はじめに
「いいね」をもらうために記事を書くっていうのはお門違いですがやっぱもらうとうれしいですよね?
私事ではありますが、エイチームブライズアドベントカレンダーの初日に@sho0211が書いてくれた記事(アドベントカレンダーのいいねをスクレイピングで数える)の冒頭にあったとおり、エイチームの子会社間でどこが一番よい記事を提供できたのかを競おう、ということになっております。(各子会社のカレンダーリスト)
そう、「いいね」をどれだけ頂けるのか、ですね。
ちなみに現状弊社が最下位です。ぐぬぬ...
そして、一番多く「いいね」を頂けた記事を書いた人は美味しいお店に連れて行ってもらえるとかなんとか![]()
そんなこんなで、良い記事とはどんなもんか
- メタ情報
- 定性的な情報
に分けて見ていきたいと思います。
検証の結果3つの知見が得られました。
今回の実装に興味ない人は検証の章を飛ばしてもらっても大丈夫かと思います。
結果にジャンプ
仮説
仮説を立てておくことで収集すべき情報と、データをどう見るのが良いのかを考えやすくしておきます。
メタ情報
- 人気のあるタグがついている
- コードが多いものより、読み物系より?
- ゴールデンタイムに投稿されたもの(通勤時、寝る前)
- 短すぎず、長すぎない
定性的な情報
- 実用的な話
- 実体験に基づく話
- ネタ要素がある
- タイトルが良い
検証
では仮説を基に実際にQiitaの記事を見て行きましょう。
記事の収集はQiita APIを使わさせていただきます。
投稿一覧取得のAPIはユーザ情報でもないので認証の必要はないのですが、認証していないと制限が厳しいのでトークンを取得しておきます。
ユーザの管理画面からトークンを取得できます。
Pythonさんを使ってやっていきます。
使うモジュールはこの辺
import urllib.request
import json
import sqlite3
import base64
import time
import datetime
from lxml import html # htmlをパースする
import matplotlib.pyplot as plt # グラフ表示
import numpy as np # 数値計算(平均しか使ってない)
from scipy import stats # 相関を見る
import MeCab # 形態素解析
import gensim # LDA
記事の取得
ページネーションが必要なため、イテレートするクラスを用意しときます。
class QiitaArticleGetter(object):
"""Iterator for request for pagenation to Qiita Posted Articles"""
URL = "https://qiita.com/api/v2/items"
TOKEN = token # 自分のトークン用意してね
def __init__(self, per_page, start_page, end_page=60):
self.per_page = per_page
self.start_page = start_page
self.end_page = end_page
self.page = start_page
def __iter__(self):
return self
def __next__(self):
if self.page > self.end_page:
raise StopIteration()
response = self.request()
self.page += 1
return response
def request(self):
params = urllib.parse.urlencode({'per_page': self.per_page, 'page': self.page})
request = urllib.request.Request(self.URL + '?' + params)
request.add_header("Authorization", "Bearer {0}".format(self.TOKEN))
print("request to {0}".format(request.get_full_url()))
try:
with urllib.request.urlopen(request) as f:
response = f.read()
print("complete")
except urllib.request.HTTPError as e:
print(e.code)
print(e.read())
response = None
return response
記事データのパース
取得するべきデータ
先ほど立てた仮説からすると以下の情報が必要そうですね。
- タグの情報
- テキストとコードを分けたテキストデータ
- 比率
- コンテンツ量(行数)
- 投稿日時
- タイトル
lxmlを使ってhtmlをパースしてテキストとコードブロックをとってきたり
必要な情報を整形したりする関数を用意しておきます。
def extract(article):
print(article['url'], article['title'], article['created_at'])
doc = html.fromstring(article['rendered_body'])
# コードブロック抽出
codes = '\n'.join([div.text_content() for div in doc.find_class("code-frame")])
code_line_count = len(codes.split('\n'))
# テキスト部抽出
text = '\n'.join([elm.text_content() for elm in doc.iterchildren() if elm.tag not in ('div')])
text_line_count = len(text.split('\n'))
tags = [tag['name'] for tag in article['tags']]
# str(tags)のところ、json.dumps(tags) にすべきでした...後で面倒に...
extract_data = (article['id'], article['title'], text, codes, article['likes_count'],
str(tags), article['created_at'], text_line_count, code_line_count,
text_line_count + code_line_count, article['url'])
return extract_data
SQLiteのテーブル用意しておきます。
db_name = 'qiita_articles.db'
conn = sqlite3.connect(db_name)
c = conn.cursor()
c.execute(
'''CREATE TABLE articles (id primary key, title, text, codes, likes_count, tags, post_date, text_line_count, code_line_count, total_count, url)'''
)
イテレータちゃんよ頑張って。
バシバシしすぎないようにちゃんとスリープかけます。
APIのドキュメントを見ると1ページ辺りの記事数はMAX100件、ページは100までしかいけないため、それで設定。
article_getter = QiitaArticleGetter(100, 1, 100)
for response in article_getter:
articles = json.loads(response.decode('utf-8'))
for article in articles:
insert_data = extract(article)
c.execute(
'''
REPLACE INTO
articles(id, title, text, codes, likes_count, tags, post_date, text_line_count, code_line_count, total_count, url)
VALUES(?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
''',
insert_data
)
conn.commit()
time.sleep(1)
メタ情報の分析
さあ、取得した情報を見ていきましょう。
まず、「いいね」数の分布をみます。
c.execute('SELECT likes_count from articles')
likes = [row[0] for row in c]
plt.hist(likes, int(max(likes)/50)) # 50づつくらいに区切る
plt.show()
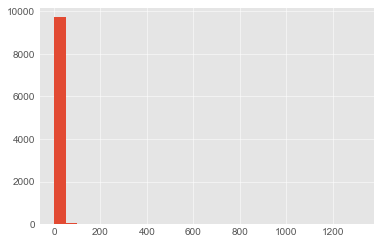
むむ...大部分が50以下のようですね...
plt.axis([50, max(likes), 0, len([like for like in likes if like >= 50 and like <= 100])])
plt.hist(likes, int(max(likes)/50)) # 50づつくらいに区切る
plt.show()
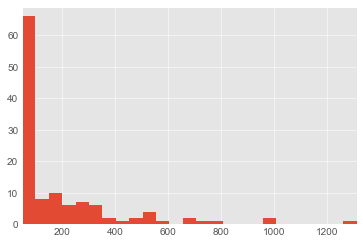
len([like for like in likes if like >= 50]) # 123
今弊社で一番いいね多い記事が50以上100未満くらいで、50以上付いているものを見てみると123記事とな。
9832記事取得してきましたがこれは意外と50の壁はでかい...!
(うちがぶち抜くとエンジニア全員いるチャット部屋で啖呵切ったのを後悔している![]() )
)
100overはもはや異常値のようなものかもしれないです。
plt.axis([10, 100, 0, len([like for like in likes if like >= 10 and like < 20])])
plt.hist(likes, int(max(likes)/10)) # 10づつくらいに区切る
plt.show()
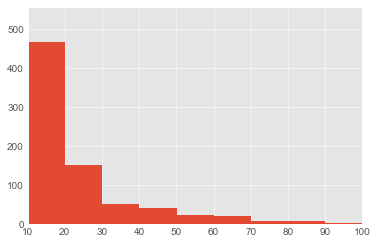
どんなタグがついているか
tags_count = dict()
for row in c:
count_group = row[0] // 10
if not count_group in tags_count:
tags_count[count_group] = dict()
tags = json.loads(row[1].replace("'", '"')) # jsonにせずstr()で入れてしまってた...
# ちゃんとjson.dumps()していれば、json.loads(tags)でOK
for tag in tags:
if not tag in tags_count[count_group]:
tags_count[count_group][tag] = 0
tags_count[count_group][tag] += 1
for count, tags in sorted(tags_count.items()):
print((count) * 10, '台:', sorted(tags.items(), reverse=True, key=lambda x: x[1])[:5])
0 台: [('Python', 486), ('JavaScript', 319), ('PHP', 249), ('Rails', 204), ('Ruby', 192)]
10 台: [('Python', 41), ('JavaScript', 34), ('Swift', 23), ('iOS', 20), ('機械学習', 19)]
20 台: [('JavaScript', 17), ('Python', 12), ('iOS', 7), ('Android', 7), ('Ruby', 5)]
30 台: [('Python', 9), ('JavaScript', 7), ('Swift', 5), ('機械学習', 4), ('iOS', 4)]
40 台: [('JavaScript', 6), ('Python', 3), ('Swift', 3), ('DeepLearning', 2), ('CSS3', 2)]
50 台: [('PHP', 2), ('Node.js', 1), ('GoogleHome', 1), ('C', 1), ('アルゴリズム', 1)]
60 台: [('新人プログラマ応援', 2), ('AWS', 2), ('HTML', 2), ('Android', 1), ('Mac', 1)]
70 台: [('機械学習', 2), ('DeepLearning', 2), ('jpeg', 1), ('ニューラルネットワーク', 1), ('LSTM', 1)]
80 台: [('JavaScript', 3), ('Ruby', 1), ('Rails', 1), ('メタプログラミング', 1), ('AST', 1)]
90 台: [('GoogleAssistant', 1), ('GoogleHome', 1), ('スマートスピーカー', 1), ('WMS', 1), ('Android', 1)]
100 台: [('Python', 1), ('初心者', 1), ('機械学習', 1), ('DeepLearning', 1), ('FX', 1)]
110 台: [('分散システム', 1), ('paxos', 1), ('Qiita', 1), ('Python', 1), ('MachineLearning', 1)]
120 台: [('C#', 1), ('Kotlin', 1), ('Xamarin', 1), ('JetBrains', 1)]
150 台: [('機械学習', 1), ('最適化', 1), ('ビッグデータ', 1), ('データフロー', 1), ('ヒューマンインザループ', 1)]
160 台: [('R', 1), ('機械学習', 1), ('MachineLearning', 1), ('DataVisualization', 1), ('Exploratory', 1)]
170 台: [('プログラミング教育', 1), ('N高等学校', 1), ('N予備校', 1), ('Java', 1), ('Git', 1)]
180 台: [('プロジェクト管理', 1), ('マネジメント', 1), ('エンジニア', 1), ('生存戦略', 1), ('デスマーチ', 1)]
190 台: [('HTML', 1), ('jQuery', 1), ('reactjs', 1), ('React', 1)]
210 台: [('chrome-extension', 1), ('阿部寛', 1), ('Haskell', 1)]
220 台: [('test', 1), ('e2e', 1), ('jest', 1), ('React', 1), ('enzyme', 1)]
230 台: [('Android', 1), ('C#', 1), ('game', 1), ('iOS', 1), ('Unity', 1)]
250 台: [('JavaScript', 1), ('Rails', 1), ('es6', 1), ('React', 1), ('reactnative', 1)]
260 台: [('Qiita', 1), ('IoT', 1), ('nefry', 1)]
280 台: [('勉強会', 1), ('ポエム', 1), ('社内勉強会', 1), ('運営', 1)]
330 台: [('ShellScript', 1), ('AdventCalendar', 1), ('shell', 1), ('初心者向け', 1), ('シェルスクリプト', 1)]
340 台: [('アジャイル', 1), ('効率化', 1), ('マネジメント', 1), ('エンジニア', 1), ('働き方改革', 1)]
370 台: [('Android', 1), ('emoji', 1), ('unicode', 1)]
440 台: [('ポエム', 1), ('リーン', 1), ('開発プロセス', 1), ('GooglePlay', 1)]
490 台: [('アジャイル', 1), ('転職', 1), ('採用', 1), ('キャリア', 1), ('Linux', 1)]
500 台: [('GoogleAnalytics', 1), ('データ分析', 1), ('アクセス解析', 1), ('ウェブ制作', 1), ('performance', 1)]
530 台: [('HTML', 1), ('CSS', 1), ('JavaScript', 1), ('Terminal', 1)]
650 台: [('AWS', 1), ('S3', 1), ('CloudFront', 1), ('WebP', 1), ('阿部寛', 1)]
710 台: [('UUID', 1), ('ULID', 1), ('Flake', 1)]
770 台: [('HTML5', 1), ('CSS3', 1), ('フロントエンド', 1)]
990 台: [('Python', 1), ('Rails', 1), ('WebAPI', 1), ('機械学習', 1), ('docker', 1)]
1000 台: [('JavaScript', 1)]
1310 台: [('iOS', 1), ('テスト', 1), ('レビュー', 1), ('Swift', 1)]
推測通り人気のタグほど「いいね」が多い!ということにはならないようですが、「いいね」50未満はまあ、その傾向はあるみたいです。
コンテンツ量
c.execute('SELECT likes_count, avg(total_count) FROM articles group by likes_count')
data = list(zip(*[row for row in c]))
plt.scatter(*data)
plt.show()
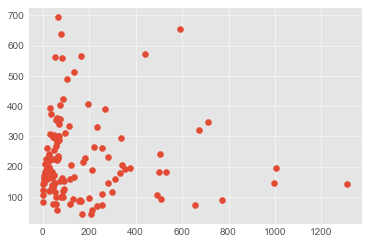
図で見ると100~200行くらいが多いというだけで、相関は特になさそう。
print("r= {0}, p= {1}".format(*stats.pearsonr(*data)))
# r= -0.04211316762387112, p= 0.7835652882516911
コンテンツの比率(テキストとコード)
c.execute(
'''SELECT likes_count, AVG(CAST(text_line_count AS REAL) / total_count) FROM articles group by likes_count'''
)
data = list(zip(*[row for row in c]))
plt.scatter(*data)
plt.show()
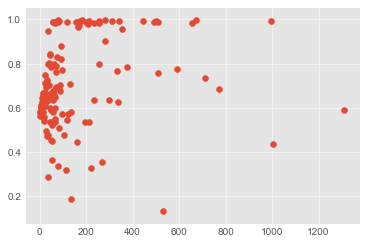
こちらは若干、テキストよりになるのかなとも思える薄い相関はあるよう?
print("r= {0}, p= {1}".format(*stats.pearsonr(*data)))
# r= 0.2045784739127026, p= 0.017734497264772386
投稿時間
c.execute('SELECT likes_count, post_date FROM articles')
data = [(row[0], time.strptime(row[1], '%Y-%m-%dT%H:%M:%S+09:00').tm_hour) for row in c]
time_count = dict()
for d in data:
if not d[0] in time_count:
time_count[d[0]] = list()
time_count[d[0]].append(d[1])
time_count = {count: np.mean(times) for count, times in time_count.items()}
data = list(zip(*time_count.items()))
plt.scatter(*data)
plt.show()
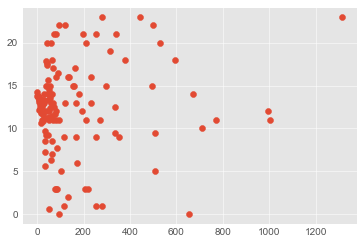
これはてんでダメ。
print("r= {0}, p= {1}".format(*stats.pearsonr(*data)))
# r= 0.09178936090059388, p= 0.2915109776986231
定性的な情報の分析(トピックモデル)
LDA(Latent Dirichlet Allocation)を用いて、文章がどんなトピックをもつのかを見ていきます。
すべての文章を形態素解析にかけ、名詞を取り出します。
# いいね50以上に搾る
c.execute('SELECT title, text FROM articles where likes_count >= 50')
doc = list()
for row in c:
text = row[1]
tagger = MeCab.Tagger('mecabrc')
results = tagger.parse(text).split('\n')
words = list()
for line in results:
word_data = line.split(',')
if word_data[0].find('名詞') < 0:
continue
if word_data[6] == '*':
word = word_data[0].split('\t')[0]
else:
word = word_data[6]
# 1文字のもの削る
if len(word) == 1: continue
# ascii文字のみの単語削る
if max([ord(char) for char in word]) < 128: continue
words.append(word)
doc.append(words)
すべてのワードからコーパス(全文章の集合みたいなの)を作成します。
dictionary = gensim.corpora.Dictionary(doc)
corpus = [dictionary.doc2bow(d) for d in doc]
tf-idf(Term Frequency - Inverse Document Frequency)を計算します。
単語の重要度です。
多くの文章にでてくる単語は文章毎に差がない、ということになるので重要度は下がる。
他の文章にはでないけど特定の文章でよく出る単語は重要度上がる。
と言った形です。
tfidf = gensim.models.TfidfModel(corpus)
corpus_tfidf = tfidf[corpus]
コーパス、tfidfを用いてモデルを学習させます。
lda = gensim.models.LdaModel(corpus=corpus_tfidf, id2word=dictionary,
num_topics=30, minimum_probability=0.01,
passes=20, update_every=0, chunksize=10000)
こんなトピック群が出来上がりました。
と行きたいところですがここ難しい...
全然いいモデルが作れないです。
記事が分散しすぎてトピックをまとめきれないのかと。
for i in range(30):
print('tpc_{0}: {1}'.format(i, lda.print_topic(i)[0:80]+'...'))
tpc_0: 0.000*"サンプル" + 0.000*"数字" + 0.000*"関数" + 0.000*"指定" + 0.000*"組み合わせ" + 0.000*"アーキテクチャ" + 0.000*"試行錯誤"...
tpc_1: 0.004*"中断" + 0.003*"カラム" + 0.003*"マイニング" + 0.003*"補完" + 0.002*"テーブル" + 0.002*"ビルダー" + 0.002*"太陽光" + ...
tpc_2: 0.003*"フォント" + 0.002*"難読" + 0.002*"無限" + 0.002*"リガチャ" + 0.002*"ループ" + 0.001*"詰め" + 0.001*"ウィルス" + 0....
tpc_3: 0.003*"断片" + 0.003*"脱出" + 0.003*"シェル" + 0.002*"連発" + 0.002*"メソッド" + 0.002*"楽器" + 0.002*"連なり" + 0.002...
tpc_4: 0.004*"乱数" + 0.003*"レイアウト" + 0.003*"影響" + 0.002*"宅配" + 0.002*"ヤマト運輸" + 0.002*"エンジン" + 0.002*"ツリー" + ...
tpc_5: 0.006*"モデル" + 0.005*"ベクトル" + 0.004*"単語" + 0.004*"予測" + 0.004*"線形" + 0.003*"精度" + 0.003*"のび太" + 0.003...
tpc_6: 0.002*"タイル" + 0.001*"キーバインド" + 0.001*"メニュー" + 0.001*"スナップショット" + 0.001*"ウェブアプリ" + 0.001*"漫画" + 0.001...
tpc_7: 0.004*"操作" + 0.004*"くん" + 0.003*"作業" + 0.003*"生成" + 0.003*"さん" + 0.003*"タイム" + 0.003*"速度" + 0.003*"ク...
tpc_8: 0.002*"コネクション" + 0.002*"番号" + 0.002*"過半数" + 0.002*"先方" + 0.001*"納品" + 0.001*"お客様" + 0.001*"合意" + 0.0...
tpc_9: 0.004*"資格" + 0.003*"ノード" + 0.002*"作図" + 0.002*"アイコンセット" + 0.002*"マネージドサービス" + 0.002*"メニュー" + 0.001*"...
tpc_10: 0.003*"絵文字" + 0.003*"フィード" + 0.003*"トップ" + 0.002*"リーク" + 0.002*"ログイン" + 0.002*"カスタム" + 0.002*"カラー" +...
tpc_11: 0.003*"運営" + 0.003*"セッション" + 0.002*"攻撃" + 0.002*"動き" + 0.002*"アニメーション" + 0.002*"ヘッダー" + 0.002*"改行" +...
tpc_12: 0.003*"ポケモン" + 0.003*"事業" + 0.003*"スクレイピング" + 0.002*"分析" + 0.002*"曲線" + 0.002*"メッシュ" + 0.002*"収集" + ...
tpc_13: 0.003*"プラットフォーム" + 0.002*"来訪" + 0.002*"受付" + 0.001*"スプレッドシート" + 0.001*"大阪" + 0.001*"呼び鈴" + 0.001*"支店...
tpc_14: 0.004*"横綱" + 0.001*"力士" + 0.001*"引退" + 0.001*"コホート" + 0.001*"富士" + 0.001*"在位" + 0.001*"北海道" + 0.001*...
tpc_15: 0.001*"緩やか" + 0.001*"⌘+" + 0.001*"デート" + 0.001*"比較" + 0.001*"習性" + 0.001*"まわり" + 0.001*"取り扱い" + 0.00...
tpc_16: 0.007*"コンポーネント" + 0.006*"オブジェクト" + 0.006*"画像" + 0.004*"ボタン" + 0.004*"入門" + 0.004*"メソッド" + 0.004*"ドキュ...
tpc_17: 0.003*"ナビゲーション" + 0.002*"データセット" + 0.002*"ネットワーク" + 0.002*"ロス" + 0.002*"デスク" + 0.002*"判定" + 0.001*"切...
tpc_18: 0.004*"数字" + 0.002*"レポート" + 0.002*"バイト" + 0.002*"トラクタ" + 0.001*"トラフィック" + 0.001*"範囲" + 0.001*"コンス" +...
tpc_19: 0.006*"関数" + 0.005*"アプリ" + 0.005*"データ" + 0.004*"設定" + 0.004*"コード" + 0.004*"開発" + 0.004*"コマンド" + 0.00...
tpc_20: 0.003*"一貫" + 0.002*"ウド" + 0.002*"クラ" + 0.002*"リトライ" + 0.002*"サーキットブレイカー" + 0.002*"誤差" + 0.001*"ドキュメン...
tpc_21: 0.003*"ファームウェア" + 0.003*"ネットワークブート" + 0.002*"カード" + 0.001*"カーネル" + 0.001*"ストレージブート" + 0.000*"アップデート"...
tpc_22: 0.003*"リファクタリング" + 0.003*"ホームページ" + 0.003*"きれい" + 0.002*"キモ" + 0.002*"阿部" + 0.001*"、「" + 0.001*"生成" ...
tpc_23: 0.003*"ドメイン" + 0.002*"スプレッドシート" + 0.002*"ポータル" + 0.002*"暗号" + 0.002*"コイン" + 0.002*"グループ" + 0.002*"エキ...
tpc_24: 0.006*"テスト" + 0.006*"サービス" + 0.005*"デバイス" + 0.005*"実装" + 0.005*"クラス" + 0.004*"指定" + 0.004*"学習" + 0.0...
tpc_25: 0.003*"生徒" + 0.003*"ハンズオン" + 0.002*"行列" + 0.002*"シェーダ" + 0.002*"クリーン" + 0.002*"用途" + 0.002*"素材" + 0....
tpc_26: 0.002*"署名" + 0.001*"チェリー" + 0.001*"対処" + 0.001*"要望" + 0.001*"マネタイズ" + 0.001*"ホームアプリ" + 0.001*"ショートカッ...
tpc_27: 0.002*"発音" + 0.002*"英語" + 0.002*"ネットワーク" + 0.002*"ケーブル" + 0.002*"メンバー" + 0.002*"ルータ" + 0.002*"スイッチ" ...
tpc_28: 0.002*"創出" + 0.002*"構文" + 0.002*"雇用" + 0.001*"タイピング" + 0.001*"配列" + 0.001*"適応" + 0.001*"課金" + 0.001*...
tpc_29: 0.004*"ブランチ" + 0.003*"シェル" + 0.003*"レジスタ" + 0.003*"乱数" + 0.002*"マージ" + 0.002*"マシン" + 0.001*"ループ" + 0...
とりあえずランダムにとってきてどんなトピックになるか見てみましょう。
c.execute('SELECT title, text FROM articles where likes_count >= 50 order by random()')
row = next(c)
text = row[1]
tagger = MeCab.Tagger('mecabrc')
results = tagger.parse(text).split('\n')
words = list()
for line in results:
word_data = line.split(',')
if word_data[0].find('名詞') < 0:
continue
if word_data[6] == '*':
word = word_data[0].split('\t')[0]
else:
word = word_data[6]
if len(word) == 1: continue
if max([ord(char) for char in word]) < 128: continue
words.append(word)
[Node.js] 無料で簡単にウェブアプリを公開できるサービス「Glitch」を使ってみた!の記事です。
vec = dictionary.doc2bow(words)
sorted(lda[vec], key=lambda x: x[1])
[(10, 0.010763541966059621),
(7, 0.053200865006979563),
(16, 0.066445719341108003),
(6, 0.14199198443140709),
(24, 0.21876784140848715),
(19, 0.5035320346009251)]
一番スコアが高い19のトピック群を見てみます。
print(lda.print_topic(19))
0.006*"関数" + 0.005*"アプリ" + 0.005*"データ" + 0.004*"設定" + 0.004*"コード" + 0.004*"開発" + 0.004*"コマンド" + 0.004*"ファイル" + 0.004*"言語" + 0.004*"処理"
それっぽいのはそれっぽいですがなんとも言えない。
トピックを上手く抽出するにはかなりワードを絞り込まないと難しそうです。
これはまた挑戦してみます...
結果
50未満でぼちぼち「いいね」を狙うなら人気のタグ(Python,Javascript等)の記事を書く
純粋にviewが稼げるからかというのが要因かと思います。
この辺はちゃんと母数も計算しないといけなかったです。
読み物系の方が大きく狙えそう
コーディング系は読むの大変&読み物系は誰でも読める&スマホから通勤の電車乗車時にも見れる。
書かれている内容に何らか規則性はない...?
トピックを見てると、技術に関係のないネタっぽいワードがちらほらあるので、時事ネタだったり、みんなが知ってるコンテンツを絡めたりするのがいいのかな?
そもそもモデルがちゃんとできていないので、また挑戦しています。
最後に
「いいね」が沢山ついているということは、たくさんの人に影響を与えた素晴らしい記事だとおもいます。
逆に「いいね」が少ないからといって悪い記事であるとは言うことはできないとおもいます(悪い記事である証明にはできない)。
見ての通り、「いいね」が10にも満たない記事はゴマンとありました。
実際のところこれまで私は「いいね」が10を超えたことないです。![]()
みんなそれでも記事を書くのです。「いいね」なんか関係ない。
変なこと考えて投稿しないよりかは投稿すれば何かしら役に立つかも知れないですし、たくさん書いて行きたいと思います。
そのうえで何が求められているのか考えて、質の高いアウトプットをするのは良いことだとおもいます。
P.S.
丁度こんな記事がトレンドに再浮上しておりました。
拝啓 本当は Qiita を書きたいのに、まだ迷っているあなたへ。
ステキです。