ブックマークを使って一度処理したデータは処理対象外とする
入力パスの先にデータがあっても既に処理済なデータは除外したい。そんな思いになったことありませんでしょうか?
これを実現する機能がGlueの"ブックマーク"です。
全体の流れ
- 前提
- ブックマークの効果を見る
- ジョブの永続的なブックマーク有効化
- トリガー側のブックマーク有効無効
- (おまけの考察)
前提
"Glueの使い方的な①(GUIでジョブ実行)"(以後①と書きます)、"Glueの使い方的な③(CLIでジョブ実行)"(以後③と書きます)あたりを読んでいただけるとスムーズです
今回扱うジョブは①と同じ内容です。
"S3の指定した場所に配置したcsvデータを指定した場所にparquetとして出力する"
③の後ろの方で書いたように、このジョブはGlueのGUIだけで作成し、1つのcsvを1つのparquetにするだけのなので、このジョブを2回実行すると同じ内容の出力が2つ出来てしまいます。
前準備
ソースデータ(19件)
※①と同じデータ
deviceid,uuid,appid,country,year,month,day,hour
iphone,11111,001,JP,2017,12,14,12
android,11112,001,FR,2017,12,14,14
iphone,11113,009,FR,2017,12,16,21
iphone,11114,007,AUS,2017,12,17,18
other,11115,005,JP,2017,12,29,15
iphone,11116,001,JP,2017,12,15,11
pc,11118,001,FR,2017,12,01,01
pc,11117,009,FR,2017,12,02,18
iphone,11119,007,AUS,2017,11,21,14
other,11110,005,JP,2017,11,29,15
iphone,11121,001,JP,2017,11,11,12
android,11122,001,FR,2017,11,30,20
iphone,11123,009,FR,2017,11,14,14
iphone,11124,007,AUS,2017,12,17,14
iphone,11125,005,JP,2017,11,29,15
iphone,11126,001,JP,2017,12,19,08
android,11127,001,FR,2017,12,19,14
iphone,11128,009,FR,2017,12,09,04
iphone,11129,007,AUS,2017,11,30,14
データの場所
※①と同じ場所
$ aws s3 ls s3://test-glue00/se2/in0/
2018-01-02 15:13:27 0
2018-01-02 15:13:44 691 cvlog.csv
S3のディレクトリ構成
*①と同じディレクトリ
Glueジョブの入力データは"in0"ディレクトリ配下、出力は"out1"ディレクトリ配下
$ aws s3 ls s3://test-glue00/se2/
PRE in0/
PRE out0/
PRE out1/
PRE script/
PRE tmp/
ブックマークの効果を見る
①や③でジョブを実行して出力ファイルがout0に既に存在しているのでそれを事前に消しておきます。
想定される流れと結果
1回目の実行で、①と同じくparquetの出力ファイルが1つできる。(あとメタデータ2つ)
こんな感じ
2018-01-02 10:44:04 782 _common_metadata
2018-01-02 10:44:04 1746 _metadata
2018-01-02 10:27:05 2077 part-00000-19a94695-23f8-492d-81ee-6a0772e4a3b5.snappy.parquet
ブックマークを有効化することで、2回目の実行で、既に処理した入力ファイルは処理されない為、新たなparquetファイルは出力されず1つのままになります
やってみる
ジョブは①で作ったのと同じ内容で新たにジョブをse2_job2という名前で作ります
ジョブの内容は以下です。
"S3の指定した場所に配置したcsvデータを指定した場所にparquetとして出力する"
最初のジョブの状態
実行履歴が1件ありますが気にしないでください。
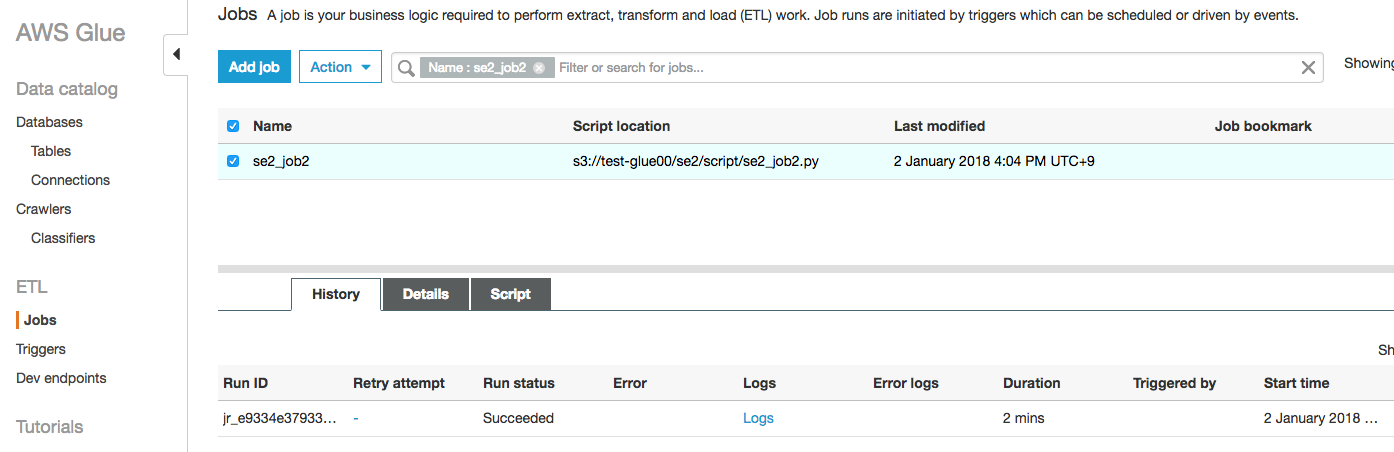
1回目実行
ブックマークを有効にして実行する
"Action"の"Run job"をクリックする
※ちなみにこの画面のActionの"Reset job bookmark"でブックマークに保持された状態をリセットできます
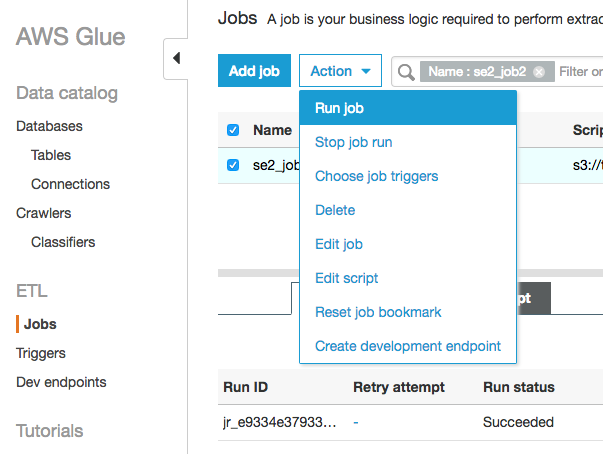
Parameter(optional)の画面で"Job bookmark"を"Enable"にして"Run job"をクリックする
今回のみ有効なパラメータとしてジョブを実行します。
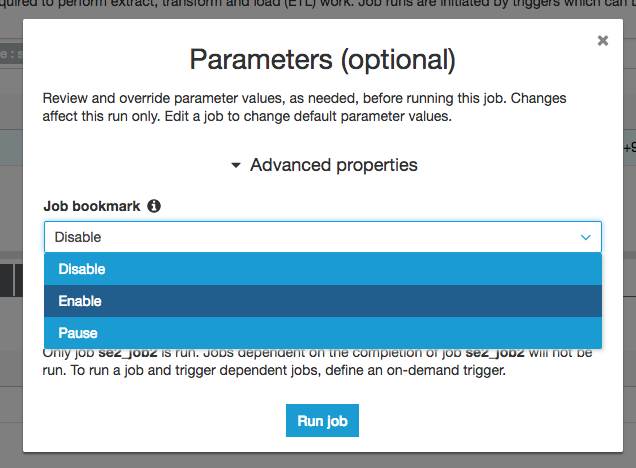
成功して履歴が1つ増えています
S3にparquetファイル1つとメタデータ2つがほぼ同じ時刻で作成されています。
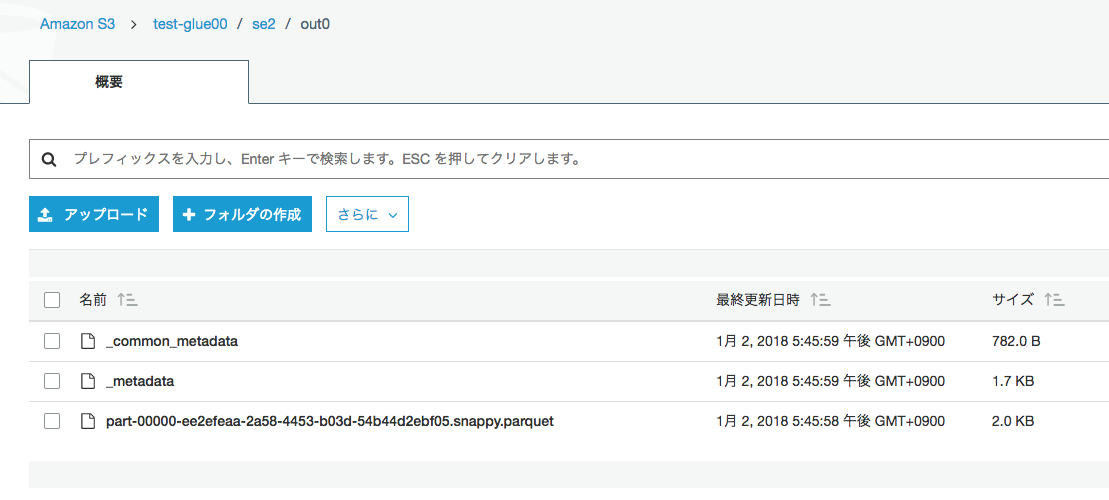
続いて同じ手順で2回目を実行します。
実行後のS3はメタデータは更新されている(?)
ただ、肝心のparquetファイルは1つのみで、1度処理した入力データを対象外としていることがわかる
※メタデータの内容は後半で確認してみます
⭐注意点としては、S3の場合はファイルを対象としているので、新規追加されたファイルはもちろん対象ですが、ファイルが更新された場合も対象となります。つまりファイル内の1行だけ更新がはいっても入力の対象となりETLして出力されます。つまり更新がなかった行も対象になってしまいます。ですので、ブックマーク利用時は基本的には過去のファイルの更新が行わない使い方が望ましいと思います。
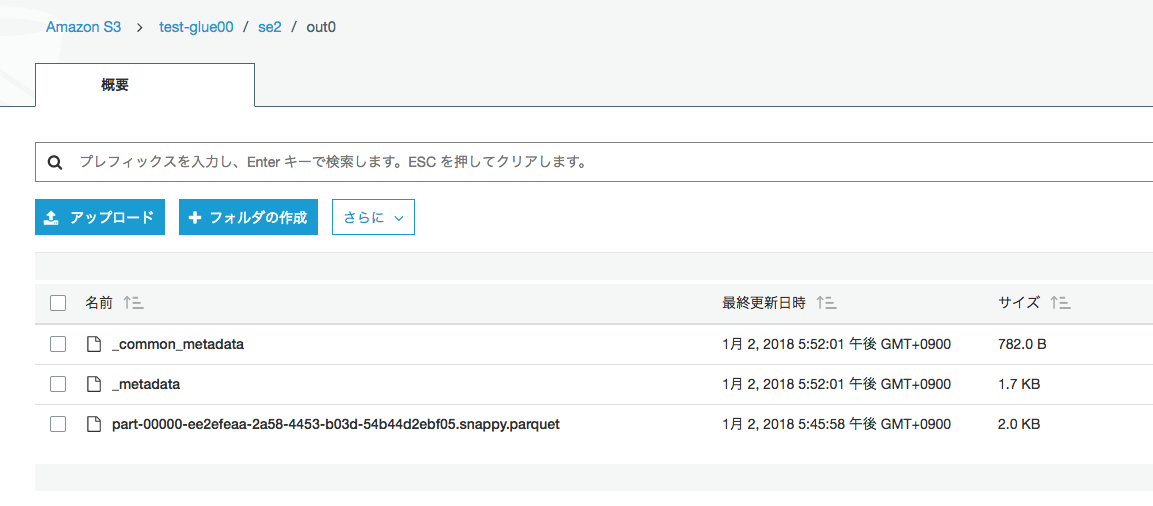
このようにGlueのブックマークを有効にしておくと、同じ場所にあるソースデータの中でまだ処理していないデータだけを処理対象とすることができます。
ジョブ側の永続的なブックマーク有効化
さっきまではジョブ実行時の1度だけのブックマーク有効でした
今回は永続的なブックマーク有効化をします。
対象ジョブにチェックを入れ、"Action"をクリックし、"Edit job"をクリックする
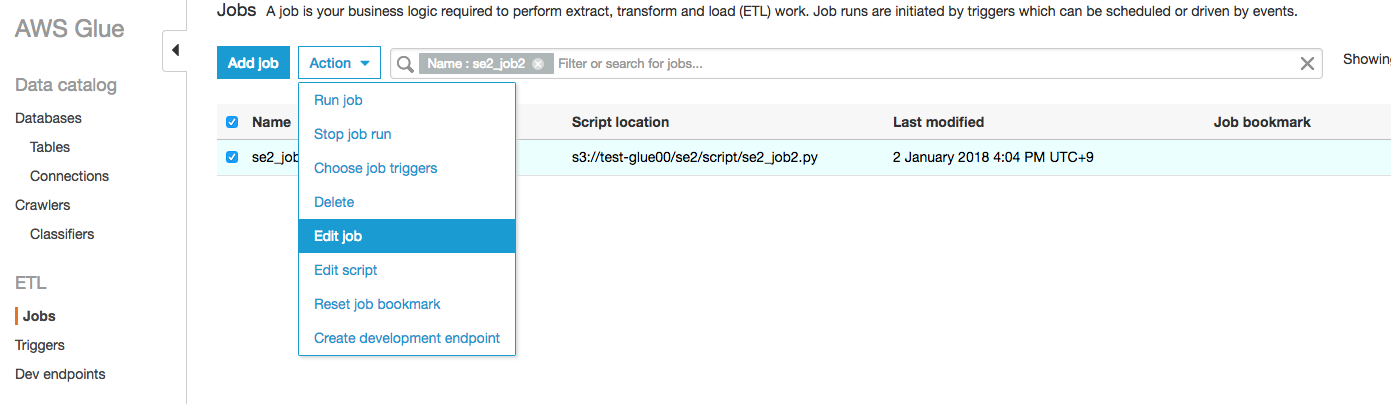
この画面が出て一見ブックマークの設定箇所がなさそうだが、実は下にスクロールできる
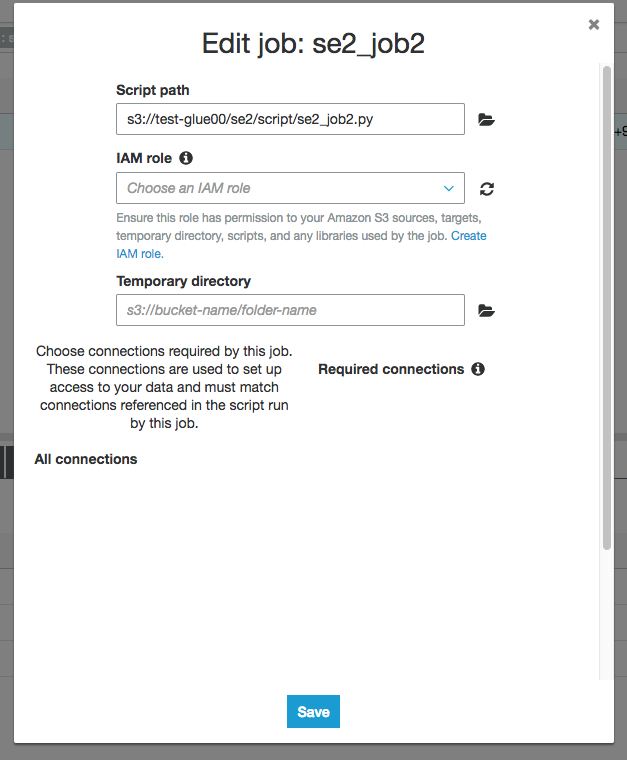
あった
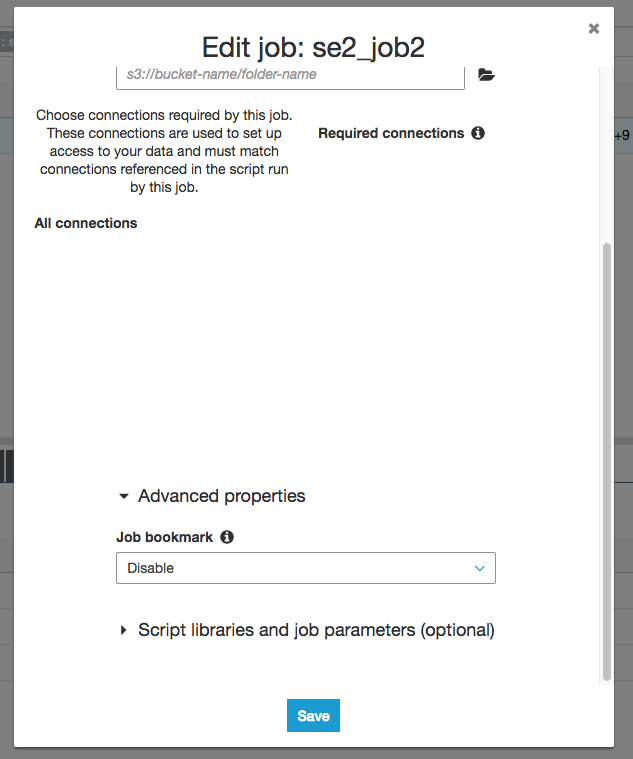
"Enable"に変更して"Save"
するとエラーが、、"temporary directory"と"IAM role"をこのタイミングでも入れないといけなようです。
それぞれ入力後"Save"をクリックします。
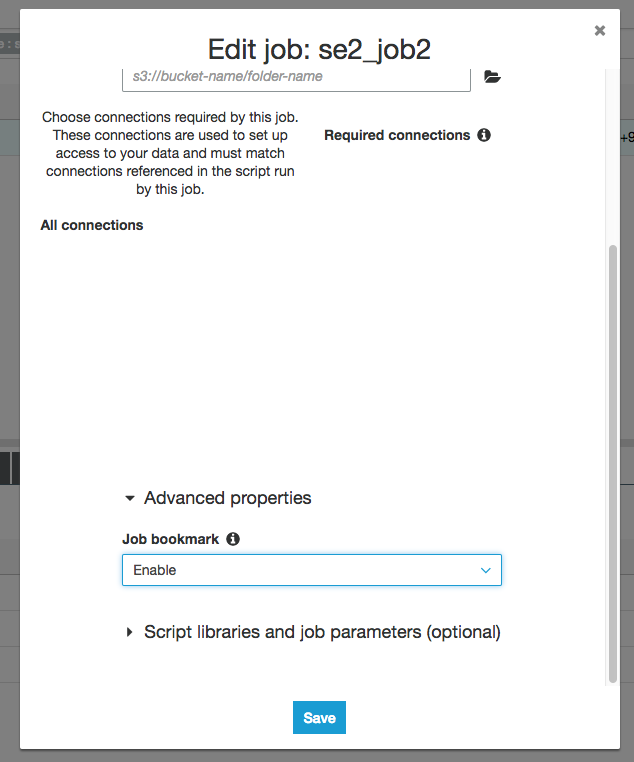
画面の右端にあるように"Job bookmark"が"Enable"になっているのがわかります。
トリガー側のブックマーク有効無効
ブックマークの有効無効確認
対象のトリガーのse2_trigger2の部分をクリック
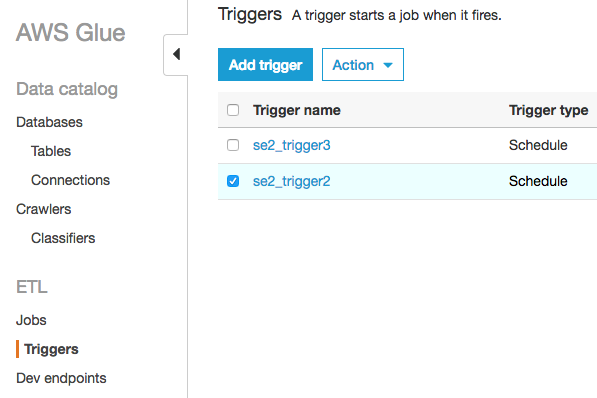
以下の画面になり、Parametersのところに"--job-bookmark-option:job-bookmark-enable"とあればブックマークが有効になっている

ブックマーク有効無効変更
対象のトリガーse2_trigger2にチェックを入れ、"Action"をクリックし"Edit trigger"をクリックする
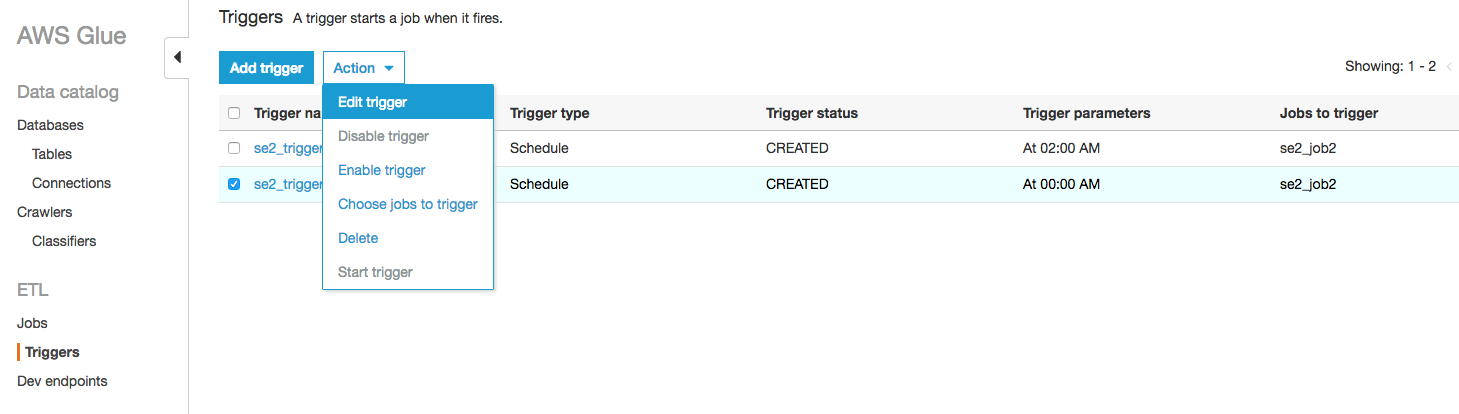
"Next"をクリックする
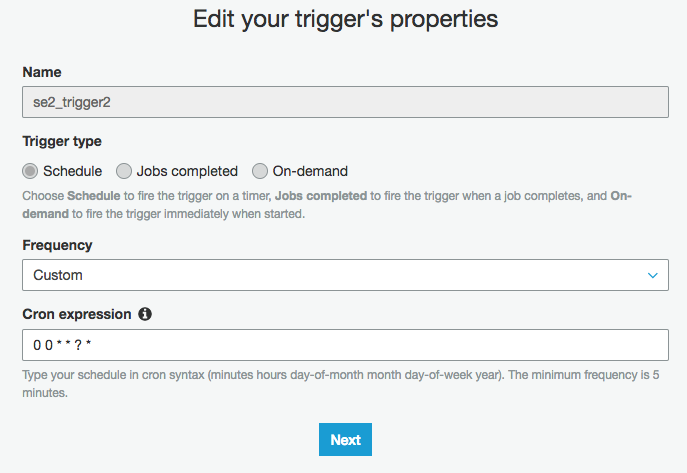
画面下の部分に"Job bookmark"がありDisable、Enable、Pauseの3つの状態が選べる
これを選びNextと進めればよさそうだが、それだけだとダメである
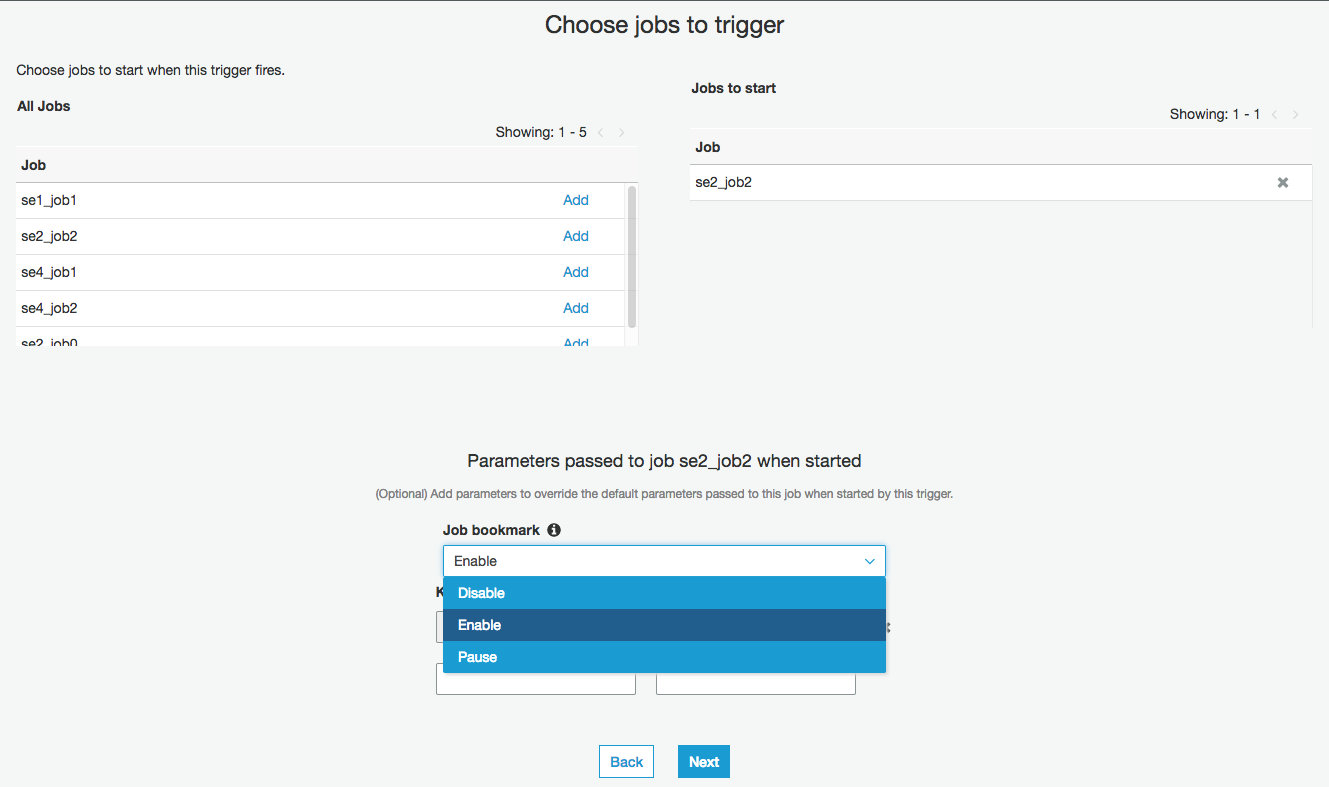
画面下部にあるKeyとValueの箇所の"job-bookmark-enable"を事前に消しておく必要がある。右側の✖をクリックすることで消せます。消した後に"Job bookmark"をDisableにして"Next"をクリックし、次にサマリが出るので問題なければ"Finish"をクリックする
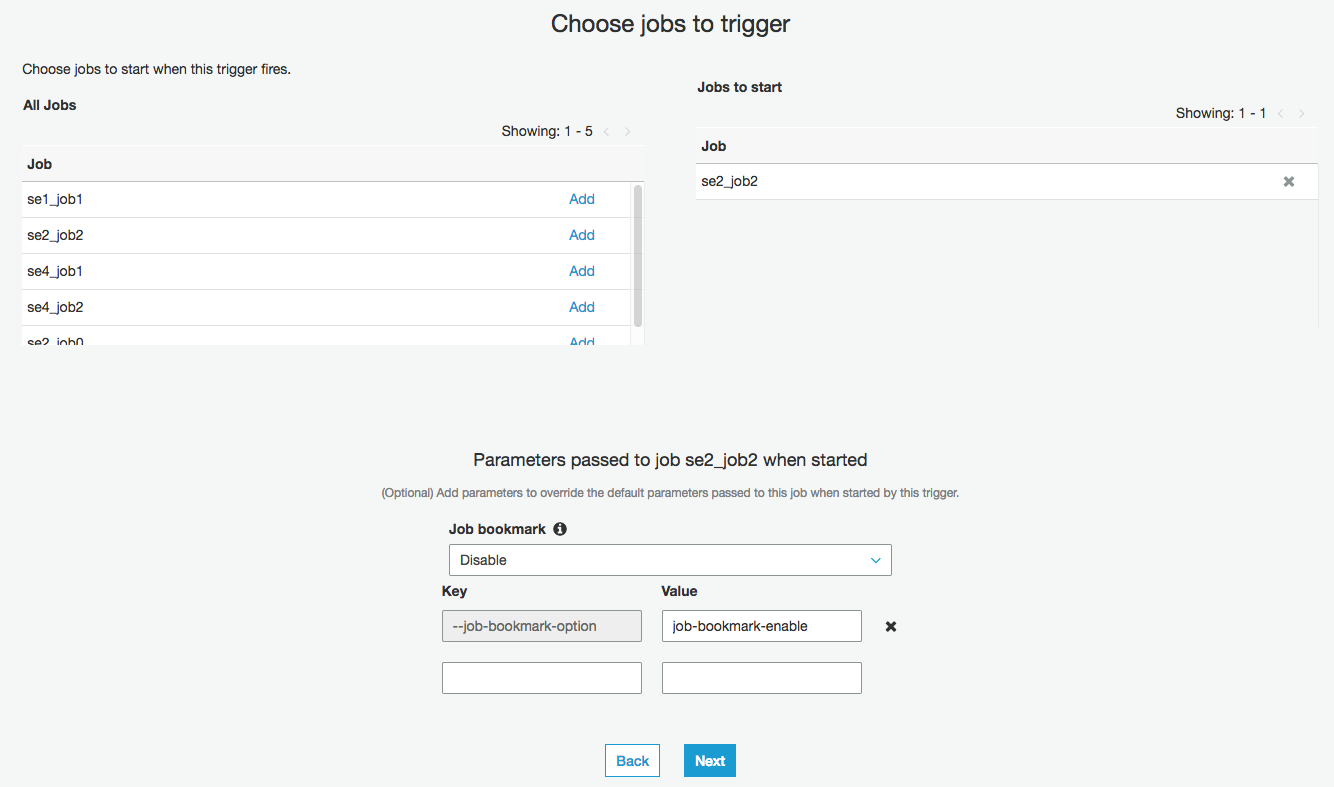
確認すると"--job-bookmark-option:job-bookmark-disable"になっていて無効に変わったことがわかる

(ブックマーク有効にしてジョブ実行してもメタデータが更新された件の考察)
結果的にはparquetの仕様っぽいので気にする必要もなさそうです。
メタを詳細に見るためにparquet-toolsを入れます。
このツール相変わらず普通にビルドできない・・
ここは弊社の担々麺デカの力を借りて無事入りました。(+1タンタンメン)
http://d.hatena.ne.jp/yohei-a/20170629/1498710035
とは言え改善してるんじゃと思い、ちょっと脱線しますが
【parquet-toolsインストール2018年版】
github
また(?)リポジトリ変わってます・・
https://github.com/apache/parquet-mr
最新のv1.8.0、v1.8.1はpom.xmlをゴニョゴニョしないとダメだ
Issueは多分こちら
https://issues.apache.org/jira/browse/PARQUET-1129
v1.7はなぜかなく、結果的にv1.6系最後(?)の1.6.0rc7だとすんなりビルドできました。
jdkインストール
yum -y install java-1.7.0-openjdk-devel
mavenインストール
wget http://ftp.yz.yamagata-u.ac.jp/pub/network/apache/maven/maven-3/3.3.9/binaries/apache-maven-3.3.9-bin.tar.gz
tar xvfz apache-maven-3.3.9-bin.tar.gz
./apache-maven-3.3.9/bin/mvn -version
.bash_profileとかでパス通す
PATH=$PATH:$HOME/bin:/root/apache-maven-3.3.9/bin
parquet-toolsインストール
git clone https://github.com/apache/parquet-mr.git
cd parquet-mr
git checkout ec6f200b4943cfcbc8be5a8e53fdebf07a8e16f7
cd parquet-tools/
mvn clean package -Plocal
実行
aws s3 cp s3://test-glue00/se2/out0/ .data/ --recursive
java -jar target/parquet-tools-1.6.0rc7.jar head -n 1 data/part-00000-19a94695-23f8-492d-81ee-6a0772e4a3b5.snappy.parquet
deviceid = iphone
uuid = 11111
appid = 1
country = JP
year = 2017
month = 12
day = 14
hour = 12
parquet-toolsでメタ情報も見れます。
ブックマークを使ったのにメタデータは更新があったので、更新前と後のメタの情報を比較してみます。
メタ情報表示
# java -jar target/parquet-tools-1.6.0rc7.jar meta data/part-00000-19a94695-23f8-492d-81ee-6a0772e4a3b5.snappy.parquet
file: file:/root/parquet/parquet-mr/parquet-tools/data/part-00000-19a94695-23f8-492d-81ee-6a0772e4a3b5.snappy.parquet
creator: parquet-mr version 1.8.1 (build 4aba4dae7bb0d4edbcf7923ae1339f28fd3f7fcf)
extra: org.apache.spark.sql.parquet.row.metadata = {"type":"struct","fields":[{"name":"deviceid","type":"string","nullable":true,"metadata":{}},{"name":"uuid","type":"long","nullable":true,"metadata":{}},{"name":"appid","type":"long","nullable":true,"metadata":{}},{"name":"country","type":"string","nullable":true,"metadata":{}},{"name":"year","type":"long","nullable":true,"metadata":{}},{"name":"month","type":"long","nullable":true,"metadata":{}},{"name":"day","type":"long","nullable":true,"metadata":{}},{"name":"hour","type":"long","nullable":true,"metadata":{}}]}
file schema: spark_schema
--------------------------------------------------------------------------------
deviceid: OPTIONAL BINARY O:UTF8 R:0 D:1
uuid: OPTIONAL INT64 R:0 D:1
appid: OPTIONAL INT64 R:0 D:1
country: OPTIONAL BINARY O:UTF8 R:0 D:1
year: OPTIONAL INT64 R:0 D:1
month: OPTIONAL INT64 R:0 D:1
day: OPTIONAL INT64 R:0 D:1
hour: OPTIONAL INT64 R:0 D:1
row group 1: RC:19 TS:952 OFFSET:4
--------------------------------------------------------------------------------
deviceid: BINARY SNAPPY DO:0 FPO:4 SZ:101/97/0.96 VC:19 ENC:BIT_PACKED,PLAIN_DICTIONARY,RLE
uuid: INT64 SNAPPY DO:0 FPO:105 SZ:138/201/1.46 VC:19 ENC:PLAIN,BIT_PACKED,RLE
appid: INT64 SNAPPY DO:0 FPO:243 SZ:98/100/1.02 VC:19 ENC:BIT_PACKED,PLAIN_DICTIONARY,RLE
country: BINARY SNAPPY DO:0 FPO:341 SZ:80/76/0.95 VC:19 ENC:BIT_PACKED,PLAIN_DICTIONARY,RLE
year: INT64 SNAPPY DO:0 FPO:421 SZ:74/70/0.95 VC:19 ENC:BIT_PACKED,PLAIN_DICTIONARY,RLE
month: INT64 SNAPPY DO:0 FPO:495 SZ:86/82/0.95 VC:19 ENC:BIT_PACKED,PLAIN_DICTIONARY,RLE
day: INT64 SNAPPY DO:0 FPO:581 SZ:137/171/1.25 VC:19 ENC:BIT_PACKED,PLAIN_DICTIONARY,RLE
hour: INT64 SNAPPY DO:0 FPO:718 SZ:129/155/1.20 VC:19 ENC:BIT_PACKED,PLAIN_DICTIONARY,RLE
更新前のメタ情報:/tmp/data1/meta.log
更新後のメタ情報:/tmp/data2/meta.log
diffは見切れちゃってますが、差分は以下の並びが違うということでした。内容は同じです。
ENC:BIT_PACKED,PLAIN_DICTIONARY,RLE
もう1回ジョブを実行した場合、上記の並びは同じでしたがタイムスタンプは最新になってました。
そういうもののようです;
# sdiff -s /tmp/data1/meta.log /tmp/data2/meta.log
file: file:/root/parquet/parquet-mr/parquet-tools/data | file: file:/root/parquet/parquet-mr/parquet-tools/data
deviceid: BINARY SNAPPY DO:0 FPO:4 SZ:101/97/0.96 VC:19 E | deviceid: BINARY SNAPPY DO:0 FPO:4 SZ:101/97/0.96 VC:19 E
uuid: INT64 SNAPPY DO:0 FPO:105 SZ:138/201/1.46 VC:19 | uuid: INT64 SNAPPY DO:0 FPO:105 SZ:138/201/1.46 VC:19
appid: INT64 SNAPPY DO:0 FPO:243 SZ:98/100/1.02 VC:19 | appid: INT64 SNAPPY DO:0 FPO:243 SZ:98/100/1.02 VC:19
country: BINARY SNAPPY DO:0 FPO:341 SZ:80/76/0.95 VC:19 | country: BINARY SNAPPY DO:0 FPO:341 SZ:80/76/0.95 VC:19
year: INT64 SNAPPY DO:0 FPO:421 SZ:74/70/0.95 VC:19 E | year: INT64 SNAPPY DO:0 FPO:421 SZ:74/70/0.95 VC:19 E
month: INT64 SNAPPY DO:0 FPO:495 SZ:86/82/0.95 VC:19 E | month: INT64 SNAPPY DO:0 FPO:495 SZ:86/82/0.95 VC:19 E
day: INT64 SNAPPY DO:0 FPO:581 SZ:137/171/1.25 VC:19 | day: INT64 SNAPPY DO:0 FPO:581 SZ:137/171/1.25 VC:19
hour: INT64 SNAPPY DO:0 FPO:718 SZ:129/155/1.20 VC:19 | hour: INT64 SNAPPY DO:0 FPO:718 SZ:129/155/1.20 VC:19
その他
-
Glueで自動生成されるPySparkコードに以下のようなコンテキストオブジェクトがあります。これにはブックマークとしての意味もあり、それぞれの実行時にソース、変換、およびシンクの状態をブックマークの状態のキーとして使用します。状態はタイムスタンプとして記録し維持します。
なのでブックマークを使用していない場合は、この変数を指定しなくても問題はありません。
transformation_ctx = "datasource0"
transformation_ctx = "applymapping1"
transformation_ctx = "datasink4" -
S3の結果整合性への対処
ジョブ開始前に、以前のデータと不整合があるデータをジョブの対象とする(整合なデータは除外リストとして維持する)
状態としてサイズも持っているということかもしれません。 -
例えばあるファイルは処理対象か対象ではないのか?と言った詳細なブックマークの状態を見ることは現在はできません。
To Be Continue
todo
参考
Bookmarkの公式ページ
https://docs.aws.amazon.com/ja_jp/glue/latest/dg/monitor-continuations.html
re:Invent資料。34ページあたりにBookMarkの細かい情報あり
https://www.slideshare.net/AmazonWebServices/abd315serverless-etl-with-aws-glue
parquet-toolsインストール
http://d.hatena.ne.jp/yohei-a/20170629/1498710035
parquet-tools
https://github.com/apache/parquet-mr
Glueの使い方まとめ
https://qiita.com/pioho07/items/32f76a16cbf49f9f712f