(この記事は、「fukuoka.ex(その2) Elixir Advent Calendar 2017」の9日目、
および「ディープラーニングのエンジニアリング Advent Calendar 2017」の2日目です)
昨日は、@kobatako さんの「ElixirでSlack Botを作った with Qiita API」でした
fukuoka.ex代表のpiacereです
今回もご覧いただいて、ありがとうございます![]()
前回連載「Excelから関数型言語マスター」にて、Elixirによる関数型プログラミングは、Excelを扱うのと似たようなノリで始められ、Elixirの構文として、3つのEnum関数、2つのデータ構造という、たった5つを覚えれば、Web+DBやWeb+APIのアプリが開発できることを示しました
今回からスタートする新シリーズ「関数型でデータサイエンス」では、そのニュアンスを踏襲しつつ、ファイル操作やデータ処理を追加していくことで、データ分析エンジンを構築していきます
![]()
![]()
![]()
![]() お礼:各種ランキングに69回のランクインを達成しました
お礼:各種ランキングに69回のランクインを達成しました ![]()
![]()
![]()
![]()
4/27から、30日間に渡り、毎日お届けしている「季節外れのfukuoka.ex Elixir Advent Calendar」と「季節外れのfukuoka.ex(その2) Elixir Advent Calender」ですが、Qiitaトップページトレンドランキングに8回入賞、Elixirウィークリーランキングでは5週連続で1/2/3フィニッシュを飾り、各種ランキング通算で、トータル69回ものランクイン(前週比+60.1%)を達成しています
みなさまの暖かい応援に励まされ、合計452件ものQiita「いいね」(前週差+103件)もいただき、fukuoka.exアドバイザーズとfukuoka.exキャストの一同、ますます季節外れのfukuoka.ex Advent Calendar、頑張っていきます![]()
取り扱う元データ
「データ分析」というと、元データとして、HDFS(Hadoop Distributed File System、Hadoopのファイルシステム)やRDD(Resilient Distributed Datasets、Sparkのデータコレクション)、Bigtable/BigQuery、GCS、Redshift、S3、もしくはElasticsearchといった、クラウド前提のビッグデータ向けストレージや分析エンジンを想像するかも知れませんが、このコラムでは、より基本的な、以下4種類の元データの取り扱いから始めたいと思います
① CSV/TSV
② Excel
③ DB
④ API
IT/非IT含めた企業における、分析前データは、依然、これら形式のものが大半を占め、そもそもクラウドに載せる以前の部分で、戸惑っているのが現実です
そして、これらデータを、どうかき集め、有用なデータ分析側へと回すか、ということに、データ分析活動の80~90%が掛かっていると言っても大袈裟では無い位、需要がとても大きな領域であり、ここがうまくいかないと、機械学習やディープラーニングも、宝の持ち腐れとなります
事前準備:データ分析用PhoenixのPJ作成、DB作成、起動
それでは早速、データ分析用Phoenixプロジェクトを作成します
なお、Phoenixのインストールは、「Excelから関数型言語マスター2回目:『列の抽出』と『Web表示』」のPhoenixインストールを見て、予めインストールしておいてください
MySQLもしくはPostgreSQLも、「Excelから関数型言語マスター3回目:WebにDBデータ表示」のDBインストールを見て、予めインストールしておいてください
なお、今回の説明中では、特に指定無い限り、PostgreSQLを使って説明しますので、MySQLを使いたい方は、適宜、読み替えてください
mix phx.new sample_analytics --no-webpack
DBを作成します ※作成しないとiex内でエラー連発となるのでお忘れなく
mix ecto.create
Phoenixサーバーを起動します
iex -S mix phx.server
ブラウザで「http://localhost:4000」にアクセスすると、Phoenixで作られたWebページが見れます
① CSV/TSV
Elixirにて、CSV/TSVを読み込むには、「CSV」というライブラリを使います
mix.exsの「def deps do」配下の先頭に追記します
defmodule SampleAnalytics.Mixfile do
use Mix.Project
…
defp deps do
[
{:csv, "~> 2.1"},
{:phoenix, "~> 1.3.0"},
{:phoenix_pubsub, "~> 1.0"},
]
end
…
起動したPhoenixサーバーを一度、Ctrl+C2度押しで中断した後、ライブラリを取得します(要ネット接続)
mix deps.get
Phoenixサーバーを起動します
iex -S mix phx.server
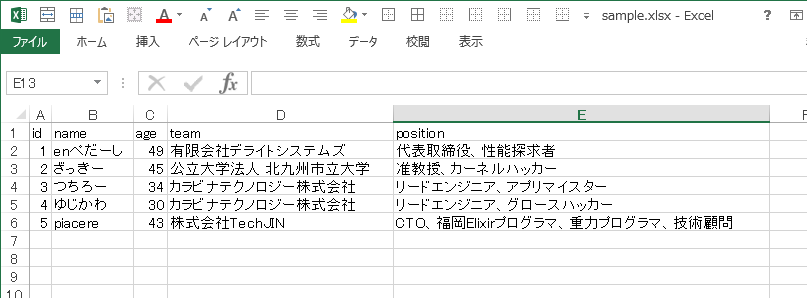
PJフォルダ配下に、「sample.csv」というファイル名で、下記内容のCSVファイルを作成します
| id | name | age | team | position |
|---|---|---|---|---|
| 1 | enぺだーし | 49 | 有限会社デライトシステムズ | 代表取締役、性能探求者 |
| 2 | ざっきー | 45 | 公立大学法人 北九州市立大学 | 准教授、カーネルハッカー |
| 3 | つちろー | 34 | カラビナテクノロジー株式会社 | リードエンジニア、アプリマイスター |
| 4 | ゆじかわ | 30 | カラビナテクノロジー株式会社 | リードエンジニア、グロースハッカー |
| 5 | piacere | 43 | 株式会社TechJIN | CTO、福岡Elixirプログラマ、重力プログラマ、技術顧問 |
CSVファイルを読み込んで、Web表示します
以前連載のDBやAPI同様、「<table~」で始まるHTML部分は変えていません
<%
result = "sample.csv"
|> File.stream!
|> CSV.decode( strip_fields: true, headers: true )
datas = result
|> Enum.map( &( elem( &1, 1 ) ) )
columns = [ "id", "name", "position" ]
%>
<table border="1">
<tr>
<%= for column <- columns do %>
<th><%= column %></td>
<% end %>
</tr>
<%= for record <- datas do %>
<tr>
<%= for column <- columns do %>
<td><%= record[ column ] %></td>
<% end %>
</tr>
<% end %>
</table>
コードの解説ですが、CSV.decode()の引数として、strip_fieldsを指定すると、カンマ区切りの間にあるスペースを削除し、headersを指定すると、先頭行をヘッダーとして扱うようになり、各データ行をヘッダー項目をキーとしたマップにしてくれます
読み込み結果は、以下形式でCSV.decode()から返ってきます
[
ok: %{ "age" => "49", "id" => "1", "name" => "enぺだーし", "position" => "代表取締役、性能探求者", "team" => "有限会社デライトシステムズ" },
ok: %{ "age" => "45", "id" => "2", "name" => "ざっきー", "position" => "准教授、カーネルハッカー", "team" => "公立大学法人 北九州市立大学" },
ok: %{ "age" => "34", "id" => "3", "name" => "つちろー", "position" => "リードエンジニア、アプリマイスター", "team" => "カラビナテクノロジー株式会社" },
ok: %{ "age" => "30", "id" => "4", "name" => "ゆじかわ", "position" => "リードエンジニア、グロースハッカー", "team" => "カラビナテクノロジー株式会社" },
ok: %{ "age" => "43", "id" => "5", "name" => "piacere", "position" => "CTO、福岡Elixirプログラマ、重力プログラマ、技術顧問", "team" => "株式会社TechJIN" }
]
これは、「キーワードリスト」と呼ばれる、順序付きキーバリューのデータ構造で、「ok:」とその直後のマップ(%{~})で1組のキーバリューを、リストで束ねたものになります
マップに似ていますが、マップは順序無しキーバリューのため、キーバリューの順序が保証されないのに対し、キーワードリストは、リスト同様、順序が保証されます
キーワードリストは、以下のような、1項目目が「:ok」、2項目目がCSV内容を持つタプルの省略表記であるため、各行をEnum.map()で取り出し、elem( &1, 1 )で2項目目(≒0オリジンなので1を指定)のみ抜き出します
[
{ :ok, %{ "age" => "49", "id" => "1", "name" => "enぺだーし", "position" => "代表取締役、性能探求者", "team" => "有限会社デライトシステムズ" } },
{ :ok, %{ "age" => "45", "id" => "2", "name" => "ざっきー", "position" => "准教授、カーネルハッカー", "team" => "公立大学法人 北九州市立大学" } },
{ :ok, %{ "age" => "34", "id" => "3", "name" => "つちろー", "position" => "リードエンジニア、アプリマイスター", "team" => "カラビナテクノロジー株式会社" } },
{ :ok, %{ "age" => "30", "id" => "4", "name" => "ゆじかわ", "position" => "リードエンジニア、グロースハッカー", "team" => "カラビナテクノロジー株式会社" } },
{ :ok, %{ "age" => "43", "id" => "5", "name" => "piacere", "position" => "CTO、福岡Elixirプログラマ、重力プログラマ、技術顧問", "team" => "株式会社TechJIN" } }
]
なお参考までに、Keywordモジュールを使って、下記のように取得することもできます
…
datas = result
|> Enum.to_list
|> Keyword.get_values( :ok )
…
結果的に、以下のような、「:ok」部分が無くなったデータになります
[
%{ "age" => "49", "id" => "1", "name" => "enぺだーし", "position" => "代表取締役、性能探求者", "team" => "有限会社デライトシステムズ" },
%{ "age" => "45", "id" => "2", "name" => "ざっきー", "position" => "准教授、カーネルハッカー", "team" => "公立大学法人 北九州市立大学" },
%{ "age" => "34", "id" => "3", "name" => "つちろー", "position" => "リードエンジニア、アプリマイスター", "team" => "カラビナテクノロジー株式会社" },
%{ "age" => "30", "id" => "4", "name" => "ゆじかわ", "position" => "リードエンジニア、グロースハッカー", "team" => "カラビナテクノロジー株式会社" },
%{ "age" => "43", "id" => "5", "name" => "piacere", "position" => "CTO、福岡Elixirプログラマ、重力プログラマ、技術顧問", "team" => "株式会社TechJIN" }
]
上記のようなデータ変換を行い、CSVファイルの内容をWeb表示できるようになりました

なお、TSVを扱う場合は、下記のように、separatorとしてタブ文字を指定します
…
|> CSV.decode( separator: ?\t, strip_fields: true, headers: true )
…
② Excel
Elixirにて、Excelを読み込むには、「Excelion」というライブラリを使います
また、小粒でピリリなユーティリティライブラリ「smallex」のMapListモジュールも使います
mix.exsの「def deps do」配下の先頭に追記します
defmodule SampleAnalytics.Mixfile do
use Mix.Project
…
defp deps do
[
{:smallex, ">= 0.1.2"},
{:excelion, "~> 0.0.5"},
{:csv, "~> 2.1"},
{:phoenix, "~> 1.3.0"},
{:phoenix_pubsub, "~> 1.0"},
]
end
…
起動したPhoenixサーバーを一度、Ctrl+C2度押しで中断した後、ライブラリを取得します(要ネット接続)
mix deps.get
Phoenixサーバーを起動します
iex -S mix phx.server
PJフォルダ配下に、「sample.xlsx」というファイル名で、下記内容のCSVファイルを作成します(シート名は、何でも構いません)
Excelファイルを読み込んで、Web表示します
DB/API/CSV同様、「<table~」で始まるHTML部分は変えていません
<%
result = "sample.xlsx"
|> Excelion.parse!( 0, 1 )
header = result |> List.first
datas = result
|> Enum.drop( 1 )
|> Enum.map( fn row -> Lst.zip( header, row ) end )
columns = [ "name", "age" ]
%>
<table border="1">
<tr>
<%= for column <- columns do %>
<th><%= column %></td>
<% end %>
</tr>
<%= for record <- datas do %>
<tr>
<%= for column <- columns do %>
<td><%= record[ column ] %></td>
<% end %>
</tr>
<% end %>
</table>
コードの解説ですが、Excelion.parse!()の第一引数は0オリジンのシート番号を指定し、第二引数は1オリジンの読み込み開始行番号を指定します
headerは、以下形式でExcelion.parse!()から返ってくるデータから、先頭行のみList.firstで取り出します
[
["id", "name", "age", "team", "position"],
["1", "enぺだーし", "49", "有限会社デライトシステムズ", "代表取締役、性能探求者"],
["2", "ざっきー", "45", "公立大学法人 北九州市立大学", "准教授、カーネルハッカー"],
["3", "つちろー", "34", "カラビナテクノロジー株式会社", "リードエンジニア、アプリマイスター"],
["4", "ゆじかわ", "30", "カラビナテクノロジー株式会社", "リードエンジニア、グロースハッカー"],
["5", "piacere", "43", "株式会社TechJIN", "CTO、福岡Elixirプログラマ、重力プログラマ、技術顧問"]
]
datasは、上記データから、先頭行のヘッダー部分をEnum.drop( 1 )で削ぎ、残り全行を、headerをキーにしたマップへと、Enum.map()とSmallexのLst.zip()によって変換しています(以下のようなデータになります)
[
%{ "age" => "49", "id" => "1", "name" => "enぺだーし", "position" => "代表取締役、性能探求者", "team" => "有限会社デライトシステムズ" },
%{ "age" => "45", "id" => "2", "name" => "ざっきー", "position" => "准教授、カーネルハッカー", "team" => "公立大学法人 北九州市立大学" },
%{ "age" => "34", "id" => "3", "name" => "つちろー", "position" => "リードエンジニア、アプリマイスター", "team" => "カラビナテクノロジー株式会社" },
%{ "age" => "30", "id" => "4", "name" => "ゆじかわ", "position" => "リードエンジニア、グロースハッカー", "team" => "カラビナテクノロジー株式会社" },
%{ "age" => "43", "id" => "5", "name" => "piacere", "position" => "CTO、福岡Elixirプログラマ、重力プログラマ、技術顧問", "team" => "株式会社TechJIN" }
]
上記のようなデータ変換を行い、Excelの内容をWeb表示できるようになりました

③ DB
DBは、「Excelから関数型言語マスター3回目:WebにDBデータ表示」で、DBアクセスライブラリ「Ecto」をDBアクセスモジュールで包んだものを作りましたが、全く同じ形式で、PJフォルダ内のlibフォルダ配下にutilフォルダを掘り、今回のPJに合わせて、下記のように作ります
なおEctoは、Phoenix PJを作成した際に、既にライブラリとしてインストールされるため、mix.exsに追加する必要はありません
defmodule Db do
def query( sql ) when sql != "" do
{ :ok, result } = Ecto.Adapters.SQL.query( SampleAnalytics.Repo, sql, [] )
result
end
def columns_rows( result ) do
result
|> rows
|> Enum.map( fn row -> Lst.zip( columns( result ), row ) end )
end
def rows( %{ rows: rows } = _result ), do: rows
def columns( %{ columns: columns } = _result ), do: columns
end
なお、コード中の「SampleAnalytics.Repo」の部分は、作成するPJ名によって変わるため、別PJを作成した際は、「SampleAnalytics」の部分をPJ名と同じにしてください
DBデータを取得し、データを読み込むコードは、以下例のようになります
なお、以下を実行する際は、事前に「Excelから関数型言語マスター3回目:WebにDBデータ表示」で作成したのと同じテーブル作成とデータ投入を行っておいてください
<%
datas = Db.query( "select * from members" ) |> Db.columns_rows
columns = [ "id", "name", "position" ]
%>
<table border="1">
<tr>
<%= for column <- columns do %>
<th><%= column %></td>
<% end %>
</tr>
<%= for record <- datas do %>
<tr>
<%= for column <- columns do %>
<td><%= record[ column ] %></td>
<% end %>
</tr>
<% end %>
</table>
④ API
APIは、「Excelから関数型言語マスター4回目:Webに外部APIデータ表示」で、小粒でピリリなユーティリティライブラリ「smallex」のJSONアクセスモジュールを使って作りましたが、今回も同じようにします
APIを呼び出し、JSONを取得した後、データを読み込むコードは、以下例のようになります
<%
datas = Json.get( "https://qiita.com", "/api/v2/items?query=elixir" )
columns = [ "title", "likes_count" ]
%>
<table border="1">
<tr>
<%= for column <- columns do %>
<th><%= column %></td>
<% end %>
</tr>
<%= for record <- datas do %>
<tr>
<%= for column <- columns do %>
<td><%= record[ column ] %></td>
<% end %>
</tr>
<% end %>
</table>
終わり
今回は、CSV/Excel/DB/APIのデータを読み込む部分の基礎について説明しました
次回は、これらを実際に使い、「インプットしたデータを変換する」を解説します
明日は @tuchiro さんの「ElixirでSI開発入門 #7 Multiで使う関数を再利用可能な粒度に分割する」です
![]()
![]()
![]()
![]()
![]() Elixir MeetUpを6月末に開催します
Elixir MeetUpを6月末に開催します ![]()
![]()
![]()
![]()
![]()
「fukuoka.ex#11:DB/データサイエンスにコネクトするElixir」を6/22(金)19時に開催します
fukuoka.exの発足から、ちょうど1周年となる、記念的なイベントでもあるため、このコラムを気に入っていただいた方と、ぜひ一緒に盛り上がりたいです
福岡近辺にお住まいの方であれば、遊びに来てください
大人気により、一度は満席となりましたが、増枠しましたので、下記URLよりご参加ください
https://fukuokaex.connpass.com/event/87241
特別ゲストは、Erlang/Elixirの両面で世界的に有名な「力武 健次さん」と、北九州の飯塚市で「e-ZUKA Tech Night」を6年間主催し続けるハウインターナショナルの「谷口 耕平さん」のお二人と、実に豪華なイベントです
私は、今回のシリーズを踏まえた、「1家に1台、パーソナルなデータ分析AIを全員が持つ2020年を作る」というタイトルで、Elixirによる、ブラウザUI上からサクっとデータ分析プラットフォームを披露するLTをお届けします

p.s.「いいね」よろしくお願いします
よろしければ、ページ左上の  や
や  のクリックをお願いしますー
のクリックをお願いしますー![]()
ここの数字が増えると、書き手としては「ウケている」という感覚が得られ、連載を更に進化させていくモチベーションになりますので、もっとElixirネタを見たいというあなた、私たちと一緒に盛り上げてください!![]()