はじめに
最近ノイズ除去の方法として深層学習がよく使われています。
深層学習でノイズ除去する時にノイズ無しのいい画像を使って学習することが多いです。
この記事などで説明された通り
しかし、実際のところ綺麗な画像を一枚も持っていない場合も多いです。例えば夜に撮る写真や天文系の画像。天体観測では大気や周りの星の光の影響が受けてどうしてもノイズが混ざっています。
それでも、同じところを何枚も撮ると、全てはノイズがあったとしても時間によって変わっていくものなので、これらの写真をたくさん纏めて使えば、ほぼノイズ無しの写真が復元できるのです。
深層学習で、綺麗な画像を一枚も使わずにいい画像を復元できるのはnoise2noiseという手法です。
ノイズがある画像だけでも綺麗な画像で学習するのと同じくらい効果がいいようです。
詳しくはこちら元の論文の和訳 http://www.sanko-shoko.net/note.php?id=pn13
ここではpytorchで実装するコードを説明します。
データの準備
まずは使う画像データの準備です。
この前DCGANの実装を試したのと同じく、アニメキャラの画像を使います。
詳しくはその記事で https://qiita.com/phyblas/items/bcab394e1387f15f66ee
今回は256x256ピクセルの画像を使います。
一部の使われた画像

これらの画像にノイズを加えます。このコードで、綺麗な画像一枚毎に何枚ものノイズいっぱいの画像を作ります。
from matplotlib.image import imsave,imread
import numpy as np
import os,torch
from glob import glob
n = 100 # 作る数
a = 0.3 # ノイズの大きさ
hozon_folder ='noi_gazou' # ノイズを追加された画像を保存するフォルダ
gazou_folder = 'moto_gazou' # 元の画像のフォルダ
gpu = 1 # GPUを使うかどうか
if(not os.path.exists(hozon_folder)):
os.mkdir(hozon_folder)
for gazou_file in sorted(glob(gazou_folder+'/*')):
gazou_namae = os.path.basename(gazou_file).split('.')[0]
gazou = imread(gazou_file) # 画像を読み込み
if(gpu): # GPUがあればpytorchのテンソルを使う
gazou = torch.cuda.FloatTensor(gazou)+torch.randn((n,)+gazou.shape).cuda()*255*a
gazou = torch.clamp(gazou,0,255).type(torch.uint8).cpu().numpy()
else:
gazou = gazou+np.random.normal(0,a,(n,)+gazou.shape)*255
gazou = np.clip(gazou,0,255).astype(np.uint8)
if(not os.path.exists(os.path.join(hozon_folder,gazou_namae))):
os.mkdir(os.path.join(hozon_folder,gazou_namae))
for i,g in enumerate(gazou):
imsave((os.path.join(hozon_folder,gazou_namae,'%03d.jpg'%i)),g) # 画像を書き込み
print(gazou_namae)
たくさんの画像を同時に作るから莫大な行列の扱いになるため、GPUを使った方がずっと早いです。pytorchはニューラルネットワークの他にこういう使い方もとても役に立ちます。基本的にpytorchのテンソルはnumpyの行列と似ているので楽です。
ノイズを追加した後はこうなります。

今回は224枚の画像を使って、一枚ごとに100枚のノイズの画像を作って、その画像を訓練に使います。
つまり、全部の訓練データはノイズいっぱいの22400枚の画像。
元の画像は後で復元する画像と比べる時に使いますが、訓練に使うことはありません。実際の状況では元の画像なんて存在しないという設定だから。
noise2noiseの見所は元の綺麗な画像を学習に使わないというところです。
深層学習のモデル
深層学習に使うモデルは元の論文と同じ構造のunetにします。
| 名前 | 関数 | 出力チャネル数 | 出力ピクセル |
|---|---|---|---|
| INPUT | n | m | |
| ENC CONV 0 | 畳み込み 3×3, ReLU | 48 | m |
| ENC CONV 1 | 畳み込み 3×3, ReLU | 48 | m |
| POOL 1 | Maxpool 2×2 | 48 | m/2 |
| ENC CONV 2 | 畳み込み 3×3, ReLU | 48 | m/2 |
| POOL 2 | Maxpool 2×2 | 48 | m/4 |
| ENC CONV 3 | 畳み込み 3×3, ReLU | 48 | m/4 |
| POOL 3 | Maxpool 2×2 | 48 | m/8 |
| ENC CONV 4 | 畳み込み 3×3, ReLU | 48 | m/8 |
| POOL 4 | Maxpool 2×2 | 48 | m/16 |
| ENC CONV 5 | 畳み込み 3×3, ReLU | 48 | m/16 |
| POOL 5 | Maxpool 2×2 | 48 | m/32 |
| ENC CONV 6 | 畳み込み 3×3, ReLU | 48 | m/32 |
| UPSAMPLE 5 | アップサンプリング 2×2 | 48 | m/16 |
| CONCAT 5 | POOL 4と結合 | 96 | m/16 |
| DEC CONV 5A | 畳み込み 3×3, ReLU | 96 | m/16 |
| DEC CONV 5B | 畳み込み 3×3, ReLU | 96 | m/16 |
| UPSAMPLE 4 | アップサンプリング 2×2 | 96 | m/8 |
| CONCAT 4 | POOL 3と結合 | 144 | m/8 |
| DEC CONV 4A | 畳み込み 3×3, ReLU | 96 | m/8 |
| DEC CONV 4B | 畳み込み 3×3, ReLU | 96 | m/8 |
| UPSAMPLE3 | アップサンプリング 2×2 | 96 | m/4 |
| CONCAT 3 | POOL 2と結合 | 144 | m/4 |
| DEC CONV 3A | 畳み込み 3×3, ReLU | 96 | m/4 |
| DEC CONV 3B | 畳み込み 3×3, ReLU | 96 | m/4 |
| UPSAMPLE 2 | アップサンプリング 2×2 | 96 | m/2 |
| CONCAT 2 | POOL 1と結合 | 144 | m/2 |
| DEC CONV 2A | 畳み込み 3×3, ReLU | 96 | m/2 |
| DEC CONV 2B | 畳み込み 3×3, ReLU | 96 | m/2 |
| UPSAMPLE 1 | アップサンプリング 2×2 | 96 | m |
| CONCAT 1 | INPUTと結合 | 96+n | m |
| DEV CONV 1A | 畳み込み 3×3, ReLU | 64 | m |
| DEV CONV 1B | 畳み込み 3×3, ReLU | 32 | m |
| DEV CONV 1C | 畳み込み 3×3, LeakyReLU | n | m |
nは画像のチャネル数で、mは元のピクセルの数
ここでの実験では$n=3$(RGB)で、$m=(256,256)$。実際にピクセルの数は32に割り切れるなら何でもいいし、広さと高さは同じである必要もないです。
ただし、アップサンプリングの部分は逆畳み込みにします。
他の人の実装を見た限り、普通にtorch.nn.Upsampleよりも、torch.nn.ConvTranspose2dは使われます。
実際に普通のアップサンプリング層も使ってみたけど、結果は逆畳み込み層に比べると劣っているので、やはり逆畳み込みの方が良いです。
活性化関数は最後の畳み込み層だけはLeakyReLUを使うが、それ以外全ての畳み込み層は普通のReLUを使います。
ドロップアウトやバッチ正規化は使っていません。
import torch
nn = torch.nn
class Unet(nn.Module):
def __init__(self,cn=3):
super(Unet,self).__init__()
# copu = convolution + pooling
self.copu1 = nn.Sequential(
nn.Conv2d(cn,48,3,stride=1,padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(48,48,3,padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(2)
)
for i in range(2,6): #copu2, copu3, copu4, copu5
self.add_module('copu%d'%i,
nn.Sequential(
nn.Conv2d(48,48,3,stride=1,padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(2)
)
)
# coasa = convolution + upsample
self.coasa1 = nn.Sequential(
nn.Conv2d(48,48,3,stride=1,padding=1),
nn.ReLU(inplace=True),
nn.ConvTranspose2d(48,48,3,stride=2,padding=1,output_padding=1)
)
self.coasa2 = nn.Sequential(
nn.Conv2d(96,96,3,stride=1,padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(96,96,3,stride=1,padding=1),
nn.ReLU(inplace=True),
nn.ConvTranspose2d(96,96,3,stride=2,padding=1,output_padding=1)
)
for i in range(3,6): #coasa3, coasa4, coasa5
self.add_module('coasa%d'%i,
nn.Sequential(
nn.Conv2d(144,96,3,stride=1,padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(96,96,3,stride=1,padding=1),
nn.ReLU(inplace=True),
nn.ConvTranspose2d(96,96,3,stride=2,padding=1,output_padding=1)
)
)
# coli = convolution + leakyrelu
self.coli = nn.Sequential(
nn.Conv2d(96+cn,64,3,stride=1,padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(64,32,3,stride=1,padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(32,cn,3,stride=1,padding=1),
nn.LeakyReLU(0.1)
)
# 重みの初期値
for l in self.modules():
if(type(l) in (nn.ConvTranspose2d,nn.Conv2d)):
nn.init.kaiming_normal_(l.weight.data)
l.bias.data.zero_()
def forward(self,x):
x1 = self.copu1(x)
x2 = self.copu2(x1)
x3 = self.copu3(x2)
x4 = self.copu4(x3)
x5 = self.copu5(x4)
z = self.coasa1(x5)
z = self.coasa2(torch.cat((z,x4),1))
z = self.coasa3(torch.cat((z,x3),1))
z = self.coasa4(torch.cat((z,x2),1))
z = self.coasa5(torch.cat((z,x1),1))
return self.coli(torch.cat((z,x),1))
構造はかなり深いので、GPUを使わなければ何日もかかります。使うGPUのRAMも十分に大きくなければバッチサイズを小さくしないと使えそうにないです。
学習
次はnoise2noiseの学習するクラスを定義して、データを与えて学習させます。
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.image import imread,imsave
import torch,os,time
from glob import glob
from unet import Unet # unet.pyからインポート
nn = torch.nn
mse = nn.MSELoss() # 損失関数
# noise2noiseのクラス
class Noi2noi:
def __init__(self,hozon_folder,gakushuuritsu=1e-3,gpu=1,kataru=1):
'''
hozon_folder: パラメータや生成された画像を保存するフォルダ
gakushuuritsu: 学習率
gpu: GPUを使うか
kataru: 学習している時、検証の結果をprintするか
'''
self.gakushuuritsu = gakushuuritsu
self.kataru = kataru
self.net = Unet(cn=3) # ネット
self.opt = torch.optim.Adam(self.net.parameters(),lr=gakushuuritsu) # オプティマイザ
if(gpu):
self.dev = torch.device('cuda')
self.net.cuda()
else:
self.dev = torch.device('cpu')
self.hozon_folder = hozon_folder
if(not os.path.exists(hozon_folder)):
os.mkdir(hozon_folder) # 保存するフォルダがまだ存在していなければ作る
netparam_file = os.path.join(hozon_folder,'netparam.pkl')
# すでに学習して重みとか保存した場合、読み込んで使う
if(os.path.exists(netparam_file)):
s = torch.load(netparam_file)
self.net.load_state_dict(s['w']) # ネットの重み
self.opt.load_state_dict(s['o']) # オプティマイザの状態
self.mounankai = s['n'] # もう何回学習した
self.sonshitsu = s['l'] # 毎回の損失を納めたリスト
else:
self.mounankai = 0
self.sonshitsu = [],[]
def gakushuu(self,dalo,n_kurikaeshi,kenshou,kenshou_hindo=1,matsu=10,yarinaosu=0):
'''
dalo: データローダ
n_kurikaeshi: 何回繰り返して学習するか
kenshou: 検証のためのオブジェクト
kenshou_hindo: 一回学習に何回検証を行うか
matsu: 何回が損失が下らなければ学習は終了
yarinaosu: 以前学習した重みを使わずに学習を最初からやり直すか
'''
# やり直す場合
if(yarinaosu):
self.net = Unet(cn=3).to(self.dev)
self.opt = torch.optim.Adam(self.net.parameters(),lr=self.gakushuuritsu)
self.mounankai = 0
self.sonshitsu = [],[]
t0 = time.time()
saitei_sonshitsu = np.inf # 一番低い損失
susundenai = 0
for kaime in range(self.mounankai,self.mounankai+n_kurikaeshi):
for i_batch,(x,y) in enumerate(dalo):
z = self.net(x.to(self.dev)) # 画像を生成する
sonshitsu = mse(z,y.to(self.dev)) # 目標画像と比べて損失を計算する
self.opt.zero_grad() # 勾配リセット
sonshitsu.backward() # 誤差逆伝搬
self.opt.step() # 重み更新
# 検証
if((i_batch+1)%int(np.ceil(len(dalo)/kenshou_hindo))==0 or i_batch==len(dalo)-1):
sonshitsu = kenshou(self,kaime,i_batch)
if(sonshitsu<saitei_sonshitsu): # 損失が前にり低くなった場合
susundenai = 0
saitei_sonshitsu = sonshitsu
else: # 低くなってない場合
susundenai += 1
if(self.kataru):
print('もう%d回進んでない'%susundenai,end=' ')
if(self.kataru):
print('%.2f分過ぎた'%((time.time()-t0)/60))
# 重みなどを保存する
sd = dict(w=self.net.state_dict(),o=self.opt.state_dict(),n=kaime+1,l=self.sonshitsu)
torch.save(sd,os.path.join(self.hozon_folder,'netparam.pkl'))
if(susundenai>=matsu):
break # 何回も損失が下がっていない場合、学習終了
def __call__(self,x,n_batch=4):
x = torch.Tensor(x)
y = []
for i in range(0,len(x),n_batch):
y.append(self.net(x[i:i+n_batch].to(self.dev)).detach().cpu())
return torch.cat(y).numpy()
# 画像のデータローダ
class Gazoudata:
def __init__(self,folder,n_batch=4,n_tsukau=None):
'''
folder: 訓練データを納めたフォルダ
n_batch: バッチサイズ
n_tsukau: 一枚の元の画像毎に、ノイズ画像を最大何枚使うか
'''
self.n_batch = n_batch
self.file = []
for fo in sorted(glob(folder+'/*')):
ff = glob(fo+'/*')
if(n_tsukau):
ff = ff[:n_tsukau]
self.file.append(ff)
# for が始めた時にランダムで画像を2枚ずつ組み合わせて並べる
def __iter__(self):
self.item = []
for fo in self.file:
i_rand = np.random.permutation(len(fo))
for i in range(0,len(fo),2):
self.item.append((fo[i_rand[i]],fo[i_rand[i+1]]))
self.i_iter = 0
self.i_rand = np.random.permutation(len(self.item))
self.len = int(np.ceil(len(self.item)/self.n_batch))
return self
# 毎回のバッチサイズにバッチサイズと同じ数の画像を渡す
def __next__(self):
if(self.i_iter>=len(self.item)):
raise StopIteration
x = [] # 入力の画像
y = [] # 目標の画像
for i in self.i_rand[self.i_iter:self.i_iter+self.n_batch]:
x.append(imread(self.item[i][0]))
y.append(imread(self.item[i][1]))
self.i_iter += self.n_batch
x = torch.Tensor(np.stack(x).transpose(0,3,1,2)/255.)
y = torch.Tensor(np.stack(y).transpose(0,3,1,2)/255.)
return x,y
def __len__(self):
return self.len
# 検証を行うオブジェクト
class Kenshou:
def __init__(self,kunren_folder,kenshou_folder,n_kenshou,n_batch=8,gazou_kaku=1,n_kaku=5,graph_kaku=1):
'''
kunren_folder: 訓練データを納めたフォルダ
kenshou_folder: 検証データを納めたフォルダ
n_kenshou: 何枚検証に使うか
n_batch: 検証の時のバッチサイズ
gazou_kaku: 検証に使われた画像を書くか
n_kaku: 何枚書くか
graph_kaku: グラフを書くか
'''
gg = sorted(glob(kunren_folder+'/*/000.jpg'))[:n_kenshou]
self.x_kunren = torch.Tensor(np.stack([imread(g) for g in gg]).transpose(0,3,1,2)/255.)
gg = sorted(glob(kunren_folder+'/*/001.jpg'))[:n_kenshou]
self.y_kunren = torch.Tensor(np.stack([imread(g) for g in gg]).transpose(0,3,1,2)/255.)
gg = sorted(glob(kenshou_folder+'/*/000.jpg'))[:n_kenshou]
self.x_kenshou = torch.Tensor(np.stack([imread(g) for g in gg]).transpose(0,3,1,2)/255.)
gg = sorted(glob(kenshou_folder+'/*/001.jpg'))[:n_kenshou]
self.y_kenshou = torch.Tensor(np.stack([imread(g) for g in gg]).transpose(0,3,1,2)/255.)
self.n_kenshou = n_kenshou
self.n_batch = n_batch
self.gazou_kaku = gazou_kaku
self.n_kaku = n_kaku
self.graph_kaku = graph_kaku
def __call__(self,model,kaime,i_batch):
# 訓練データと検証データに対する損失を計算して格納する
z_kunren = torch.cat([model.net(self.x_kunren[i:i+self.n_batch].to(model.dev)).cpu() for i in range(0,self.n_kenshou,self.n_batch)])
sonshitsu_kunren = mse(z_kunren,self.y_kunren).item()
model.sonshitsu[0].append(sonshitsu_kunren)
z_kenshou = torch.cat([model.net(self.x_kenshou[i:i+self.n_batch].to(model.dev)).cpu() for i in range(0,self.n_kenshou,self.n_batch)])
sonshitsu_kenshou = mse(z_kenshou,self.y_kenshou).item()
model.sonshitsu[1].append(sonshitsu_kenshou)
# 生成された画像を保存する
if(self.gazou_kaku):
img_kunren = z_kunren.detach()[:self.n_kaku].cpu().numpy().transpose(0,2,3,1)
img_kenshou = z_kenshou.detach()[:self.n_kaku].cpu().numpy().transpose(0,2,3,1)
img = np.stack(list(img_kunren)+list(img_kenshou)).reshape(2,-1,256,256,3)
img = np.hstack(np.hstack(img))
img = (np.clip(img,0,1)*256).astype(np.uint8)
imsave(os.path.join(model.hozon_folder,'%03d_%04d.jpg'%(kaime+1,i_batch+1)),img)
# グラフを書く
if(self.graph_kaku):
plt.gca(ylabel='MSE')
plt.plot(model.sonshitsu[0])
plt.plot(model.sonshitsu[1])
plt.legend([u'訓練',u'検証'],prop={'family':'TakaoPGothic','size':17})
mi = np.argmin(model.sonshitsu[1])
m = model.sonshitsu[1][mi]
arrowprops = {'arrowstyle':'->','color':'r'}
plt.annotate('%.5f'%m,[mi,m],[mi*0.9,m*1.01],arrowprops=arrowprops)
plt.tight_layout()
plt.savefig(os.path.join(model.hozon_folder,'graph.jpg'))
plt.close()
if(model.kataru):
print('%d回目の%d 損失=[%.8f,%.8f]'%(kaime+1,i_batch+1,sonshitsu_kunren,sonshitsu_kenshou))
return sonshitsu_kenshou
# ここで設定
kunren_folder = 'noi_gazou_kunren' # 訓練のノイズ画像を納めた場所
kenshou_folder = 'noi_gazou_kenshou' # 検証のノイズ画像を納めた場所
hozon_folder = 'noi2noi' # 結果を保存する場所
n_batch = 4 # バッチサイズ
n_tsukau = 100 # 訓練の画像毎に最大何枚ノイズ画像を使うか
n_kenshou = 20 # 検証の画像毎に最大何枚ノイズ画像を使うか
n_batch_kenshou = 8 # 検証する時のバッチサイズ
gazou_kaku = 1 # 検証の時に画像を書くか
n_kaku = 5 # 検証の時に何枚画像を書くか
graph_kaku = 1 # 検証のグラフを書くか
n_kurikaeshi = 100 # 損失が結束しない場合最大何回まで続くか
kenshou_hindo = 6 # 毎回の訓練に何回検証をするか
matsu = 10 # 何回損失が下がらないと学習が終わるか
yarinaosu = 0 # 最初から学習をやり直すか
gakushuuritsu = 0.001 # 学習率
gpu = 1 # GPUを使うか
# 実行
n2n = Noi2noi(hozon_folder,gakushuuritsu,gpu) # noise2noiseモデル
dalo = Gazoudata(kunren_folder,n_batch,n_tsukau) # データローダ
kenshou = Kenshou(kunren_folder,kenshou_folder,n_kenshou,n_batch_kenshou,gazou_kaku,n_kaku,graph_kaku) # 検証オブジェクト
n2n.gakushuu(dalo,n_kurikaeshi,kenshou,kenshou_hindo,matsu,yarinaosu) # 学習開始
ミニバッチを実装するにはそもそもpytorchにはtorch.utils.data.DataLoaderというデータローダがありますが、それに合わせるデータセットのクラスを書くことはややこしい気がするので、
寧ろ自分でデータローダを作った方がわかりやすいと思って、簡単なイテレータのクラスを定義しました。
検証の部分もクラスを定義して使います。検証の際に各段階の損失が計算され、学習の終わる条件にされます。それと、進度を見るために、一部の生成された画像を出力します。
検証データに対する損失がもう10回ほど下がってなければ学習が終わり。
データセットを全部使われると一回となります。普段なら一回が終わる時に検証しますが、今回ではその間に何回も検証できるように設定されています。検証する頻度はkenshou_hindoで設定できます。訓練データが多いと一回に時間がかかり過ぎるからです。
毎回終わった後、重みが保存されていつでも又続けられることにしています。
訓練のバッチサイズは元の論文と同じく4を使います。
検証のバッチサイズは結果に影響がないが、GPUのRAMに制限があるので、大きいのは使えません。
結果
出力の画像は、上は訓練に使われたもので、下は訓練に使われてない検証用の画像。
1/6回

1/2回

1回

8回

学習は8回のところで終わり。
元の綺麗な画像にまでは戻れないが、それでもそこまで復元できました。訓練データに含まれていない画像(下の方)でもよく復元されています。
訓練の画像と検証の画像の結果の違いは、画像を見るだけでわかりにくいかもしれませんが、損失(MSE)のグラフを見ると訓練の画像の方が損失が低いとわかります。
訓練データと検証データに対する損失の変化を示すグラフ
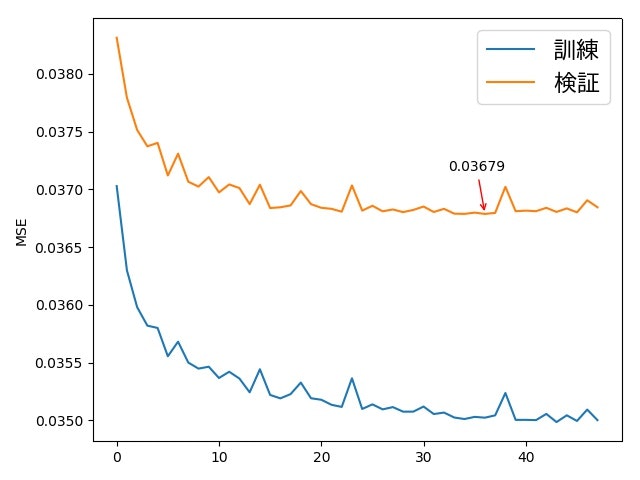
サンプルの数に関する検討
機械学習にとってたくさんの学習データが必要です。
サンプルがどれくらいあれば十分かをわかるために実験を行いました。
今回の実験でたった一枚の画像をテストデータにしました。
これは元の画像

そしてノイズを加えた後。

テストの画像が訓練データに含んだ場合と、含んでない場合を考えます。それぞれ画像一枚毎にノイズ画像を10枚と100枚使う場合を考えます。
それぞれ画像の数を変えながら学習させて、テストデータに対する損失(MSE)を計算して比べます。
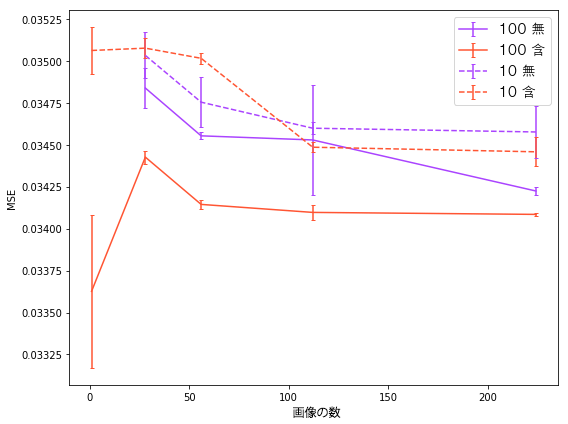
試した画像の数は1, 28, 56, 112, 224。赤線は訓練に含んだ場合で、紫線は含んでない場合。赤線の『1』はその画像しか使わないという意味です。
グラフ上の値は3回試した値の平均値で、エラーバーの幅はその標準誤差。
結果から見れば……
ノイズサンプルが十分にある場合、その画像だけで学習する方がいい。他の画像と一緒に訓練するとモデルは一般化するので、特定の画像にはとってよくない効果になるかもしれません。
その画像のノイズサンプルが少ない場合、その画像で訓練するよりも他の画像と一緒に訓練する方が結果がいい。
ノイズサンプルが少ないと、訓練データにその画像が含んだかどうかは関係なくなるようです。
平均値や中央値との比較
そもそもノイズを除去するには深層学習を使わなくても簡単な方法があります。たくさんの画像の平均値や中央値を使えば簡単に綺麗な画像が復元できます。
ここで結果を比べてみます
- 平均値
- 中央値
- この画像だけを訓練に使ってnoise2noiseで
- この画像を含む224枚の画像を訓練に使ってnoise2noise

比べてみれば、サンプルが1000枚くらい多いと平均値や中央値だけでもnoise2noiseと結果はあまり変わらないようです。そもそもあんなにたくさんサンプルがあったら、深層学習などの複雑な方法が必要なくただの統計だけで十分かもしれません。
それに対しサンプルが少ないと平均値と中央値を使ったらまだノイズがいっぱい残る。noise2noiseの方がノイズ減るがぼやっと見えます。
224枚の画像を訓練に使う場合はノイズサンプルが10枚しかなくても、それなりに随分うまく復元できるようです。つまり、復元したい画像がノイズサンプルが少ない場合、他の画像と一緒に学習すると有利になるということです。
終わりに
以上noise2noiseの実装を紹介しました。
上述の比較と結果はただ簡単な実験でした。まだ改善できる余地がいっぱいあると思います。例えば、ハイパーパラメータの調整とか、損失関数を変えることとか、モデルの構造とか、ノイズの種類や大きさとか、試していないことがいっぱいあります。サンプルももっと増やすほど結果は良くなるはずですが、時間はさらにかかります。色々変えると結果は違うかもしれません。もっと研究していく必要があります。
参考
以上のコードは前から色んな他の人の書いてあるコードを参考にして書いたものです。