒ですのでZeppelinだけで確認をします。
コードは以下になります。
複数パーティション指定する場合は文字列として宣言し、それをDynamicFrameに渡します。
%pyspark
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
pushDownPredicateString = "(country=='JP' and year=='2017' and month=='11' and day=='29')"
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
datasource0 = glueContext.create_dynamic_frame.from_catalog(database = "se2", table_name = "se2_in5",push_down_predicate = pushDownPredicateString, transformation_ctx = "datasource0")
df = datasource0.toDF()
df.show()
resolvechoice2 = ResolveChoice.apply(frame = datasource0, choice = "make_struct", transformation_ctx = "resolvechoice2")
dropnullfields3 = DropNullFields.apply(frame = resolvechoice2, transformation_ctx = "dropnullfields3")
# datasink4 = glueContext.write_dynamic_frame.from_options(frame = dropnullfields3, connection_type = "s3", connection_options = {"path": "s3://test-glue00/se2/out7", "partitionKeys": ["country","year","month","day","hour"]}, format = "parquet", transformation_ctx = "datasink4")
実行結果
入力の段階でデータがフィルタリングされてるのがわかります。

その他
今までは全データロードしてから変換でしたが、pre-filteringで必要なパーティションのみロードすることで、処理全体のスループットを上げることが期待できます。
ある決まったyear=2017,month=12,day=12,hour=12だけのロードや、country=JPとFRだけロードや、その他設定してあるパーティションを特定したロードができます。
To Be Continue
よくありそうな変換処理ケースを今後書いていければと思います。
こちらも是非
Glueマニュアル
https://docs.aws.amazon.com/glue/latest/dg/aws-glue-programming-etl-partitions.html
Spark API
https://spark.apache.org/docs/preview/api/python/pyspark.sql.html
https://hackernoon.com/managing-spark-partitions-with-coalesce-and-repartition-4050c57ad5c4
Glueの使い方まとめ
https://qiita.com/pioho07/items/32f76a16cbf49f9f712f