5/8追記→【業務連絡w】altさん、コードの色付け、ありがとうございますm(__)m
(この記事は Elixir (その2)とPhoenix Advent Calendar 2016 9日目の記事です)
前回は、CaboChaで文章構成を解析するための準備を行いました
今回は、いよいよAIらしいロジックである、意味解析...つまり、文脈から意味を読み取ってアクションする(といってもカンタンなものですが)を作り込んでいきます
なお、本コラム中の「Elixirの書き方」については、あまり細かく説明をしていないので、「ここの書き方が分からない」とか「この処理が何をしているのかよく分からない」等あれば、コメントいただければ、回答します ![]()
特に今回は、データ変換の書き方が、けっこう難しい領域に入っていきます(&安易にcaseで書いてしまった(-_-u...)ので、遠慮無くご質問いただければと思います(空いているAdvent Calenderのコマでお答えしたり、を考えています) ![]()
CaboChaの解析結果をもう1段、加工する
前回の最後に、「xml_parser」モジュールで、CaboChaの解析結果をElixirで処理しやすいよう変換しましたが、もう1段、処理しやすくなるよう加工します
CaboCha解析結果は、「chunk」1つで、ひと塊のフレーズとなっており、「chunk」配下には、単語である「toks」とその単語の品詞が並びますが、品詞がカンマ区切りの文字列のため、扱いにくいので、マップ化します(ついでに使わない構造や値も削除して、データをスッキリさせます)
defmodule Cabocha do
def parse( body \\ "10年後、ブラックホールの謎を応用した、重力のプログラミングが可能となる" ) do
case body == "" || body == nil do
true -> ""
false ->
body
|> xml
|> XmlParser.parse
|> chunks
|> chunk_map( [] )
end
end
def chunks( { :sentence, nil, chunks } ), do: chunks
def chunk_map( [ { :chunk, %{ id: id, link: link, score: score }, toks } | tail ], chunk_list ) do
chunk_map( tail,
chunk_list ++ [ %{ "chunk" => %{ "id" => id, "link" => link, "score" => score },
"toks" => toks_map( toks, [] ) } ] )
end
def chunk_map( [], chunk_list ), do: chunk_list
def toks_map( [ { :tok, %{ feature: feature, id: id }, word } | tail ], tok_list ) do
toks_map( tail,
tok_list ++ [ %{ "id" => id, "word" => word, "feature" => feature_map( feature ) } ] )
end
def toks_map( [], tok_list ), do: tok_list
def feature_map( feature ) do
Regex.named_captures( ~r/
^
(?<part_of_speech>[^,]*),
\*?(?<part_of_speech_subcategory1>[^,]*),
\*?(?<part_of_speech_subcategory2>[^,]*),
\*?(?<part_of_speech_subcategory3>[^,]*),
\*?(?<conjugation_form>[^,]*),
\*?(?<conjugation>[^,]*),
(?<lexical_form>[^,]*),
(?<yomi>[^,]*),
(?<pronunciation>.*)
$
/x, feature )
end
…
この変換で、chunk配下の品詞も「feature」配下にマップ化し、更にパターンマッチしやすくしました
iex> recompile()
iex> Cabocha.parse
[%{"chunk" => %{"id" => "0", "link" => "6", "score" => "-1.514907"},
"toks" => [
%{"feature" => %{"conjugation" => "", "conjugation_form" => "",
"lexical_form" => "1", "part_of_speech" => "名詞",
"part_of_speech_subcategory1" => "数",
"part_of_speech_subcategory2" => "",
"part_of_speech_subcategory3" => "", "pronunciation" => "イチ",
"yomi" => "イチ"}, "id" => "0", "word" => "1"},
%{"feature" => %{"conjugation" => "", "conjugation_form" => "",
"lexical_form" => "0", "part_of_speech" => "名詞",
"part_of_speech_subcategory1" => "数",
"part_of_speech_subcategory2" => "",
"part_of_speech_subcategory3" => "", "pronunciation" => "ゼロ",
"yomi" => "ゼロ"}, "id" => "1", "word" => "0"},
%{"feature" => %{"conjugation" => "", "conjugation_form" => "",
"lexical_form" => "年", "part_of_speech" => "名詞",
"part_of_speech_subcategory1" => "接尾",
"part_of_speech_subcategory2" => "助数詞",
"part_of_speech_subcategory3" => "", "pronunciation" => "ネン",
"yomi" => "ネン"}, "id" => "2", "word" => "年"},
…
文章のツリー構造を解析する
CaboCha解析結果は、「chunk」間の上下関係が、文章の構造となっており、各Chunkの「link」が別のchunkの「id」を指すようなツリー構造をしています
これを抽出するため、Relationというモジュールを追加します
defmodule Relation do
def get( body \\ "10年後、ブラックホールの謎を応用して、重力のプログラミングが可能となる" ) do
case body == "" || body == nil do
true -> []
false ->
parsed = Cabocha.parse( body )
[ terminate_id ] = terminate( parsed, [] )
ids = nodes( [ terminate_id ], parsed, parsed, [] )
[ terminate_id, ids ]
end
end
def nodes( terminate_id, [ %{ "chunk" => %{ "id" => id, "link" => link } } | tail ], body, node_ids ) do
concat_node_ids = case terminate_id == [ link ] do
true ->
inner_ids = case link == "-1" do
true -> []
false ->
[ ids ] = Enum.map( [ id ], &( nodes( [ &1 ], body, body, [] ) ) )
ids
end
case inner_ids == [] do
true -> node_ids ++ [ id ]
false -> node_ids ++ [ id, inner_ids ]
end
false -> node_ids
end
nodes( terminate_id, tail, body, concat_node_ids )
end
def nodes( _terminate_id, [], _body, node_ids ), do: node_ids
def terminate( [ %{ "chunk" => %{ "id" => id, "link" => "-1" } } | tail ], _terminate_id ) do
terminate( tail, [ id ] )
end
def terminate( [ _ | tail ], terminate_id ) do
terminate( tail, terminate_id )
end
def terminate( [], terminate_id ), do: terminate_id
end
ビルドして動かすと、各chunkのツリー構造が、入れ子リストで表示されます
iex> recompile()
iex> Relation.get
["6", ["0", "3", ["2", ["1"]], "5", ["4"]]]
ちなみに、inspect()を使うと、Phoenixでも表示できるみたいなので、CaboCha解析結果の「id」と「link」の関係が表現されていることを確認してください
<p>あなた「<%= @params[ "message" ] %>」</p>
<p>貧弱AI「<%= MiniAi.listen( @params[ "message" ] ) %>」</p>
<form method="GET" action="/">
<input type="text" name="message" size="60" value="">
<input type="submit" value="話しかける">
</form>
<hr>
<h3>CaboCha解析結果</h3>
<p><pre><%= Cabocha.view( @params[ "message" ] ) %></pre></p>
<p><pre><%= inspect( Relation.get( @params[ "message" ] ) ) %></pre></p>
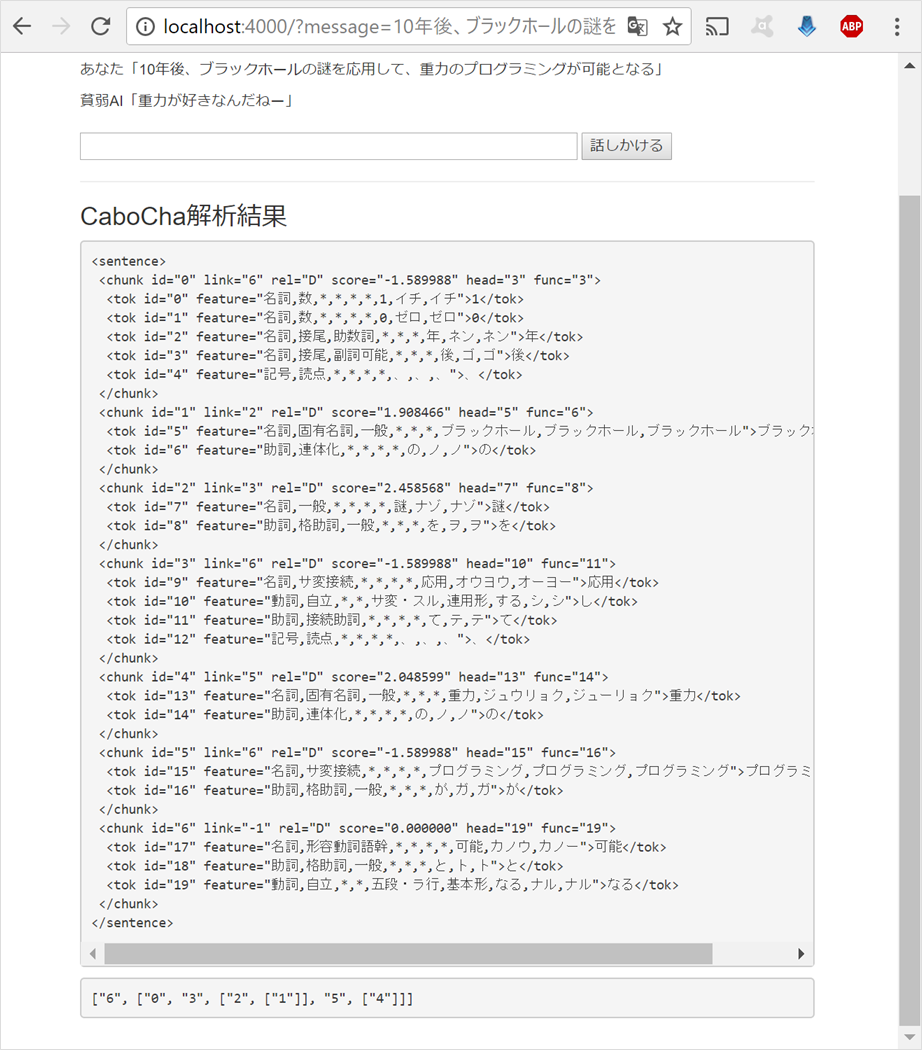
ここまでで、文章の構造と、各フレーズ内の単語とその品詞が分解できたので、文章の意味を解析できるようになりました ![]()
意味を解釈する(概論および要件定義編)
たとえば、iPhoneのSiriや、AndroidのGoogleNowのようなライトな人工無能は、スマホに「命令」口調で指示することで、天気を調べたり、Web検索したりができますが、これは言われた文章の意味の解釈として、「述語のアクション+名詞が述語の対象」という感じで、意味解釈し、設定済のアクションを実行します
「OK、Google。昨日の天気を教えて。」と言うと、Androidは、「天気を調べる」という設定済みアクションを、「昨日」という対象で行います(文章の間にある「~の~」や「~を~」、もしくは「~教えて」は、無視してたりします ![]() )
)
今回、開発しているAIは、より対話を意識した設計として、「命令」口調による意味解釈としてのアクションよりも、「ユーザがただボヤいた」ことに対し、リアクションするような設計を目指してみましょう
その1つの実装として、これは「コーチング」ないしは「カウンセリング」のテクニックになりますが、「相手がやろうとしていること(≒述語)を理解し、相手自身により深く考えてもらう」ために、「相手のやろうとしていることをそのまま質問する」、をやってみます
意味を解釈する(基本設計編)
「10年後、ブラックホールの謎を応用して、重力のプログラミングが可能となる」という文章は、述語である「可能となる」(・・・CaboCha解析結果のid="6")に対し、以下3つが係るツリー構造となっています
①「10年後」・・・CaboCha解析結果のid="0"
②「ブラックホールの謎を応用して」・・・CaboCha解析結果のid="3"←"2"←"1"
③「重力のプログラミングが」・・・CaboCha解析結果のid="5"←"4"
これを質問形式にすると、こんな感じです
①「10年後、可能になるんですね?」
②「ブラックホールの謎を応用して、可能になるんですね?」
③「重力のプログラミングが、可能になるんですね?」
なんかどれも、それっぽい返事に聞こえますね? ![]()
どれか1つを選ぶのは、悩ましいところですが、独断と偏見で③でいきます
実はこのテクニック、明石家さんまがトークするときのテクニックであり、異性にモテたり、セールスで相手から本音を引き出すためのテクニックでもあったりしますので、あまり異性ウケしないなぁとか相手にうまく売り込めないなぁと悩んでいる方は、意識されると良いかも知れません ![]()
意味を解釈する(詳細設計編)
この文章のツリー構造は、終端の動詞句である"6"をトップとし、その直下の名詞句の先頭である"0"、"3"、"5"が並ぶ構成なので、最後の名詞句である"5"を選び、"5"配下のフレーズと、"6"のフレーズ、質問である「んですね?」を接げば完成です
本来、動詞句や名詞句は、各フレーズ内の単語の品詞を解析し、マッチしなければ次の候補をチェックしますが、CaboChaの解析結果は、既にこれを意識した解析結果となっているため、「常にリスト先頭にある動詞句」="6"と、「その直下の最後の名詞句」="5"配下の各フレーズを抽出すればOKです
意味を解釈する(実装編①:ユーティリティの実装)
まずは、idを指定すると、そのフレーズを返す関数が必要です
defmodule Cabocha do
def get_words( [ %{ "chunk" => %{ "id" => id }, "toks" => toks } | tail ], target_id, words ) do
new_words = case id == target_id do
true -> concat_toks( toks, "" )
false -> words
end
get_words( tail, target_id, new_words )
end
def get_words( [], _target_id, words ), do: words
def concat_toks( [ %{ "word" => word } | tail ], words ) do
concat_toks( tail, words <> word )
end
def concat_toks( [], words ), do: words
…
次に、直下の名詞句の先頭をリストアップするために、ツリーの任意の階層をリストアップする関数を作ります
また、名詞句の階層を全て取得してくるために、任意のid配下をリストアップする関数も作ります
defmodule Relation do
def list_level( [ head | tail ], target_level, current_level, items ) do
new_items = case is_list( head ) do
true ->
list_level( head, target_level, current_level + 1, items )
false ->
case target_level == current_level do
true -> items ++ [ head ]
false -> items
end
end
list_level( tail, target_level, current_level, new_items )
end
def list_level( [], _target_level, _current_level, items ), do: items
def list_follow( [ head | tail ], target_id, is_following, items ) do
new_items = case is_list( head ) do
true ->
list_follow( head, target_id, is_following, items )
false ->
case head == target_id || is_following do
true ->
inner_items = items ++ [ head ]
case is_list( List.first( tail ) ) do
true ->
next_target_id = List.first( tail ) |> List.first
list_follow( tail, next_target_id, true, inner_items )
false ->
inner_items
end
false -> items
end
end
case is_following do
false -> list_follow( tail, target_id, is_following, new_items )
true -> new_items
end
end
def list_follow( [], _target_id, _is_following, items ), do: items
…
意味を解釈する(実装編②:メイン処理の実装)
ここまで作った関数を組み合わせて、「常にリスト先頭にある動詞句」="6"と、「その直下の最後の名詞句」="5"配下の各フレーズを抽出するには、以下のようなコードを書けばOKです
defmodule MiniAi do
def listen( message \\ "進撃の巨人はとても面白いです" ) do
case message do
"" -> ""
nil -> ""
_ ->
relation = Relation.get( message )
verb_id = List.first( relation )
subject_top_id = Relation.list_level( relation, 1, 0, [] ) |> List.last
subject_ids = Relation.list_follow( relation, subject_top_id, false, [] )
syntax = Cabocha.parse( message )
verb = get_multi_words( [ verb_id ], syntax, "" )
subjects = get_multi_words( subject_ids, syntax, "" )
"#{subjects}#{verb}んですね?"
end
end
def get_multi_words( [ head | tail ], syntax, words ) do
word = Cabocha.get_words( syntax, head, "" )
get_multi_words( tail, syntax, word <> words )
end
def get_multi_words( [], _syntax, words ), do: words
…
では、試してみましょう
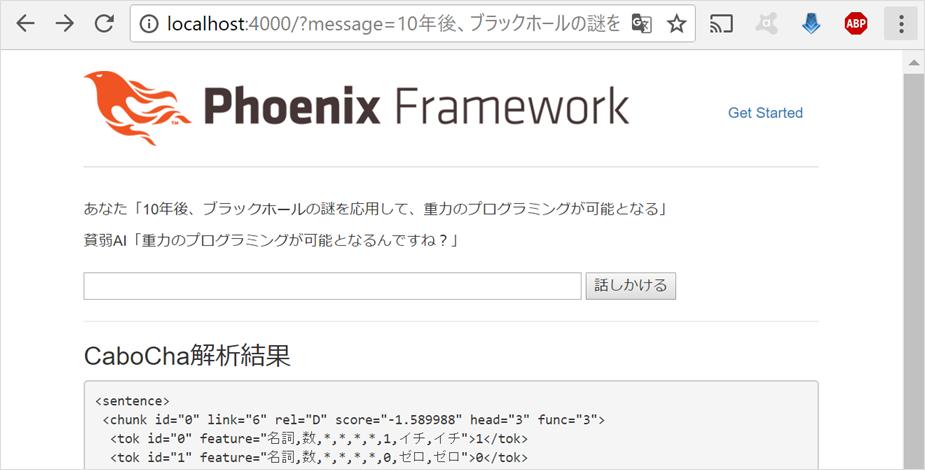
うまく、いきました!! ![]()
他の文章だと、どうでしょう?
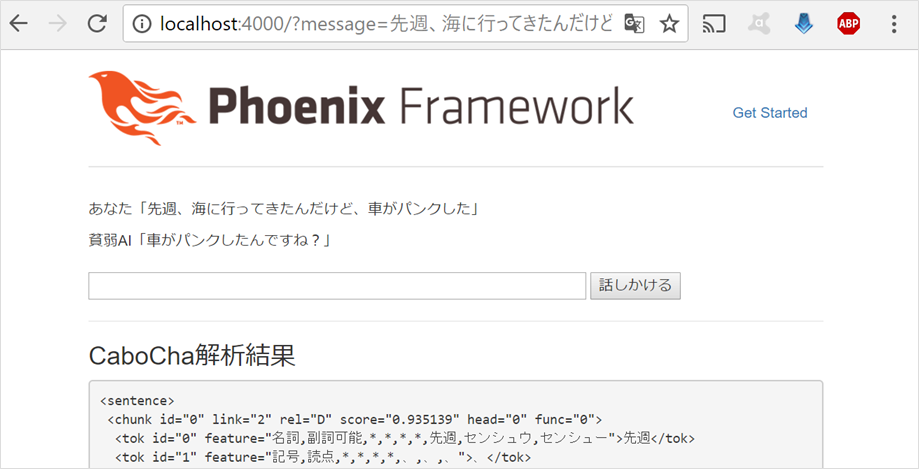
うん、いい感じですね
しかし、文章末尾が口語体とかになると...
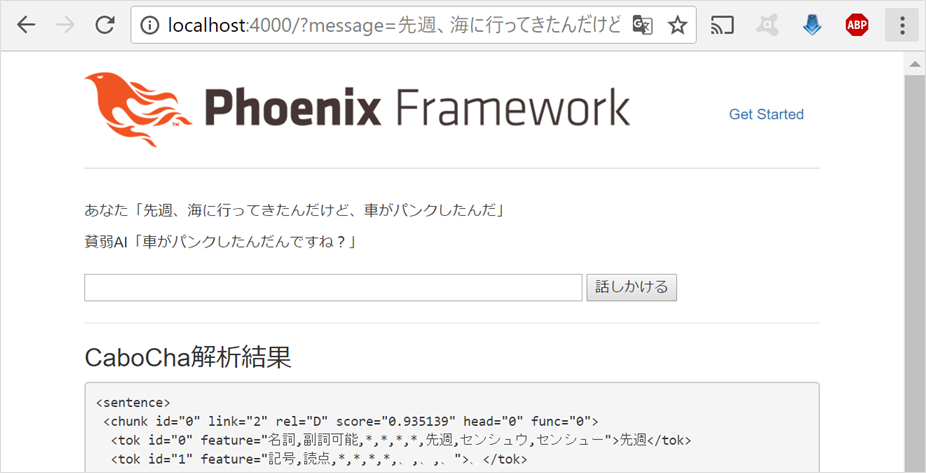
まぁ、おかしな感じになりますが、ここの補正は、また今度の機会に
基本、品詞のパターンで削っていくことになりますが、if文の嵐になる上、精度がイマイチなので、機械学習やディープラーニングを使って除去できれば、と考えています
次回は、これまでの文章解析から少し方向性を変え、AIに感情のような「状態」を持たせ、その状態次第で返事を変えるようなロジックを作りましょう ![]()