最近「Nuxt.jsとPythonで作る!ぬるさくAIアプリ開発入門」という本を読んで、その本でかなり新しいPythonのウェブフレームワークであるresponderが紹介されているので興味を持ってもっと調べて色々勉強した後、簡単なウェブサイトを作ってみたいと思います。
今回の目標のサイトは、SQLデータベースと接続して、データを表示したり、追加したり、更新したり、削除したりすることができるサイトです。
データベースは一番簡単であるsqlite3を使います。
使うモジュールについて
本の他に、responderとsqlite3の使い方については色んな方の記事を読みました。
responder
- Responder + WebSocketで簡易チャットアプリ
- Python+ResponderでWEBアプリケーションを構築する。
- はじめての Responder(Python の次世代 Web フレームワーク)
- 人間のためのイケてるPython WebFramework「responder」、そして作者のKenneth Reitzについて
sqlite3
これらの記事はとても参考になったので、ここでは基本な使い方については省略します。
構造
準備
データベースは簡単のためにSQLiteにします。
SQLiteは実際のサイトを作る時にはあまり向いていないが、MySQLやPostgreSQLとは違って、SQLiteは特にインストールする必要なく、最初からついているから便利です。
使うPythonモジュールは主にresponderとsqlite3だけです。
sqlite3はPythonの標準モジュールなので、インストールする必要があるのはresponderだけ。
responderの公式サイトではpipenvを使うと言われていますが、普通のpipでも簡単にインストールできます。
pip install responder
機能
このような簡単なウェブサイトを作ります。
- サイトを操るのはたった一つのPythonファイル
- 各ページはresponderを通じてjinja2のテンプレートに成される
- ページはただ3つ
-
- 全部のデータを閲覧したりダウンロードしたりできるインデックスページ
-
- データを編集できるページ
-
- エラーが出た時のページ
- スタイルシートも簡単なcssファイルだけど一応準備しておく
- formsとinputでデータを入力と編集する
- javascriptの出番はない
- データベースに収めるのはたった2列しかないテーブル
データベース
| 列名 | データ型 | |
|---|---|---|
| 名前 | namae | text |
| レベル | lv | integer |
今回の目標はただちゃんとデータベースに接続してやり取りできることを確認したいだけなので、簡単のために2列しかないテーブルにします。
このテーブルはSQLコードにすると
create table kyara (namae text,lv integer, primary key (namae));
ファイル
サイトは全部ただこの5つのファイルから成されます。
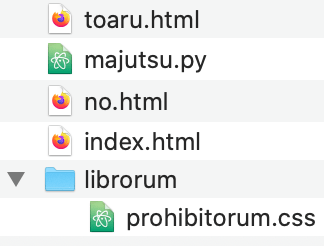
.htmlファイルはjinja2テンプレートです。jinja2は今まで使ったことはないが、ちょっとdjangoのテンプレートと似ています。
ちなみにファイルの名前は見ての通り「とある魔術の禁書目録」からです。
│- majutsu.py サーバ実行コード
│─ index.html インデックスページ
│- toaru.html データ表示と編集のページ
│- no.html 間違ったことが起きる時に出るページ
└─ librorum
└─prohibitorum.css スタイルシート
環境
OSとPythonとresponderのバージョンが違ってもあまり問題ないと思いますが一応今回で試した時の環境を書いておきます。
- Mac OS 10.15.4 Catalina
- python 3.7.7
- conda 4.8.3
- responder 2.0.5
- jinja2 2.11.2
- starlette 0.12.13
コード
次は各ファイルの中のコードの説明。
htmlテンプレート
jinja2テンプレートのhtmlファイル
index.html
まずはインデックスページ。
<head>
<meta charset="utf-8">
<title>とあるサイトのINDEX</title>
<link rel="stylesheet" href="/librorum/prohibitorum.css" type="text/css" media="all">
</head>
<body>
<h3>とあるsqlite3のresponder</h3>
<ul>
{% for k in kyara %}
<li>
<a href="/toaru/{{ k[0] }}">{{ k[0] }}</a> lv {{ k[1] }}
</li>
{% endfor %}
</ul>
<form action="/insert" method="post">
<div>名前 <input type="text" name="namae"></div>
<div>レベル <input type="text" name="lv"><br></div>
<div><input type="submit" value="追加"></div>
</form>
<a href="/download">ダウンロード</a>
</body>
構成は
- データの列挙
- 新しいデータを追加するフォーム
- データをダウンロードするリンクがあります。
toaru.html
次は、とあるキャラのデータを表示したり編集したりするページ。
<head>
<meta charset="utf-8">
<title>とある{{ namae }}のページ</title>
<link rel="stylesheet" href="/librorum/prohibitorum.css" type="text/css" media="all">
</head>
<body>
<form action="/update/{{ namae }}" method="post">
<div>名前: <input type="text" name="namae" value="{{ namae }}"></div>
<div>レベル: <input type="text" name="lv" value="{{ lv }}"></div>
<input type="submit" value="更新">
</form>
<form action="/delete/{{ namae }}" method="delete">
<input type="submit" value="削除">
</form>
<div><a href="/">戻る</a></div>
</body>
構成は
- 編集できるキャラのデータのフォーム
- データを削除のボタン
- インデックスに戻るリンク
no.html
そして、何かの間違いが起きたら出るページ。インデックスへ戻るリンクしかない。
<head>
<meta charset="utf-8">
</head>
<body>
<h1>NO!!</h1>
空はこんなに青いのにお先は真っ暗<br><br>
<a href="/">~- 戻る -~</a>
</body>
python
魔術を使ってサイトの全てを操るファイルです。
大きいサイトなら色々なファイルに分解するべきかもしれませんが、今回は小さいサイトなので、分ける必要なく一つのファイルにします。
全部のルートのコントローラーと、データベースに接続するコードは全てここに書いてあります。
majutsu.py
import responder,sqlite3,urllib,os
# データを保存するファイル
dbfile = 'dedicatus545.db'
# APIオブジェクト
api = responder.API(templates_dir='.', # テンプレートのフォルダ
static_dir='librorum', # 静的ファイルのフォルダ
static_route='/librorum') # 静的ファイルのルート
# インデックスページ
@api.route('/')
def index(req,resp):
with sqlite3.connect(dbfile) as conn:
sql_select = '''
select * from kyara
''' # 全てのキャラのデータを表示する
kyara = conn.execute(sql_select).fetchall()
resp.html = api.template('index.html',kyara=kyara)
# 各データ表示と編集のページ
@api.route('/toaru/{namae}')
def select(req,resp,*,namae):
with sqlite3.connect(dbfile) as conn:
sql_select = '''
select * from kyara where namae==?
''' # その名前を持つキャラのデータを取る
kyara = conn.execute(sql_select,[namae]).fetchone()
if(kyara):
resp.html = api.template('toaru.html',namae=kyara[0],lv=kyara[1])
else:
print('このページは存在しない')
api.redirect(resp,'/no') # 存在しない名前が入れられる場合、エラーページへ
# 何か間違っている場合のページ
@api.route('/no')
def no(req,resp):
resp.html = api.template('no.html')
# データ追加した後
@api.route('/insert')
async def insert(req,resp):
try:
with sqlite3.connect(dbfile) as conn:
param = await req.media() # フォームからのデータを取得
namae = param['namae']
lv = param['lv']
sql_insert = '''
insert into kyara (namae,lv)
values (?,?)
''' # 新しいデータ追加
conn.execute(sql_insert,(namae,lv))
api.redirect(resp,'/') # インデックスページに戻る
except Exception as err:
print(f'Error: {type(err)} {err}')
api.redirect(resp,'/no') # なにか間違いの場合
# データ更新した後
@api.route('/update/{namae0}')
async def update(req,resp,*,namae0):
try:
with sqlite3.connect(dbfile) as conn:
param = await req.media() # フォームからのデータを取得
namae = param['namae']
lv = param['lv']
sql_update = '''
update kyara set namae=?,lv=? where namae==?
''' # データ更新
conn.execute(sql_update,(namae,lv,namae0))
# データ表示のページに戻る **ここで名前はエスケープしないとエラーが出る場合があるのでurllib.parse.quoteが必要
api.redirect(resp,f'/toaru/{urllib.parse.quote(namae)}')
except Exception as err:
print(f'Error: {type(err)} {err}')
api.redirect(resp,'/no') # 何か間違いがある場合
# データ削除した後
@api.route('/delete/{namae}')
def delete(req,resp,*,namae):
try:
with sqlite3.connect(dbfile) as conn:
sql_delete = '''
delete from kyara where namae==?
''' # データ削除
conn.execute(sql_delete,[namae])
api.redirect(resp,'/') # インデックスページに戻る
except Exception as err:
print(f'Error: {type(err)} {err}')
api.redirect(resp,'/no') # 何か間違いが起こる場合
# データをロード
@api.route('/download')
def download(req,resp):
with sqlite3.connect(dbfile) as conn:
# データをjsonファイルに
data = conn.execute('select * from kyara').fetchall()
resp.media = [{'namae': d[0], 'lv': d[1]} for d in data]
# ファイルをダウンロードするためのページにするために、ヘッダに指定する
resp.headers['Content-Disposition'] = 'attachment; filename=data.json'
if(__name__=='__main__'):
# 初めて実行した時、新たにテーブルを作っておく
if(not os.path.exists(dbfile)):
with sqlite3.connect(dbfile) as conn:
sql_create = '''
create table kyara (
namae text,
lv integer,
primary key (namae)
)
'''
conn.execute(sql_create)
# サーバ開始
api.run()
ルートは7つありますが、実際にテンプレートを使うのは
- '/'
- '/toaru/{namae}'
- '/no'
3つだけ。
それに加えて
- '/insert'
- '/update/{namae0}'
- '/delete/{namae}'
これらはデータベースとのやり取りをして他のページにリダイレクトするのです。
'/insert'と'/update/{namae0}'のページはフォームからのデータを受け取る必要があってawaitが使われるのでasync関数にしています。
Pythonのasyncとawaitについては最近勉強したばかりです。色んなqiita記事を読んで参考になったのでここで紹介しておきます
responderを使う時に、例え私達は直接asyncとawaitを書かなくても、そもそもresponderの中ではasyncとawaitで動く関数がいっぱいなので、非同期処理について理解しておいたらとても役に立ちます。
最後に、'/download'はデータベースの中の全部のデータをjsonファイルに保存するためのページです。
初めてサーバを実行する時にデータベースは作成されます。その後はデータベースを収めるファイル(ここではdedicatus545.dbという名前)が現れます。
responder.APIオブジェクトにはこのように設定されます
templates_dir = '.'
static_dir = 'librorum'
static_route = '/librorum'
templates_dirはテンプレートのあるフォルダ。
デフォルトではtemplatesというフォルダにありますが、今回はフォルダを使わないので'.'に指定します。
static_dirは静的ファイルのあるフォルダ。
デフォルトではstaticというフォルダですが、ここでは'librorum'にします。
static_routeは静的ファイルのルートで、デフォルトでは'/static'ですが、同じように'/librorum'にする必要があります。
css
ウェブサイトの装飾は今回の主な目的ではないので、ちょっと見世物にできる程度に適当なcss
librorum/prohibitorum.css
div,li,h3 {
padding: 2px;
font-size: 20px;
}
input {
border: solid #194 2px;
font-size: 19px;
}
form {
margin: 3;
}
実行と結果
コードの準備が完成したら、次はサーバ.pyコードの実行です。
python majutsu.py
そしてブラウザーで http://127.0.0.1:5042/ にアクセス。
ここではfirefoxで行きます。
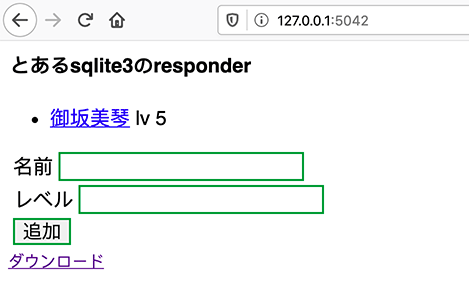
何かの間違いがなければこのようなページは表示されるはずです。
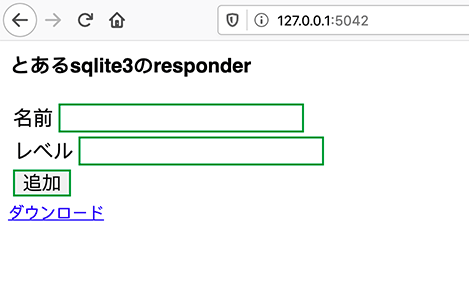
まだデータが入っていないので、まずは追加してみます。
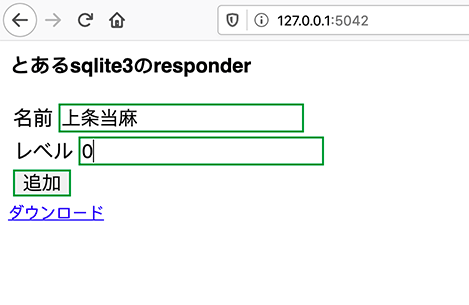
名前とレベルを入力して追加ボタンをクリックすると、データが追加されます。
試しにもう一つ追加。
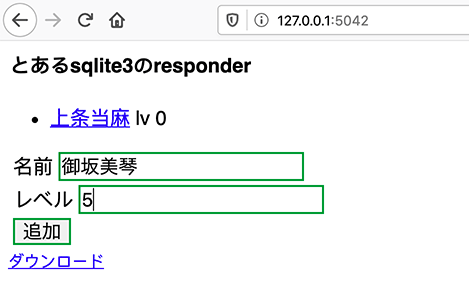
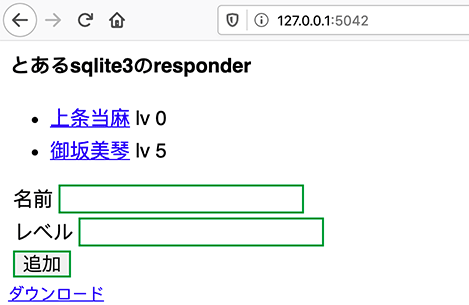
「ダウンロード」のリンクをクリックしたら、データはjsonファイルにされてダウンロードできます。
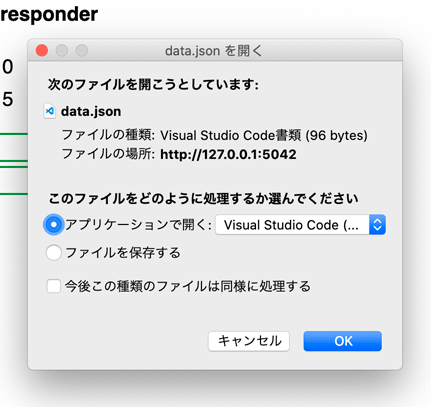
ただこの方法ならjsonに変換する時にこのように漢字はユニコードになってしまいます。
[{"namae": "\u4e0a\u6761\u5f53\u9ebb", "lv": 0}, {"namae": "\u5fa1\u5742\u7f8e\u7434", "lv": 5}]
これを避ける方法はこの記事で書いてあります https://qiita.com/nassy20/items/adc59c4b7abd202dda26
ただ、それでもfirefoxとかで調べたらちゃんと漢字に戻っているので、今回はこのままでもいいと思います。

次は、試しにフォームに何も入れずに追加ボタンをクリックすると、エラーが起きてこのページになります。

エラーが出る原因は、名前が入れられていないからreq.media()を使う時に、'namae'キーがなくてparam['namae']を呼ぶとエラーになります。
エラーを避けるためには.get()を使った方がいいですが、今回はそもそも空っぽにできる必要があるわけではないのでここではこのままでいいです。
インデックスに戻って、一つ名前をクリックしてリンクに入ったらデータ編集ページになります。
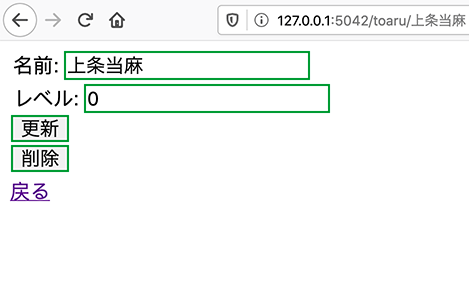
試しにレベルを空っぽにして、更新ボタンをクリックするとエラーが出てまたnoのページへ。
もう一度このページに戻って、今回ちゃんと新しいデータを入力して、ボタンをクリックしたら、データは更新されます。
インデックスに戻ったらデータはもうちゃんと更新したと確認できます。

最後に、また編集ページに入って削除ボタンをすると
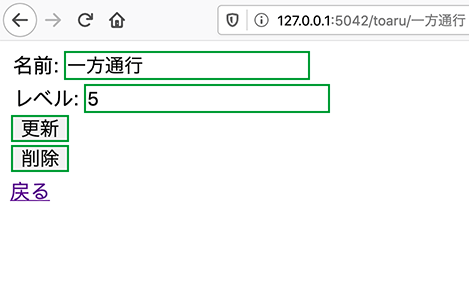
そのデータは消えます。
これで全部の機能のテストは完了。
終わりに
こうやってresponderとsqlite3でウェブサイトができました。
ただ単純であまり使い物にならないウェブサイトかもしれませんが、本格的なサイトを作るための基本の練習としては使えると思います。
javascriptなどを加えてSPAにする例は次の記事で書いてあります。