実務未経験者である私ですが、この度なんと実務案件に挑戦する機会をいただきました。その時の経験や学び、成果をここに記しておこうと思います。私と同じような境遇の人のみならず、さまざまな方にご覧いただけると非常にうれしいです。
自己紹介
Over30の方のアラサー。未経験からエンジニアへの転職を目指しています。Techacademyでバックエンドとフロントエンド、ウェブデザインを学んだ後、Rails Tutorialやその他書籍を通じて勉強していました。
今回の実務案件に参加する前は、AWS等のインフラの知見は一切ありませんでした。しかし、「30歳を過ぎている場合、最低レベルでも実務レベルじゃないとエンジニア転職できないだろう」との思いで日々学習に励んでいたところ、本案件の募集があったため即応募。熱意が認められたのか、本案件を受注することができました。
案件の概要
運営中のWEBサービス「独学エンジニア」のKPIモニタリング体制の整備が今回の案件となります。
状況を説明しますと、運用中のWebサービスであるにもかかわらずデータ分析アプリ・ツールが全く導入されておらず、新規登録者数や有料購読者数などのKPIをグラフィックなインターフェイスで手軽にモニタリングできない状態でした。
しかも、SQLでデータを分析するにも、本番DBに踏み台サーバーからmysql接続して行う以外の方法がありませんでした。このような状況を脱するために、クライアントが希望する要件を満たすアプリ・ツールを開発or導入するのが本案件の中心的な課題となります。
要件定義
本案件の主な要件は次の通りです。
機能要件
・SQLの発行によりダッシュボードを自由に構築できる
・主要な指標を数字とグラフで表示できる
・ダッシュボードのモニタリング指標が自動更新される
・ユーザー管理機能がある
・新規ユーザーへ招待メールを送ることができる
・adminと非adminで権限を分けられる
・adminが非adminに自由に権限を付与できる
など
非機能要件
・ユーザー名とメルアドへのマスキング処理がされており、個人情報は閲覧できない
・マスキングされたデータの値がユニークになっている
・分析ツール利用時に本サービス用DBサーバーに負荷をかけない
・その他本サービス用DBサーバーに大きな負荷をかける処理の実装は禁止
・マスキング等の処理が自動で実行される
・ユーザーがデータベースの情報を更新、追加、削除できない
・ダッシュボードの表示速度は3秒以内
・分析ツールへの通信がhttps通信になっている
・分析ツールとDBサーバーとの通信もSSL化されている
・死活監視が実装できている
・エラー監視が実装できている
など
課題
本案件においては、上記の全要件を満たすことが最低条件でした。それ以外の指定は何もありませんでした。そのため、さまざまな課題解決の方法が考えられました。
例えば、完全自作のアプリケーションを用意することも選択肢の一つでした。その一方で、AWSやサードパーティのツールを使いつつ、不十分な点を自作で補うという手段も考えられました。ツールを使う場合、どのツールを選ぶかも自分で考える必要がありました。
実際にはBIツールを導入することになるのですが、どのBIツールを選べば要件を不足なく満たせるのかを自分でリサーチする必要はもちろんありました。予算や機能などの観点からある程度は絞れましたが、残った候補(最低限の要件を満たしている)の中から一つのツールを合理的に決めることも当然求められました。
ただし自分が調査した限りでは、マスキング処理の機能はどのBIツールにも備わっていませんでした。そこで、マスキング処理に関しては自作することにしました。
また本案件では、「分析ツール利用時に本サービス用DBサーバーに負荷をかけない」という用件があることから、BIツールを本サービス用RDSに直接つなぐわけにはいかないので、本サービス用RDSからBIツール用RDSへデータ転送するシステムを構築しなければなりませんでした。
もちろん、本サービス用DBサーバーに大きな負荷をかける処理の実装はNGですので、本サービス用DBサーバーからデータ取得する最も負荷のかからない方法を考えて実装する必要もありました。
また、個人情報を見れてしまう機会をBIツールのユーザーに与えないようにするために、BIツール用RDSにインポートするデータはマスキング処理後のものでなければならないので、それを実現できるシステムを構築することも求められました。
しかも、これらの処理は定期的に実行しなければなりませんでした。定期実行する方法としては、Webサーバー等でcronを動かしたり、AWS CloudWatchEventを使ったりするなど、いろいろな方法がありますが、これらの中から最善の手段を選ぶ必要がありました。
死活監視・エラー監視についても、AWSやサードパーティのツールを導入することを検討しました。
システム構成
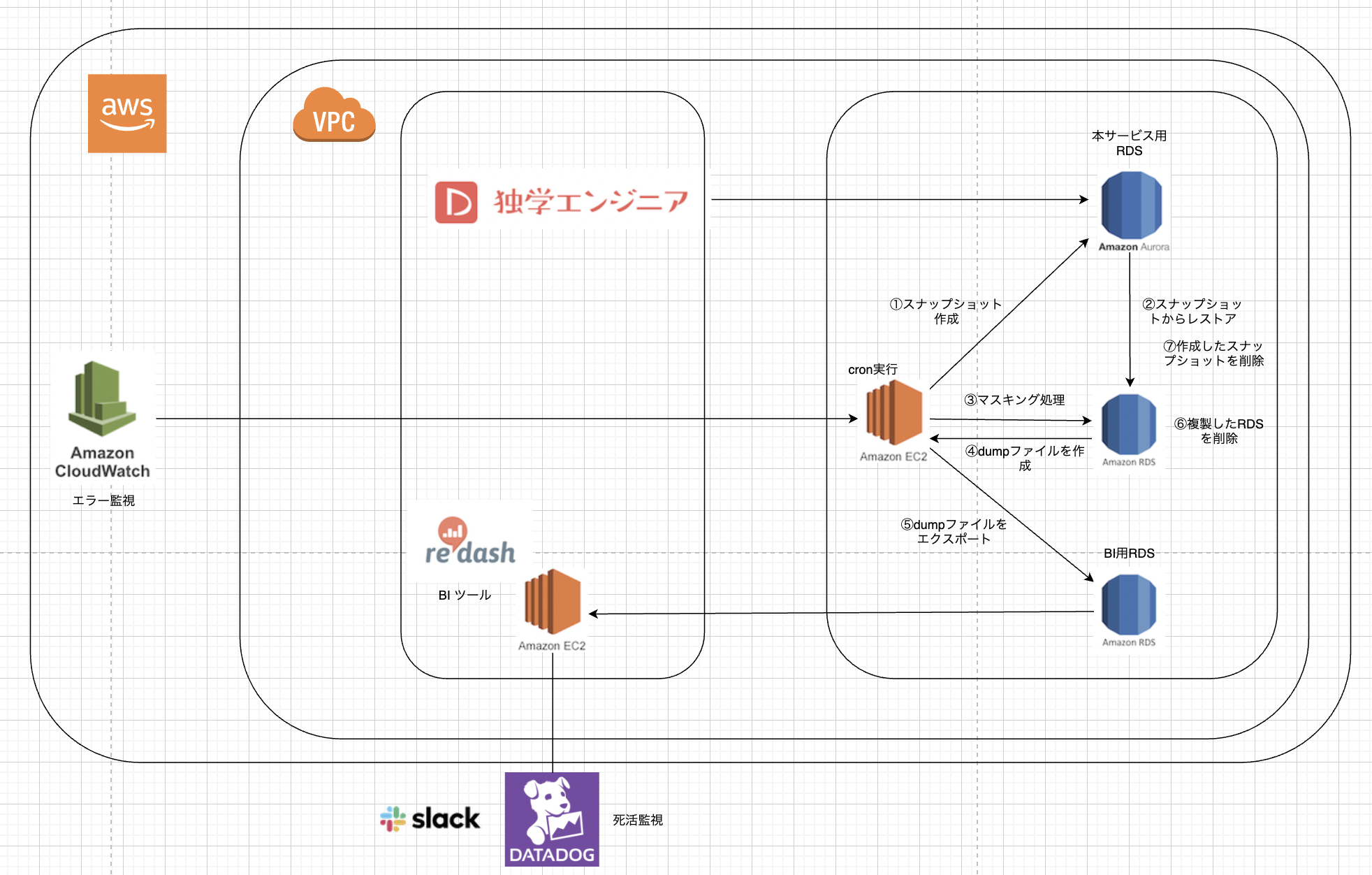
こちらが、私が最終的に構築したシステムになります。
BIツールはRedashを採用
予算が5000円〜1万円のレンジ内だったため、無料のOSS(オープンソースソフトウェア)である方が好ましいということから、Redashを採用しました。同じOSSのBIツールであるMetabaseと比較して最後までどちらにするかで悩んだのですが、実際に両者を使ってみてRedashを選びました。
Metabaseの長所は、簡単なモニタリング指標であればSQLを使わずに作れることです。Redashの場合、ダッシュボードの作成にSQLを必ず使わないといけません。しかし、本案件で構築するモニタリングツールのユーザーは、エンジニアかSQLの分かるマーケターのどちらかなので、その点は考慮する必要がないと判断しました。
MetabaseにないRedashの長所としては、「より細かな権限管理が可能」「データソースが50以上と豊富で将来的に応用が利く(例えばスプレッドシートやCSVからデータを取得したくなった場合に対応できる)」「ダッシュボードがシンプルで使いやすい(これは好みの問題ですが)」という点が挙げられます。これらは必須の要件ではありませんでしたが、ある方が良いだろうということでRedashの採用に至りました。
今回の案件でRedashを始めて触ったため、その実装においては苦労することがいろいろありました。苦労した作業については下記記事にまとめておりますので、ご覧いただけますと幸いです。
マスキング処理プログラムはRubyで作成
マスキング処理のプログラムはRubyで作成することにしました。作成したRubyファイルは、他のコマンドと共にシェルスクリプト内に記載してcronで定期実行します。ディレクトリ構成は次の画像の通りです。
.
├── Gemfile
├── Gemfile.lock
├── app
│ ├── active_record.rb
│ ├── mask_processing.rb
│ ├── masking.rb
│ └── user.rb
├── config
│ └── database.yml
├── etc
└── excute_all_process.sh
マスキング処理プログラムの作成においては、SQLをループ中で実行しないようにしてN+1問題を回避し、できるだけ処理速度が高まるように努めました。N+1問題とは、本来なら1回のクエリ実行で済む処理であるにもかかわらず、無駄にN回ものクエリをループ処理の中で実行してしまい、処理速度が低下してしまうことをいいます(少なくとも私はそう理解しています)。現時点ではレコード数が少ないのでN+1問題も大した問題ではありませんが、将来的にレコード数が増えることも考慮し、このような設計にしております。
今回の案件では、usersテーブルのusernameとemailにマスキング処理をかける必要がありました。その場合、①SQLでテーブルからデータを取ってくる、②usernameとemailをダミーデータに置き換える、③SQLでテーブルを更新する、という手続きをコードに落とし込むことでマスキング処理は実現できます。
今回作成したプログラムでは、①と③の2回にとどめてSQLを実行する設計にしました。また、①と③を実行するためにActiveRecordを導入しています。③に関しては、一括での更新(バルクアップサート)を実現するためにactiverecord-importというgemを導入しました。
require "activerecord-import"
require_relative "./active_record"
require_relative "./user"
require_relative "./mask_processing"
user_list = User.all
masked_users = MaskProcessing.masking_user(user_list)
User.import masked_users, on_duplicate_key_update: %i[username email], validate: true
②では、①で取得したuserテーブルデータ(カラム名がキーでフィールドの内容がバリューとなったハッシュが配列になっている)に対してmapメソッドを実行し、ダミーデータと置き換わった新しい配列を作成しています。mapで新しい配列を作ったのは、既製の変数の内容を変更するという副作用を避けるためです。
もちろん②については、一意制約を回避するために(usernameとemailの両カラムには一意制約がかかっています)、配列のインデックスをダミーデータの末尾に記述するようにしました。with_indexに引数として1を与えることで、idと同じ数字が記載されるようにしています。
class MaskProcessing
def self.dummy_user(user, id)
user["username"] = "dummy_username_#{id}"
email_domain = user["email"].split("@")[1]
user["email"] = "dummy_email_#{id}@#{email_domain}"
user
end
def self.masking_user(records)
records.map.with_index(1) do |record, index|
dummy_user(record, index)
end
end
private_class_method :dummy_user
end
その他のファイルは以下になります。
余談ですが、ソースコードをgithubに上げるに当たり、環境変数を管理するためのgemであるdotenvを導入しました。これを使えば、環境変数を定義した.envファイルをルート配下に設置するだけで、定義した環境変数が自動で読み込まれるようになります。
なお、環境変数を利用する場合、環境変数を<%= ENV['DB_HOST'] %>のように<%= %>で囲む必要があるので、RubyファイルでもERB記法を使えるように工夫しております。
require "dotenv"
require "mysql2"
require "active_record"
require "yaml"
require "erb"
Dotenv.load
yaml_file = File.read("./config/database.yml")
config = YAML.safe_load(ERB.new(yaml_file).result)
ActiveRecord::Base.establish_connection(config["db"])
class User < ActiveRecord::Base
self.table_name = "users"
validates_presence_of :username
validates_presence_of :email
end
たとえ小さなプログラムであったとしても妥協せず、可読性や再利用性が高まるようにクラスとメインの部分を分けるなどの配慮もしております。
N+1問題について私がどのように理解しているかについては下記の記事に記載しておりますので、ぜひご覧ください。
データの日次同期はAWS CLIとMySQLコマンドで
本サービス用RDSからのデータ取得とBIツール用RDSへのインポートは、AWS CLIやMySQLコマンドをシェルスクリプトに書いてcronで定期実行することで実装しました。マスキング処理用のRubyファイルも同シェルスクリプトに記載して実行します。これにより、本サービス用RDSとBIツール用RDSとのデータの同期と個人情報のマスキングが日次で定期実行されるようにしました。
具体的には、以下の手順で実行します。
①本サービス用RDSのスナップショットを作成(AWS CLI)
②そのスナップショットからレプリカのRDSを複製(AWS CLI)
③レプリカRDSのデータベースにマスキング処理を実施
④マスキング処理後データベースをdumpファイル化(MySQLコマンド)
⑤同dumpファイルをBIツール用RDSにインポート(MySQLコマンド)
⑥複製したRDSを削除(AWS CLI)
⑦作成したスナップショットを削除(AWS CLI)
スナップショットからRDSを複製するのは、この方法であれば本サービス用RDSに負荷がかからないからです(全テーブルにSELECT文を実行したり、データベースのdumpファイルを作成したりする手段もあり得ますが、負荷がかかってしまいます)。
また、複製したRDSのデータベースに対してマスキング処理を施してから、当該データベースをdumpファイル化してBIツール用RDSにインポートすることで、BIツールのユーザーが個人情報を見れてしまう機会を0にしています。
レプリカのRDSとスナップショットはデータ転送後に即座に削除するようにしました。RDSの削除は費用がかからないようにするために実施しています。スナップショットの削除は次回再度スナップショットを作成できるようにするためです(スナップショットの作成時に識別子を付けなければなりませんが、同じ識別子のスナップショットは作成できません。同じCLIでスナップショットを定期的に作成するには同じ識別子で作成することが避けられないため、作成したスナップショットは削除するようにしています)。
シェルスクリプトに書いた実際のコードは以下の通りです。
# !/bin/bash
# スナップショットの作成
/usr/bin/aws rds create-db-snapshot \
--region ap-northeast-1 \
--db-instance-identifier database-0 \
--db-snapshot-identifier hogehoge
# スナップショットの作成を待つ
/usr/bin/aws rds wait db-snapshot-available \
--region ap-northeast-1
# スナップショットからRDSを復元する
/usr/bin/aws rds restore-db-instance-from-db-snapshot \
--region ap-northeast-1 \
--db-snapshot-identifier hogehoge \
--db-instance-identifier database-3 \
--availability-zone ap-northeast-1c \
--db-subnet-group-name redash-db-sub-groupe \
--vpc-security-group-ids sg-0cdd1b46c92f20dd7 \
--db-parameter-group-name redash-db-param \
--no-multi-az
# RDSの立ち上がりを待つ
/usr/bin/aws rds wait db-instance-available \
--region ap-northeast-1
# dokugaku_engineerデータベースにマスキング処理
/bin/bash -lc "~/.rbenv/shims/ruby ~/app/masking.rb"
# マスキングしたデータベースからダンプファイルを作成
mysqldump --defaults-file=~/etc/.my.cnf --set-gtid-purged=OFF \
--single-transaction dokugaku_engineer > dokugaku_engineer.dump.sql
# BI専用RDSのデータベースにダンプデータを投入
mysql --defaults-file=~/etc/your.cnf dokugaku_engineer < dokugaku_engineer.dump.sql
# 作成したスナップショットを削除
/usr/bin/aws rds delete-db-snapshot \
--region ap-northeast-1 \
--db-snapshot-identifier hogehoge
# 作成したRDSを削除
/usr/bin/aws rds delete-db-instance \
--region ap-northeast-1 \
--db-instance-identifier database-3 \
--skip-final-snapshot
本ソリューションについては下記URLの記事に詳しく記載しておりますので、こちらもご覧いただけますと幸いです。
監視やセキュリティ
監視に関しては次の通りです。
Redashに関しては、死活監視ツールとしてDataDogを導入しました。また、マスキング処理はcronで自動化しているので、そのエラーログをCloudWatchで見れるようにしています。
なお、cron実行用のEC2をprivateサブネットに置いているのはセキュリティを強化するためです。Redash用のEC2にcronを実装していないのは、別の役割のものは別のサーバーに分けていた方がお互いに影響出ることなく独立して管理できるからでもあります。
まとめ
今回の案件を通じて、私は非常に多くのことを学びました。
特に勉強になったのは、課題解決のためには必ずしもRubyなどでコードを書かなければならないわけではないということです。特にインフラ周りの場合、LinuxコマンドやMySQLコマンド、AWS CLIが非常に役に立つという実感を得ました。
むしろ、それらだけで課題を解決できることも少なくないのではないでしょうか。以前はコードを書くことしか頭にありませんでしたが、今後はより幅広い視野で物事を考え、問題解決に挑みたいと思います。
セキュリティや保守・運用に関しても大いに勉強になりました。本案件に携わる前はセキュリティ意識はさして高くなく、自分の作ったプログラムを別の人再利用する可能性も考慮するといった保守・運用の発想もあまりありませんでした。
それが今回、実務を通じる中で、そういったことの重要性を身に染みて感じました。後で問題が起きないよう、セキュリティリスクを徹底的に考え抜いたり、コードの可読性や再利用可能性を極力高めたりすることの意義について、本案件では深く学ぶことができました。