(この記事は Elixir (その2)とPhoenix Advent Calendar 2016 11日目の記事です)
前回は、AIに感情のような「状態」を持たせ、その状態次第で返事を変えるようなロジックを作ってみました
最終回である今回は、くだけた会話もそこそこ理解できるようにするための工夫として、幾つかのトリッキーな構文での応答を作り込みます
また、Wikipediaから引用するようなロジックも作ってみたいと思います ![]()
なお、本コラム中の「Elixirの書き方」については、あまり細かく説明をしていないので、「ここの書き方が分からない」とか「この処理が何をしているのかよく分からない」等あればコメントください ![]()
くだけた会話のパターン
ひとまず、以下のような、くだけた会話に対応できるよう、品詞等の構成とリアクションを整理します
| パターン | 品詞等の構成 | リアクション |
|---|---|---|
| ①要望(見たい、等) | 「動詞,自立」+「助動詞」”たい” | 興味あれば同意する |
| ②問いかけ(見る?、見たい?、等) | 「動詞,自立」(+「助動詞」”たい”)+「記号」”?” | 興味あれば賛成する |
| ③同意要求(~よね?) | 「助詞,終助詞」”よ”+「助詞,終助詞」”ね” | 興味あれば同意する |
| ④ボソっとドラマ名などを言われる | 「固有名詞」のみ | Wikipediaから引用 |
さて、これらのパターンを追加する前に、3つほど、事前準備をしておきます ![]()
(準備1)英字単語の品詞キャプチャを修正
CaboChaで、英字単語で無い文字列は、以下のように、「feature」に9つの項目があります
<tok id="1" feature="助動詞,*,*,*,特殊・デス,基本形,です,デス,デス">です</tok>
一方、英字単語は、以下のように、「feature」に7つしか項目が無いため、現在のCabochaモジュールでうまくキャプチャできていないため、修正します
<tok id="0" feature="名詞,一般,*,*,*,*,*">SF</tok>
9項目のキャプチャで失敗した際は、7項目でキャプチャし直す修正とします
defmodule Cabocha do
…
def feature_map( feature ) do
map_feature = Regex.named_captures( ~r/
^
(?<part_of_speech>[^,]*),
\*?(?<part_of_speech_subcategory1>[^,]*),
\*?(?<part_of_speech_subcategory2>[^,]*),
\*?(?<part_of_speech_subcategory3>[^,]*),
\*?(?<conjugation_form>[^,]*),
\*?(?<conjugation>[^,]*),
\*?(?<lexical_form>[^,]*),
\*?(?<yomi>[^,]*),
\*?(?<pronunciation>.*)
$
/x, feature )
remap_feature = case map_feature == nil do
true ->
Regex.named_captures( ~r/
^
(?<part_of_speech>[^,]*),
\*?(?<part_of_speech_subcategory1>[^,]*),
\*?(?<part_of_speech_subcategory2>[^,]*),
\*?(?<part_of_speech_subcategory3>[^,]*),
\*?(?<conjugation_form>[^,]*),
\*?(?<conjugation>[^,]*),
\*?(?<lexical_form>[^,]*)
$
/x, feature )
false -> map_feature
end
remap_feature
end
…
(準備2)接続詞を前の単語と繋げる
「接尾」や「サ変接続」といった、接続詞となるサブ品詞があった場合、前の単語と繋げます
まず、繋げるための判定と、繋げる処理をDialogモジュールとして作成します
defmodule Dialog do
def compact_feature( [ %{ "chunk" => chunk, "toks" => toks } | tail ], list ) do
compact_feature( tail, list ++ [ %{ "chunk" => chunk, "toks" => compact_tok( toks, [] ) } ] )
end
def compact_feature( [], list ), do: list
def compact_tok( [ %{ "id" => id, "word" => word, "feature" => feature } | tail ], tok_list ) do
{ new_tok, new_tail } = case feature do
%{ "part_of_speech" => "名詞", "part_of_speech_subcategory1" => "数" } ->
{ %{ "id" => id, "word" => word, "feature" => feature }, tail }
|> compact_number
|> concat_unit
%{ "part_of_speech" => "名詞" } ->
{ %{ "id" => id, "word" => word, "feature" => feature }, tail }
|> concat_unit
_ -> no_edit( { %{ "id" => id, "word" => word, "feature" => feature }, tail } )
end
compact_tok( new_tail, tok_list ++ [ new_tok ] )
end
def compact_tok( [], tok_list ), do: tok_list
def no_edit( { %{ "id" => id, "word" => word, "feature" => feature }, tail } ) do
{ %{ "id" => id, "word" => word, "feature" => feature }, tail }
end
def compact_number( { no_edit = %{ "id" => id, "word" => word, "feature" => feature }, tail } ) do
case List.first( tail ) do
%{ "feature" => %{ "part_of_speech" => "名詞", "part_of_speech_subcategory1" => "数" }, "word" => word2 } ->
[ _ | next_tail ] = tail
new_feature = feature
|> Map.update( "lexical_form", "", &( &1 = word <> word2 ) )
|> Map.update( "pronunciation", "", &( &1 = word <> word2 ) )
|> Map.update( "yomi", "", &( &1 = word <> word2 ) )
{ %{ "id" => id, "word" => word <> word2, "feature" => new_feature }, next_tail }
_ -> no_edit( { no_edit, tail } )
end
end
def concat_unit( { no_edit = %{ "id" => id, "word" => word, "feature" => feature }, tail } ) do
case List.first( tail ) do
%{ "feature" => %{ "part_of_speech" => "名詞", "part_of_speech_subcategory1" => "接尾", "pronunciation" => pronunciation, "yomi" => yomi }, "word" => word2 } ->
[ _ | next_tail ] = tail
new_feature = feature
|> Map.update( "lexical_form", "", &( &1 = word <> word2 ) )
|> Map.update( "pronunciation", "", &( &1 = word <> pronunciation ) )
|> Map.update( "yomi", "", &( &1 = word <> yomi ) )
{ %{ "id" => id, "word" => word <> word2, "feature" => new_feature }, next_tail }
%{ "feature" => %{ "part_of_speech" => "名詞", "part_of_speech_subcategory1" => "サ変接続" }, "word" => word2 } ->
[ _ | next_tail ] = tail
new_feature = feature
{ %{ "id" => id, "word" => word <> word2, "feature" => new_feature }, next_tail }
_ -> no_edit( { no_edit, tail } )
end
end
end
Cabochaモジュールのパースの末尾に、Dialogモジュール呼出を追加し、単語を繋げて、1つの単語にまとめます
defmodule Cabocha do
…
def parse( body \\ "10年後、ブラックホールの謎を応用した、重力のプログラミングが可能となる" ) do
body
|> xml
|> XmlParser.parse
|> chunks
|> chunk_map( [] )
|> Dialog.compact_feature( [] )
end
…
(準備3)会話処理をリファクタリング+句読点の半角スペース置換
今回、様々な会話処理が追加されてゴチャゴチャしてくるため、これまで実装した会話処理を関数化することでスッキリさせておきます
またMeCab/CaboChaは、「記号」とその直後の句読点を、1つの単語としてまとめてしまうことがあるため、事前に句読点を半角スペースに置換しておきます(置換しても構文解析の結果は全く変わりません)
defmodule MiniAi do
…
def listen( message \\ "えりこは圧倒的に美しい" ) do
clean_message = message
|> String.replace( "、", " " )
|> String.replace( "。", " " )
case clean_message do
"" -> ""
nil -> ""
_ ->
relation = Relation.get( clean_message )
verb_id = List.first( relation )
noun_ids = Relation.list_level( relation, 1, 0, [] )
subject_ids = Relation.list_follow( relation, noun_ids |> List.last, false, [] )
syntax = syntax( clean_message )
verb = get_multi_words( [ verb_id ], syntax, "" )
subjects = get_multi_words( subject_ids, syntax, "" )
emotional_reply = emotional( syntax, noun_ids, verb_id )
case emotional_reply != "" do
true -> emotional_reply
false -> others( subjects, verb )
end
end
end
def emotional( syntax, noun_ids, verb_id ) do
abuse = any( Emotion.abuse, syntax, verb_id, "" )
praise = any( Emotion.praise, syntax, verb_id, "" )
score = case abuse == "" do
true ->
case praise == "" do
true -> 0
false ->
item = Enum.find( Emotion.praise, &( &1[ "word" ] == praise ) )
item[ "score" ]
end
false ->
item = Enum.find( Emotion.abuse, &( &1[ "word" ] == abuse ) )
item[ "score" ]
end
is_me = case score do
0 -> ""
_ -> any_ids( noun_ids, syntax, me(), "" )
end
case is_me == "" do
true -> ""
false ->
Feeling.affected( score )
impressions( score )
end
end
def others( subjects, verb ), do: "#{subjects}#{verb}んですね?"
…
end
ゴチャゴチャしてたlisten()が、だいぶスッキリしましたね ![]()
①要望(見たい、等)
さて、事前準備も完了したので、ここから本編です ![]()
まず、品詞とサブ品詞での判別が必要なので、Cabochaモジュールのmatch_word_class()をサブ品詞まで判別可能に修正します
また、単語指定無でのマッチングもできるようにします
この修正の結果、match_word_class()はbooleanを返す仕様から、マッチした文字列を返す仕様に変更となりますが、その上位のany_tok()が元々マッチ文字列を返す仕様なので、any_tok()で吸収できます
defmodule Cabocha do
def any_tok( [ %{ "chunk" => %{ "id" => id }, "toks" => toks } | tail ], target_id, match, words ) do
match_word = case id == target_id do
true -> match_word_class( toks, match, "" )
false -> ""
end
any_tok( tail, target_id, match, words <> match_word )
end
def any_tok( [], _target_id, _match, word ), do: word
…
def match_word_class( [ %{ "word" => word, "feature" => %{ "part_of_speech" => class, "part_of_speech_subcategory1" => subclass } } | tail ], match, words ) do
is_match = case match[ "word" ] == nil do
true ->
case match[ "subclass" ] == nil do
true -> { class } == { match[ "class" ] }
false -> { class, subclass } == { match[ "class" ], match[ "subclass" ] }
end
false ->
case match[ "subclass" ] == nil do
true -> { word, class } == { match[ "word" ], match[ "class" ] }
false -> { word, class, subclass } == { match[ "word" ], match[ "class" ], match[ "subclass" ] }
end
end
new_word = case is_match do
true -> word
false -> ""
end
match_word_class( tail, match, new_word <> words )
end
def match_word_class( [], _match, words ), do: words
…
興味ある「対象」と、その対象に対する「どんな動詞が来たらリアクションを返すか?」をFavoriteモジュールとして追加します
defmodule Favorite do
def target_and_action do
[
%{ "word" => "BLAME!", "class" => "名詞", "action" => "見る", "reaction" => "映画は5/2までだから急がなきゃ!" },
%{ "word" => "マトリックス", "class" => "名詞", "action" => "見る", "reaction" => "DVD家にあるよ!うちくる?" },
%{ "word" => "海", "class" => "名詞", "action" => "行く", "reaction" => "いいね、のんびり電車で行こうよ" },
%{ "word" => "ドライブ", "class" => "名詞", "action" => "行く", "reaction" => "どこの峠を攻めるの?" },
%{ "word" => "焼肉", "class" => "名詞", "action" => "食べる", "reaction" => "いいね、カルビ食べたい" },
%{ "word" => "焼肉", "class" => "名詞", "action" => "焼く", "reaction" => "食べ放題行く?" },
]
end
end
「動詞,自立」+「助動詞」”たい”を拾う処理を追加します
defmodule MiniAi do
…
def listen( message \\ "えりこは圧倒的に美しい" ) do
…
syntax = syntax( clean_message )
verb = get_multi_words( [ verb_id ], syntax, "" )
subjects = get_multi_words( subject_ids, syntax, "" )
answer = ask( syntax, noun_ids, verb_id )
case answer != "" do
true -> answer
false ->
emotional_reply = emotional( syntax, noun_ids, verb_id )
case emotional_reply != "" do
true -> emotional_reply
false -> others( subjects, verb )
end
end
end
end
def ask( syntax, noun_ids, verb_id ) do
independent_verb = any_ids( [ verb_id ], syntax, %{ "class" => "動詞", "subclass" => "自立" }, "" )
tai_auxiliary_verb = any_ids( [ verb_id ], syntax, %{ "word" => "たい", "class" => "助動詞" }, "" )
case independent_verb != "" && tai_auxiliary_verb != "" do
true -> any_action( noun_ids, verb_id, syntax, Favorite.target_and_action, "" )
false -> ""
end
end
…
試してみましょう
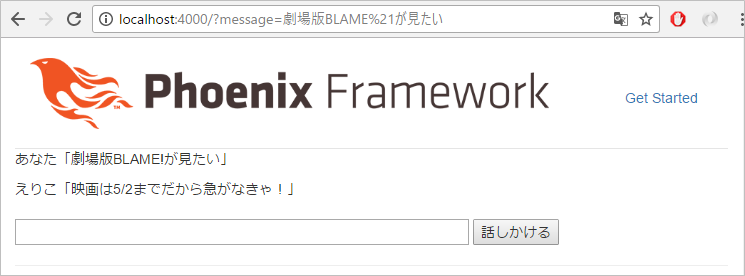
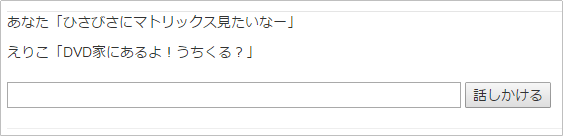
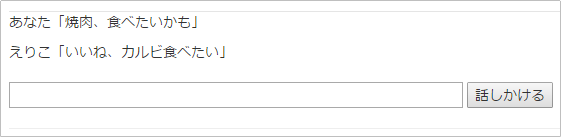
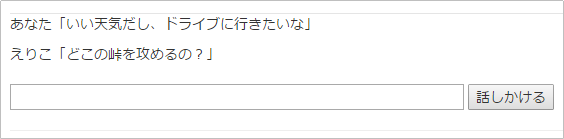
現在のリアクションは、いかにも原始的でバリエーションに乏しいですが、「対象」と「動詞」の組み合わせを判別し、その後のリアクションを決めるロジックは、第4回の「意味を解釈する」でも説明した、「述語のアクション+名詞が述語の対象」のベースになるので、さまざまなバリエーションに発展できる可能性を持っています
たとえば、「福岡の天気を教えて」と入力したら、Yahoo!天気の福岡版を返す、とか、をここから作り込むのは、非常にカンタンです
また、Favoriteモジュールで定義しているリストを、テキストファイルやDBで持たせるようにすれば、「学習による知識の拡張」とかもできます
②問いかけ(見る?、見たい?、等)
先ほど作った「①要望」と、ほぼ同じ構成で、「②問いかけ」は実現できます
まず、問いかけに対する「対象」と「動詞」の組み合わせ毎の「回答」を追加します
defmodule Favorite do
def target_and_answer do
[
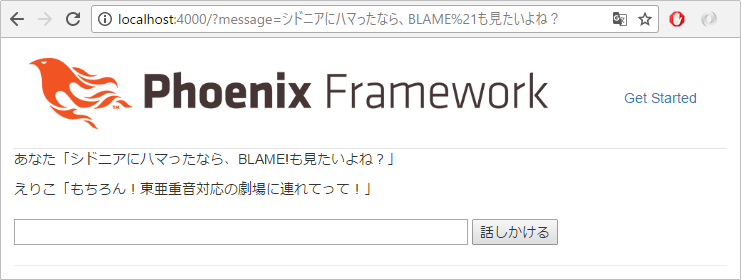
%{ "word" => "BLAME!", "class" => "名詞", "action" => "見る", "reaction" => "もちろん!東亜重音対応の劇場に連れてって!" },
%{ "word" => "マトリックス", "class" => "名詞", "action" => "見る", "reaction" => "次見たら何周目だろ?" },
%{ "word" => "海", "class" => "名詞", "action" => "行く", "reaction" => "新しい水着買ってくれるなら喜んで!" },
%{ "word" => "ドライブ", "class" => "名詞", "action" => "行く", "reaction" => "ずっと助手席でもいいならいいよ" },
%{ "word" => "焼肉", "class" => "名詞", "action" => "食べる", "reaction" => "うん、食べ放題がいい" },
%{ "word" => "焼肉", "class" => "名詞", "action" => "焼く", "reaction" => "焼くより食べる方がいいな" },
]
end
…
そして、「①要望」で追加した関数内に、「②問いかけ」に対する判別とリアクションを追加します
defmodule MiniAi do
…
def ask( syntax, noun_ids, verb_id ) do
independent_verb = any_ids( [ verb_id ], syntax, %{ "class" => "動詞", "subclass" => "自立" }, "" )
tai_auxiliary_verb = any_ids( [ verb_id ], syntax, %{ "word" => "たい", "class" => "助動詞" }, "" )
question = any_ids( [ verb_id ], syntax, %{ "word" => "?", "class" => "記号", "subclass" => "一般" }, "" )
case independent_verb != "" do
true ->
case question != "" do
true -> any_action( noun_ids, verb_id, syntax, Favorite.target_and_answer, "" )
false ->
case tai_auxiliary_verb != "" do
true -> any_action( noun_ids, verb_id, syntax, Favorite.target_and_action, "" )
false -> ""
end
end
false -> ""
end
end
…
試してみましょう
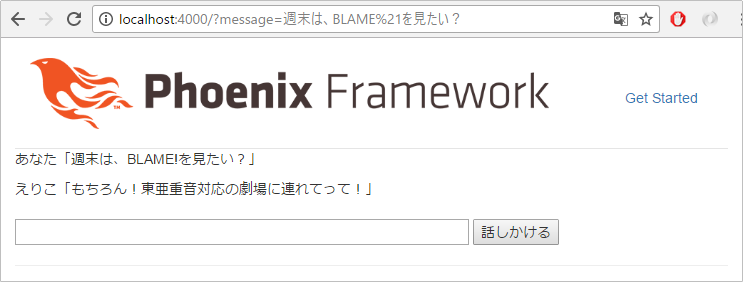

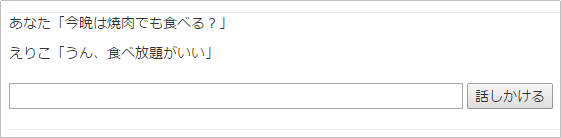
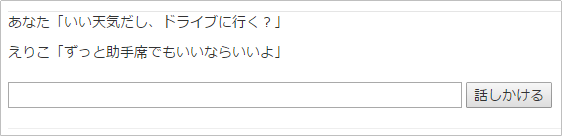
ほぼ同じ文章だけど、多少のニュアンスの違いでリアクションが変わることも確認しましょう
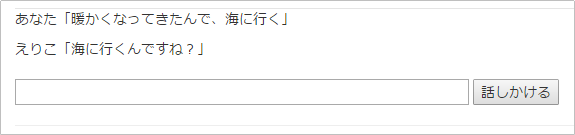
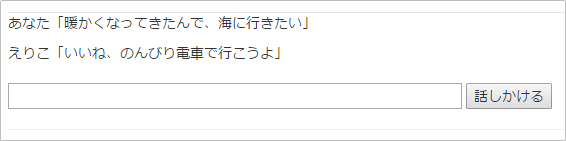
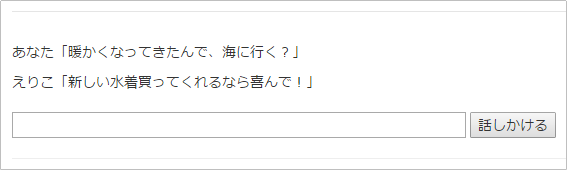
こんな人工無能の向こうに、「海デートに出かける自分」が見出せたら、ある種の素質があります ![]()
③同意要求(~よね)
「③同意要求」も、「①要望」「②問いかけ」とほぼ同じ構造ですが、”よね”の前に、「動詞,自立」が来るか、「形容詞」が来るかは規定できないため、別関数で用意し、「回答」は「②問いかけ」のものをそのまま流用します
defmodule MiniAi do
…
def listen( message \\ "えりこは圧倒的に美しい" ) do
…
answer = ask( syntax, noun_ids, verb_id )
case answer != "" do
true -> answer
false ->
agreement = right( syntax, noun_ids, verb_id )
case agreement != "" do
true -> agreement
false ->
emotional_reply = emotional( syntax, noun_ids, verb_id )
case emotional_reply != "" do
true -> emotional_reply
false -> others( subjects, verb )
end
end
end
end
end
def right( syntax, noun_ids, verb_id ) do
yo_post_particle = any_ids( [ verb_id ], syntax, %{ "word" => "よ", "class" => "助詞", "subclass" => "終助詞" }, "" )
ne_post_particle = any_ids( [ verb_id ], syntax, %{ "word" => "ね", "class" => "助詞", "subclass" => "終助詞" }, "" )
case yo_post_particle != "" && ne_post_particle != "" do
true ->
agreement = any_action( noun_ids, verb_id, syntax, Favorite.target_and_answer, "" )
case agreement == "" do
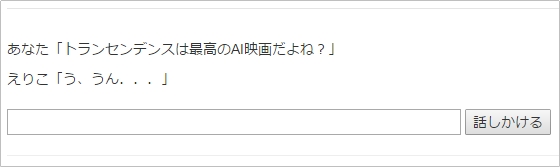
true -> "う、うん..."
false -> agreement
end
false -> ""
end
end
…
試してみましょう
同意してないパターンも試してみます
④ボソっとドラマ名などを言われる
「固有名詞」のみ、ボソっと言われたら、Wikipediaから序文のみを引用します
Wikipedia APIを叩いて、JSON形式で取得します
Wikipedia APIを叩くために、HTTPクライアントの「HTTPoison」モジュールと、JSONパーサの「Poison」モジュールをインストールします
defmodule WebMiniAi.Mixfile do
…
defp deps do
…
{ :httpoison, "~> 0.7.2" },
{ :poison, "~> 1.5" },
…
モジュールを取得します(要ネット接続)
# mix deps.get
さて、現在のxml_parserモジュールは、WikipediaのJSONの本文箇所をハンドリングする関数が未定義でエラーとなってしまうため、本文箇所をハンドリングする関数を追加します
29: defp quinn2xml_parser(%{attr: attr, name: name, value: value}) do
30: {name, parse_attr(attr), quinn2xml_parser(value)}
31: end
32: defp quinn2xml_parser([value]) when is_binary(value), do: value
33: defp quinn2xml_parser([head | tail]) do
これを以下のように書き換えます(32行目と33行目を入れ替え)
29: defp quinn2xml_parser(%{attr: attr, name: name, value: value}) do
30: {name, parse_attr(attr), quinn2xml_parser(value)}
31: end
32: defp quinn2xml_parser([value]) when is_binary(value), do: [ [ value ] | [] ]
33: defp quinn2xml_parser(value) when is_binary(value), do: [ value | [] ]
34: defp quinn2xml_parser([head | tail]) do
この変更により、xml_parserモジュールを使っている、Cabochaモジュールの「word」をパースする箇所が影響を受けるので、以下のように修正します
defmodule Cabocha do
…
def toks_map( [ { :tok, %{ feature: feature, id: id }, [ [ word ] ] } | tail ], tok_list ) do
toks_map( tail, tok_list ++ [ %{ "id" => id, "word" => word, "feature" => feature_map( feature ) } ] )
end
def toks_map( [], tok_list ), do: tok_list
…
これらの準備が終わった後、Wikipedia APIを叩いてパースする、以下コードを追加します
「|> String.replace(~)」が、やたら連発しているところは、Wikipediaから引っ張ってきた本文から、純粋なテキスト以外を除去するノイズフィルター群です
defmodule Wikipedia do
def preface( title \\ "BLAME!" ) do
title
|> contents
|> String.replace( "。", "\n" )
|> String.split( "\n" )
|> List.first
end
def contents( title \\ "BLAME!" ) do
HTTPoison.start
pages = url( title )
|> HTTPoison.get!
|> Parse.body
|> Poison.decode!
|> query_pages
page_id = Map.keys( pages ) |> Enum.at( 0 )
case page_id == "-1" do
true -> ""
false ->
contents = pages[ page_id ]
contents
|> revisions_parsetree
|> XmlParser.parse
|> body
|> not_tuple( "" )
|> String.replace( "[", "" )
|> String.replace( "]", "" )
|> String.replace( "|", "/" )
|> String.replace( ~r/(.+?)/, "" )
|> String.replace( "'''", "" )
end
end
def url( title ), do: "https://ja.wikipedia.org/w/api.php?format=json&action=query&prop=revisions&rvprop=content&rvgeneratexml&titles=#{title}"
def query_pages( %{ "query" => %{ "pages" => pages } } ), do: pages
def revisions_parsetree( %{ "revisions" => [ %{ "parsetree" => parsetree } | _tail ] } ), do: parsetree
def body( { :root, nil, body } ), do: body
def not_tuple( [ head | tail ], not_tuples ) do
new_not_tuple = case is_tuple( head ) do
true -> ""
false ->
[ sentense ] = head
sentense
end
not_tuple( tail, not_tuples <> new_not_tuple )
end
def not_tuple( [], not_tuples ), do: not_tuples
end
「固有名詞」のみなら、Wikipedia APIの序文を知ったかぶりして返す処理を入れます
defmodule MiniAi do
…
def listen( message \\ "えりこは圧倒的に美しい" ) do
…
syntax = syntax( clean_message )
verb = get_multi_words( [ verb_id ], syntax, "" )
subjects = get_multi_words( subject_ids, syntax, "" )
wikipedia_preface = fixed_noun_only( syntax, verb_id, clean_message )
case wikipedia_preface != "" do
true -> wikipedia_preface
false -> ""
answer = ask( syntax, noun_ids, verb_id )
case answer != "" do
true -> answer
false ->
agreement = right( syntax, noun_ids, verb_id )
case agreement != "" do
true -> agreement
false ->
emotional_reply = emotional( syntax, noun_ids, verb_id )
case emotional_reply != "" do
true -> emotional_reply
false -> others( subjects, verb )
end
end
end
end
end
end
…
_build/dev/lib/xml_parserフォルダを削除し、iexを抜けた後、リビルドと再起動を行います
# iex -S mix phoenix.server
固有名詞のみでボヤいてみます
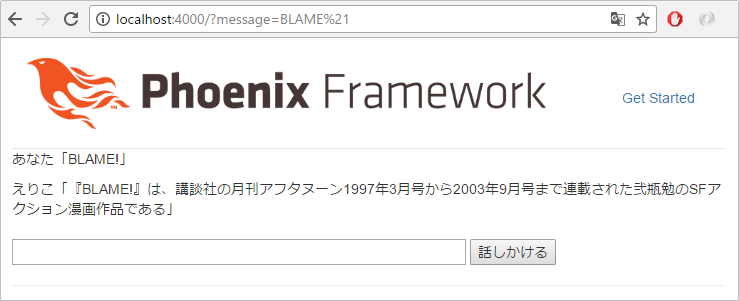

本当は、序文の後半のみ抽出して、砕けた文体にアレンジしたいところですが、もうお腹いっぱいだと思うので、今回は、この位で止めておくとしましょう
まとめ
さて、ここまでの6回で、Elixirによる、「弱々しいAI」を実装してきました ![]()
できあがったものは、まだまだ至るところでボロが出てしまうとは思いますが、当初掲げていた、以下のザックリ仕様は満たしていると思います
- 対話して、言われた文脈を何となく解釈して、それとない返事を返す
- 聞いた言葉から受けた印象から、感情のようなものが揺らぎ、返事が変化する
- 足りない知識は、Wikipediaに取得しに行き、当たり障り無い感じで引用する
また、基礎的な会話エンジンとしての構文解析や意味解析を備えているため、ボット等に応用できるレベルには達したのでは無いかと思われます
ここから先は、文末だけで無く文章全体を把握する意味解析に改善したり、品詞の解釈パターンを機会学習で自動生成したり、知識情報をElixirリストから外部のファイル/DBに分離したり、SlackやTwitterの会話から自動学習したり、リアクションだけで無い能動的発言の機能を追加したり...と、様々なやれることがありますが、1stシーズンとしては〆たいと思います ![]()
2ndシーズンが実現するかは、未だ分かりませんが、Elixirのコラムは、テーマを変えて引き続き書いていくので、そんなに遠くない日に続編始めているかも知れません ![]()
余談
このシリーズで作ったような「ゆるふわ系AI」好きには堪らないオススメ小説を2冊ほど紹介します

普段の生活をAI(バディ)がアシスタントするのが当たり前になった社会で、人が死んだ後もバディが生き様を受け継いでデジタルの世界で生存し続けたり、宇宙人とのコンタクトをバディ経由で行う試みをしたり...という世界観が実現するまでのドタバタを、「OL」と「ドロップアウトした学生」、「凄腕プログラマ」の3人と各々のバディ達が繰り広げるラブコメ
出てくるAIは、ゆるふわ系ばっかりなので、ハードな印象は全く無いが、中古PCに潜伏さえたワームで某国の地下兵器庫を破壊したり、義手に知能が宿ったり、AIが宇宙と通信して地上に向けて光を明滅させたり、とこっそりハードSFのニュアンスがチラホラ

人格を全てコンピュータ上で記述できる「ITP」というテクノロジーを商業向けに開発する研究者サマンサが、重病にかかり、余命僅か、という中で、量子コンピュータ上に生成されたITP人格「wanna be」と共に、人間の生死や、作られた人格の死がどういう意味を持つのか等について、理解し合うストーリー
コンピュータ上に人格が生成される一方で、サマンサは死へ向かう運命を受け入れられず、他人のデータ化されたITPを自らの脳にインストールするタブーを犯したり、「wanna be」を自らにダウンロードして共存する提案をしたり、自分の脳をデータ化した人格と会話したり、と、中盤以降は、かなりのハードSFな展開だが、「wanna be」の人間臭い部分と、非人間的な部分の違いが、ゆるふわ系AIかな