Pythonのasyncio、またasync/awaitについてはあまり実践的な例が出回っていなかったため、収集した情報をもとに用例ベースの逆引きリファレンスを作ってみました。
ただ、この辺はほんとに情報がなくて何が真実なのか謎に包まれている点があるので、情報をお持ちの方はぜひご連絡をいただければと思います。
今回紹介する例は、以下のgistにまとめてあります。実装時の参考にしていただければと思います。
icoxfog417/asyncio_examples.py
はじめに
Pythonにはthreading、multiprocessing、asyncioとどれも並列処理に使えそうなパッケージが3つあります。これらの違いをまず押さえておきます。
これらのパッケージの違いは、そのまま「マルチスレッド」、「マルチプロセス」、「ノンブロッキング」の違いに相当します。まず、マルチスレッドとマルチプロセスの違いについて。
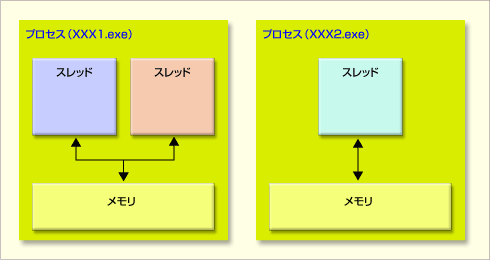
プロセスは固有のメモリをもつ処理単位で、いわゆるマルチコアのCPUの場合各コアにたいしてこのプロセスを割り当てることができ、効率的に処理できます(コア数以上のプロセスを作るのも不可能ではないが、効率が悪くなる)。
スレッドはプロセスの中の処理単位になり、同じプロセス間のスレッドはメモリを共有するという特徴があります。
ノンブロッキングはマルチスレッドの弱点を克服する方法として生まれたものです。多数のリクエストをさばく際の手法に違いがあります(参考: Node.js入門)。
- マルチスレッド: リクエスト分スレッドを生成する -> リクエストが多いと大変なことになる(C10K問題)
- ノンブロッキング: 1スレッドで複数リクエストを処理する
- あるリクエストをここまでさばいたらほかのリクエストの処理に移って、それが終わったら元の・・・という感じで処理していく
よって、マルチスレッドとノンブロッキングはスレッドの扱い方が違うため同居はできませんが、マルチプロセスとは両方とも組み合わせることができます(理論上は)。
今回扱うasyncio、またasync/awaitはノンブロッキング処理を実装するための機能になります。この点をまず押さえておいてください。
基本: ノンブロッキング処理の書き方
まず、基本としてasyncioを使ったノンブロッキング処理の書き方を紹介します。なお、このノンブロッキングでの処理が効果的、かつ適用できるのは以下のようなケースです。
- ボトルネックとなるような重たい処理がある
- その処理は大量に発生する
- 処理を完了させる順序は問わない
具体的にはurlからのページ取得や、DBからのデータ取得などが該当すると思いますが、「処理の完了順序は問わない」という点に注意してください。
以下は、シンプルな例になります(最初の例から抜粋しています)。
import asyncio
Seconds = [
("first", 5),
("second", 0),
("third", 3)
]
async def sleeping(order, seconds, hook=None):
await asyncio.sleep(seconds)
if hook:
hook(order)
return order
async def basic_async():
# the order of result is nonsequential (not depends on order, even sleeping time)
for s in Seconds:
r = await sleeping(*s)
print("{0} is finished.".format(r))
return True
if __name__ == "__main__":
loop = asyncio.get_event_loop()
loop.run_until_complete(basic_async())
処理の中核はbasic_asyncになります。ここでsleepingという処理(イメージ的にはこれが「重いけど処理順は問わない」処理に該当)を繰り返し処理しています。
処理の実行を担うのがloop = asyncio.get_event_loop()で生成されるイベントループで、これが「ノンブロッキングなスレッド」になります。ここにasyncである関数(asyncio.coroutine)を渡して処理させる(loop.run_until_complete(basic_async()))のが基本となります。
r = await sleeping(*s)のところを見ると、awaitで処理が終わるのを待っています。これだけ見ると、毎回処理が終わるのを待っているから普通のfor文と同じじゃないか、という感じがしますし実際この例ではそうなっています。実行してみればわかりますが、結果は常に以下の順になります。
first is finished.
second is finished.
third is finished.
非同期じゃないじゃないか!となりますが、実際このawaitが機能するのは以下で紹介するような並列で処理を行う場合です。
awaitが行われるということは何か重たい処理が始まるということなので、ここに到達したらスレッドは「イベントループ内の他の処理」を開始します。そしてawaitで行っていた処理が終わった際、またそのタスクに戻り処理を継続します。
そのため、下記のように処理を並列にすると、それぞれでタスクが行われているのが分かると思います(以下のスクリプトはrun_foreverの指す通り終了しないので実行する際は注意)。
async def basic_async(num):
# the order of result is nonsequential (not depends on order, even sleeping time)
for s in Seconds:
r = await sleeping(*s)
print("{0}'s {1} is finished.".format(num, r))
return True
if __name__ == "__main__":
loop = asyncio.get_event_loop()
# make two tasks in event loop
asyncio.ensure_future(basic_async(1))
asyncio.ensure_future(basic_async(2))
loop.run_forever()
実行結果を見ると、1を実行してawaitに到達したら2を開始、1がawaitから戻ってきたら1に戻り継続・・・という風に処理されているのが分かると思います。
1's first is finished.
2's first is finished.
1's second is finished.
2's second is finished.
1's third is finished.
2's third is finished.
よって、イベントループ内に1つしかcoroutineがない場合、async/awaitは効果を発揮しません。この点は重要なので、覚えておく必要があります。
基本の最後に、混乱しがちなasyncioにまつわるオブジェクトを整理しておきます。
-
coroutine: async関数の返り値はcoroutineになります -
async def hoge(): xxxという関数があった場合、hoge()はすぐにreturnが返るのではなく、coroutineオブジェクトとなります -
Future: jQueryにおけるDeferred的なオブジェクト -
set_resultやset_exceptionを使って実行結果を伝播させることができる Task-
Futureのサブクラスで、実行を管理する。直接作ることはない(というか作ってはいけない)ので、あまり意識することはない。
実際扱うのは、coroutineかFutureであり、ほとんどの関数はこの両方に対応しています。coroutineはasyncio.ensure_futureでTask化することができます(create_taskというメソッドもありTaskにすることもできますが、これら2つのメソッドに基本的に差異はありません)。
では、ここから実際にイベントループ内の複数のタスクの処理の仕方を見ていきたいと思います。
並列で処理を行いたい(固定長)
あらかじめ並列で実行したい処理の数が決まっている際は、それらを並列で一斉に処理させることができます。そのために提供されている機能が、asyncio.gatherとasyncio.waitです。
まず、asyncio.gatherのパターン
async def parallel_by_gather():
# execute by parallel
def notify(order):
print(order + " has just finished.")
cors = [sleeping(s[0], s[1], hook=notify) for s in Seconds]
results = await asyncio.gather(*cors)
return results
if __name__ == "__main__":
loop = asyncio.get_event_loop()
results = loop.run_until_complete(parallel_by_gather())
for r in results:
print("asyncio.gather result: {0}".format(r))
このasyncio.gatherは、実行される順序は通常通り不定になりますが、処理した結果については渡した順に返してくれるというありがたい特性があります(こちらご参照)。非同期処理をしつつも実行結果において元の配列のオーダーを保持したいという場合に有用です。
※Dictionary系を利用する場合は、Dictionary自体の順序が不定である点に注意してください(私ははまりました)。Dictionaryの場合キーが定義順に出てくるのは保証されません。
もうひとつは、asyncio.waitを使う方法です。
async def parallel_by_wait():
# execute by parallel
def notify(order):
print(order + " has just finished.")
cors = [sleeping(s[0], s[1], hook=notify) for s in Seconds]
done, pending = await asyncio.wait(cors)
return done, pending
if __name__ == "__main__":
loop = asyncio.get_event_loop()
done, pending = loop.run_until_complete(parallel_by_wait())
for d in done:
dr = d.result()
print("asyncio.wait result: {0}".format(dr))
waitの結果はdoneとpendingで帰ってきます。結果を取り出す際は、result()で取り出す必要があるので注意してください(処理中例外が発生していた場合、result()実行時に例外が飛びます)。
並列で処理を行いたい(不定長)
先ほどの並列処理は並列処理をする数がわかっていましたが、次々リクエストが来る場合など長さが固定でない場合もあります(ストリームなど)。
そうした場合は、Queueを使った処理が可能です。
async def queue_execution(arg_urls, callback, parallel=2):
loop = asyncio.get_event_loop()
queue = asyncio.Queue()
for u in arg_urls:
queue.put_nowait(u)
async def fetch(q):
while not q.empty():
u = await q.get()
future = loop.run_in_executor(None, requests.get, u)
future.add_done_callback(callback)
await future
tasks = [fetch(queue) for i in range(parallel)]
return await asyncio.wait(tasks)
if __name__ == "__main__":
loop = asyncio.get_event_loop()
results = []
def store_result(f):
results.append(f.result())
loop.run_until_complete(queue_execution([
"http://www.google.com",
"http://www.yahoo.com",
"https://github.com/"
], store_result))
for r in results:
print("queue execution: {0}".format(r.url))
これは固定長でurlの配列を渡しているのであまりQueueを活用していませんが・・・。ポイントとしては、asyncio.Queueでqueueを作成し、その中にput_nowaitで処理対象をどんどん入れていきます(queueのサイズを固定する場合、putを使うことでqueueが空くまでブロックできます)。
async def fetchはqueueが空にならない限りどんどん処理していきます。今回はparallelの数だけ並列でfetchを稼働させているので、1つのqueueを2つのcoroutineで分担して処理しているような形になります。
なお、Pythonのurlの取得(urllib.request.urlopen)は処理をブロックしてしまうのでこちらを参考に実装してみたんですが、うまく並列に実行されませんでした(おそらくrun_in_executorを一通り終えた後にawaitしていかないといけない?と思われる)。並列に取得を行いたい場合は、すなおにaiohttpを使ったほうが無難と思います。
ただ、loop.run_in_executor(None, requests.get, u)にあるように、run_in_executorを使うことで普通の関数をFuture化できるというのはほかのケースでもテクニックとして使えると思います。
並列での実行数を制御したい
特にスクレイピングなどを行う場合、あるサイト内の1000個のコンテンツのurlを一斉に処理するなどするとと多大な迷惑がかかるため、並列で実行するプロセスの数を制御したい場合があります。
この時に使うのがSemaphoreになります。
async def limited_parallel(limit=3):
sem = asyncio.Semaphore(limit)
# function want to limit the number of parallel
async def limited_sleep(num):
with await sem:
return await sleeping(str(num), num)
import random
tasks = [limited_sleep(random.randint(0, 3)) for i in range(9)]
return await asyncio.wait(tasks)
if __name__ == "__main__":
loop = asyncio.get_event_loop()
done, pending = loop.run_until_complete(limited_parallel())
for d in done:
print("limited parallel: {0}".format(d.result()))
使い方は簡単で、同時実行数を制御したいasync関数の中でwith await semによりSemaphoreが空くのを待つようにするだけです。
非同期処理の完了後にコールバック処理をしたい
処理の完了後に特定の処理を行わせたいという場合は、asyncio.Futureのadd_done_callbackが利用できます。以下では、coroutineをasyncio.ensure_futureでTaskに変換し、受け取ったコールバックを追加しています。
async def future_callback(callback):
futures = []
for s in Seconds:
cor = sleeping(*s)
f = asyncio.ensure_future(cor)
f.add_done_callback(callback)
futures.append(f)
await asyncio.wait(futures)
if __name__ == "__main__":
loop = asyncio.get_event_loop()
results = []
def store_result(f):
results.append(f.result())
loop.run_until_complete(future_callback(store_result))
for r in results:
print("future callback: {0}".format(r))
やろうと思えば、callbackで受け取ったFutureをさらに・・・とできると思いますが、複雑怪奇になるのでやめたほうが良いと思います(私は貴重な休みの数時間を無駄にしました)。
非同期で処理するIteratorを作りたい
データベースからの逐次読み出しなど、Iteratorでありつつ処理はノンブロッキングで流したい場合は、Iteratorを自作することが可能です。
def get_async_iterator(arg_urls):
class AsyncIterator():
def __init__(self, urls):
self.urls = iter(urls)
self.__loop = None
def __aiter__(self):
self.__loop = asyncio.get_event_loop()
return self
async def __anext__(self):
try:
u = next(self.urls)
future = self.__loop.run_in_executor(None, requests.get, u)
resp = await future
except StopIteration:
raise StopAsyncIteration
return resp
return AsyncIterator(arg_urls)
if __name__ == "__main__":
loop = asyncio.get_event_loop()
async def async_fetch(urls):
ai = get_async_iterator(urls)
async for resp in ai:
print(resp.url)
loop.run_until_complete(async_fetch([
"http://www.google.com",
"http://www.yahoo.com",
"https://github.com/"
]))
ポイントは__aiter__と__anext__で、これは通常のIteratorのasync版になります。anextのほうでawaitを使うことができます。利用する際は、async for resp in aiとasync forでイテレートする点に注意してください。
マルチプロセスでノンブロッキング処理を行いたい(未確認)
一番最初でマルチプロセスとノンブロッキングは同居可能(理論的には)と言いましたが、それを実現する?と思われる方法が以下になります。どう確認したらマルチプロセス+ノンブロッキングになっているかわかるのかが謎なので正確なところは把握してないのですが、一応掲載しておきます。
import asyncio
import concurrent.futures
loop = asyncio.get_event_loop()
executor = concurrent.futures.ProcessPoolExecutor()
loop.set_default_executor(executor)
出典
- Cleanly shutdown the IO loop when using an executor
- How to properly create and run concurrent tasks using python's asyncio module?
デフォルトのexecutorはThreadPoolExecutorを使うので、これをProcessPoolExecutorに変えてやるということです。これによっておそらくプロセス単位でノンブロッキング処理を行うことになり、multiprocessing同様CPUのコア分だけ分散させれば並行処理の恩恵を受けることができます。
ただ、逆に言えばプロセスはCPUコア数以上複製するのは効率的ではなく、URLを多数並列で取得したい場合などは不向きです(これはスレッドのほうが向いている)。状況に応じて使い分けていけばよいと思います。デフォルトに設定するのが怖い、という場合はrun_in_executorで特定のfunction実行時にのみ使うのもありだと思います。
以下は、Queueの例をProcess版にしたものです(これが一番相性が良いと思う)。print_numが外に出ているのは、グローバルな関数でないとエラーが発生したためです(Processを複製する際にpickleを使っている?)。
def print_num(num):
print(num)
async def async_by_process():
executor = concurrent.futures.ProcessPoolExecutor()
queue = asyncio.Queue()
for i in range(10):
queue.put_nowait(i)
async def proc(q):
while not q.empty():
i = await q.get()
future = loop.run_in_executor(executor, print_num, i)
await future
tasks = [proc(queue) for i in range(4)] # 4 = number of cpu core
return await asyncio.wait(tasks)
if __name__ == "__main__":
loop = asyncio.get_event_loop()
loop.run_until_complete(async_by_process())
以上、Pythonのasyncioについてのまとめでした。