GlueのDynamicFrameではなく、GlueでDataFrameを使ってデータ入力出力する
ジョブの内容
csvファイルをparquetに変換します。
※"Glueの使い方的な①(GUIでジョブ実行)"(以後①とだけ書きます)と同じ処理です。データ入力と出力部分をDynamicFrameからDataFrameに変更します。
ジョブ名
se2_job14
前準備
IAMロールなどは①をご確認ください。
今回使うサンプルログファイル(19件)
csvlog.csv
deviceid,uuid,appid,country,year,month,day,hour
iphone,11111,001,JP,2017,12,14,12
android,11112,001,FR,2017,12,14,14
iphone,11113,009,FR,2017,12,16,21
iphone,11114,007,AUS,2017,12,17,18
other,11115,005,JP,2017,12,29,15
iphone,11116,001,JP,2017,12,15,11
pc,11118,001,FR,2017,12,01,01
pc,11117,009,FR,2017,12,02,18
iphone,11119,007,AUS,2017,11,21,14
other,11110,005,JP,2017,11,29,15
iphone,11121,001,JP,2017,11,11,12
android,11122,001,FR,2017,11,30,20
iphone,11123,009,FR,2017,11,14,14
iphone,11124,007,AUS,2017,12,17,14
iphone,11125,005,JP,2017,11,29,15
iphone,11126,001,JP,2017,12,19,08
android,11127,001,FR,2017,12,19,14
iphone,11128,009,FR,2017,12,09,04
iphone,11129,007,AUS,2017,11,30,14
S3に配置
$ aws s3 ls s3://test-glue00/se2/in0/
2018-01-02 15:13:27 0
2018-01-02 15:13:44 691 cvlog.csv
実行コード
適当なGlueジョブを作成し、できあがったジョブの中身のコードを以下のコードで上書きする
inferSchemaでデータ型をSpark側で自動で類推する。DataFrameにしているので型が必要だから。
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
args = getResolvedOptions(sys.argv, ['TempDir','JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
df = spark.read.format("csv").option("header", "true").option("inferSchema", "true").load('s3://test-glue00/se2/in0/*.csv', header=True)
output='s3://test-glue00/se2/out14/'
codec='snappy'
df.write.mode("overwrite").parquet(output,compression=codec)
job.commit()
クローラー作成し実行、テーブル確認
出力先のS3パスへのクローラーを作成し、クローラー実行
出来上がったテーブルが以下のようになる
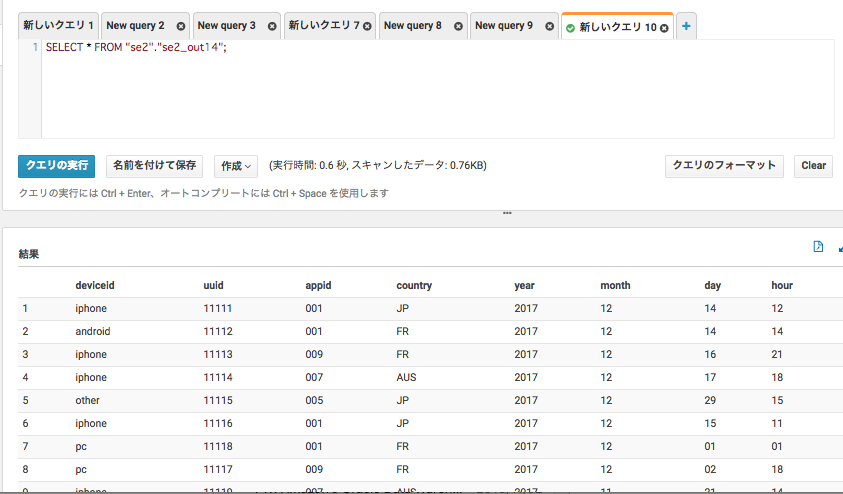
Athena確認
こちらも是非
Glueの使い方まとめ
https://qiita.com/pioho07/items/32f76a16cbf49f9f712f