DCGANのことは以前から聞いたことがあって興味がありました。最近pytorchを勉強し始めたので、練習としてDCGANを書いてみたいと思います。
DCGANでアニメキャラの顔を生成した例はすでにたくさんあったのですが、pytorchで書いた例は見つからなかったので、自分で書いて見ることにしました。
まずは結果の例です


基本的に以前から書いたmattyaさんやrezoolabさんなどのかたのコードを参考として自分なりにpytorchで書いてみたものです。
参考に使ったコード
https://qiita.com/rezoolab/items/5cc96b6d31153e0c86bc
https://qiita.com/mattya/items/e5bfe5e04b9d2f0bbd47
https://qiita.com/triwave33/items/35b4adc9f5b41c5e8141
https://github.com/carpedm20/DCGAN-tensorflow
https://github.com/chainer/chainer/tree/master/examples/dcgan
https://github.com/pytorch/examples/tree/master/dcgan
理論のことは上述のリンクで詳しい説明があるので、ここではpytorchでの書き方と、結果の可視化について書きます。
実装の概念
- 画像のピクセルは64、80、96どっちでも使える
- CPUでもGPUでも実行できる
- 毎回の訓練の後、サンプル結果を出力する
- 後で訓練を続けられるように、常にパラメータを保存する
- optimizerのパラメータも一緒に保存する
最初は16で割り切れるピクセルの数だったらどんなに大きい画像でもうまくいくかと思って112pxで試してみたら、何の絵も生成できなくて大失敗でした。結局64pxと80pxと96pxは一番みたいです。ただし96pxは失敗しやすいですし、結果も80pxと比べたら劣るようです。
ジェネレーターとディスクリミネータのモデル
ジェネレーターとディスクリミネータはこれらの層から構成されています。
- Conv 畳み込み層
- ConvT 逆畳み込み層
- Lin 全結合層
- BatchNorm バッチ正規化層
- ReLU
- LReLU
- Tanh
- Sigmoid
上から下へこのように並んでいます。
ジェネレーター

ディスクリミネータ

ConvとConvTの後ろの数字は:入力サイズ,出力サイズ,フィルターサイズ,ストライド,パディング
LINの後ろの数字は:入力サイズ,出力サイズ
BatchNormの後ろの数字は:入力と出力のサイズ
これは80pxサイズの画像を使う場合のモデルです。64と96pxを使う場合も同じ構造ですが、数字は微妙に違います。
使用した模範の画像
データはhttps://konachan.net と https://safebooru.org の画像から取得して、lbpcascade-animeface(https://github.com/nagadomi/lbpcascade_animeface )を使ってcv2で顔検出。
実装
# -*- coding: UTF-8 -*-
import numpy as np
from skimage.io import imsave,imread
import torch
import time,sys,os,re
from glob import glob
from random import shuffle
nn = torch.nn
relu = nn.ReLU(True)
lrelu = nn.LeakyReLU(0.2,True)
sigmoid = nn.Sigmoid()
tanh = nn.Tanh()
entropy = nn.BCELoss() # 損失を計算する関数
# それぞれの層の定義
class Conv(nn.Conv2d):
def __init__(self,*arg,**kw):
if('bias' not in kw):
kw['bias'] = False # ここでバイアスは使用しない
super(Conv,self).__init__(*arg,**kw)
self.weight.data.normal_(0,0.02) # 初期値の設定
class ConvT(nn.ConvTranspose2d):
def __init__(self,*arg,**kw):
if('bias' not in kw):
kw['bias'] = False
super(ConvT,self).__init__(*arg,**kw)
self.weight.data.normal_(0,0.02)
class Lin(nn.Linear):
def __init__(self,*arg,**kw):
if('bias' not in kw):
kw['bias'] = False
super(Lin,self).__init__(*arg,**kw)
self.weight.data.normal_(0,0.02)
class BN(nn.BatchNorm2d):
def __init__(self,*arg,**kw):
super(BN,self).__init__(*arg,**kw)
self.weight.data.normal_(1,0.02)
self.bias.data.fill_(0)
# テンソルを変形するためのモジュール
class Henkei(nn.Module):
def __init__(self,*k):
super(Henkei,self).__init__()
self.k = k
def forward(self,x):
return x.view(x.size()[0],*self.k)
# ジェネレータの定義
class Genera(nn.Sequential):
def __init__(self,nz=100,c=3,d=64,p=4,kn=4,st=2,pd=1):
d = [d*2**i for i in range(4)]
super(Genera,self).__init__(
Henkei(nz,1,1),
ConvT(nz,d[3],p,1,0),
BN(d[3]),
relu,
ConvT(d[3],d[2],kn,st,pd),
BN(d[2]),
relu,
ConvT(d[2],d[1],kn,st,pd),
BN(d[1]),
relu,
ConvT(d[1],d[0],kn,st,pd),
BN(d[0]),
relu,
ConvT(d[0],c,kn,st,pd),
tanh)
# ディスクリミネータの定義
class Discrim(nn.Sequential):
def __init__(self,c=3,d=64,p=4,kn=4,st=2,pd=1):
d = [d*2**i for i in range(4)]
super(Discrim,self).__init__(
Conv(c,d[0],kn,st,pd),
lrelu,
Conv(d[0],d[1],kn,st,pd),
BN(d[1]),
lrelu,
Conv(d[1],d[2],kn,st,pd),
BN(d[2]),
lrelu,
Conv(d[2],d[3],kn,st,pd),
BN(d[3]),
lrelu,
Henkei(d[3]*p*p),
Lin(d[3]*p*p,1),
Henkei(),
nn.Sigmoid())
# DCGANの定義
class DCGAN:
def __init__(self,nz,kk,eta=0.002,gpu=0):
assert(kk%16==0)
super(DCGAN,self).__init__()
self.nz = nz # zの数
self.kk = kk # 画像のサイズ
self.g = Genera(nz,p=int(kk/16))
self.g.opt = torch.optim.Adam(self.g.parameters(),lr=eta,betas=(0.5,0.999))
self.d = Discrim(p=int(kk/16))
self.d.opt = torch.optim.Adam(self.d.parameters(),lr=eta,betas=(0.5,0.999))
if(gpu):
self.g.cuda()
self.d.cuda()
self.dev = torch.device('cuda')
else:
self.dev = torch.device('cpu')
# 学習
def gakushuu(self,X,kurikaeshi=200,n_batch=64):
if(not os.path.exists(outfolder)):
os.mkdir(outfolder)
param = sorted(glob(os.path.join(outfolder,'tomopara*.pkl')))
# 前に保存されたパラメータを探して、見つかったら読み出す
if(param):
param = param[-1]
state_dict = torch.load(param)
self.g.load_state_dict(state_dict[0])
self.d.load_state_dict(state_dict[1])
self.g.opt.load_state_dict(state_dict[2])
self.d.opt.load_state_dict(state_dict[3])
z0 = torch.load(os.path.join(outfolder,'z0.pkl'))
hajime = int(re.search(r'(\d+)\.pkl',param)[1])
else:
hajime = 0
z0 = (torch.rand(n_batch,self.nz)*2-1).to(self.dev)
torch.save(z0,os.path.join(outfolder,'z0.pkl'))
n = len(X)
t0 = time.time()
v0 = torch.zeros(n_batch).to(self.dev)
v1 = torch.ones(n_batch).to(self.dev)
for j in range(hajime,hajime+kurikaeshi):
sentaku = np.random.permutation(n) # ミニバッチのランダム選択
for i in range(0,n,n_batch):
X_mohan = X[sentaku[i:i+n_batch]]
X_mohan = [imread(img) for img in X_mohan] # 模範の画像を読み出す
X_mohan = np.stack(X_mohan)
X_mohan = X_mohan/127.5-1.
X_mohan = X_mohan.transpose(0,3,1,2)
X_mohan = torch.FloatTensor(X_mohan).to(self.dev) # テンソルに変換
nx = len(X_mohan)
z = (torch.rand(nx,self.nz)*2-1).to(self.dev)
X_seisei = self.g(z) # ジェネレーターで画像を生成する
hyouka_seisei = self.d(X_seisei) # ディスクリミネータで生成された画像を評価する
hyouka_mohan = self.d(X_mohan) # 模範の画像も評価する
# 損失を計算して逆伝播
self.d.opt.zero_grad()
loss_d_mohan = entropy(hyouka_mohan,v1[:nx])
loss_d_mohan.backward()
loss_d_seisei = entropy(hyouka_seisei,v0[:nx])
loss_d_seisei.backward(retain_graph=True) # 後でまた逆伝播を再利用するためにretain_graphは必須
self.d.opt.step()
self.g.opt.zero_grad()
loss_g = entropy(hyouka_seisei,v1[:nx])
loss_g.backward() # retain_graphをしておいていなかったらここでエラーが出る
self.g.opt.step()
# サンプル画像を生成して書き込む
if(i+n_batch>=n or i/n_batch%100==99):
gazou = np.hstack(np.hstack(self.g(z0).data.cpu().numpy().transpose(0,2,3,1).reshape(8,8,self.kk,self.kk,3)))/2.+0.5
if(i/n_batch%100==99):
namae = os.path.join(outfolder,'pts%03d_%06d.jpg'%(j,i+nx))
else:
namae = os.path.join(outfolder,'pts%03d.jpg'%(j+1))
imsave(namae,gazou)
print('%d/%d 第%d回 %.3f分過ぎた'%(i+nx,n,j+1,(time.time()-t0)/60)) # 毎回進度発表
state_dict = [self.g.state_dict(),self.d.state_dict(),self.g.opt.state_dict(),self.d.opt.state_dict()]
torch.save(state_dict,os.path.join(outfolder,'tomopara%03d.pkl'%(j+1))) # パラメータを保存
if(__name__=='__main__'):
nz = 100 # zの数
lr = 0.0002 # 学習率
n_batch = 64 # ミニバッチの数
kurikaeshi = 151 # 何回繰り返す
pixel = 80 # 画像の大きさ
gpu = 1 # GPUを使うかどうか
datafolder = 'imgdata' # 模範の画像のフォルダ
outfolder = 'dcganimg' # 生成の画像とパラメータを保存するフォルダ
X = glob(os.path.join(datafolder,'*.jpg'))
shuffle(X)
X = np.array(X)
dcgan = DCGAN(nz,pixel,lr,gpu)
dcgan.gakushuu(X,kurikaeshi,n_batch) # 学習開始
注意するところ
- 生成された画像のディスクリミネータによる評価は、ジェネレーターとディスクリミネータ両方の逆伝播に使われるため、先に行われる.backward()にretain_graph=Trueをつけないとエラーが出ます
- pytorchのtorch.nn.Sequentialを使うとkerasみたいにforwardを自分で書く必要なくモジュールを並べるだけで住むので便利だけど、畳み込み層から全結合層に向かう時などにテンソルを変形する必要があります。pytorchでは自動で変形されないし、変形するためのモジュールも準備されていないため、自分で書く必要があります。
- パラメータの初期値の設定は意外と必要みたいです。pytorchではデフォルトの初期値の設定はあまりDCGANに向いていないため、自分でConv2dやConvTranspose2dやBatchNorm2dのクラスを継承して初期値の設定を変更することにします。
- ジェネレーターの出力はtanhを使うので、-1〜1となりますが、画像に出力する場合は0〜1に変換する必要があります。
- ディスクリミネータに入力する時に模範の画像もジェネレーターによって生成された画像と同じく-1〜1に変換する必要があります
結果
64pxも80pxも96pxも試したが、ここでは80pxの結果を発表します
学習データによって結果は違いますが、まずはkonachanから全部検出できた顔の画像117870枚を使った結果はこうなります

あまりいい結果ではないようです。自動で顔を検出してできた画像は、関係のない画像が4%くらい混ざっているようです。この関係ない画像を自分で消そうとしましたが、数が多すぎて全部処理したら何日もかかると予想したら断念してそのまま学習に使いました。結果はあまりよくないのはダメなサンプルの存在のせいでもあるかもしれません。
それと、以下は一回目画像を全部使って学習したばかりの時の結果です。まだ未熟ではっきり絵が描けないのですが、こういうのも意外と美学的だと思います。

そのあと、safebooruの画像で試しました。safebooruの方が画像がずっとたくさんなので今回では青髪と赤髪だけを取り出して、全部19008枚です。
数が少ないが、ダメなサンプルが少ない。これはsafebooruのよくできたタグのおかげです。
これをそれぞれの段階で出力された画像はこの通りです。
1/3回

2/3回

1回

1+1/3回

1+2/3回

2回

3回

5回

7回

10回

20回

30回

50回

151回

最初は変化が速いが、しばらく学習したら変化は緩やかになってきた。学習すればするほどよくなるってわけではないみたい。むしろ学習しすぎるとバリエーションがなくなってゆくようです。だから151回の画像では何枚の顔は同じようになっちゃったのです。
学習していく段階を動画でも作ってみたのですが大きいのでpixivに置きました >> https://www.pixiv.net/member_illust.php?mode=medium&illust_id=67905951
訓練した後の利用
さて次は本番です。訓練の結果を利用して楽しめる時です。
訓練し終わったジェネレータを使って画像を作ってみます。
import numpy as np
from skimage.io import imsave
import torch
from tomodcgan import Genera # 上述のコードを保存したtomodcgan.pyからジェネレーターをインポート
# ジェネレーターを作ってパラメータをロードする
genera = Genera(nz=100,p=5,kn=4,st=2,pd=1).eval()
param = 'tomopara.pkl'
genera.load_state_dict(torch.load(param,lambda s,l:s)[0])
# ジェネレーターを使ってzから画像に変換する関数を定義する
def seisei(z):
z = torch.FloatTensor(z)
r = genera(z).data.numpy()
return r.transpose(0,2,3,1)*0.5+0.5
# zをランダムして画像を16枚生成して保存する
z = np.random.uniform(-1,1,[16,100])
gazou = seisei(z)
for i in range(16):
imsave('g%d.jpg'%(i+1),gazou[i])
こうやってzを入力すれば色んな顔が生成できます。
ここで注意すべきなのは、ジェネレーターでは.eval()をつけることです。これはバッチ正規化を無効にするためです。バッチ正規化は訓練の時に学習がよく進めるためのいい助けになりますが、テストや実際に使う時は無効にしないと結果は違います。そこでpytorchではただモデルに.eval()をつけることでモデルの中の全部のバッチ正規化やドロップアウトの効果はなくなります。とても使いやすいです。
そしと、torch.load(param,lambda s,l:s)の中のlambda s,l:sはGPUで学習してできたパラメータが使えるようにつけるおまじないみたいなものです。これをつけないとエラーが出ます。それはGPUで使うテンソルの変数タイプは違うからです。CPUで学習した場合はtorch.load(param)のままで問題ありません。
変わってゆく顔
どんどん変わってゆく画像をかなり忠実に作れるのはDCGANの長所の一つです。
こうやって始まりと終わりの画像を決めておいて、その間の画像も生成することができます。
w = np.linspace(0,1,15)[:,None]
rr = []
for i in range(50):
z = np.random.uniform(-1,1,[2,100])
z = z[0]*w+z[1]*(1-w)
r = seisei(z)
r = np.hstack(r)
rr.append(r)
rr = np.vstack(rr)
imsave('ganimg.jpg',rr)

そして、このようなgifも生成できます
import imageio
w = np.linspace(0,1,8,0)[:,None]
rrrr = []
zz = np.random.uniform(-1,1,[5,5,4,100])
for i in range(4):
rrr = []
for k in range(5):
rr = []
for j in range(5):
z = zz[k,j,i-1]*(1-w)+zz[k,j,i]*w
r = seisei(z)
rr.append(r)
rr = np.hstack(rr)
rrr.append(rr)
rrr = np.dstack(rrr)
rrrr.append(rrr)
rrrr = np.vstack(rrrr)
imageio.mimsave('ganimg.gif',rrrr,fps=5)

そしてできるだけいい画像を生成するために、pyqtを書いてこんなGUIまで作っておいたのです。
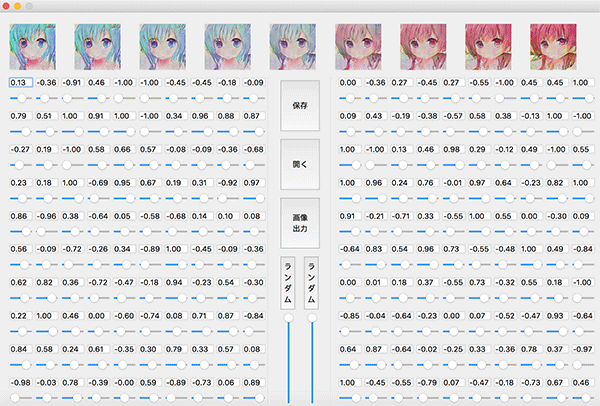
こうやってzを少しずつ調整しながら変化を見ることができます。これを使ってたくさんの絵から比較的にいいものを選ぶことができました。
最後にこれは96pxサイズの一番よくできた絵です。

そしてwaifu2x (http://waifu2x.udp.jp )を使って4倍拡大して自動コントラストを行ってみたらこんな絵ができます。自分のアイコンに使いました。

自分は絵が描けないので、こうやってプログラミングで絵作りできるのはとても助かります。
終わりに
意外と色々困難でしたが、ここまでできると随分満足だと思います。深層学習って本当に素晴らしいものです。これからも深層学習をもっと勉強して、色々挑戦していきたいです。