
(a) SegNet Basic output (b) Blended with input (c) Same input with SSD detection
概要
SegNetはケンブリッジ大学が提案した、ディープラーニングを用いるオープンソースの画像分割手法で、交通シーンにおいて画素単位で画像を分割することが可能です。SegNetのアーキテクチャにはEncoderネットワークとDecoderネットワークが構成されており、EncoderネットワークはVGG16モデルの一部を用いて、物体の特徴情報を抽出する。それに対してDecoderネットワークはこれまで得られた特徴情報を元に車や道路などの物体ごとにラベリングを行います。しかし、SegNetは画像単位で分割することを実現できているのですが、FPGAなどのモバイルデバイスで動かすにはやはり軽量化する必要があります。そこでSegNetのライトモデルを使用してFPGAで実装してみました。(本記事はこちらの記事を和訳したものです。)
アーキテクチャ解説
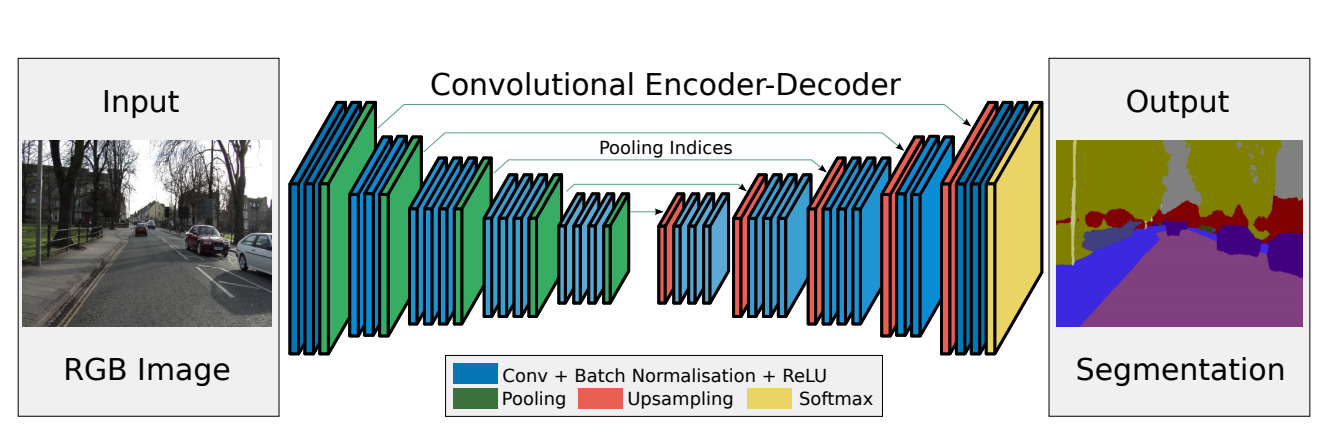
SegNet Architecture
SegNetネットワークは下図のようにEncoderネットワーク(左)とDecoderネットワーク(右)からなる対称性を用いた構造です。RGB画像が与えられると、画像に存在する車や道路などにラベリング付けを行い、番号の異なるラベルを違う色で表現するという仕組みです。SSDと比べると物体の領域が正確になっているほか、自動運転に望まれる道路のフリー領域や道路標識も同時に予測することができます。
Encoder
Encoderという名付けになっていますが、その構成を覗くと、ごく一般的なニューラルネットワークに過ぎない。畳み込み層、プーリング層、BatchNormalization層から構成されています。畳み込み層では画像の局所特徴を抽出し、プーリング層でダウンサンプリングをし、更にスケール不変なものを後ろの層に伝播していきます。BatchNormalization層は、訓練データの分布を正規化することで勾配消失などを防ぎ、学習を加速させます。
要するに、局所的な画素値から人や車、道路などのハイレベルの物体特徴を学習していくのがEncoderの役割です。DecoderはEncoderが求めた低解像度特徴マップから、個々の物体が対応している画素値にマッピング処理を行います。
Decoder
Encoderによって物体の種類と大まかな位置情報を持つ低解像度の特徴マップが得られたが、それを元の解像度マップに対応付けを行うのがDecoderです。具体的には低解像度マップをアップサンプリングして、畳み込み処理を行うことによって物体の形がよりきれいに補完されます。
視点を変えてEncoder+Decoderの仕組みを解説
ここで具体的な例説明してみます。例えばあるレシピ本があるとします。そのレシピ本はいくつかの文章に構成され、それぞれの文章は料理の作り方についてずらりと日本語で書かれています。ここでこの本に含まれる全ての文字をSegNetに入力し学習させることにします。学習させる時点ではまだSegNetはレシピ本の構造や内容などは全く理解していないのですが、学習していくのにつれて、Encoderが各章ではどういう料理を教えているのかをある程度理解できるようになり、文章のかたまりをより簡略化した料理手順のまとめ(つまり、特徴マップ)で表現しています。次に、サラダや魚料理、肉料理などが理解できたところで、Decoderはこれらの料理が対応した文章はどこからどこまでかというふうにマッピングを行います。そうすると、ユーザからみると、内容を読まずにどの文章がどの料理についてなのかというのがわかります。言い換えると、このレシピはどういう料理を教えているかということだけではなく、各料理がどの章で書かれているかというマッピング情報も入手できますので、全体像を捉えることができます。
Pooling, Upsampling & Pooling Indices
下図に示すように、SegNetでは2x2Max Poolingを用いて2x2の領域の中にある最大値のみ次に層に伝播させます。
2x2 Max Pooling
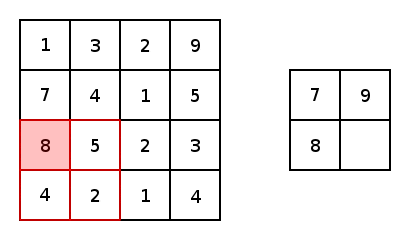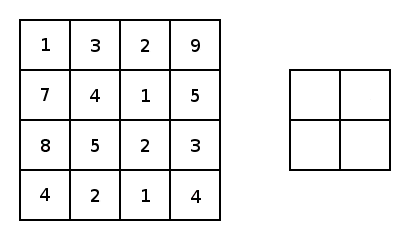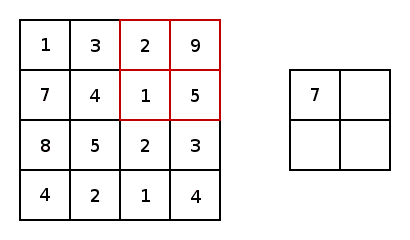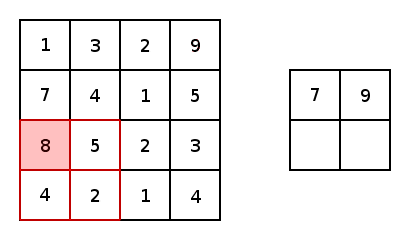
アップサンプリングとは、プーリング層で縮小した特徴マップを拡大することです。通常1x1の特徴領域が2x2となります。そして次は新しい2x2の領域の中に、空白を埋めていくのですが、一つは元の1x1特徴点で、他は空白のままになります。さて、1x1特徴点の場所ですが、どれを選べばいいでしょうか?ランダムに選ぶか、それとも固定の場所を選ぶかによって誤差が生じることがあります。しかも、この誤差は後ろの層にどんどん伝播していくので、層が深いほど誤差の影響範囲がさらに広がります。したがって、1x1特徴点の場所を正確に決めるのが大事です。
SegNetでどのようにやっているかというと、Pooling Indicesという手法でプーリングのインデックスを一時保存します。Encoderのプーリング層でダウンサンプリングしたあと、Max値が元の2x2の領域の中の場所を示すIndexを保存しておきます。このIndexのことがPooling Indicesです。対称性を用いたネットワーク構造だから、Decoderでアップサンプリングするとき、その層が対応するプーリングにおけるPooling Indicesを取り出し、1x1の特徴点は以下の図のように、Pooling Indicesの示した場所に置きます。
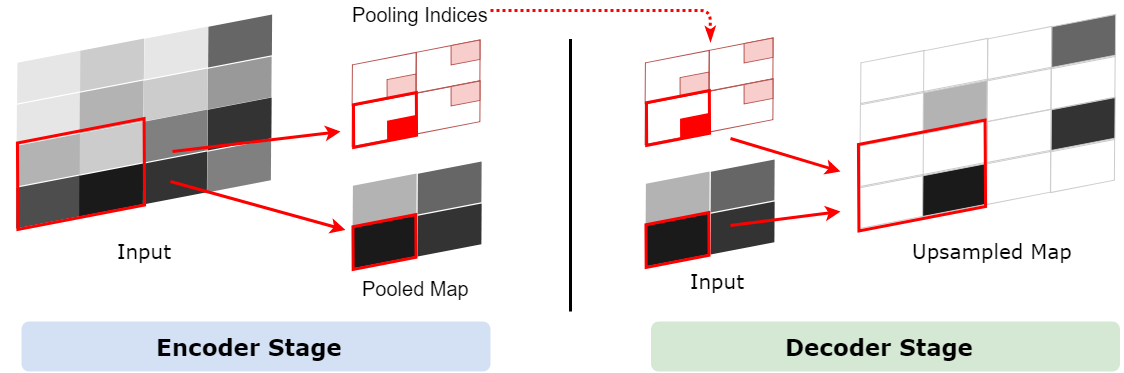
Convolution Layer in Encoder and Decoder
EncoderもDecoderも畳み込み層を利用し、処理自体も全く同じですが、結果的に異なる振る舞いをしているように見えます。Encoderでは、畳み込み層は画像における局所特徴を捉えてプーリング層に伝播し、プーリング層で情報を圧縮してスケール不変な特徴を更に次の層に伝播していきます。したがって、Convolution+Pooling=「画像から特徴を抽出すること」です。
一方、Decoderでは、アップサンプリングしてから畳み込み処理を行うことからみると、2x2の中に前の層からもらったのは1x1の特徴値しかなく、それ以外の3つの空白を補填し、全体を滑らかにするのがここでの畳み込みの仕事です。したがって、DecoderにおけるUpsampling+Convolution=「特徴マップに新しい情報を追加・補填すること」です。
要するに、畳み込み層は計算が全く同様だが、ダウンサンプリングの前で、又はアップサンプリングの後で畳み込みをかけると、異なる挙動に見えることになります。その挙動の違いによって、逆畳み込み(Deconvolution)または、転置畳み込み (Transposed Convolution) と呼ばれることがありますが、実際の計算は全く違いがありません。下記の動画を見るとわかりやすいと思います。
| Convolution | Deconvolution |
|---|---|
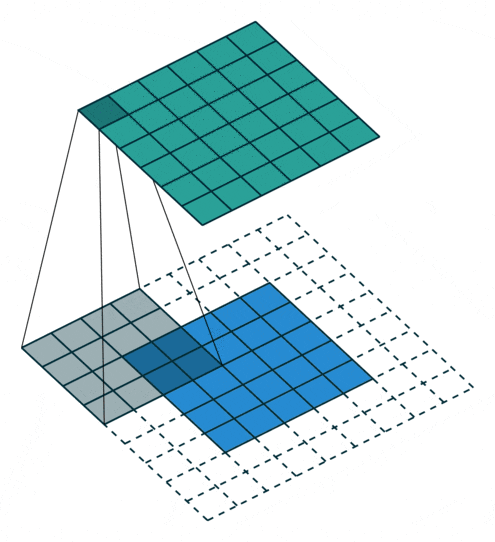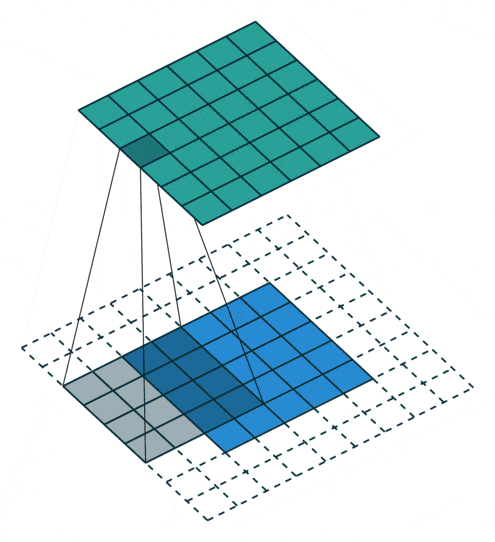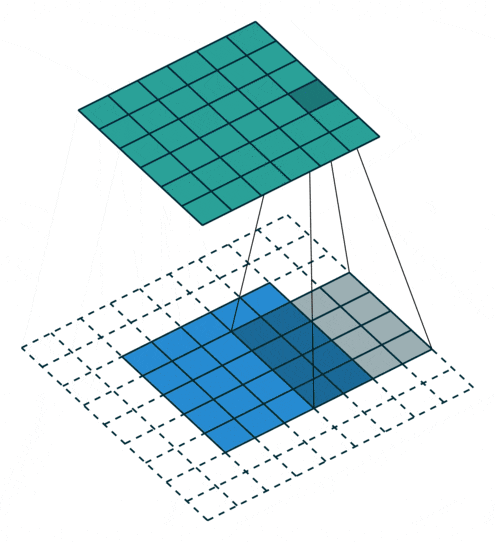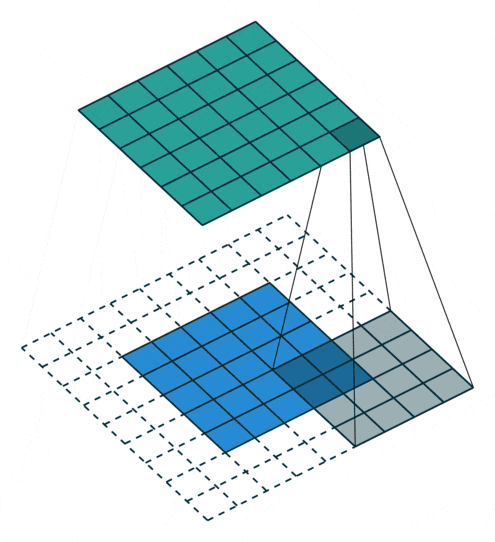 |
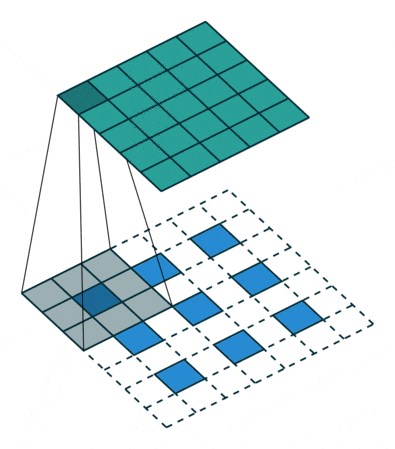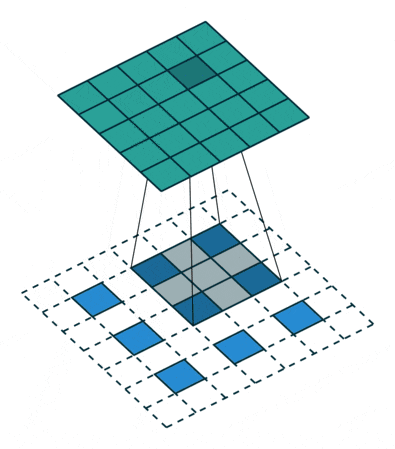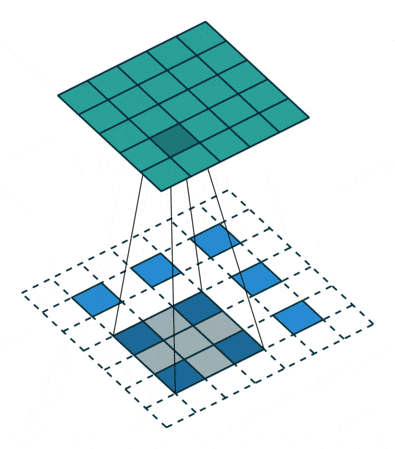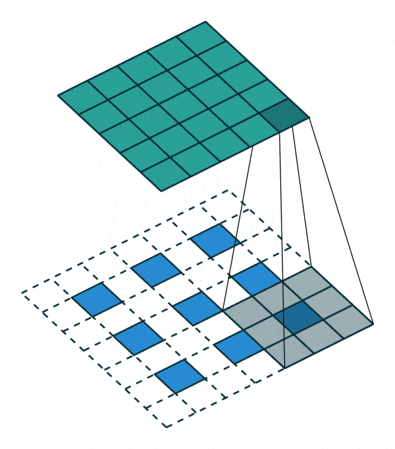 |
Our Implementation Model
SegNetは計算量が多くてFPGAで動作するのは難しいので、性能を上げるために、layer数を減らした軽量化モデルSegNet Basicを採用しました。SegNet Basicのアーキテクチャは下記に示します。
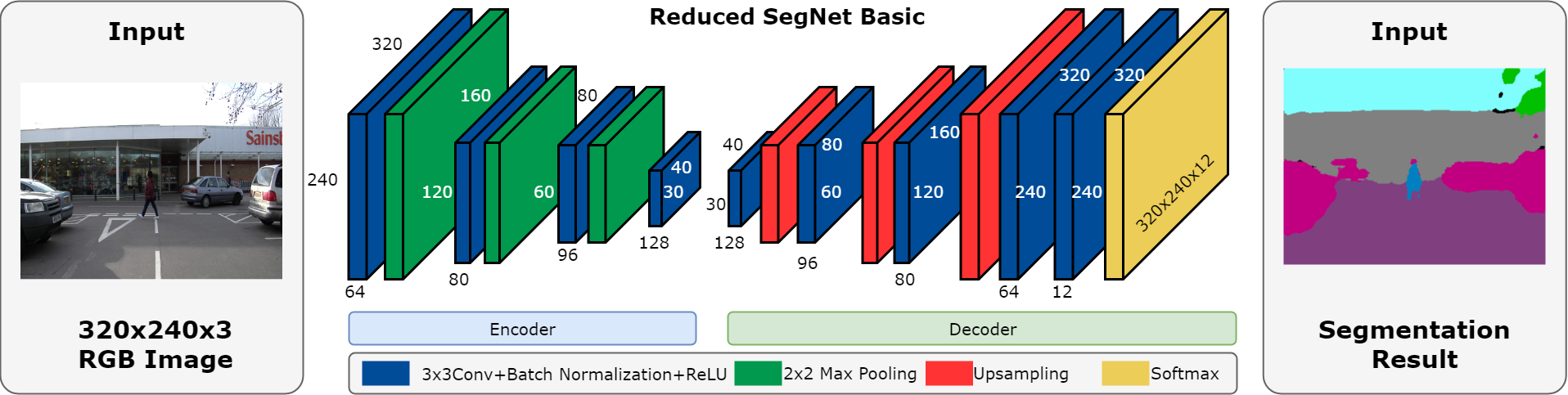
Network Architecture of Reduced SegNet Basic
Demo GIF
動画をみると、人、車、木、ビルなどはちゃんと分割されていることがわかります。
また、SegNetとの違いを示すために、DV700でSSD物体検出も同時に行って、その結果は下記にあります。結果からみると、DV700は単体ではもちろん、複数のネットワークも同時に構築することができ、複数のタスクを同時に処理することができています。複数のネットワークを同時に処理できることは実際の自動運転では大変多く求められています。

(a) SegNet Basic output (b) Blended with input (c) Same input with SSD detection
Accuracy: 85% @ original training dataset
Platform: DV700 FPGA
Processing Time:
SegNet Basic: 250ms/frame
SSD: 50ms/frame
※本記事で使用したSSDは自社データセットで学習したモデルであり、若干誤検出が見受けられています。