pythonで文字列を書く時はいつも%書式を使ってたのですが、python3.6からはf-stringという新しい表記があります。
f-stringについてこの記事を参考に https://qiita.com/shirakiya/items/2767b30fd4f9c05d930b
で、二ヶ月前にこの記事を書いた時にhttps://qiita.com/phyblas/items/9a087ad1f73aca5dcbe5
@shiracamusさんに指示してもらったのはきっかけで、f-stringを興味を持ち始めたのですが、今でも時々python2.7を使う必要がまだあるので、互換性のことを考慮するとやはり今はまだf-stringに乗り換える時ではないと思ってました。
しかし、先日この記事を見つけました。https://qiita.com/Nakamurus/items/9171a37014d9b25eece0
記事ではf-stringが高速だと説明したのです。
とても早ければ乗り換えるメリットがあるし、いいかもしれないと思ったので、結局自分も実験してみたのです。
今回は3つの方法の速度を測って比べることにしました。
- %書式
- format
- f-string
色々試してみたのですが、結果は意外でした。ここでその結果を発表します。
%書式からf-stringに乗り換えるべきかどうか迷っている人に参考になれたらと思います
比較対象
データの種類によって結果は随分違います。
今回で実験してみたのは
- 文字列をそのまま出力する(%s、{})
- intを文字列に変換する(%d、{})
- intを指定の桁数で0埋めて文字列に変換する(%010d、{:010})
- floatを指数形式で小数部の桁数を指定しずに文字列に変換する(%e、{:e})
- floatを指数形式で指定の小数部の桁数で文字列に変換する(%.10e、{:.10e})
- floatをfで小数部の桁数を指定しずに文字列に変換する(%f、{:f})
- floatをfで指定の小数部の桁数で文字列に変換する(%.10f、{:.10f})
- floatを形式を指定しずに文字列に変換する(%s、{})
- Noneを文字列に変換する(%s、{})
- listを文字列に変換する(%s、{})
小数(float)の場合は色々違う形で変換できるのです。
コード
3つの方法で10つの場合毎に五回実行して平均値と標準偏差を求めて棒グラフを書いてみす。
import time
import numpy as np
import matplotlib.pyplot as plt
tt =[]
n = 100000
t = [[],[],[]]
for j in range(5):
a = 'あい'
b = 'まい'
t0 = time.time()
for i in range(n):
'%s%s'%(a, b)
t[0].append(time.time()-t0)
t0 = time.time()
for i in range(n):
'{}{}'.format(a, b)
t[1].append(time.time()-t0)
t0 = time.time()
for i in range(n):
f'{a}{b}'
t[2].append(time.time()-t0)
tt.append(t)
t = [[],[],[]]
for j in range(5):
a = 10
b = 200
t0 = time.time()
for i in range(n):
'%d%d'%(a, b)
t[0].append(time.time()-t0)
t0 = time.time()
for i in range(n):
'{}{}'.format(a, b)
t[1].append(time.time()-t0)
t0 = time.time()
for i in range(n):
f'{a}{b}'
t[2].append(time.time()-t0)
tt.append(t)
t = [[],[],[]]
for j in range(5):
a = 10
b = 200
t0 = time.time()
for i in range(n):
'%010d%010d'%(a, b)
t[0].append(time.time()-t0)
t0 = time.time()
for i in range(n):
'{:010}{:010}'.format(a, b)
t[1].append(time.time()-t0)
t0 = time.time()
for i in range(n):
f'{a:010}{b:010}'
t[2].append(time.time()-t0)
tt.append(t)
t = [[],[],[]]
for j in range(5):
a = 1.522555
b = 3.125
t0 = time.time()
for i in range(n):
'%e%e'%(a, b)
t[0].append(time.time()-t0)
t0 = time.time()
for i in range(n):
'{:e}{:e}'.format(a, b)
t[1].append(time.time()-t0)
t0 = time.time()
for i in range(n):
f'{a:e}{b:e}'
t[2].append(time.time()-t0)
tt.append(t)
t = [[],[],[]]
for j in range(5):
a = 1.522555
b = 3.125
t0 = time.time()
for i in range(n):
'%.10e%.10e'%(a, b)
t[0].append(time.time()-t0)
t0 = time.time()
for i in range(n):
'{:.10e}{:.10e}'.format(a, b)
t[1].append(time.time()-t0)
t0 = time.time()
for i in range(n):
f'{a:.10e}{b:.10e}'
t[2].append(time.time()-t0)
tt.append(t)
t = [[],[],[]]
for j in range(5):
a = 1.522555
b = 3.125
t0 = time.time()
for i in range(n):
'%f%f'%(a, b)
t[0].append(time.time()-t0)
t0 = time.time()
for i in range(n):
'{:f}{:f}'.format(a, b)
t[1].append(time.time()-t0)
t0 = time.time()
for i in range(n):
f'{a:f}{b:f}'
t[2].append(time.time()-t0)
tt.append(t)
t = [[],[],[]]
for j in range(5):
a = 1.522555
b = 3.125
t0 = time.time()
for i in range(n):
'%.10f%.10f'%(a, b)
t[0].append(time.time()-t0)
t0 = time.time()
for i in range(n):
'{:.10f}{:.10f}'.format(a, b)
t[1].append(time.time()-t0)
t0 = time.time()
for i in range(n):
f'{a:.10f}{b:.10f}'
t[2].append(time.time()-t0)
tt.append(t)
t = [[],[],[]]
for j in range(5):
a = 1.522555
b = 3.125
t0 = time.time()
for i in range(n):
'%s%s'%(a, b)
t[0].append(time.time()-t0)
t0 = time.time()
for i in range(n):
'{}{}'.format(a, b)
t[1].append(time.time()-t0)
t0 = time.time()
for i in range(n):
f'{a}{b}'
t[2].append(time.time()-t0)
tt.append(t)
t = [[],[],[]]
for j in range(5):
a = None
b = None
t0 = time.time()
for i in range(n):
'%s%s'%(a, b)
t[0].append(time.time()-t0)
t0 = time.time()
for i in range(n):
'{}{}'.format(a, b)
t[1].append(time.time()-t0)
t0 = time.time()
for i in range(n):
f'{a}{b}'
t[2].append(time.time()-t0)
tt.append(t)
t = [[],[],[]]
for j in range(5):
a = list(range(1,6))
b = list(range(11,16))
t0 = time.time()
for i in range(n):
'%s%s'%(a, b)
t[0].append(time.time()-t0)
t0 = time.time()
for i in range(n):
'{}{}'.format(a, b)
t[1].append(time.time()-t0)
t0 = time.time()
for i in range(n):
f'{a}{b}'
t[2].append(time.time()-t0)
tt.append(t)
tt = np.array(tt)/n*1000000
plt.figure(figsize=[7,6])
plt.subplot(211)
for i,c in enumerate(['#ffaaaa','#aaffaa','#aaaaff']):
plt.bar(np.arange(10)+(i-1)/4.,tt[:,i].mean(1),width=0.25,yerr=tt[:,i].std(1),capsize=5,color=c,ecolor='#332211')
plt.legend(['%書式','format','f-string'],prop={'family':'AppleGothic'})
plt.ylabel('時間($\mu s$)',family='AppleGothic')
plt.xticks([])
plt.subplot(212)
for i,c in enumerate(['#ffaaaa','#aaffaa','#aaaaff']):
plt.bar(np.arange(10)+(i-1)/4.,(tt[:,i]/tt[:,0]).mean(1),width=0.25,yerr=(tt[:,i]/tt[:,0]).std(1),capsize=5,color=c,ecolor='#332211')
plt.ylabel('書式の倍數',family='AppleGothic')
plt.xticks(np.arange(10),['s','d','010d','e','.10e','f','.10f','f>>s','None','list'])
plt.tight_layout()
plt.show()
結果
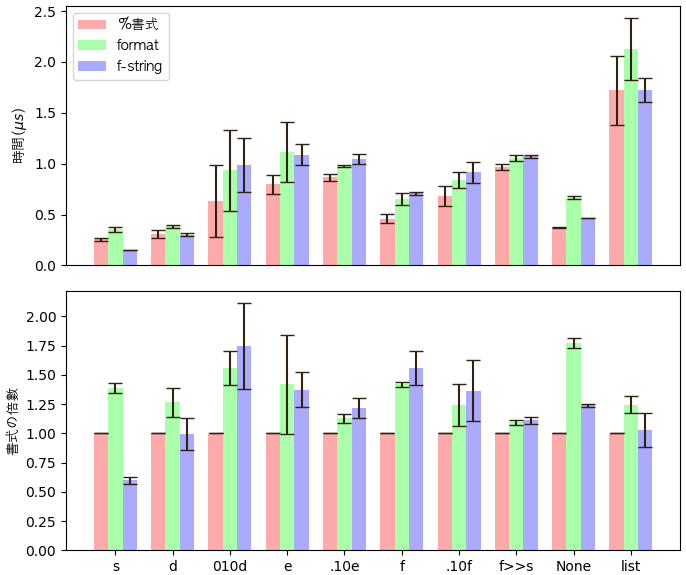
結果は以上です。上図はマイクロ秒単位の一回毎の過ごす時間で、下図は%書式の場合と比べる倍数です。
ちなみに、macでpython 3.7.1で実行したのですが、環境によって違う可能性があるかもしれません。
まとめ
結果から見ると、殆どの場合は%書式の方が早いです。
直接文字列をそのまま出力する場合ははf-stringの方が早いですが、それ以外は勝つことがありません。
formatについてですが、この記事を読んだことがあります。https://qiita.com/amedama/items/8635aff8729a248bad16
記事によると、formatの方が推奨さられていたようですが、結果から見ると、どんな場合でも%書式より遅いようですし書く時も一番冗長だから、そもそもformatを使う理由はあるのでしょうか?と不思議に思っています。
文字列をそのまま出力する時はf-stringはとても高速ですし、短く書けるから便利です。
整数やリストを形式を指定しないで文字列に変換する場合もあまり変わらないようです。
ただ、形式指定で整数と小数を変換することはf-stringは向いていないようです。どんな場合でもformatよりも遅いです。
書き方もこの場合では%書式と同じくらいの長さになります。
というわけで、速度のことにこだわるのなら使い分けしたらいいかもしれません。
とは言っても、速度の違いはそんなに大きいっていうわけではないから、好きなように選ぶといいと思います。