Chainerを使ってSemantic Segmentationをやってみよう、ということで、SegNetを実装してみました(実はFCNもやってみたけど、なんかうまくいかなかった)。Semantic Segmentationというのは、ピクセル単位に識別をやるということで、SegNetは代表的なSemantic Segmentationのモデルの一つです。SegNetは2016年にVijay Badrinarayananらによって提案されました(原論文はこちら)。いまではSegNetより遥かに正確にSegmentationが可能なモデルもたくさん提唱されていますが、実装力を試してみるのによい課題だと思って挑戦してみました。SegNetについての詳しい説明は@cyberailabさんの記事にまとまっているのでここでは触れません。
またここでは、ガチのSegNetではなく、その廉価版のSegNet Basicを実装&実行してみました。なお、実装に際しては、SegNetをKerasで実装した@uni-3さんの記事の記事をとても参考にしました。私の記事は@uni-3さんの記事の内容をchainerに移植したプラスアルファくらいの内容です。
以下の全コードはgitにあげています。
環境
python 3.5.2
chainer 5.1.0
Ubuntu 16.04
GeForce GTX 1050
データ
CamVidというデータセットを用いました。
https://github.com/alexgkendall/SegNet-Tutorial
リポジトリのCamVid内のデータを使います。クラス数は12です。
annotフォルダの中には真っ黒な画像が入っていますが、これをPILなどで開いてみると各セルに0から11までの数字が入っています。
ちなみに、このデータセットのみでは十分な汎化性能を出すことができません。もっと多くの訓練データが必要です。
2019/4/16 追記
U-Netの実装とsegmentationの結果を末尾に書き加えました。
実装
また、以下のコードを読む際にはpngのインデックスカラーについて知っておくとスムーズに理解が進むと思います。
下準備
まずは、諸設定を行うconfig.pyファイルを作ります。
dropoutをTrueにすると、学習に時間がかかりますが過学習を抑制できます。img_normalizationがTrueの場合は@uni-3さんの記事のdataset.pyで行われていた操作と同じことを前処理としてRGB画像に施します。LRNは局所的応答正規化のことで、TrueにするとネットワークにRGB画像を読み込む際に局所応答正規化を実行します。
GPUメモリに余裕がある場合はbatch_sizeを大きくするとよいと思います。
max_epoch = 101
batch_size = 1
n_class = 12
img_size = (360, 480)
train_img_path = "dataset/train"
train_gt_path = "dataset/trainannot"
valid_img_path = "dataset/val"
valid_gt_path = "dataset/valannot"
test_img_path = "dataset/test"
test_gt_path = "dataset/testannot"
save_predicted_path = "predicted_imgs"
save_model_path = "saved_models"
img_normalization = True
LRN = True
dropout = True
次に必要に応じて、dataset内の画像や画像名を参照するloader.pyを作ります。
Chainerでは、CNNに(バッチサイズ, チャンネル数, 縦, 横)の4次元配列を食わせるため、その準備として、(縦,横,チャンネル数)という並びの配列を(チャンネル数, 縦, 横)という順番にtransposeすることに注意してください。
import os
import cv2
import numpy as np
import config
img_size = config.img_size
train_img_path = config.train_img_path
valid_img_path = config.valid_img_path
train_gt_path = config.train_gt_path
valid_gt_path = config.valid_gt_path
def img_loader(imgs_names, valid=False):
num_imgs = len(imgs_names)
imgs = np.empty((num_imgs, 3, img_size[0], img_size[1]), dtype="float32")
for i in range(num_imgs):
if not valid:
img = cv2.imread(os.path.join(train_img_path, imgs_names[i]))
else:
img = cv2.imread(os.path.join(valid_img_path, imgs_names[i]))
img = img.transpose(2,0,1)
img = img.astype("float32")
imgs[i] = img
gts = np.empty((num_imgs, img_size[0], img_size[1]), dtype="int32")
for i in range(num_imgs):
if not valid:
gt = cv2.imread(os.path.join(train_gt_path, imgs_names[i]))
else:
gt = cv2.imread(os.path.join(valid_gt_path, imgs_names[i]))
gt = gt.astype("int32")
gt = gt[:,:,0] #gt[:,:,0] == gt[:,:,1] == gt[:,:,2]
gt = gt.reshape(img_size[0], img_size[1]) #which is better it or flatten()?
gts[i] = gt
return imgs, gts
def img_names_loader():
imgs_names = os.listdir(train_img_path)
imgs_names.sort()
imgs_names = np.asarray(imgs_names)
gt_names = os.listdir(train_gt_path)
gt_names.sort()
gt_names = np.asarray(gt_names)
valid_imgs_names = os.listdir(valid_img_path)
valid_imgs_names.sort()
valid_imgs_names = np.asarray(valid_imgs_names)
valid_gt_names = os.listdir(valid_gt_path)
valid_gt_names.sort()
valid_gt_names = np.asarray(valid_gt_names)
return imgs_names, gt_names, valid_imgs_names, valid_gt_names
次にconfig.pyでimg_normalization = Trueとした場合に実行されるスクリプトを書きます。opencvでヒストグラム平坦化を各チャンネル毎に行います。
import cv2
import os
import config
import numpy as np
img_size = config.img_size
def normalize(imgs):
num_imgs = len(imgs)
imgs = imgs.astype("uint8")
normalized_imgs = np.zeros((num_imgs, 3, img_size[0], img_size[1]), dtype="float32")
for i in range(num_imgs):
normalized_imgs[i,0,:,:] = cv2.equalizeHist(imgs[i,0,:,:])
normalized_imgs[i,1,:,:] = cv2.equalizeHist(imgs[i,1,:,:])
normalized_imgs[i,2,:,:] = cv2.equalizeHist(imgs[i,2,:,:])
return normalized_imgs
モデル
SegNet Basicの本体をchainerで記述します。config.pyでLRN = Trueとすると、局所応答正規化を行うF.local_response_normalizationが入力rgb画像xに行われます。dropout = True とするとネットワークの中央でドロップアウトを生じさせます。これらは、原論文に忠実に加えました。
import chainer
import chainer.links as L
import chainer.functions as F
import config
from chainer import Chain
n_class = config.n_class
LRN = config.LRN
dropout = config.dropout
class SegNet(Chain):
def __init__(self, n_class=n_class):
super().__init__()
with self.init_scope():
self.n_class = n_class
self.enco1_1 = L.Convolution2D(None, 64, ksize=3, stride=1, pad=1) #image size will not change
self.enco2_1 = L.Convolution2D(None, 128, ksize=3, stride=1, pad=1)
self.enco3_1 = L.Convolution2D(None, 256, ksize=3, stride=1, pad=1)
self.enco4_1 = L.Convolution2D(None, 512, ksize=3, stride=1, pad=1)
self.deco4_1 = L.Convolution2D(None, 512, ksize=3, stride=1, pad=1)
self.deco3_1 = L.Convolution2D(None, 256, ksize=3, stride=1, pad=1)
self.deco2_1 = L.Convolution2D(None, 128, ksize=3, stride=1, pad=1)
self.deco1_1 = L.Convolution2D(None, 64, ksize=3, stride=1, pad=1)
self.deco0_1 = L.Convolution2D(None, n_class, ksize=1)
self.bn_enco1_1 = L.BatchNormalization( 64)
self.bn_enco2_1 = L.BatchNormalization(128)
self.bn_enco3_1 = L.BatchNormalization(256)
self.bn_enco4_1 = L.BatchNormalization(512)
self.bn_deco4_1 = L.BatchNormalization(512)
self.bn_deco3_1 = L.BatchNormalization(256)
self.bn_deco2_1 = L.BatchNormalization(128)
self.bn_deco1_1 = L.BatchNormalization( 64)
def __call__(self, x): #x = (batchsize, 3, 360, 480)
if LRN:
x = F.local_response_normalization(x) #Needed for preventing from overfitting
h = F.relu(self.bn_enco1_1(self.enco1_1(x)))
h, idx1 = F.max_pooling_2d(h, 2, stride=2, return_indices=True)
h = F.relu(self.bn_enco2_1(self.enco2_1(h)))
h, idx2 = F.max_pooling_2d(h, 2, stride=2, return_indices=True)
h = F.relu(self.bn_enco3_1(self.enco3_1(h)))
h, idx3 = F.max_pooling_2d(h, 2, stride=2, return_indices=True)
h = F.relu(self.bn_enco4_1(self.enco4_1(h)))
if dropout:
h = F.dropout(h)
h, idx4 = F.max_pooling_2d(h, 2, stride=2, return_indices=True)
h = F.relu(self.bn_deco4_1(self.deco4_1(h)))
h = F.unpooling_2d(h, ksize=2, stride=2, outsize=(idx3.shape[2], idx3.shape[3]))
h = F.relu(self.bn_deco3_1(self.deco3_1(h)))
h = F.unpooling_2d(h, ksize=2, stride=2, outsize=(idx2.shape[2], idx2.shape[3]))
h = F.relu(self.bn_deco2_1(self.deco2_1(h)))
h = F.unpooling_2d(h, ksize=2, stride=2, outsize=(idx1.shape[2], idx1.shape[3]))
h = F.relu(self.bn_deco1_1(self.deco1_1(h)))
h = F.unpooling_2d(h, ksize=2, stride=2, outsize=(x.shape[2], x.shape[3]))
h = self.deco0_1(h)
return h
訓練&テスト
Trainを行うtrain.pyを作ります。loss関数は原論文にあるようにweight balancedされたsoftmax cross entropyを採用します。ここで唐突にclass_weighting配列が登場しますが、これは@uni-3さんの記事のtrain.pyから引用しました。この数字の根拠は分かりません。どのように求めたのか誰か知っていれば教えてください。
デフォルトで訓練中のモデルは10 epoch毎に.h5ファイルとしてsaved_modelに保存されます。また、同じく10 epoch毎にvalidation loss と training loss の変化を折れ線グラフで表したloss_curve.pngが保存されます。
私はtrainerなどを使って、コードを抽象化するのが苦手なのでベタ書きしています。
import os
import cv2
import time
import numpy as np
import cupy as xp
import matplotlib.pyplot as plt
from chainer import functions as F
from chainer import Variable, optimizers, serializers
import network
import config
import loader
import normalize
max_epoch = config.max_epoch
batch_size = config.batch_size
n_class = config.n_class
save_model_path = config.save_model_path
img_normalization = config.img_normalization
class_weighting = xp.array([0.2595, 0.1826, 4.5640, 0.1417, 0.5051, 0.3826, 9.6446, 1.8418, 6.6823, 6.2478, 3.0, 7.3614], dtype="float32")
def draw_loss_curve(t_loss, v_loss):
t = np.arange(0, len(t_loss))
plt.figure(figsize=(8,8))
plt.plot(t, t_loss, label="train", color="b")
plt.plot(t, v_loss, label="valid", color="r")
plt.legend(fontsize=18)
plt.xlabel("Epoch", fontsize=18)
plt.ylabel("Loss", fontsize=18)
plt.title("Loss Curve", fontsize=18)
plt.ylim(0, 2.5)
plt.savefig("loss_curve.png")
plt.clf()
def train():
if not os.path.exists(save_model_path):
os.makedirs(save_model_path)
print("Made save folder")
imgs_names, gt_names, valid_imgs_names, valid_gt_names = loader.img_names_loader()
model = network.SegNet(n_class = n_class)
model.to_gpu(0)
optimizer = optimizers.Adam().setup(model)
train_loss_recode = []
valid_loss_recode = []
N = len(imgs_names)
M = len(valid_imgs_names)
perm = np.random.permutation(N)
perm_valid = np.random.permutation(M)
start_time = time.time()
for epoch in range(max_epoch):
losses = []
for i in range(0, N, batch_size):
imgs_names_batch = imgs_names[perm[i:i + batch_size]]
imgs_batch, gt_batch = loader.img_loader(imgs_names_batch)
if img_normalization:
imgs_batch = normalize.normalize(imgs_batch)
imgs_batch = Variable(imgs_batch)
imgs_batch.to_gpu(0)
gt_batch = Variable(gt_batch)
gt_batch.to_gpu(0)
model.cleargrads()
t = model(imgs_batch)
loss = F.softmax_cross_entropy(t, gt_batch, class_weight=class_weighting)
loss.backward()
optimizer.update()
losses.append(loss.data)
valid_losses = []
for i in range(0, M, batch_size):
valid_names_batch = valid_imgs_names[perm_valid[i:i + batch_size]]
valid_imgs_batch, valid_gt_batch = loader.img_loader(valid_names_batch, valid=True)
if img_normalization:
valid_imgs_batch = normalize.normalize(valid_imgs_batch)
valid_imgs_batch = Variable(valid_imgs_batch)
valid_imgs_batch.to_gpu(0)
valid_gt_batch = Variable(valid_gt_batch)
valid_gt_batch.to_gpu(0)
model.cleargrads()
t = model(valid_imgs_batch)
valid_loss = F.softmax_cross_entropy(t, valid_gt_batch, class_weight=class_weighting)
valid_losses.append(valid_loss.data)
train_loss_recode.append(sum(losses)/len(losses))
valid_loss_recode.append(sum(valid_losses)/len(valid_losses))
print("epoch:{0:}\t train loss:{1:.5f}\t valid loss:{2:.5f}\t time:{3:.2f}[sec]".format(epoch, float(train_loss_recode[-1]), float(valid_loss_recode[-1]), time.time()-start_time))
if epoch % 10 == 0:
draw_loss_curve(train_loss_recode, valid_loss_recode)
serializers.save_hdf5(os.path.join(save_model_path, "SegNet_{}.h5".format(epoch)), model)
print("saved model")
if __name__ == '__main__':
train()
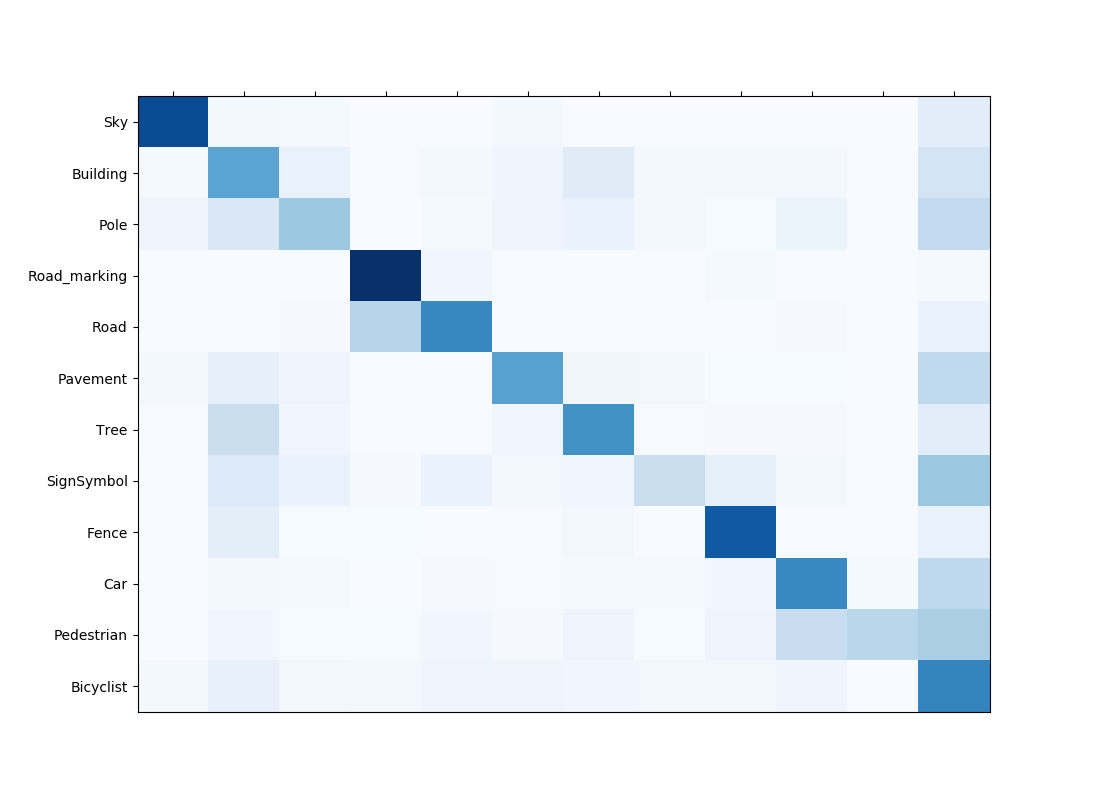
次にテスト用コードを書きます。dataset/train内にある画像を順番にトレーニング済みのモデルに突っ込んだ結果、得られた1チャンネル2次元画像を着色して保存します。そのあ後に、混合行列を作成します。overfittingしたモデルでテストすることを避けるために、デフォルトでは20epoch時に保存されたモデルを用いてテストを行います。
import cv2
import os
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
from chainer import serializers, Variable
from chainer.cuda import to_cpu
from chainer import functions as F
import network
import config
import normalize
import confusion_matrix as cm
test_img_path = config.test_img_path
test_gt_path = config.test_gt_path
save_model_path = config.save_model_path
save_predicted_path = config.save_predicted_path
img_size = config.img_size
n_class = config.n_class
max_epoch = config.max_epoch
img_normalization = config.img_normalization
palette = [
[128,128,128],
[128,0,0],
[192,192,128],
[128,64,128],
[255,69,0],
[60,40,222],
[128,128,0],
[192,128,128],
[64,64,128],
[64,0,128],
[64,64,0],
[0,128,192],
[0,0,0]]
def draw_png(img):
seg_img = np.zeros((img_size[0], img_size[1], 3))
for i in range(img_size[0]):
for j in range(img_size[1]):
color_number = img[i,j]
seg_img[i,j,0] = palette[color_number][0]
seg_img[i,j,1] = palette[color_number][1]
seg_img[i,j,2] = palette[color_number][2]
seg_img = Image.fromarray(np.uint8(seg_img))
return seg_img
#When you use cv2, RGB will be BGR. TAKE CARE IT.
def main():
model = network.SegNet()
model.to_gpu(0)
serializers.load_hdf5(os.path.join(save_model_path, "SegNet_{}.h5".format(20)), model)
if not os.path.exists(save_predicted_path):
os.makedirs(save_predicted_path)
print("Made save folder")
test_names = os.listdir(test_img_path)
test_names.sort()
num_imgs = len(test_names)
imgs_eval = np.empty((num_imgs, img_size[0], img_size[1]))
for i in range(num_imgs):
img = cv2.imread(os.path.join(test_img_path, test_names[i]))
img = img.transpose(2,0,1)
img = img.reshape((1, 3, img_size[0], img_size[1]))
img = img.astype("float32")
if img_normalization:
img = normalize.normalize(img)
img = Variable(img)
img.to_gpu(0)
seg_img = model(img)
seg_img.to_cpu()
seg_img = seg_img.reshape((n_class, img_size[0], img_size[1]))
seg_img = F.argmax(seg_img, axis=0).array
colored_seg_img = draw_png(seg_img)
colored_seg_img.save(os.path.join(save_predicted_path, test_names[i]))
print("{} is saved".format(test_names[i]))
imgs_eval[i] = seg_img
confusion_matrix, acc = cm.make_confusion_matrix(imgs_eval)
cm.show_confusion_matrix(confusion_matrix, acc)
if __name__ == '__main__':
main()
評価
評価用に混合行列をつくります。この辺は好みですが、sklearnを使ってもよいと思います。私はフルスクラッチしました。
import cv2
import os
import network
import config
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
from chainer import serializers, Variable
from chainer.cuda import to_cpu
from chainer import functions as F
test_gt_path = config.test_gt_path
img_size = config.img_size
n_class = config.n_class
def make_confusion_matrix(pre_imgs):
pre_imgs = pre_imgs.astype("int32")
gt_names = os.listdir(test_gt_path)
gt_names.sort()
num_gts = len(gt_names)
gt_imgs = np.empty((num_gts, img_size[0], img_size[1]), dtype="int32")
for i in range(num_gts):
gt_img = cv2.imread(os.path.join(test_gt_path, gt_names[i]))
gt_img = gt_img[:, :, 0]
gt_imgs[i] = gt_img
confusion_matrix = np.zeros((n_class, n_class), dtype="float32")
print("making confusion matrix...")
for i in range(len(pre_imgs)):
for j in range(img_size[0]):
for k in range(img_size[1]):
confusion_matrix[gt_imgs[i,j,k], pre_imgs[i,j,k]] += 1
acc = np.trace(confusion_matrix)/confusion_matrix.sum()
acc = round(acc, 3)
for i in range(n_class):
if confusion_matrix[i].sum() != 0:
confusion_matrix[i] = confusion_matrix[i] / confusion_matrix[i].sum()
return confusion_matrix, acc
def show_confusion_matrix(confusion_matrix, acc):
fig, ax = plt.subplots(figsize=(11, 8))
heatmap = ax.pcolor(confusion_matrix, cmap=plt.cm.Blues)
labels = ["Sky", "Building", "Pole", "Road_marking", "Road", "Pavement", "Tree", "SignSymbol", "Fence", "Car", "Pedestrian", "Bicyclist"]
ax.set_xticks(np.arange(confusion_matrix.shape[0]) + 0.5, minor=False)
ax.set_yticks(np.arange(confusion_matrix.shape[1]) + 0.5, minor=False)
ax.invert_yaxis()
ax.xaxis.tick_top()
ax.set_xticklabels(labels, minor=False)
ax.set_yticklabels(labels, minor=False)
plt.title("Confusion Matrix acc={}".format(acc))
plt.savefig("confusion_matrix.png")
print("saved confusion matrix")
実行
トレーニングを開始するためには、config.pyのbatchsizeなどを設定した後に
python3 train.py
としてください。すると、下の画像のようにepoch数, train loss, valid loss, 経過時間が順にターミナル上に出力されていきます。
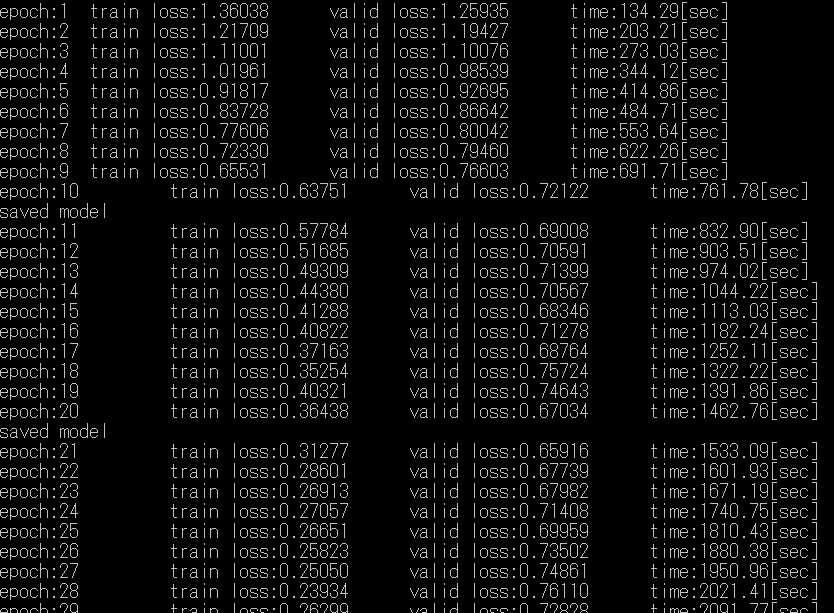
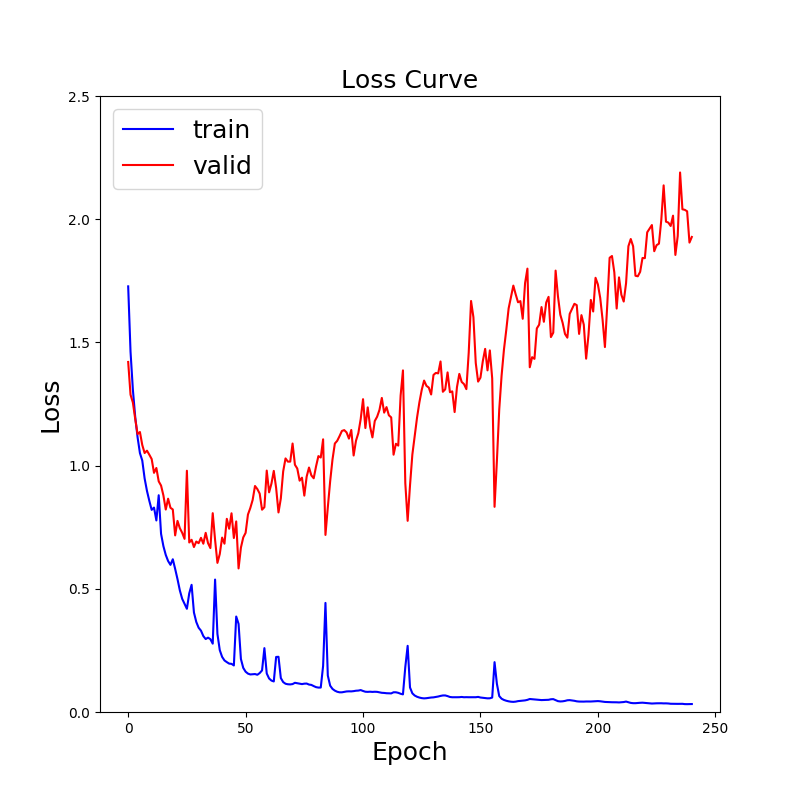
10epoch毎にloss_curve.pngが更新されていきます。30epochで既に過学習が起きていることが分かります。@uni-3さんの記事にある結果よりも過学習が遅く始まるのは、dropoutの効果と思われます。
テストを行うためには
python3 test.py
を実行します。dataset/test内の画像を1枚ずつ訓練済みモデルに渡して、出てきた2次元配列を着色したものをpredicted_imgsに保存します。その後、混合行列を作ります。
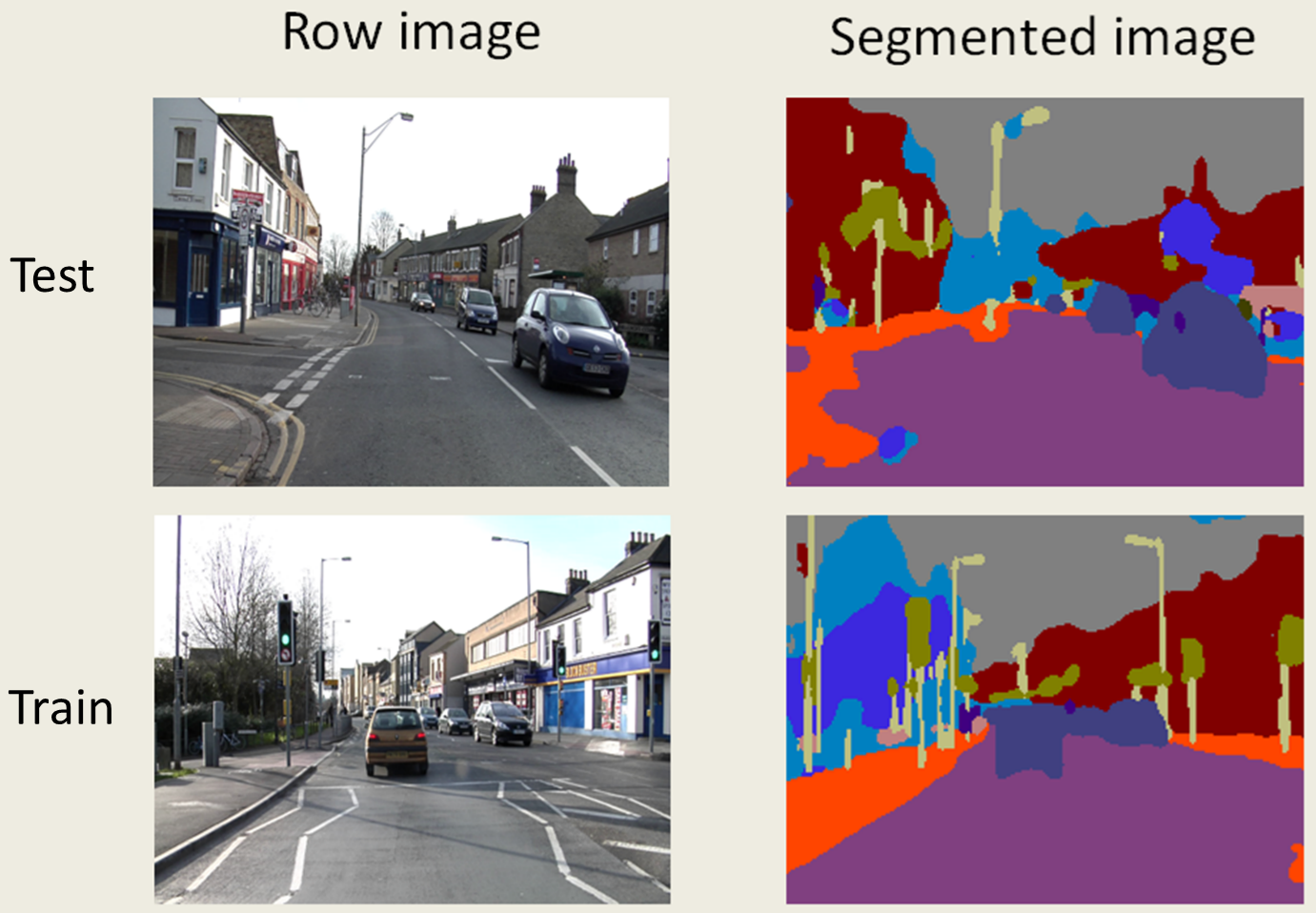
画像を見てわかるように非常に汎化性能は低いです。もっと沢山訓練データが必要なようです。
最後に
SegNetを実装してみましたが、見直してみるといろいろと反省する点がでてきました。
・classが使いこなせてない。loaderとか普通にクラスにするべきでは?
・みんなが嫌いなglobal変数を使いまくってる。
・PILとcv2が混ざっていて気持ち悪い。
ところで、ここで使われているCamVidデータセットの詳細ってどこに書いてあるのでしょうか。クラス数とか、class_weightingとかは@uni-3さんの記事から持ってきたのですが、1次ソースが見当たらないです。誰か知っていたら教えてください。
追記 U-Netについて
SegNetのエンコード・デコード間にスキップ結合を含めたU-Netも実装してみました。Unetについての詳しい説明は@tktktks10を参照してください。ネットワークは原論文を参考にして以下のようにしました。
class UNet(Chain):
def __init__(self, n_class=n_class):
super().__init__()
with self.init_scope():
self.n_class = n_class
self.enco1_1 = L.Convolution2D(None, 64, ksize=3, stride=1, pad=1)
self.enco1_2 = L.Convolution2D(None, 64, ksize=3, stride=1, pad=1)
self.enco2_1 = L.Convolution2D(None, 128, ksize=3, stride=1, pad=1)
self.enco2_2 = L.Convolution2D(None, 128, ksize=3, stride=1, pad=1)
self.enco3_1 = L.Convolution2D(None, 256, ksize=3, stride=1, pad=1)
self.enco3_2 = L.Convolution2D(None, 256, ksize=3, stride=1, pad=1)
self.enco4_1 = L.Convolution2D(None, 512, ksize=3, stride=1, pad=1)
self.enco4_2 = L.Convolution2D(None, 512, ksize=3, stride=1, pad=1)
self.enco5_1 = L.Convolution2D(None,1012, ksize=3, stride=1, pad=1)
self.deco6_1 = L.Convolution2D(None,1012, ksize=3, stride=1, pad=1)
self.deco6_2 = L.Convolution2D(None, 512, ksize=3, stride=1, pad=1)
self.deco7_1 = L.Convolution2D(None, 512, ksize=3, stride=1, pad=1)
self.deco7_2 = L.Convolution2D(None, 256, ksize=3, stride=1, pad=1)
self.deco8_1 = L.Convolution2D(None, 256, ksize=3, stride=1, pad=1)
self.deco8_2 = L.Convolution2D(None, 128, ksize=3, stride=1, pad=1)
self.deco9_1 = L.Convolution2D(None, 128, ksize=3, stride=1, pad=1)
self.deco9_2 = L.Convolution2D(None, 64, ksize=3, stride=1, pad=1)
self.deco9_3 = L.Convolution2D(None, 64, ksize=3, stride=1, pad=1)
self.final_layer = L.Convolution2D(None, n_class, ksize=1)
self.bn1_1 = L.BatchNormalization( 64)
self.bn1_2 = L.BatchNormalization( 64)
self.bn2_1 = L.BatchNormalization( 128)
self.bn2_2 = L.BatchNormalization( 128)
self.bn3_1 = L.BatchNormalization( 256)
self.bn3_2 = L.BatchNormalization( 256)
self.bn4_1 = L.BatchNormalization( 512)
self.bn4_2 = L.BatchNormalization( 512)
self.bn5_1 = L.BatchNormalization(1012)
self.bn6_1 = L.BatchNormalization(1012)
self.bn6_2 = L.BatchNormalization( 512)
self.bn7_1 = L.BatchNormalization( 512)
self.bn7_2 = L.BatchNormalization( 256)
self.bn8_1 = L.BatchNormalization( 256)
self.bn8_2 = L.BatchNormalization( 128)
self.bn9_1 = L.BatchNormalization( 128)
self.bn9_2 = L.BatchNormalization( 64)
self.bn9_3 = L.BatchNormalization( 64)
def __call__(self, x): #x = (batchsize, 3, 360, 480)
if LRN:
x = F.local_response_normalization(x) #Needed for preventing from overfitting
h1_1 = F.relu(self.bn1_1(self.enco1_1(x)))
h1_2 = F.relu(self.bn1_2(self.enco1_2(h1_1)))
pool1 = F.max_pooling_2d(h1_2, 2, stride=2, return_indices=False) #(batchsize, 64, 180, 240)
h2_1 = F.relu(self.bn2_1(self.enco2_1(pool1)))
h2_2 = F.relu(self.bn2_2(self.enco2_2(h2_1)))
pool2 = F.max_pooling_2d(h2_2, 2, stride=2, return_indices=False) #(batchsize, 128, 90, 120)
h3_1 = F.relu(self.bn3_1(self.enco3_1(pool2)))
h3_2 = F.relu(self.bn3_2(self.enco3_2(h3_1)))
pool3 = F.max_pooling_2d(h3_2, 2, stride=2, return_indices=False) #(batchsize, 256, 45, 60)
h4_1 = F.relu(self.bn4_1(self.enco4_1(pool3)))
h4_2 = F.relu(self.bn4_2(self.enco4_2(h4_1)))
pool4 = F.max_pooling_2d(h4_2, 2, stride=2, return_indices=False) #(batchsize, 256, 23, 30)
h5_1 = F.relu(self.bn5_1(self.enco5_1(pool4)))
up5 = F.unpooling_2d(h5_1, ksize=2, stride=2, outsize=(pool3.shape[2], pool3.shape[3]))
h6_1 = F.relu(self.bn6_1(self.deco6_1(F.concat((up5, h4_2)))))
h6_2 = F.relu(self.bn6_2(self.deco6_2(h6_1)))
up6 = F.unpooling_2d(h6_2, ksize=2, stride=2, outsize=(pool2.shape[2], pool2.shape[3]))
h7_1 = F.relu(self.bn7_1(self.deco7_1(F.concat((up6, h3_2)))))
h7_2 = F.relu(self.bn7_2(self.deco7_2(h7_1)))
up7 = F.unpooling_2d(h7_2, ksize=2, stride=2, outsize=(pool1.shape[2], pool1.shape[3]))
h8_1 = F.relu(self.bn8_1(self.deco8_1(F.concat((up7, h2_2)))))
h8_2 = F.relu(self.bn8_2(self.deco8_2(h8_1)))
up8 = F.unpooling_2d(h8_2, ksize=2, stride=2, outsize=(x.shape[2], x.shape[3])) #x = (batchsize, 128, 360, 480)
h9_1 = F.relu(self.bn9_1(self.deco9_1(F.concat((up8, h1_2)))))
h9_2 = F.relu(self.bn9_2(self.deco9_2(h9_1)))
h9_3 = F.relu(self.bn9_3(self.deco9_3(h9_2)))
h = self.final_layer(h9_3)
return h
テスト結果のSegNetとU-Netとの比較は以下の通り。U-Netの方がSegNetよりも解像度の高い結果が得られている。

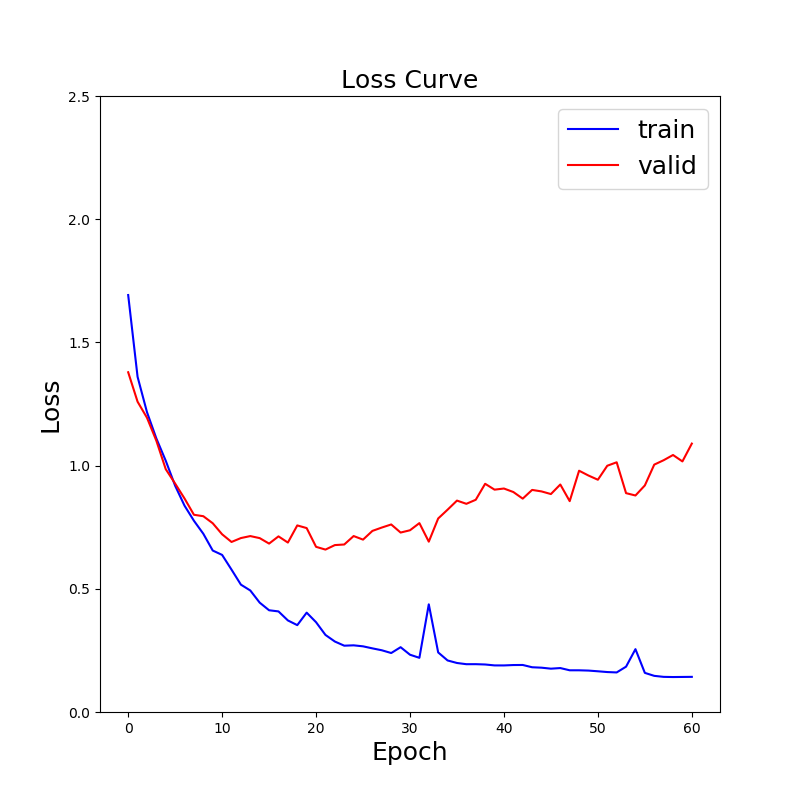
lossの変化は以下の通り。SegNetの場合に比べて過学習が起きるのが遅いのがわかる。