Crawler SchemaChangePolicy の効果をみてみる
今回使うGlueのリソース名
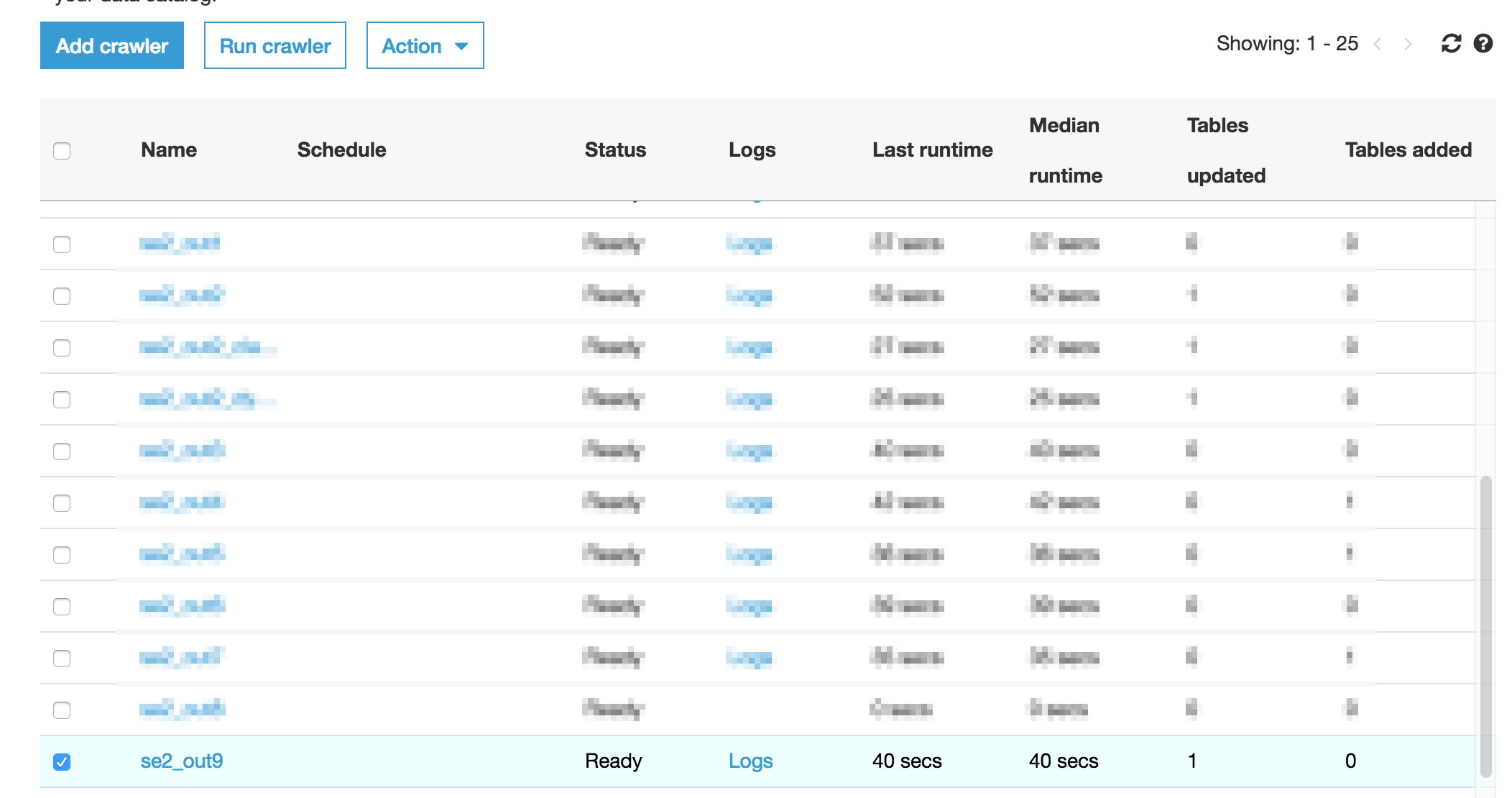
クローラー名
se2_in6
se2_out9
ジョブ名
se2_job9
データ
入力:in6
出力:out9
全体の流れ
- 前準備
- Crawler SchemaChangePolicy のデフォルト値確認
- Schema updates in the data store の確認
- CLIによる確認
※長くなったので、"Object deletion in the data store"は次回
前準備
今回使うサンプルジョブ、入力ファイル、出力ファイル
Glueの使い方的な②(csvデータをパーティション分割したparquetに変換)のジョブをse2_job9、入力データをin6、出力データをout9にそれぞれ複製して今回利用する。
上記で実行した処理は以下のCSVファイルをyear,month,day,hourでパーティション分割している。
deviceid,uuid,appid,country,year,month,day,hour
iphone,11111,001,JP,2017,12,14,12
android,11112,001,FR,2017,12,14,14
iphone,11113,009,FR,2017,12,16,21
iphone,11114,007,AUS,2017,12,17,18
other,11115,005,JP,2017,12,29,15
iphone,11116,001,JP,2017,12,15,11
pc,11118,001,FR,2017,12,01,01
pc,11117,009,FR,2017,12,02,18
iphone,11119,007,AUS,2017,11,21,14
other,11110,005,JP,2017,11,29,15
iphone,11121,001,JP,2017,11,11,12
android,11122,001,FR,2017,11,30,20
iphone,11123,009,FR,2017,11,14,14
iphone,11124,007,AUS,2017,12,17,14
iphone,11125,005,JP,2017,11,29,15
iphone,11126,001,JP,2017,12,19,08
android,11127,001,FR,2017,12,19,14
iphone,11128,009,FR,2017,12,09,04
iphone,11129,007,AUS,2017,11,30,14
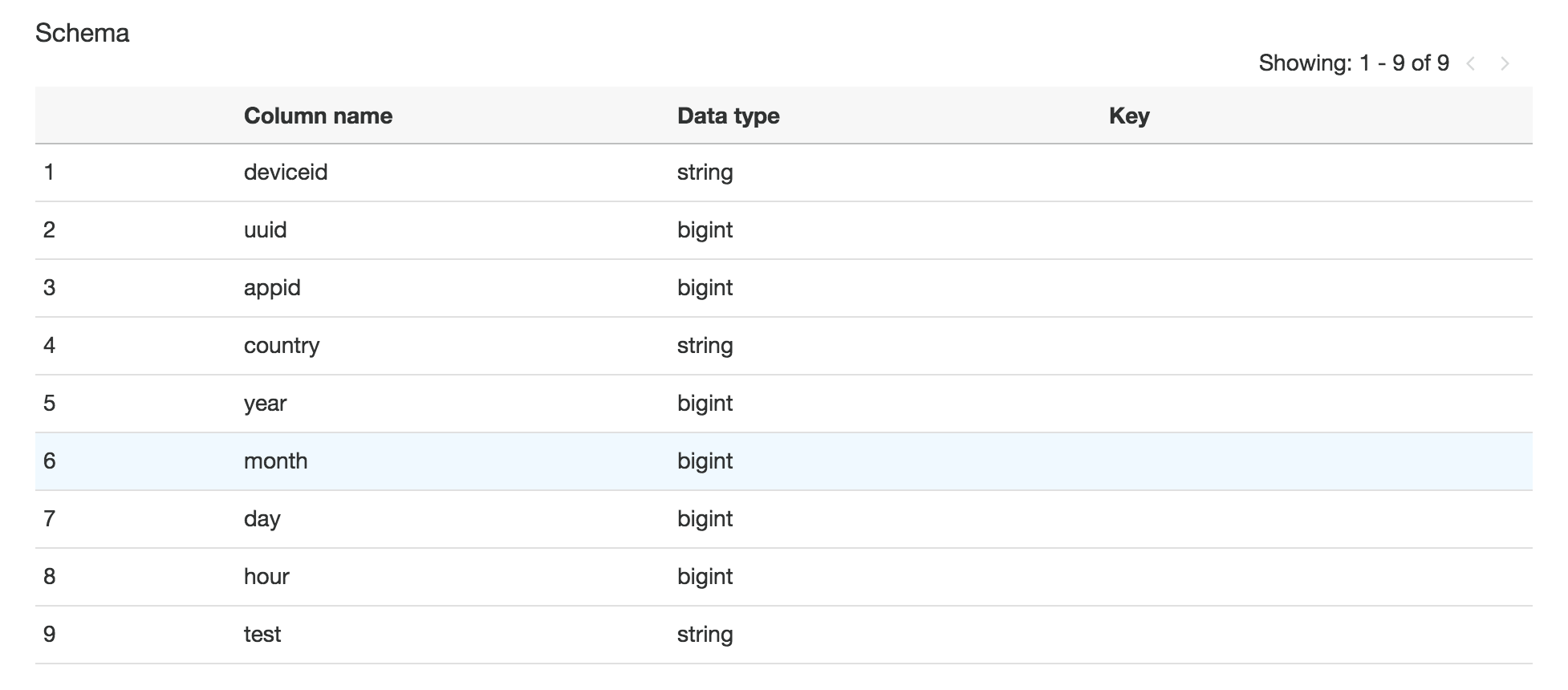
今回利用する入力データ(in6)をクローリングしたスキーマ情報

今回利用する出力データ(out9)をクローリングしたスキーマ情報

Athena によるデータ内容確認

Athena によるデータ件数確認
19件

ディレクトリ構成
in6に入力ファイル、out9に出力ファイル
$ aws s3 ls s3://test-glue00/se2/in6/
2018-05-27 21:11:45 0
2018-05-27 21:12:13 691 cvlog.csv
$ aws s3 ls s3://test-glue00/se2/out9/
PRE year=2017/
2018-05-27 21:23:08 0
2018-05-27 21:23:35 498 _common_metadata
2018-05-27 21:23:35 11419 _metadata
2018-05-27 21:23:35 0 year=2017_$folder$
1$ aws s3 ls s3://test-glue00/se2/out9/year=2017/
PRE month=11/
PRE month=12/
2018-05-27 21:25:01 0 month=11_$folder$
Crawler SchemaChangePolicy のデフォルト値確認
クローラーのEditをクリックし、以下の画面まで進み、"設定オプション(省略可能)"をクリック

SchemaChangePolicy が表示される

Schema updates in the data store
"クローラがデータストア内のスキーマの変更を検出すると、AWS Glueはデータカタログのテーブル更新をどのように処理する必要がありますか?"
SchemaChangePolicy の UpdateBehavior と呼ばれ3種類から選べる
- "データカタログのテーブル定義を更新する"
- "新規列のみを追加します"
- "変更を無視して、データカタログのテーブルを変更しない"
"データカタログのテーブル定義を更新する"
テーブルのスキーマ情報を手動などで変更した場合、クローラーによって再度更新が行われます。(つまり戻ります)
例えば以下のスキーマに

①9個目のカラムの追加や、dayのカラムをStringからBIGINTに修正

クローラーを実行すると、クローラーの実行後にupdatedが1となり更新が行われます。
クローラー実行後のスキーマの内容は以下のようになり、元のスキーマ情報に戻っています

②入力csvファイルのcvlog.csvに、列を追加(testという名前の列)したcvlog1.csvを作成し、S3の同じ場所にアップする
deviceid,uuid,appid,country,year,month,day,hour
iphone,11111,001,JP,2017,12,14,12
android,11112,001,FR,2017,12,14,14
iphone,11113,009,FR,2017,12,16,21
iphone,11114,007,AUS,2017,12,17,18
other,11115,005,JP,2017,12,29,15
iphone,11116,001,JP,2017,12,15,11
pc,11118,001,FR,2017,12,01,01
pc,11117,009,FR,2017,12,02,18
iphone,11119,007,AUS,2017,11,21,14
other,11110,005,JP,2017,11,29,15
iphone,11121,001,JP,2017,11,11,12
android,11122,001,FR,2017,11,30,20
iphone,11123,009,FR,2017,11,14,14
iphone,11124,007,AUS,2017,12,17,14
iphone,11125,005,JP,2017,11,29,15
iphone,11126,001,JP,2017,12,19,08
android,11127,001,FR,2017,12,19,14
iphone,11128,009,FR,2017,12,09,04
iphone,11129,007,AUS,2017,11,30,14
deviceid,uuid,appid,country,year,month,day,hour,test
iphone,11111,001,JP,2017,12,14,12,a
android,11112,001,FR,2017,12,14,14,a
iphone,11113,009,FR,2017,12,16,21,b
iphone,11114,007,AUS,2017,12,17,18,c
other,11115,005,JP,2017,12,29,15,c
iphone,11116,001,JP,2017,12,15,11,a
pc,11118,001,FR,2017,12,01,01,a
pc,11117,009,FR,2017,12,02,18,a
iphone,11119,007,AUS,2017,11,21,14,a
other,11110,005,JP,2017,11,29,15,a
iphone,11121,001,JP,2017,11,11,12,a
android,11122,001,FR,2017,11,30,20,a
iphone,11123,009,FR,2017,11,14,14,a
iphone,11124,007,AUS,2017,12,17,14,a
iphone,11125,005,JP,2017,11,29,15,a
iphone,11126,001,JP,2017,12,19,08,a
android,11127,001,FR,2017,12,19,14,a
iphone,11128,009,FR,2017,12,09,04,a
iphone,11129,007,AUS,2017,11,30,14,a
クローリングする。
結果のスキーマ情報に、testの列ができている
Athenaによる確認。test列ができている。以前のデータはtest列はnull


「"データカタログのテーブル定義を更新する"は常にクローリングした結果をスキーマに反映したいときに使う」
これがデフォルトです
"新規列のみを追加します"
※201805頃出た新しい機能
https://forums.aws.amazon.com/ann.jspa?annID=5696
S3にデータがある場合にのみ有効なオプションで、検出した新しい列は追加されますが、既存の列のタイプは Data Catalog で削除または変更されません。
①と同じ作業を実施すると、更新がそのまま残っている
詳細割愛
②と同じ作業を実施すると、追加した列(testという名前)が追加されている。

Athenaで確認。追加した列(testという名前)が追加されている

③入力csvファイルのcvlog.csvに、列を追加(testという名前の列)したcvlog1.csvを作成し、S3の同じ場所にアップする
deviceid,uuid,appid,country,year,month,day,hour
iphone,11111,001,JP,2017,12,14,12
android,11112,001,FR,2017,12,14,14
iphone,11113,009,FR,2017,12,16,21
iphone,11114,007,AUS,2017,12,17,18
other,11115,005,JP,2017,12,29,15
iphone,11116,001,JP,2017,12,15,11
pc,11118,001,FR,2017,12,01,01
pc,11117,009,FR,2017,12,02,18
iphone,11119,007,AUS,2017,11,21,14
other,11110,005,JP,2017,11,29,15
iphone,11121,001,JP,2017,11,11,12
android,11122,001,FR,2017,11,30,20
iphone,11123,009,FR,2017,11,14,14
iphone,11124,007,AUS,2017,12,17,14
iphone,11125,005,JP,2017,11,29,15
iphone,11126,001,JP,2017,12,19,08
android,11127,001,FR,2017,12,19,14
iphone,11128,009,FR,2017,12,09,04
iphone,11129,007,AUS,2017,11,30,14
deviceid,uuid,appid,country,year,month,day,hour,test
iphone,11111,001,JP,2017,12,14,12,a
android,11112,001,FR,2017,12,14,14,a
iphone,11113,009,FR,2017,12,16,21,b
iphone,11114,007,AUS,2017,12,17,18,c
other,11115,005,JP,2017,12,29,15,c
iphone,11116,001,JP,2017,12,15,11,a
pc,11118,001,FR,2017,12,01,01,a
pc,11117,009,FR,2017,12,02,18,a
iphone,11119,007,AUS,2017,11,21,14,a
other,11110,005,JP,2017,11,29,15,a
iphone,11121,001,JP,2017,11,11,12,a
android,11122,001,FR,2017,11,30,20,a
iphone,11123,009,FR,2017,11,14,14,a
iphone,11124,007,AUS,2017,12,17,14,a
iphone,11125,005,JP,2017,11,29,15,a
iphone,11126,001,JP,2017,12,19,08,a
android,11127,001,FR,2017,12,19,14,a
iphone,11128,009,FR,2017,12,09,04,a
iphone,11129,007,AUS,2017,11,30,14,a
dayのカラムをBIGINTからStringに修正

クローリングする。
結果のスキーマ情報に、dayのカラムはStringのまま変更されていない。新しいtest列ができている。

Athenaによる確認。test列ができている。以前のデータはtest列はnull

「"新規列のみを追加します"は追加した列を反映しそれ以外はそのままにしたい時に使う」
"変更を無視して、データカタログのテーブルを変更しない"
テーブルのスキーマ情報を手動などで変更した場合、クローラーによって再度更新が行われない。(つまり戻らない)
①と同じ作業を実施すると、クローラーによる更新は行われません。(つまりクローラーによるスキーマ変更はなくなる)
クローラーを実行すると、クローラーの実行後にTable Updatedは0

スキーマも修正した状態が残っている

②と同じ作業を実施すると、クローラーによる更新は行われません。(つまりクローラーによるスキーマ変更はなくなる)
追加した列(testという名前)も反映されない。
Athenaで確認。
test列は出てこない

件数は入力ファイルをコピーしたので19件の倍の38件で合っている

「"変更を無視して、データカタログのテーブルを変更しない"はクローラーによるスキーマ変更したくない時に使う(またはmsck prepair tableだけさせたい時とか?)」
CLIによる確認
get-crawler で SchemaChangePolicy の確認ができる
Crawler の se2_out9 の情報をコマンドで見てみる
$ aws glue get-crawler --name se2_out9
{
"Crawler": {
"CrawlElapsedTime": 0,
"Name": "se2_out9",
"CreationTime": 1527423893.0,
"LastUpdated": 1527490194.0,
"Targets": {
"JdbcTargets": [],
"S3Targets": [
{
"Path": "s3://test-glue00/se2/out9",
"Exclusions": [
"_common_metadata",
"_metadata"
]
}
]
},
"LastCrawl": {
"Status": "SUCCEEDED",
"LogStream": "se2_out9",
"MessagePrefix": "99999999-9999-9999-9999-e3a72b9ccff7",
"StartTime": 1527490210.0,
"LogGroup": "/aws-glue/crawlers"
},
"State": "READY",
"Version": 7,
"Role": "test-glue",
"DatabaseName": "se2",
"SchemaChangePolicy": {
"DeleteBehavior": "LOG",
"UpdateBehavior": "UPDATE_IN_DATABASE"
},
"TablePrefix": "se2_",
"Classifiers": []
}
}
- "UpdateBehavior"がGUIだと以下です

Logが、"データカタログのテーブル定義を更新する"
MergeNewColumnsが、"新規列のみを追加します"
UPDATE_IN_DATABASEが、"変更を無視して、データカタログのテーブルを変更しない"
でGUIだと↓

- "DeleteBehavior"がその下の部分でこちらは別の機会に

To Be Continue
Object deletion in the data store の効用と Crawler APIによるConfiguration option の確認
こちらも是非
AWS Glue コンソールでのクローラの設定
https://docs.aws.amazon.com/ja_jp/glue/latest/dg/crawler-configuration.html
SchemaChangePolicy 構造
https://docs.aws.amazon.com/ja_jp/glue/latest/dg/aws-glue-api-crawler-crawling.html#aws-glue-api-crawler-crawling-SchemaChangePolicy
Glueの使い方まとめ
https://qiita.com/pioho07/items/32f76a16cbf49f9f712f