この記事は、Elixir Advent Calendar 2025その3 の5日目です
昨日は私で、「【2025年版】Ubuntu 24.04 Elixir/Phoenix最短インストール手順(ベアメタル or mise)」 でした
piacere です、ご覧いただいてありがとございます ![]()
Ollamaが使いやすくなり、ローカルLLMによるAIアプリが簡単に作れるようになったので、そこにWeb Speech APIによる音声入力と、VOICEVOXによる音声出力を組み合わせて、LiveView製の「会話できるAIボット」を作ってみました
Elixirアドベントカレンダー、応援お願いします 
今年もやっています
全体像
下記をLiveView上で順々に実装していきます
- ①ローカルLLMエンジン「Ollama」でローカルLLMを動かす
- ②音声合成エンジン「VOICEVOX」でAI推論結果を喋らす
- ③Web Speech APIで音声入力を受け付け、AIに返答させる
なお、コラムで使った環境は、下記CPU/GPU/メモリ/OSがセットアップされたノートPCです
- Ryzen 7 6800U with Redeon
- Windows 11
- WSL2 Ubuntu 24.04
- Erlang 28.1.1
- Elixir 1.19.3-otp-28
- Phoenix 1.8.1
- Chrome ※ブラウザがChromeかEdgeで無いと動きません
上記中、2025年11月時点の最新Elixir/ErlangとPhoenixのインストール方法は、下記コラムで解説しています
①OllamaでローカルLLMを動かす
Ollama上でモデルを動かし、ElixirでAI推論可能とします
Ollamaのインストールとモデル実行
Ollamaは、サーバーを起動した上でモデルを動かすので、下記でインストールして起動します
curl -fsSL https://ollama.com/install.sh | sh
ollama serve
別シェルで下記を打ち、軽量なgemma3:270mモデルをインストールすると、シェル上での対話確認ができるので、適当にプロンプトを投げてみてください(/bye で抜けられます)
ollama run gemma3:270m
>>> 「先端ぴあちゃん」から連想されるストーリーを3つ挙げて
>>> /bye
ElixirからOllamaを動かす
Phoenix PJを作成します
mix phx.new basic --no-ecto
cd basic
Ollamaライブラリを追加します
defmodule Basic.MixProject do
use Mix.Project
…
defp deps do
[
+ {:ollama, "~> 0.9"},
{:phoenix, "~> 1.8.1"},
…
新たなページとLiveViewを追加します(この時点のプロンプトはハードコーディング状態)
LiveView(~_live.ex)とHTML(~_live.html.heex)は、@ で始まる変数でフロントサイドの状態を保持したり、入力内容をサーバーサイドに渡すことができ、逆にサーバーサイドで書き換えると、フロント側への表示反映や状態更新を自動的に行うこともできます
<div class="p-4">
<p class="p-4">
<div>入力:</div>
<div id="input"><%= @input %></div>
</p>
<p class="p-4">
<div>結果:</div>
<div id="output"><%= @output %></div>
</p>
</div>
次にLiveViewのロジック部分で、mount() がページ初期時に行う処理、handle_info() はLiveView側処理を数珠繋ぎにするためのハンドラ(send() で遅延呼出しも可能)、assign() でサーバーサイド更新をフロントに反映させます
今回は、assigns.conversations という変数に、各会話回ごとの %{"prompt" => transcript, "answer" => "AI処理中…"} をリストし、それをHTML側で :for を使って全ての会話履歴を表示しています
なお今回は使いませんが、フロント側での入力/変更内容は、handle_info() の第2引数 params に文字列キーのマップとして入っており、HTML側の name= で指定した変数名で取得できます
defmodule BasicWeb.BuddyLive do
use BasicWeb, :live_view
@impl true
def mount(_params, _session, socket) do
send(self(), {"predict", "「先端ぴあちゃん」から連想されるストーリーを3つ挙げて"})
{:ok, assign(socket, is_recording: false, input: "", output: "")}
end
@impl true
def handle_info({"predict", transcript}, socket) do
client = Ollama.init(base_url: "http://localhost:11434/api", receive_timeout: 300000)
result = case Ollama.preload(client, model: model) do
{:ok, false} -> "(Ollamaでモデルロード失敗…)"
_ ->
context = "問いかけに一言二言で返してください。"
{:ok, %{"message" => %{"content" => result}}} = Ollama.chat(
client,
model: model,
messages: [%{role: "system", content: context}, %{role: "user", content: prompt}]
)
result
end
end
end
ルートを上記LiveViewに入れ替えます
defmodule BasicWeb.Router do
use BasicWeb, :router
…
scope "/", BasicWeb do
pipe_through :browser
- get "/", PageController, :home
+ live "/", BuddyLive
end
…
Phoenixを起動します
mix deps.get
iex -S mix phx.server
実行すると、ハードコーディングしたプロンプトに沿ってAI推論が走ります(リロードするたびに、推論結果が変わります)
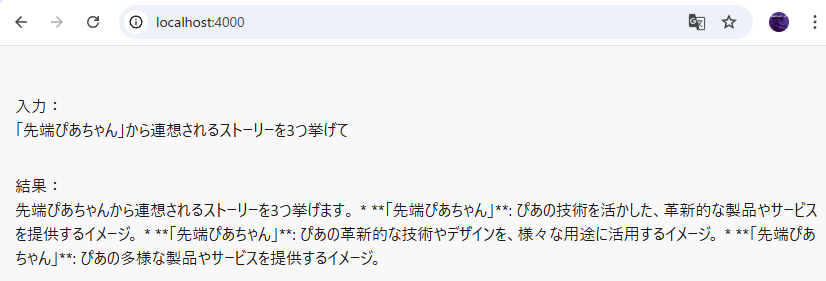
②VOICEVOXにAI推論結果を喋らす
次に、AI推論結果をElixirからVOICEVOX APIを呼ぶことで喋らせます
WSL2シェルでインストール/起動
下記サイトの「ダウンロード」で、Linux「CPU (x64)」版のインストーラを選び、WSL2のホームフォルダ \\wsl$\Ubuntu-24.04\home\【ユーザー名】 配下にダウンロードします
なお、利用するPCにNVIDIA GPUが搭載されていれば「GPU / CPU (x64)」も選べますが、GPUの方が声が滑らかで、CPUだとややガビガビします
下記コマンドでインストール/起動します
sudo apt update
sudo apt install p7zip -y
sudo apt install libnspr4 libnss3 alsa-utils pulseaudio -y
sudo chmod 755 VOICEVOX.Installer.0.25.0.Linux.sh
./VOICEVOX.Installer.0.25.0.Linux.sh
cd .voicevox
./VOICEVOX.AppImage
下記のようなウインドウが起動すれば成功です
「同意して使用開始」を押すと、下記のようなキャラ一覧画面が出て、これで起動完了です(様々なキャラの音声をこの画面でお楽しみください)
ElixirからHTTP API経由で喋らせる
VOICEVOXは、裏でHTTP APIサーバーも起動しているので、http://localhost:50021/speakers にブラウザでアクセスすると、下記のようにキャラ一覧が引けます
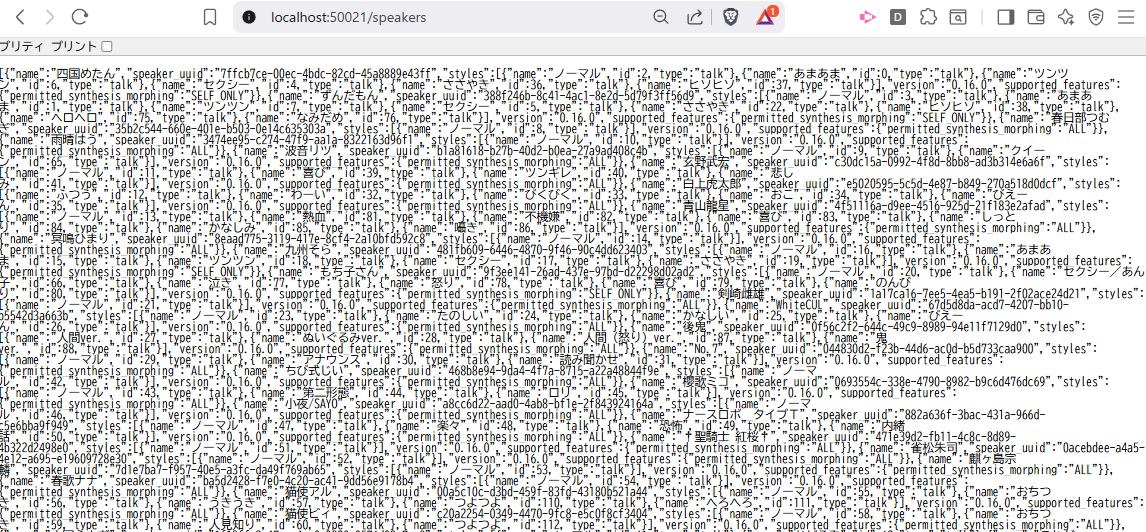
これを確認後、下記の @t-yamanashi さん作コードを盛大にパクってLiveView化します
コードはこんな感じで、VOICEVOX APIの呼び出しは、先ほどのキャラ一覧と同じく、URLに /audio_query 指定で喋る内容のデータ化、/synthesis 指定で音声合成を行いますが、キャラ指定は ?speaker=【キャラID】 で出来ます
defmodule BasicWeb.BuddyLive do
use BasicWeb, :live_view
@impl true
def mount(_params, _session, socket) do
send(self(), {"predict", "「先端ぴあちゃん」から連想されるストーリーを3つ挙げて"})
{:ok, assign(socket, is_recording: false, input: "", output: "")}
end
@impl true
def handle_info({"predict", transcript}, socket) do
predict = predict(transcript)
+ send(self(), {"speak", {transcript, predict}})
{:noreply, assign(socket, is_recording: false, input: transcript, output: predict)}
end
+
+ @impl true
+ def handle_info({"speak", {transcript, predict}}, socket) do
+ speak(predict)
+ {:noreply, assign(socket, is_recording: false, input: transcript, output: predict)}
+ end
+
+ def speak(text, character_id \\ 3) do
+ File.rm("predict.wav")
+
+ query =
+ "http://localhost:50021/audio_query?#{URI.encode_query(%{text: text, speaker: character_id})}"
+ |> Req.post!(body: "")
+ |> Map.get(:body)
+ |> Map.put("speedScale", 1.5)
+ |> Jason.encode!()
+
+ "http://localhost:50021/synthesis?speaker=#{character_id}"
+ |> Req.post!(body: query, headers: ["Content-Type": "application/json"])
+ |> Map.get(:body)
+ |> then(& File.write("predict.wav", &1))
+
+ System.cmd("aplay", ["predict.wav"])
+ end
…
これで、AI推論した結果を喋り出すようになります(リロードするたびに、喋る内容が変わります)
③音声入力を受け付け、AIに返答させる
ブラウザ上でWeb Speech APIを使って音声入力を受け付け、上記で作ったAI推論を音声で返す処理に渡すことで会話可能としましょう
なお、ブラウザがChromeかEdgeで無いと動かないのでご注意ください
ページ先頭に音声入力開始ボタンを追加します
phx-clickやphx-submit等で、LiveView側のhandle_eventを呼び出せます(どんな連携の種類があるかは下記をご覧ください)
+<div class="p-4">
+ <button
+ class="bg-gray-400 text-white p-2 active:border-b-0 active:translate-y-1"
+ id="start" phx-click="start" phx-hook="Speech" disabled={@is_recording}>
+ <%= if @is_recording do %>
+ 🔴 音声認識中…
+ <% else %>
+ 🎙️ ここを押して喋ってください
+ <% end %>
+ </button>
+</div>
<div class="p-4">
<p class="p-4">
<div>入力:</div>
…
LiveView側は、mountからのAI呼出を消し、代わりに音声入力後にAI呼出するように変更した上で、カスタムHook recognize でWeb Speech APIを呼び、result でWeb Speech APIによる音声入力テキストを受け取り、AI処理以降に回す処理を末尾に追加します
handle_eventは、ページ上のphx-clickやJS Hooksから呼べるハンドラです
push_eventで、JS Hooks関数を呼び出せます
…
@impl true
def mount(_params, _session, socket) do
- send(self(), {:start_ai_process, "「先端ぴあちゃん」から連想されるストーリーを3つ挙げて"})
{:ok, assign(socket, is_recording: false, input: "", output: "")}
end
…
+ @impl true
+ def handle_event("start", _value, socket) do
+ socket = assign(socket, is_recording: true, input: "", output: "")
+ {:noreply, push_event(socket, "recognize", %{})}
+ end
+
+ @impl true
+ def handle_event("finish", %{"transcript" => transcript}, socket) do
+ send(self(), {"predict", transcript})
+ {:noreply, assign(socket, is_recording: false, input: transcript, output: "AI処理中…")}
+ end
+
+ @impl true
+ def handle_event("error", %{"error" => error}, socket) do
+ {:noreply, assign(socket, is_recording: false, input: "エラーが発生しました: #{error}", output: "")}
+ end
Web Speech APIを呼ぶカスタムHooks JSファイルを追加します
liveHook.pushEventで、LiveView側のhandle_eventを呼び出せます
import { LiveSocket } from "phoenix_live_view";
let Hooks = {};
Hooks.Speech = {
mounted() {
const SpeechRecognition = window.SpeechRecognition || window.webkitSpeechRecognition;
this.recognition = new SpeechRecognition();
this.recognition.lang = 'ja-JP';
this.recognition.continuous = false;
this.recognition.interimResults = false;
const liveHook = this;
this.handleEvent("recognize", () => {
try {
this.recognition.start();
} catch (e) {
liveHook.pushEvent("error", {error: "すでに音声認識が実行中です"});
}
});
this.recognition.onresult = (event) => {
const finalTranscript = event.results[0][0].transcript;
liveHook.pushEvent("finish", {transcript: finalTranscript});
};
this.recognition.onerror = (event) => {
liveHook.pushEvent("error", {error: event.error});
};
}
};
export default Hooks;
カスタムHooksをimportし、liveSocket内のhooksに ...customHooks を追加しましょう
// If you want to use Phoenix channels, run `mix help phx.gen.channel`
// to get started and then uncomment the line below.
…
import {Socket} from "phoenix"
import {LiveSocket} from "phoenix_live_view"
import {hooks as colocatedHooks} from "phoenix-colocated/basic"
import topbar from "../vendor/topbar"
+import Speech from "./speech.js"
const csrfToken = document.querySelector("meta[name='csrf-token']").getAttribute("content")
const liveSocket = new LiveSocket("/live", Socket, {
longPollFallbackMs: 2500,
params: {_csrf_token: csrfToken},
- hooks: {...colocatedHooks},
+ hooks: {...colocatedHooks, ...Speech},
})
…
これで、ボタンを押すと音声を聴き、それに音声で返してくれるAIボットが完成しました
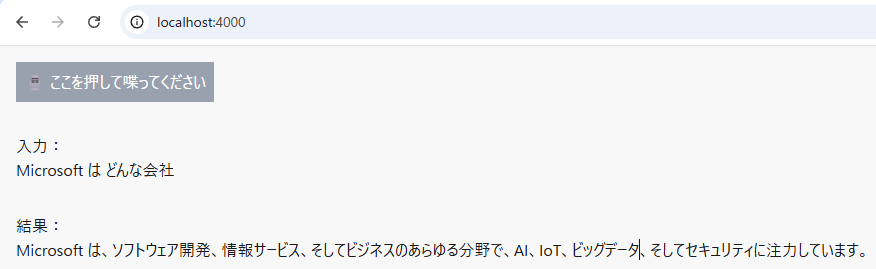
さらなる改善
ひとまず最低限の会話AIボットは実装できましたが、下記のような改善をすると、より本格的な会話AIボット化できると思います … 今回の内容が気に入った方は、ぜひトライしてみてください
- 全体
- ボタンを押さずとも「OK、Google」とかで会話を開始できるようにしたい
- ✅音声出力のレスポンスをもっと速くしたい(チャンク生成→チャンク再生で可能?)
- ✅推論結果の再生中に中断できるようにしたい
- ✅LiveView UIを固めないため、TaskでOllamaやVOICEVOXをバックグラウンド実行
- ✅LLM実行のストリーミング化
- ①Ollama
- ✅RAGやFine Tuningの追加
- ②VOICEVOX
- GPU付きサーバーでは無くCLIサーバー化
- ✅音声出力をaplayコマンド実行では無く、ブラウザ上で再生
- ③音声入力
- Web Speech APIはGoogleサーバーでの音声認識なので、ローカル化したい
- その他
- LangChain化
- MCP化
- Antigravityから呼ぶ
- Ollama部分をBumblebeeに差し替え
- Dockerに包んでパッケージ化して配布
- ✅VRアバターとの対話インタフェース化
終わりに
「ローカルLLMを使った会話AIボット」が割とカンタンに作れるんだってことが伝われば幸いです
なお今回コードは、LiveViewプログラミングとして、ハンドラの使いこなしや数珠繋ぎ、JS HooksでのJavaScript呼出などのテクニックをステップ・バイ・ステップで学べる教材にもなっているので、LiveViewが何となく苦手な方はご参考ください
さらに、「さらなる改善」に書いたTaskでのバックグラウンド実行も入ると、LiveViewの裏側でAI含む重めの処理を行うテクニックも身に付くと思います
p.s.このコラムが、面白かったり、役に立ったら…
 にて、どうぞ応援よろしくお願いします
にて、どうぞ応援よろしくお願いします ![]()
明日は、 @t-yamanashi さんで 「AtomVM Raspberry Pi Picoのファームをビルドしてブートを高速化する」 です