Glue Workflows とは
以下のリンクをご参照ください
Glueの使い方的な㊵(Workflowsでジョブフローの可視化)
https://qiita.com/pioho07/items/0cd0ae27b61f5914f78d
Workflowsを作る
内容
以下の記事で書いたクローラーやジョブを使いワークフローを作ります
https://qiita.com/pioho07/items/a24d188d67fe97034b34
クローラー -> ジョブ(PySpark) -> ジョブ(PythonShell)
処理はシンプルで、S3のcsvファイルをクローリングし、parquet変換し、変換後のファイル名をリネームします。これらの処理でワークフローから環境変数を表示し、渡し、その値に変更を加えます。後続の処理でその環境変数を取得し表示します。ジョブ間でのパラメータの受け渡すようなイメージです。
- 1つ目のクローラー:S3のcsvファイルをクローリングしGlue Data Catalogのテーブル(スキーマ)を作る
- 2つ目のジョブ:PySparkでフォーマットをparquetにしたり、country,year,month,day,hourでパーティション化したり、圧縮してS3に出力
- 3つ目のジョブ:PythonShellで出力されたファイルをリネームする
※詳細なコードの内容は上のリンクを参照ください
全体の流れ
- 前準備
- ワークフロー作成
- ワークフロー実行
- 確認
前準備
リソース名
クローラー名
se2_in0
ジョブ名
se2_job24(job15の微修正してパラメータを渡す)
se2_job25(job16の微修正してパラメータを渡す)
コード修正部分
se2_job24
コードの中で「sc = SparkContext()」より上の部分を修正しています。
getResolvedOptionsで'WORKFLOW_NAME'と'WORKFLOW_RUN_ID'も取得しています。get_workflow_run_propertiesでこの値を使って、ワークフローの実行プロパティを取得しています。また、直後にput_workflow_run_propertiesで新しいprodという値を入れてworkflow_envの値を更新しています。
import sys
# add start
import boto3
# add end
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
### delete
# args = getResolvedOptions(sys.argv, ['JOB_NAME'])
### add start
glue_client = boto3.client("glue", region_name='ap-northeast-1')
args = getResolvedOptions(sys.argv, ['JOB_NAME', 'WORKFLOW_NAME', 'WORKFLOW_RUN_ID'])
workflow_name = args['WORKFLOW_NAME']
workflow_run_id = args['WORKFLOW_RUN_ID']
workflow_params = glue_client.get_workflow_run_properties(Name=workflow_name, RunId=workflow_run_id)["RunProperties"]
run_env = workflow_params['workflow_env']
print(run_env)
## put
workflow_params['workflow_env'] = 'prod'
glue_client.put_workflow_run_properties(Name=workflow_name, RunId=workflow_run_id, RunProperties=workflow_params)
### add end
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
datasource0 = glueContext.create_dynamic_frame.from_catalog(database = "se2", table_name = "se2_in0", transformation_ctx = "datasource0")
applymapping1 = ApplyMapping.apply(frame = datasource0, mappings = [("deviceid", "string", "deviceid", "string"), ("uuid", "long", "uuid", "long"), ("appid", "long", "appid", "long"), ("country", "string", "country", "string"), ("year", "long", "year", "long"), ("month", "long", "month", "long"), ("day", "long", "day", "long"), ("hour", "long", "hour", "long")], transformation_ctx = "applymapping1")
resolvechoice2 = ResolveChoice.apply(frame = applymapping1, choice = "make_struct", transformation_ctx = "resolvechoice2")
dropnullfields3 = DropNullFields.apply(frame = resolvechoice2, transformation_ctx = "dropnullfields3")
df = dropnullfields3.toDF()
partitionby=['country','year','month','day','hour']
output='s3://test-glue00/se2/out15/'
codec='snappy'
df.repartition(1).write.partitionBy(partitionby).mode("overwrite").parquet(output,compression=codec)
job.commit()
se2_job25
「s3 = boto3.resource('s3')」より上の部分を修正しています。1つ目のジョブと同じようにgetResolvedOptionsで'WORKFLOW_NAME'と'WORKFLOW_RUN_ID'を取得し、get_workflow_run_propertiesでこの値を使って、ワークフローの実行プロパティを取得しています。この取得した実行プロパティが1つ目のジョブで更新した値になっていることを後半で確認します。
# -*- coding: utf-8 -*-
import boto3
import re
### add start
import sys
from awsglue.utils import getResolvedOptions
glue_client = boto3.client("glue", region_name='ap-northeast-1')
args = getResolvedOptions(sys.argv, ['WORKFLOW_NAME', 'WORKFLOW_RUN_ID'])
workflow_name = args['WORKFLOW_NAME']
workflow_run_id = args['WORKFLOW_RUN_ID']
workflow_params = glue_client.get_workflow_run_properties(Name=workflow_name, RunId=workflow_run_id)["RunProperties"]
run_env = workflow_params['workflow_env']
print(run_env)
### add end
s3 = boto3.resource('s3')
bucket = s3.Bucket('test-glue00')
bucket_name='test-glue00'
for object in bucket.objects.filter(Prefix='se2/tmp2/country='):
#print(object.key)
old_file = object.key
pattern1 = r'.*part.*'
result1 = re.match(pattern1, old_file)
if result1:
Copy_from = result1.group()
Copy_to = result1.group().rsplit('/', 1)[0] + '/' + result1.group().split("/")[2]
s3.Object(bucket_name,Copy_to).copy_from(CopySource=bucket_name + '/' + Copy_from )
s3.Object(bucket_name,Copy_from).delete()
ワークフロー作成
Glueの画面の左メニューから"ワークフロー"をクリックし[ワークフローの追加]をクリック
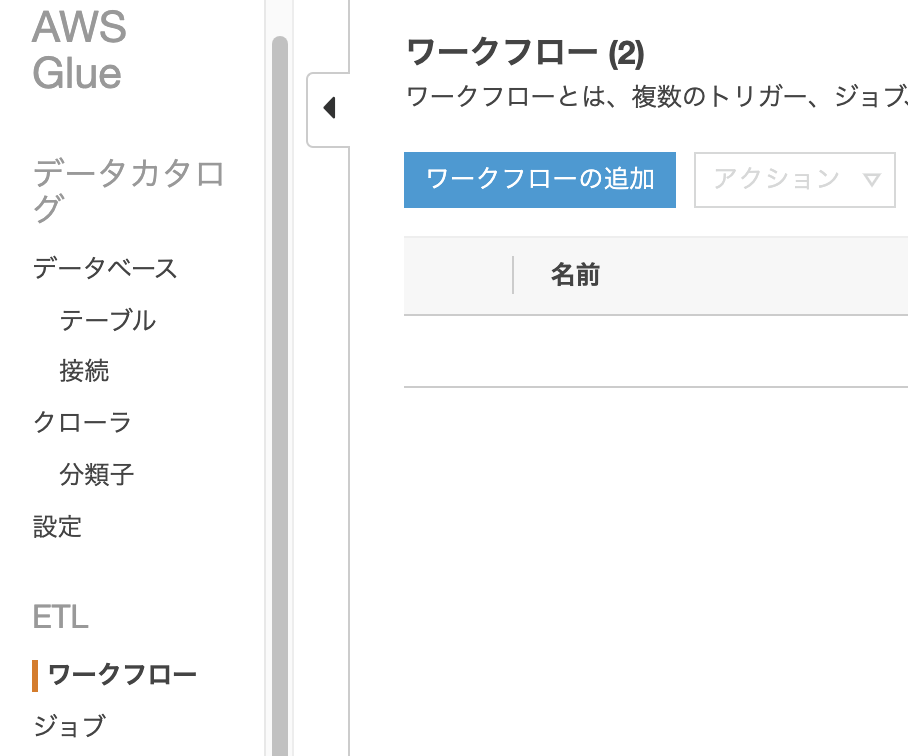
以下を入力して[ワークフローの追加]をクリックする
ここで入力しているプロパティは"実行プロパティ"と呼ばれ、ジョブの中で読み出して使い、また更新することができる値。ジョブ間で受け渡しできる環境変数のようなもの。今回はworkflow_env:devというキーバリューで(この値には特に意味はないです)、1つ目のジョブでこの値を読みworkflow_evn:prodに更新する。2つ目のジョブでworkflow_envを読みprodの値を得る。ということをやってみる。
ワークフロー名: se2_workflow2
[プロパティの追加]をクリックし以下を入力
キー:env
値:test
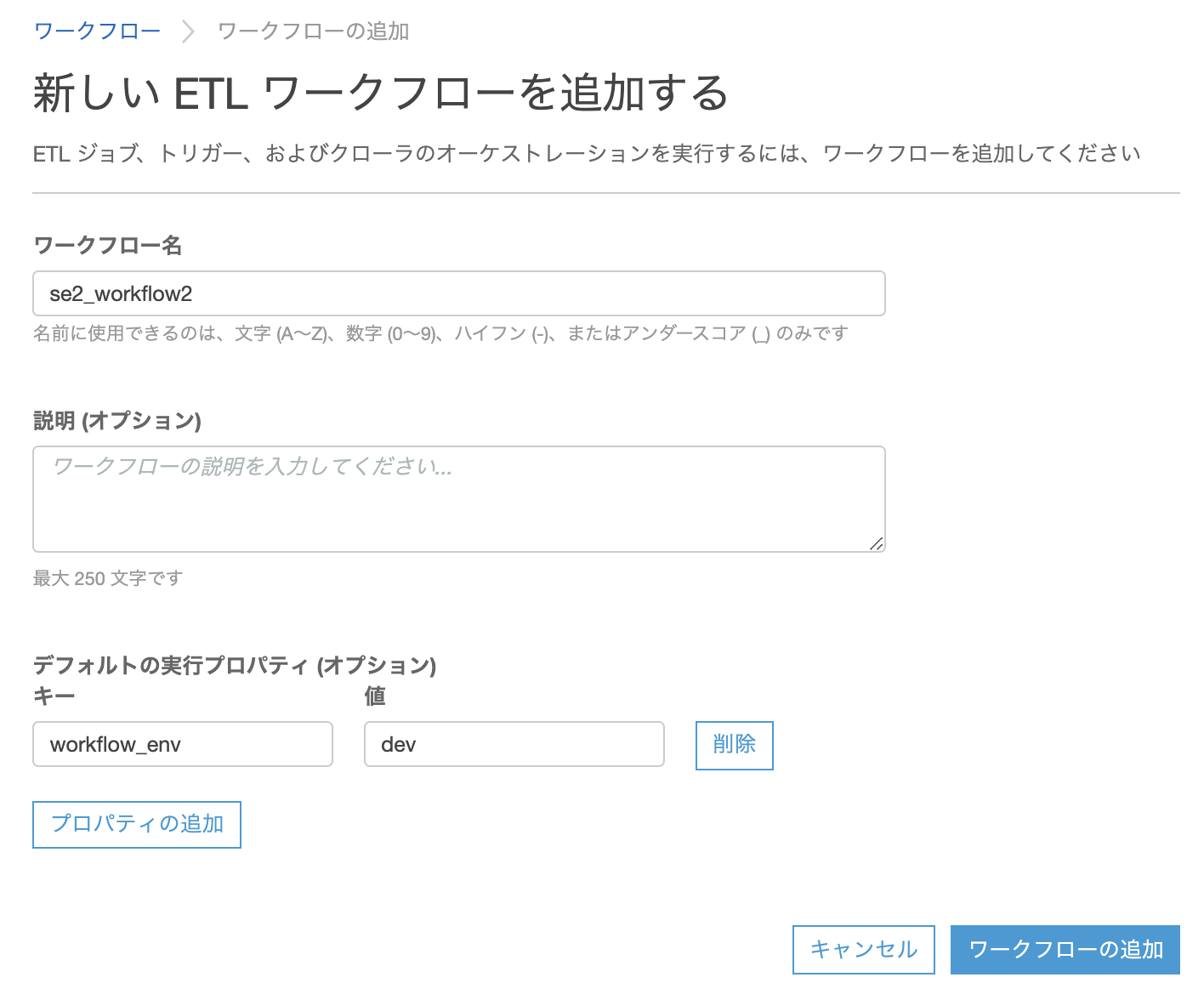
作成されたworkflowの"se2_workflow2"にチェックを入れ、画面下の[グラフ]タブをクリックし[トリガーを追加]をクリックする
※ここで作るトリガーはGlueのトリガーとして作られます
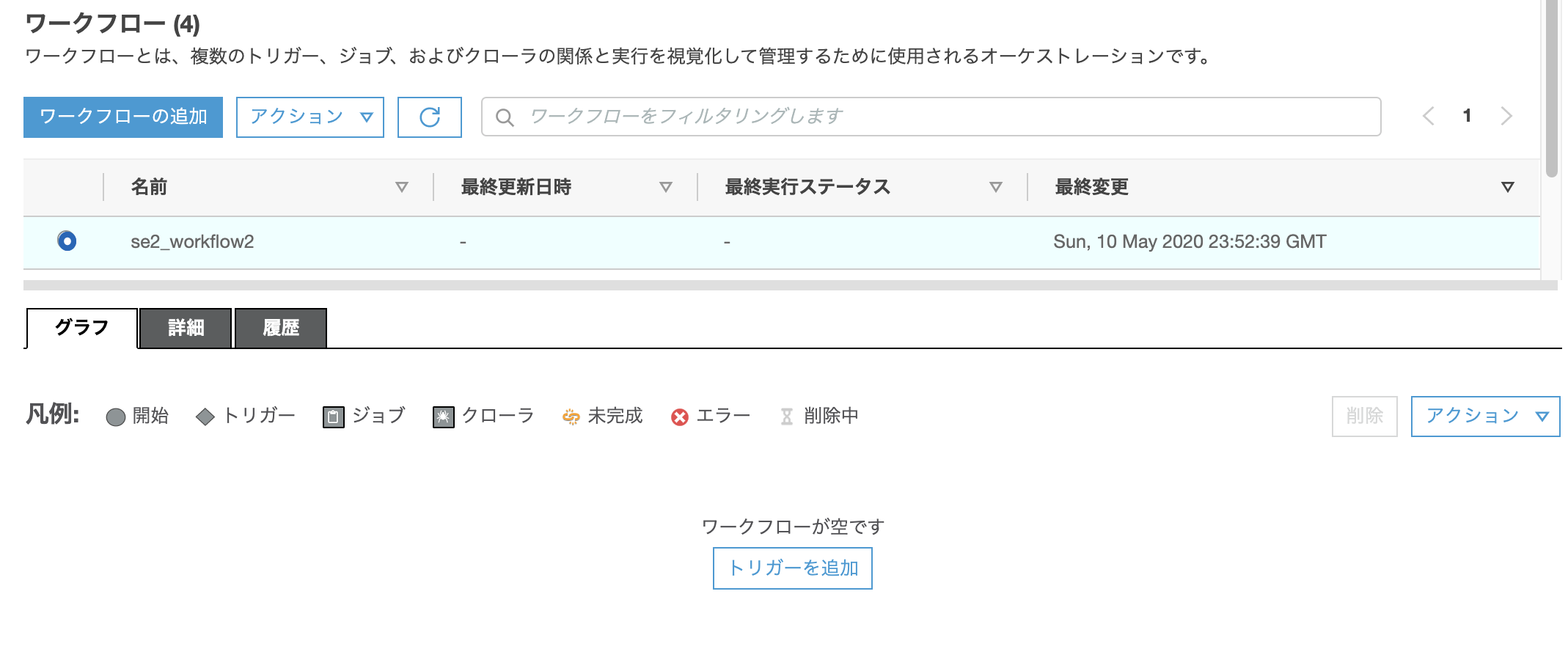
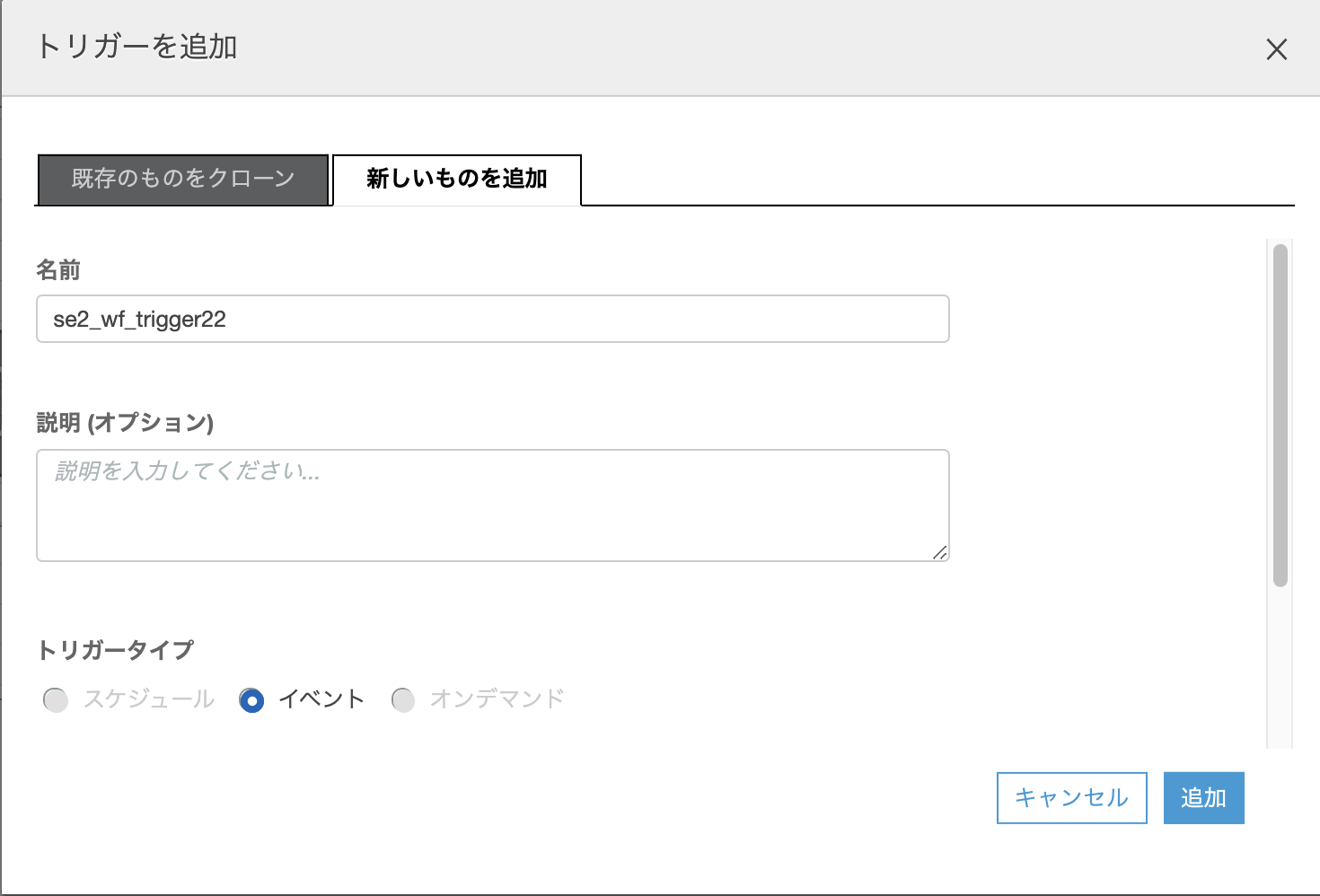
"新しいものを追加"タブをクリックし、Nameに"se2_wf_trigger21"を入れ、トリガータイプを"オンデマンド"にチェックを入れ、[追加]をクリック
※"既存のものをクローン"タブで既存のトリガーからコピーもできます
こんなのが出来きる
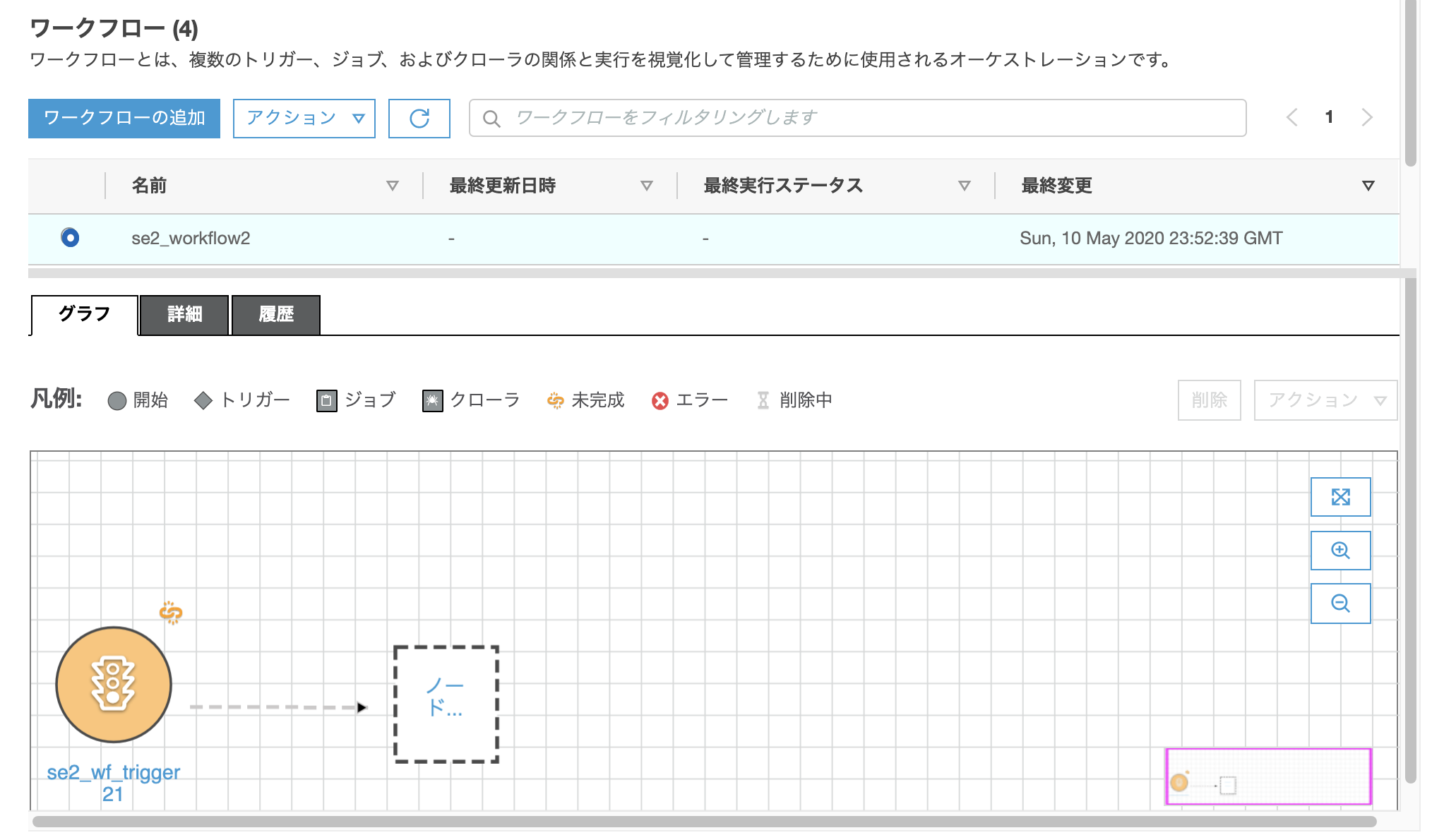
とりあえず全画面表示にしてみて、"ノードの追加"の箇所をクリック。※文字が見切れてて「ノード...」しか見えないがおそらく"ノードの追加"と書かれてる。

ポップアップ画面が出るので、"クローラ"タブをクリックし、該当のクローラー"se2_in0"にチェックを入れ、[追加]をクリックする
※"ジョブ"タブをクリックすればジョブを選べる
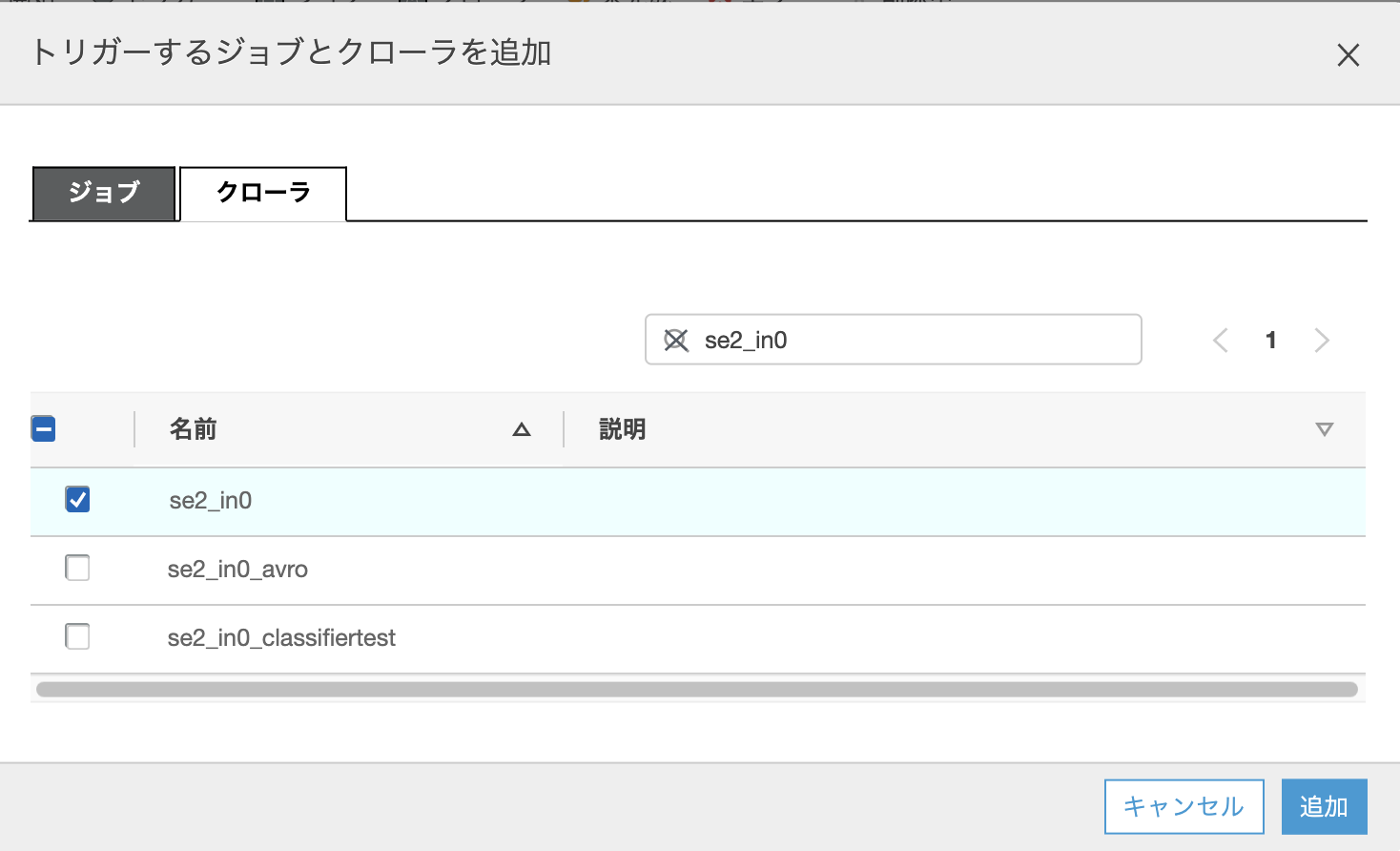
左の丸いのがスタート、虫みたいなアイコンがクローラー
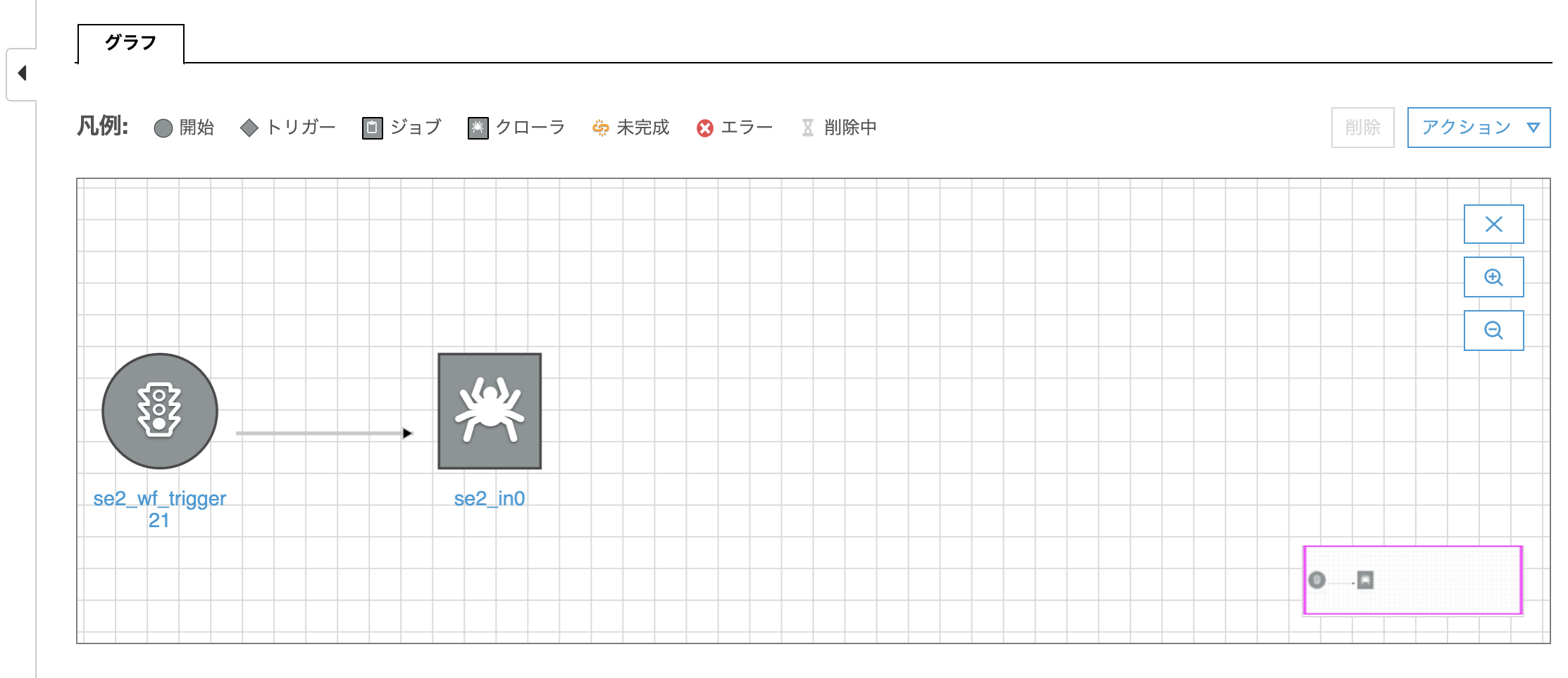
クローラーのアイコンをクリックすると以下のようになり、"トリガーを追加"をクリックする
ポップアップ画面で名前に"se2_wf_trigger22"を入れ[追加]をクリックする
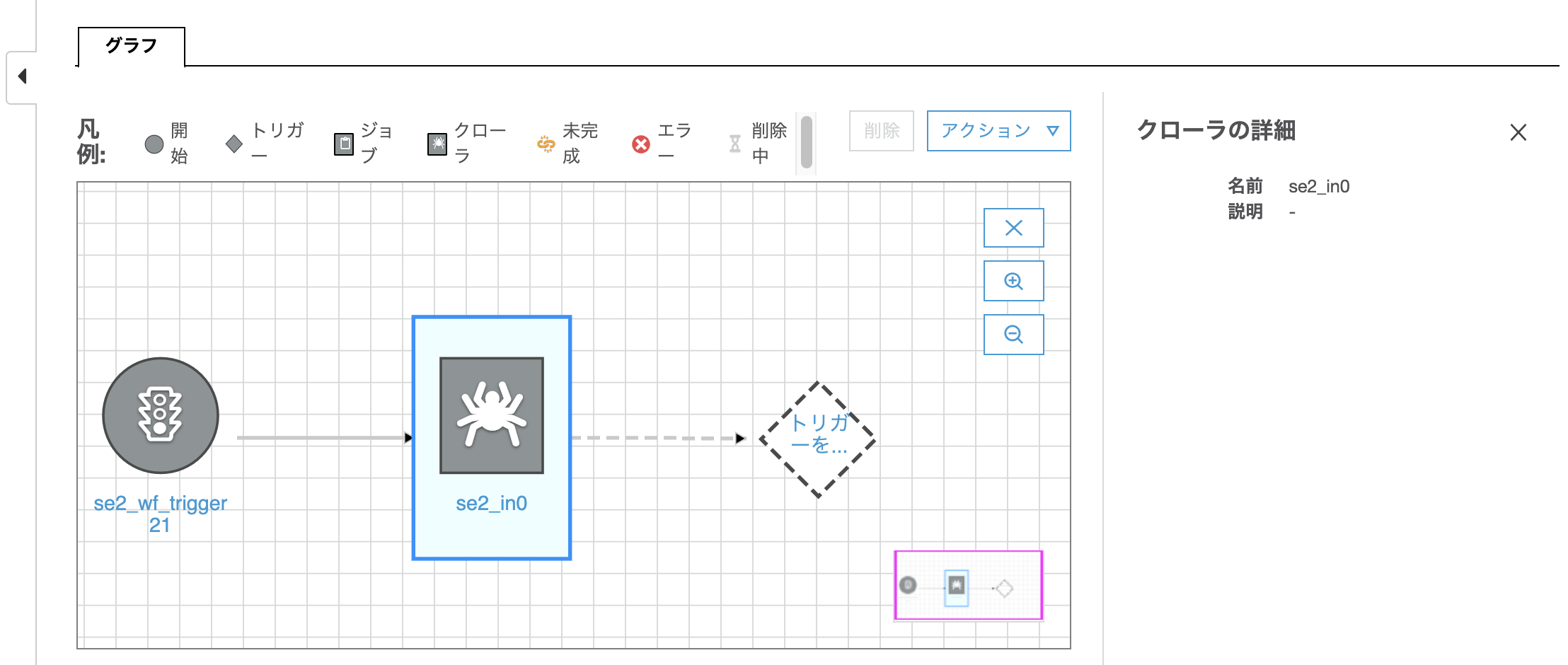
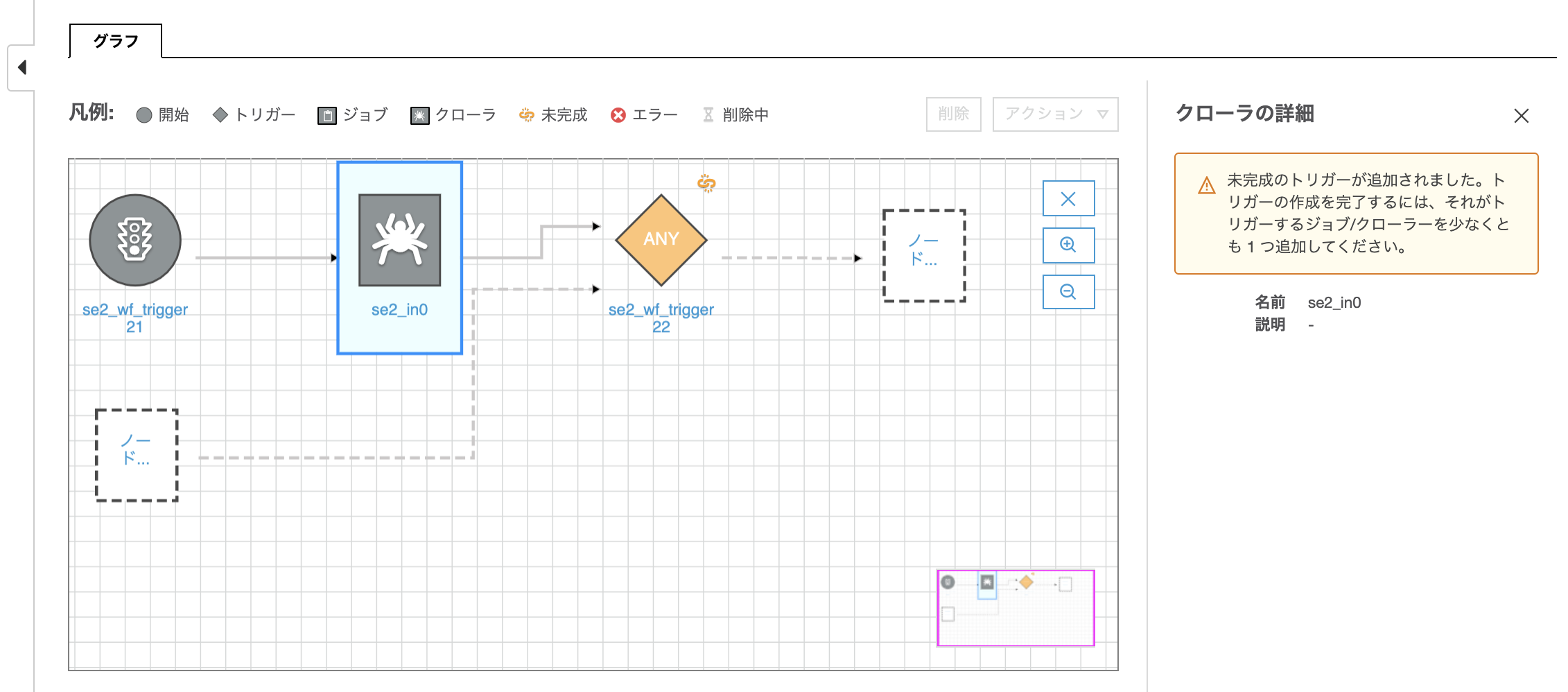
このように一瞬変な感じになったと思うが、これはまだトリガーでトリガーされるアクションが決まってない状態である。右側の"ノードを追加"をクリックしてトリガーされるアクションを定義していく。
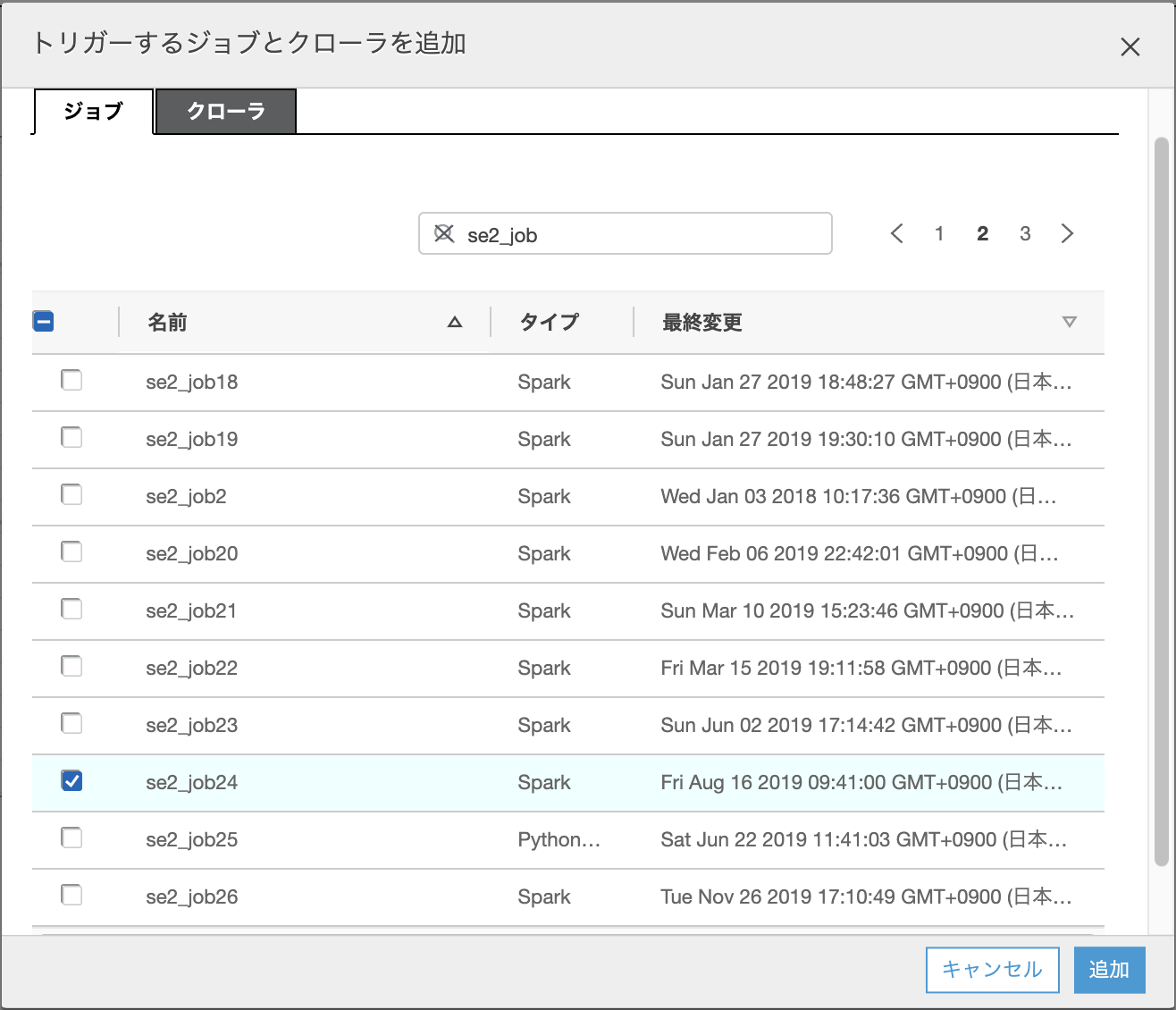
"ジョブ"のタブをクリックし、該当のジョブ"se2_job24"にチェックを入れ、[追加]をクリックする
1つ目のジョブが出来る
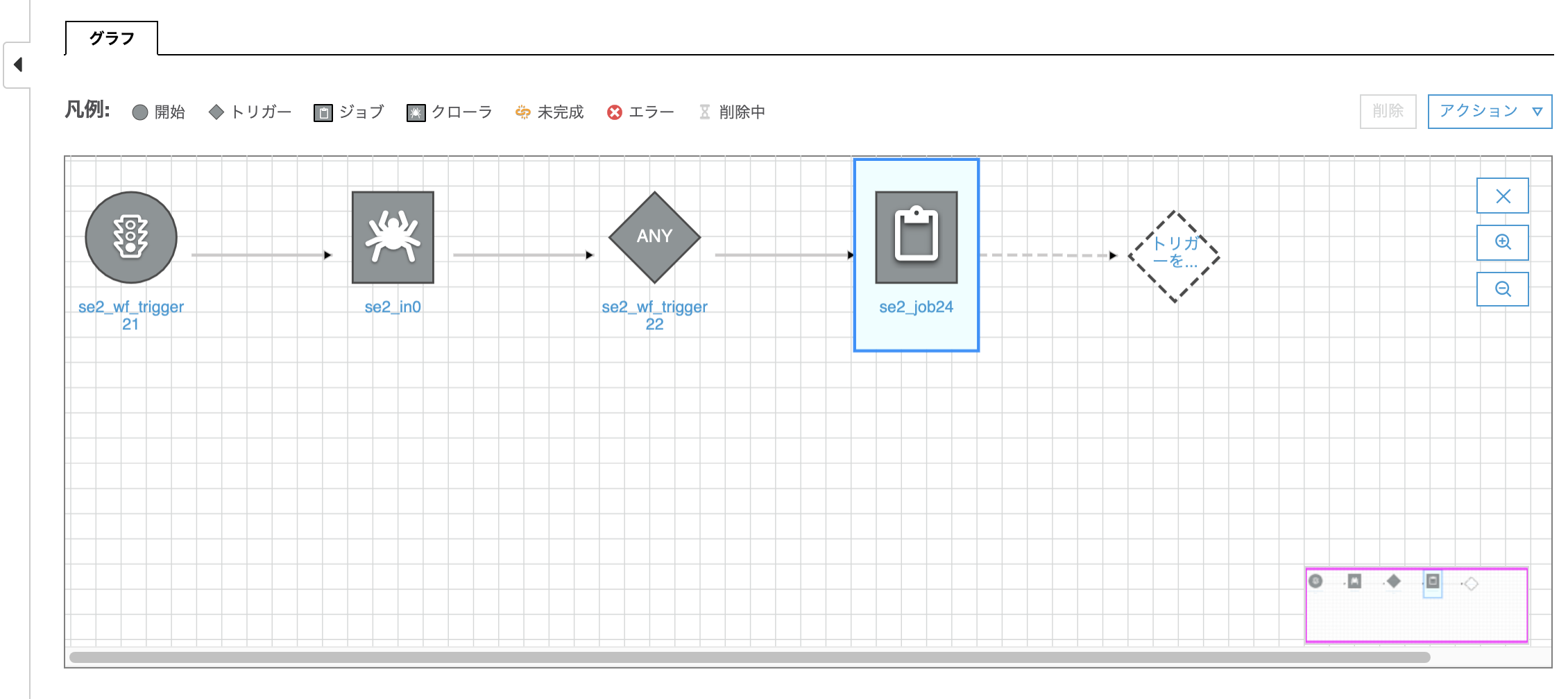
あとは同じ要領でトリガー(se2_wf_trigger23)と2つ目のジョブ(se2_job25)を追加する
数珠つなぎにジョブまたはクローラーをトリガーでつなげる。
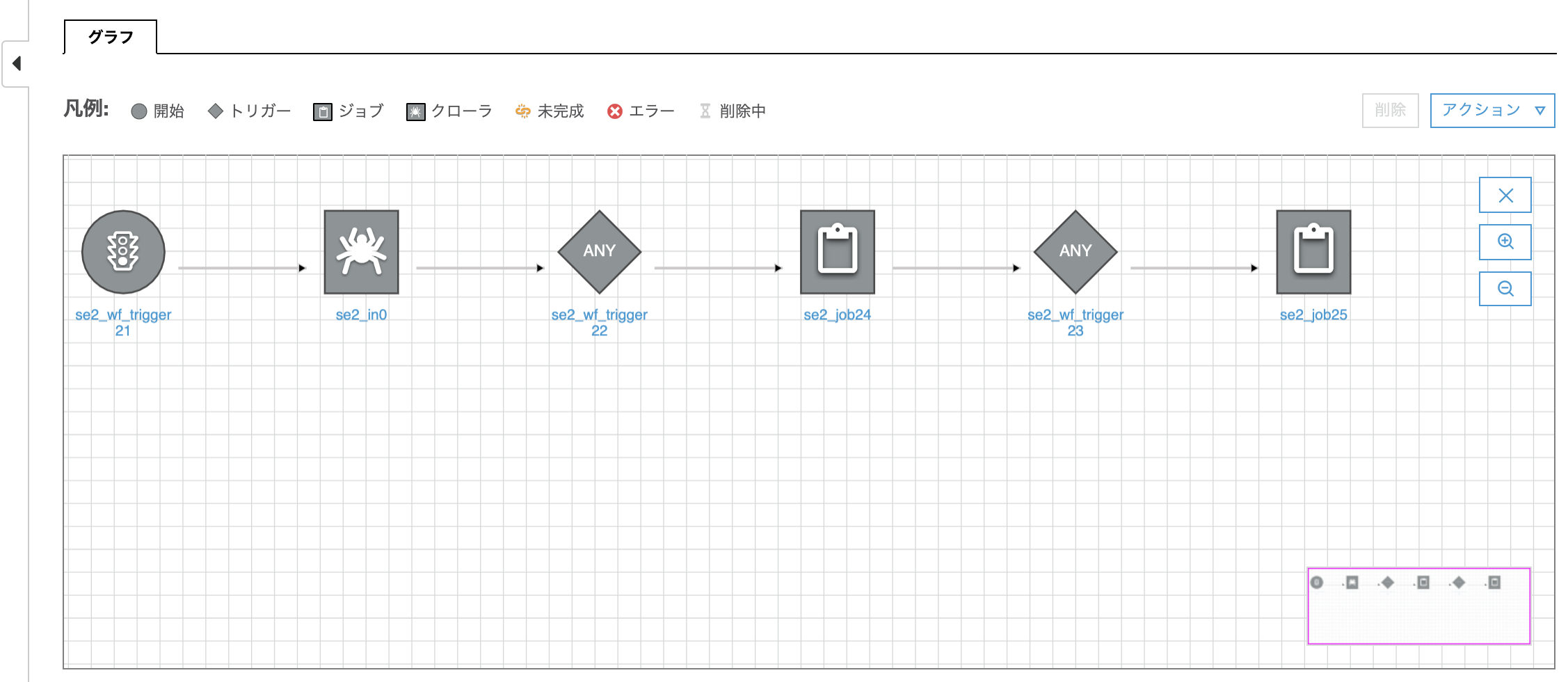
ワークフロー実行
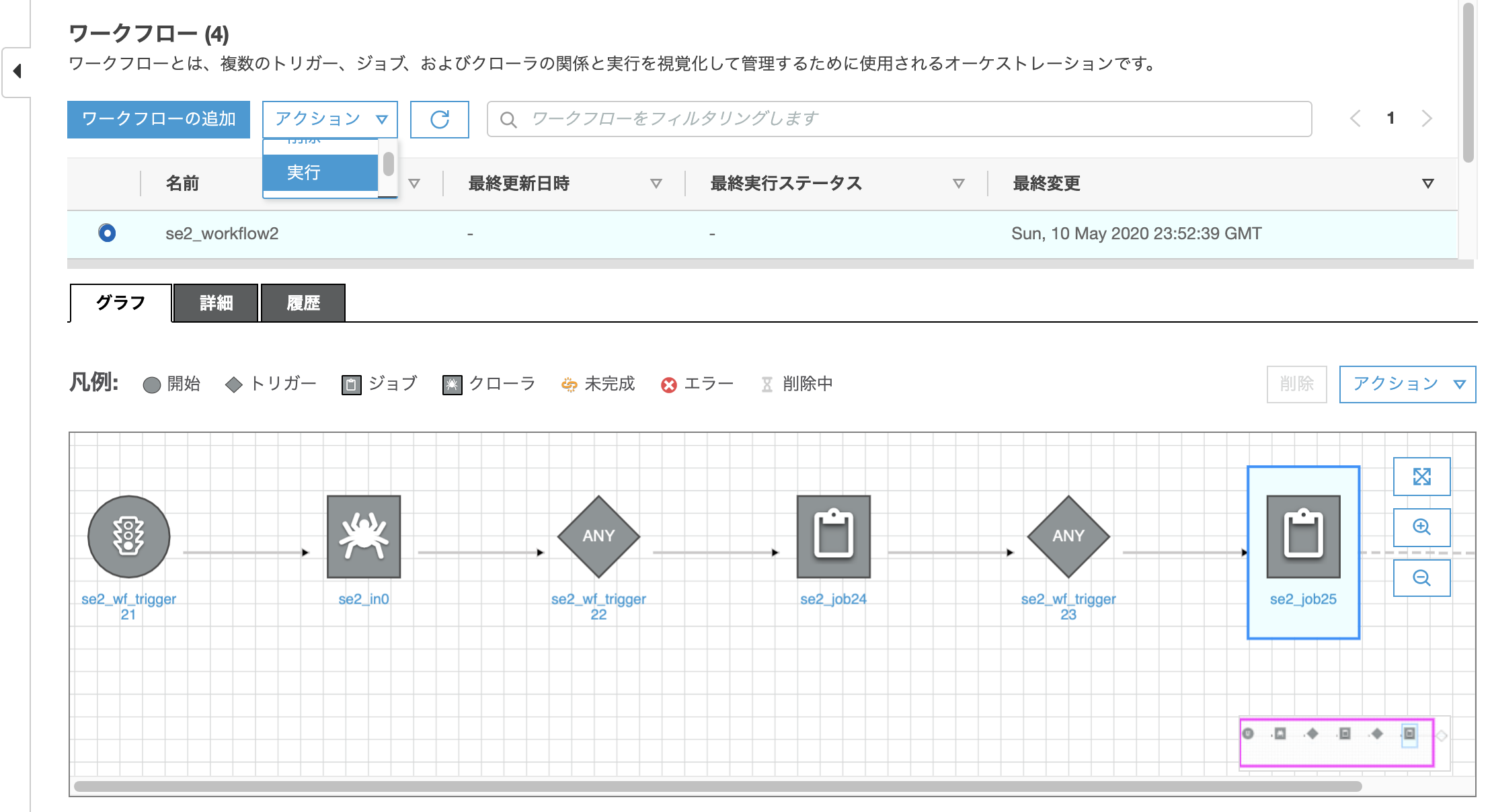
対象のworkflowにチェックを入れ、[アクション]->[実行]をクリック
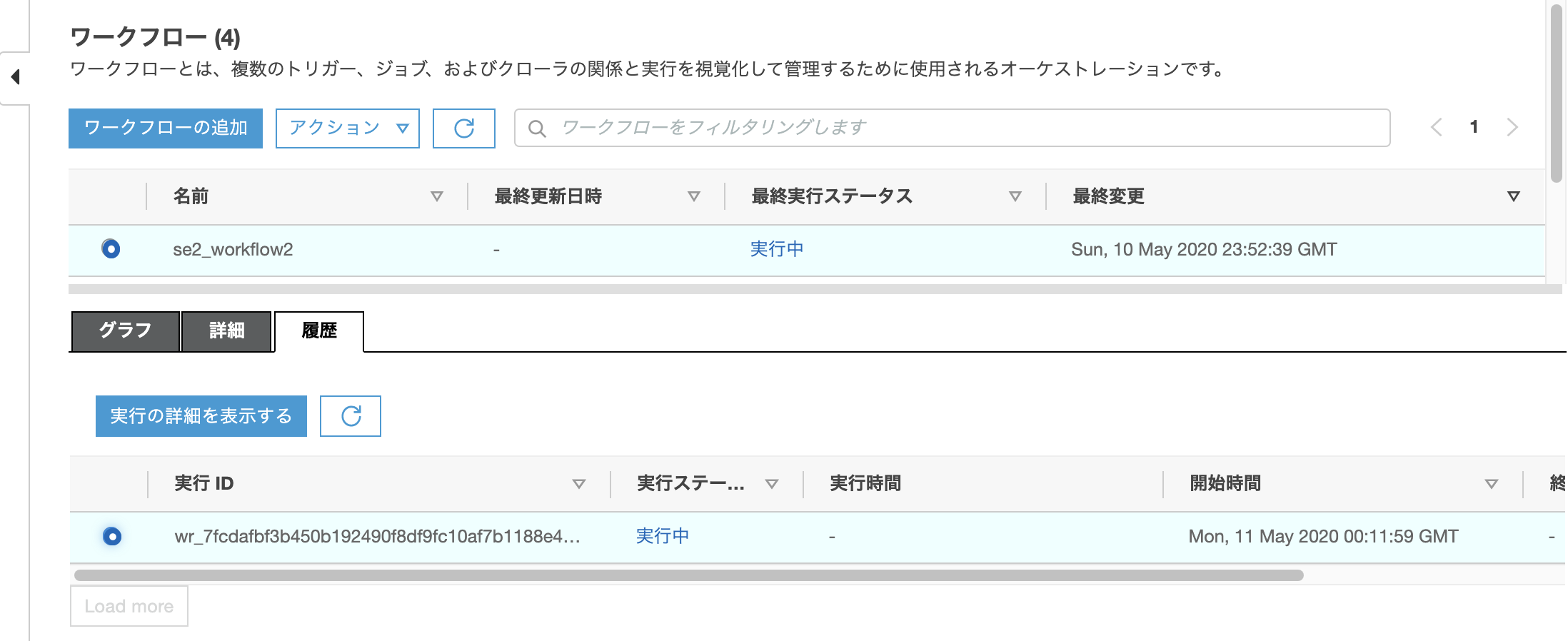
対象のworkflowにチェックを入れ、画面下の"履歴"タブをクリックし、”実行ID"にチェックを入れ、[実行の詳細を表示する]をクリックする
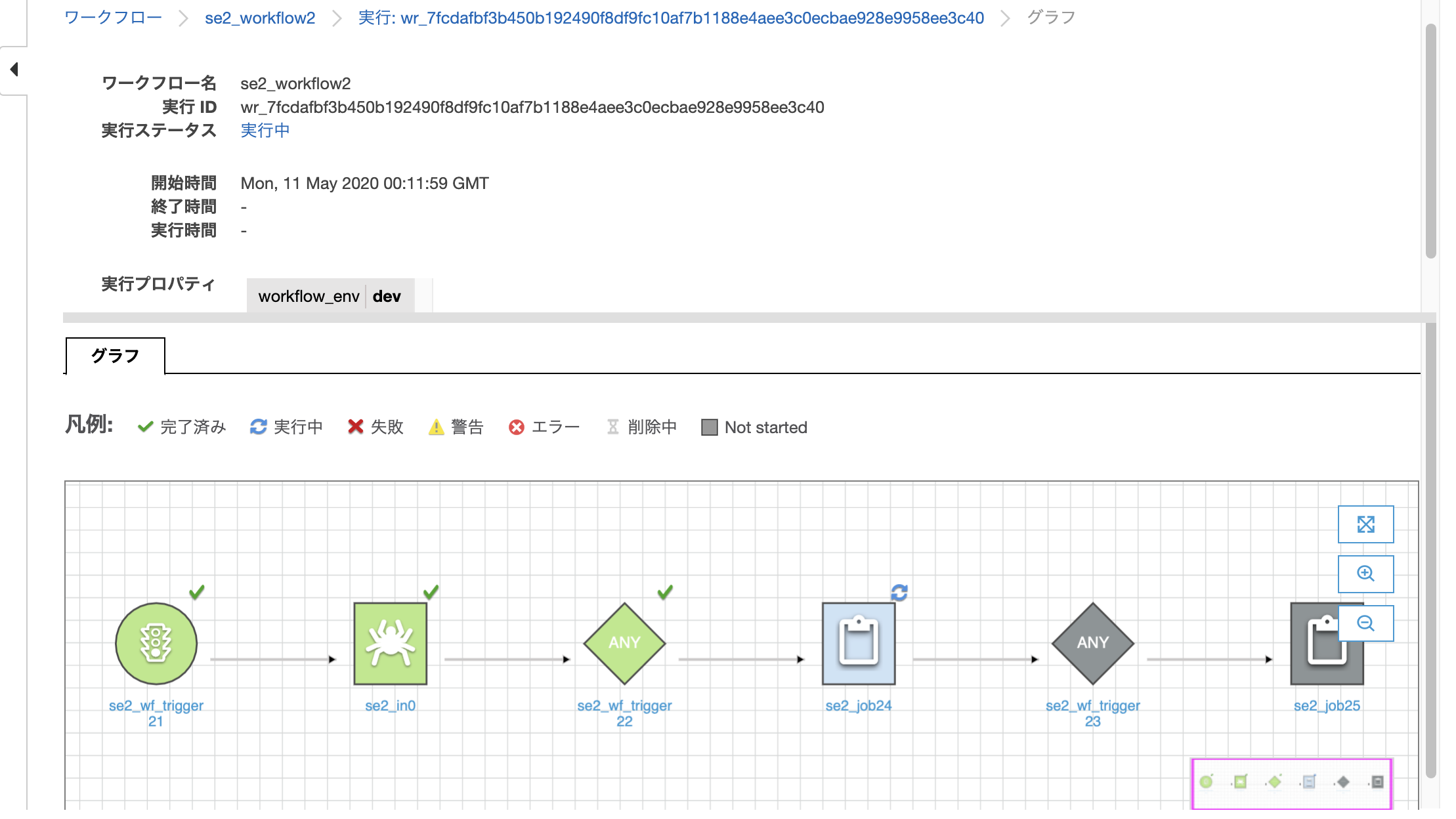
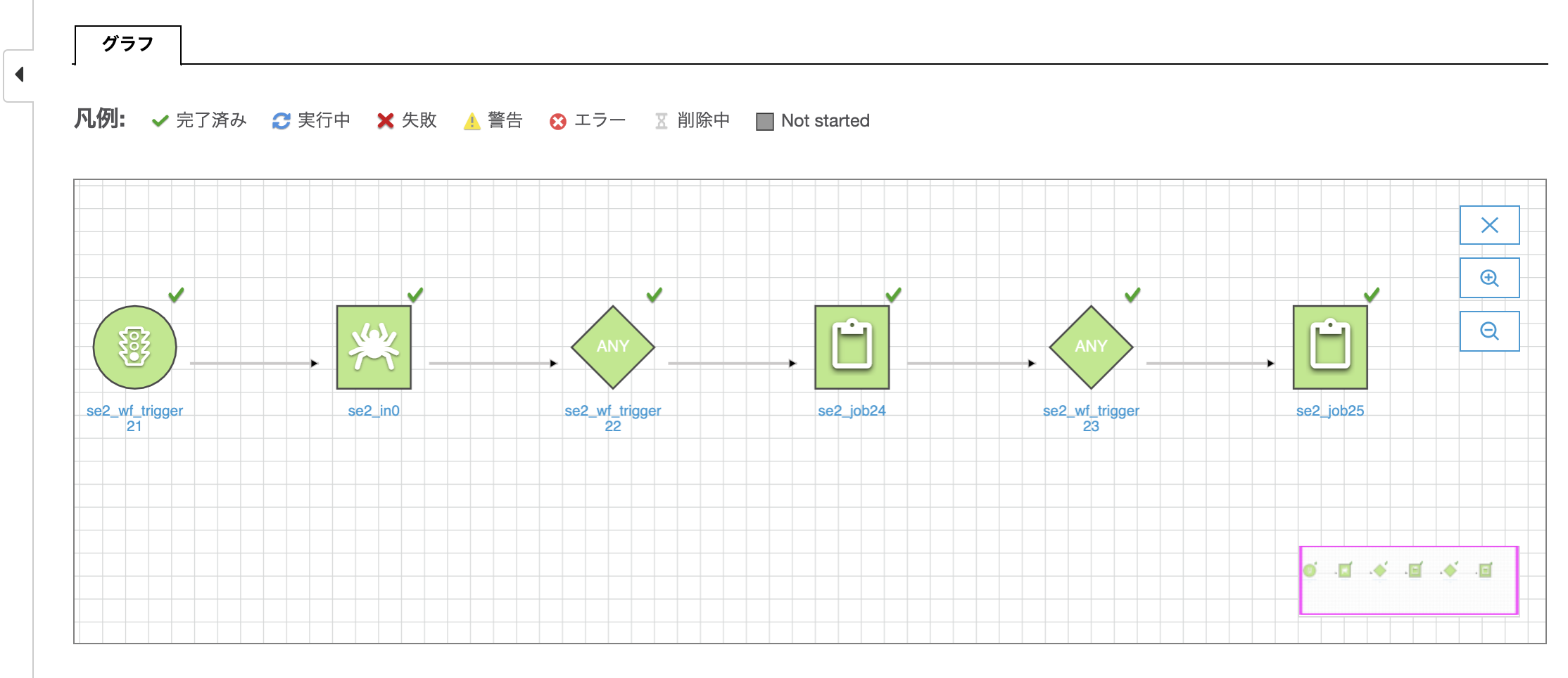
Workflowの実行状態が確認できる
緑色は完了を表しクローラーが完了していることがわかり、青色が実行中を表し次のジョブが実行中であることがわかる
確認
ジョブの正常終了
全てのジョブがグリーンで正常終了しているのがわかります
実行プロパティ(環境変数のようなもの)がひきわたされたか?
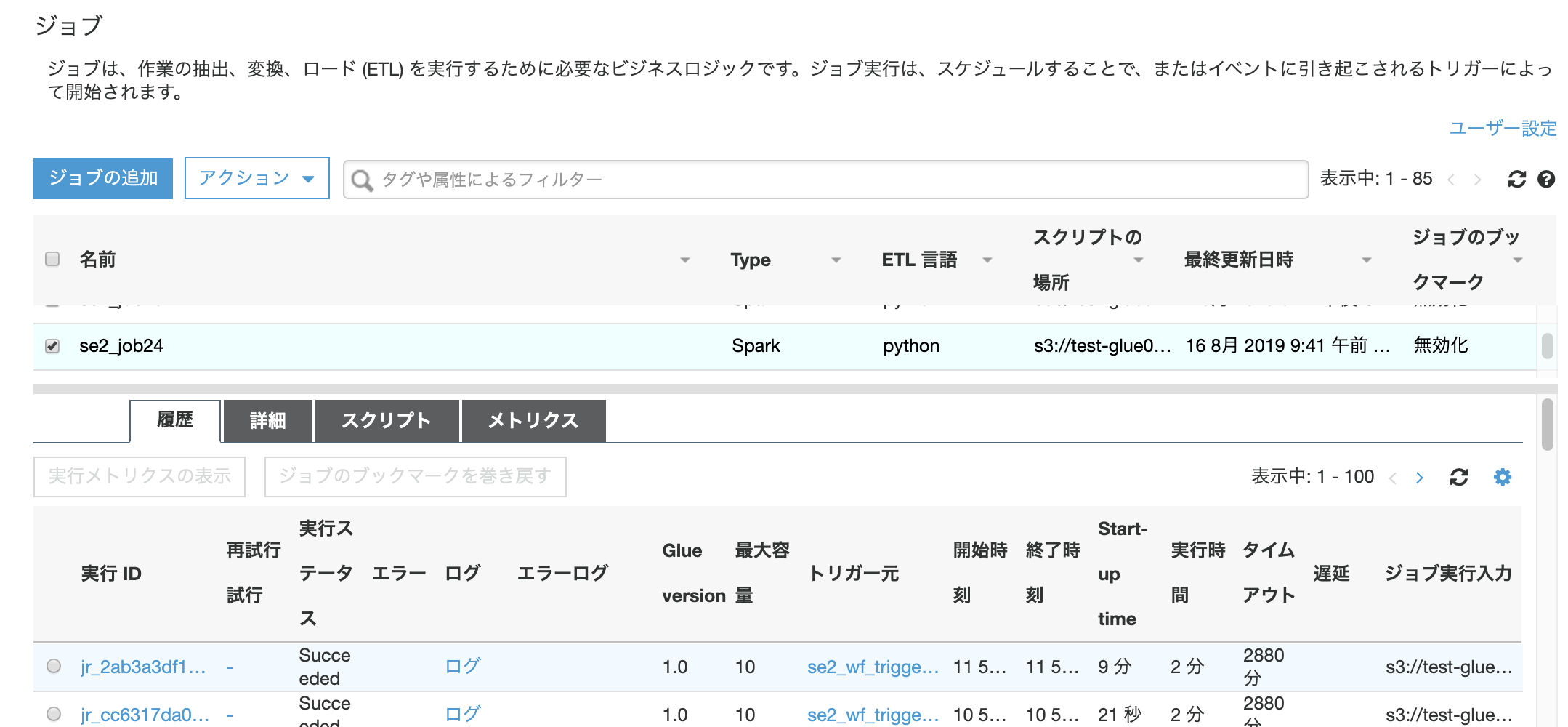
1つ目のジョブ(se2_job24)のログを確認します。画面下部の履歴タブの一番上の実行IDの「ログ」の箇所をクリックします。
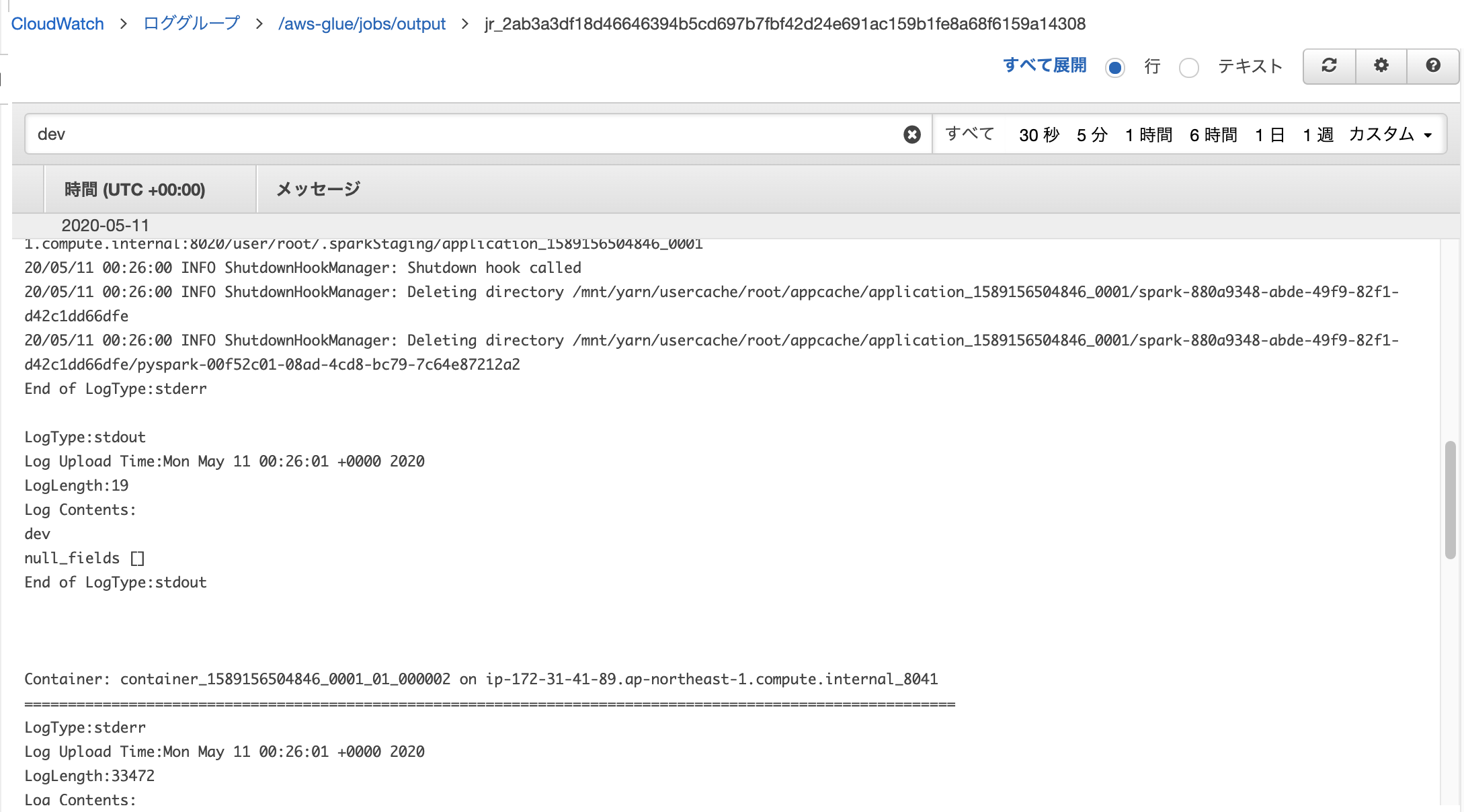
CloudWatch Logsに飛びます。検索窓にdevと入れて検索します。実行プロパティがworkflow_env:devで、ジョブの中でこの値をprintしているので、成功していればログに出力があります。ちょっとわかりずらいですが、以下のようにdevという文字列が表示されています。
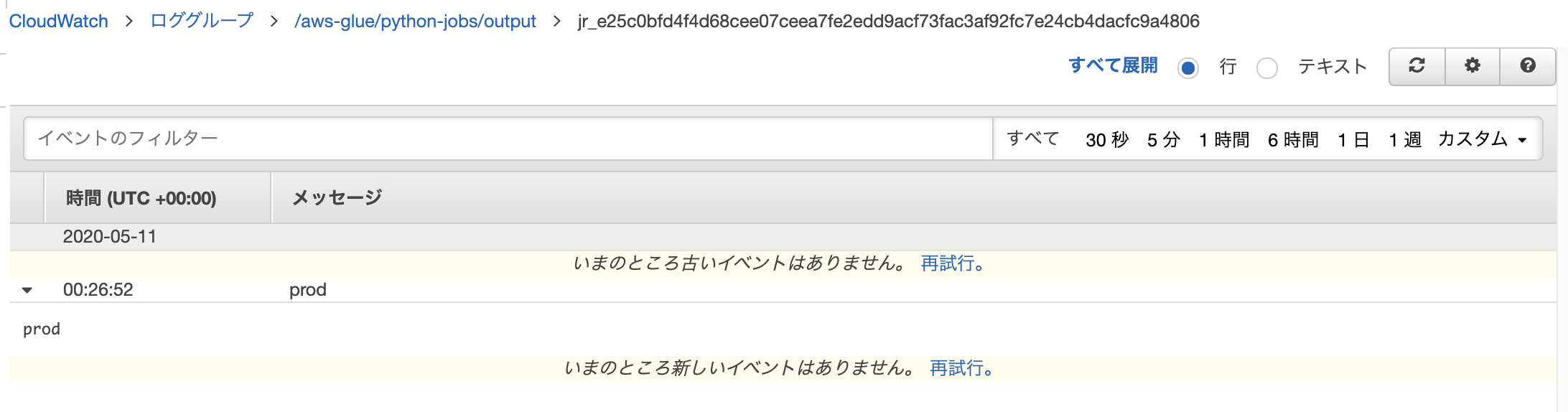
2つ目のジョブ(se2_job25)も同じようにログを確認します。以下のようにprodと表示されているのがわかります。これは1つ目のジョブの中でworkflow_envの値をdevからprodに変更し、その後でprintでworkflow_envを表示しているためです。
こちらも是非
ワークフロー実行プロパティの取得と設定
https://docs.aws.amazon.com/ja_jp/glue/latest/dg/workflow-run-properties-code.html
boto3 document(get_workflow_run_properties、put_workflow_run_properties)
https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/glue.html#Glue.Client.get_workflow_run_properties
PutWorkflowRunPropertiesアクション
https://docs.aws.amazon.com/ja_jp/glue/latest/dg/aws-glue-api-workflow.html#aws-glue-api-workflow-PutWorkflowRunProperties
サンプルコード Getting and Setting Workflow Run Properties
https://github.com/awsdocs/aws-glue-developer-guide/blob/master/doc_source/workflow-run-properties-code.md
あらためてgetResolvedOptions
https://docs.aws.amazon.com/ja_jp/glue/latest/dg/aws-glue-api-crawler-pyspark-extensions-get-resolved-options.html
Glueの使い方的な㊵(Workflowsでジョブフローの可視化)
https://qiita.com/pioho07/items/0cd0ae27b61f5914f78d
Glueの使い方まとめ
https://qiita.com/pioho07/items/32f76a16cbf49f9f712f