はじめに
純白のわたあめの舞う今日この頃皆様いかがお過ごしでしょうか?
某総合電機メーカ・某設計部門(機械設計)に属する 六花 牡丹(りっか ぼたん)と申します。
とある事情でこちらのサイトに不定期で記事を載せています。
本記事はKotoba Technologiesさんが発表された英語/日本語事前学習済みMamba2.8Bモデルの推論コードを提供するとともに、実装における注意点をお知らせすることを目的としています。
拙筆ではございますが、皆様のお役に立つことを心から願っております。
未熟者故、記事中にて誤記・欠落などが見られることがございます。
もし発見しました場合には、コメント等にてご指摘いただきますようお願い申し上げます。
六花牡丹のX(Twitter)アカウント
ここで最新の進捗や技術に関する情報(時々近況)を共有していきますで、
もしよろしければフォローなどお願いいたします。
執筆動機
執筆時点(2024年2月26日)において、各サイトでは、Kotoba technologiesさん公式の推論コードをそのまま利用した試みしかなされていないため、独自の推論コード・注意点を示し、より応用的な利用を促進するために執筆を行う。
対象とする読者
・Mambaというモデルの存在は知っている。
(下記に拙筆ではございますが、Mambaの概要を示した記事を添付します。
もし気になる方がいれば読んでみてください。)
・英語/日本語事前学習済みMamba2.8Bモデルで推論を行いたい。
・公式のコードをそのまま使うのではなく、推論コードを独自で改良・応用したい。
kotomambaを扱うための推論コードと注意点
本記事では下記の流れに沿って、解説を行なっていきます。
0.Mambaの特徴(概略説明)
1.今回開発した推論コード
2.工夫点・注意点・応用に向けた改良点
3.謝辞
4.最後に
参考論文・記事等(リンク)
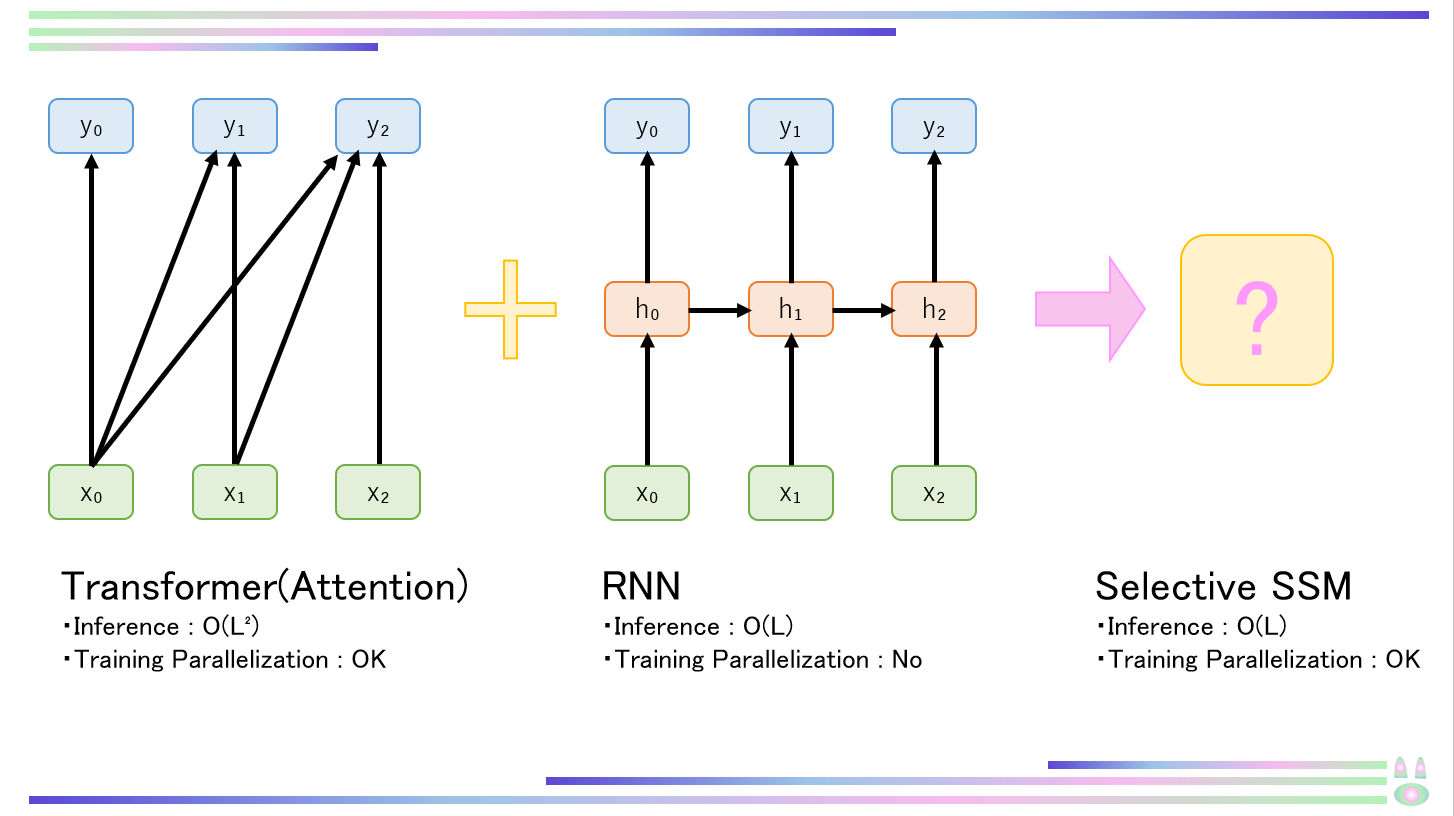
0.Mambaの特徴(概略説明)
MambaはAttentionやMLPblockを用いず、選択的状態空間モデル(Selective SSM:Selective State Space Model)という新しい構造を用いることで、必要な情報のみに注目し、計算効率の大幅な向上を達成した革新的なモデルです。
高速な推論(Transformerの約5倍)と高い精度(パラメータサイズ2倍のモデルと同程度)を可能にするとともに、シーケンス長(トークン数などのこと)の増大に対して、推論コストが線形に増大するため、シーケンス長が長い場合に有利です。
GPUメモリ階層間の移動を最小限化するとともに、ハードウェアに最適化された並列アルゴリズムにより高速な計算が可能になり、要求されるメモリ容量も軽減されます。

1.今回開発した推論コード
今回開発したkotomambaで推論を行うためのコードと出力例を下記に示します。
コメントを多く残していますので、初心者でも簡単に扱えるように工夫しています。
このコードはgoogle colabで動作させることを前提にしています。(2024年2月26日動作確認済み)
そのままコピペしても動作しますが、ご自身でパラメータ等は是非調整してみてください。
なお引用元をどこかに付けていただければ、商用・非商用問わずコピペで自由に使用していただいて構いません。
もし、上手く動作しない等の不具合がございましたら、コメント等でご指摘いただけますと幸いです。
注意点:このコードはgoogle colab無料版T4 GPUでも動作しますが、モデルのパラメータサイズが大きいため、何度か実行していると、メモリオーバー(RuntimeError: CUDA out of memory)になります。その場合はメニューのランタイムの「セッションを再起動する」をすると解消されます。
kotomamba推論のためのサンプルコード
# このコードはkotoba techさんのモデルを用いて文章生成を行うためのコードです。
# まず各ライブラリのインストールを行います。互換性のために一部ライブラリはバージョンを指定しています。
# バージョン指定はkotomambaの実装を参考にしています。今後colabのライブラリのバージョンが変更されるに従って
# このバージョン指定は変わる可能性があります(2024/2/25動作確認済み)。
# このコードはgoogle colab無料版のT4 GPUでも動作します。
!pip install wheel
!pip install transformers==4.36.2 torch causal-conv1d>=1.1.0
!pip install accelerate -U
# 普通の公式Mambaは!pip install mamba-ssm --no-build-isolation で大丈夫ですが、
# kotomambaでは辞書型の出力を得るために「return_dict」をTrueにする必要があります。
# しかし、なぜかMamba公式実装ではconfigが「MambaConfig」という通常Mambaのものに固定されてしまっており、
# モデル自体のconfigが読み込めない仕様になっています。
# そのため、kotoba techさんの実装した方の「mamba_ssm」を読み込む必要があります。
# まず、GitHubリポジトリをクローンし、ライブラリを読み込めるようにします。
!git clone https://github.com/kotoba-tech/kotomamba.git
# ライブラリが保存されているディレクトリを追加して、パス(システム上のつながり)を確保します。
import sys
sys.path.append("/content/kotomamba")
!ldconfig /usr/lib64-nvidia # libcuda.so not found! というエラーを防止するために入れています。特に理由がない場合はそのままにしておいてください。
# ここから必要なライブラリのimportを行います。
from transformers import LlamaTokenizer, AutoConfig
import torch
# kotomambaの公式リポジトリからこのモデルのために改良された「mamba_ssm」の中から、「MambaLMHeadModel」をインポートします。
from kotomamba.mamba_ssm.models.mixer_seq_simple import MambaLMHeadModel
# Tokenizerは適宜適切なもの(その時々で精度が高く、高速なもの)を選択してください。
# ちなみにTokenizerは文章をトークン化(その文字に対応する値化すること)してくれるものです。
tokenizer = LlamaTokenizer.from_pretrained("kotoba-tech/kotomamba-2.8B-v1.0", legacy=False)
# 処理の関係で文末を示すトークンを変更しています。
tokenizer.eos_token = "<|endoftext|>"
# PADトークンを文末を示すトークンに変えています。これは文長を揃える必要がなく、文が終わったらすぐに処理を終了してほしいからです。
tokenizer.pad_token = tokenizer.eos_token
# finetuned Mambaモデルの読み込みを行います。
model = MambaLMHeadModel.from_pretrained("kotoba-tech/kotomamba-2.8B-v1.0", device = "cuda", dtype = torch.float16)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 推論モードにします。
model.eval()
# 入力テキストは適宜変えてください。
inputs = tokenizer("慶應義塾大学とは", return_tensors="pt")['input_ids']
# ここでは、トークン(単語)を設定に従って生成します。各パラメータは下記に簡単に説明しているので、適宜変えてみてください。
with torch.no_grad():
tokens = model.generate(inputs.to(device),
max_length = 128, # 生成する最大トークン長を指定します。生成したい内容に応じて決めてください。
# max_lengthが大きいほど生成に時間がかかります。
return_dict_in_generate = True, # 辞書型の出力を得たいので、Trueにします。
temperature = 0.9, # temperatureは生成されるトークンの確率分布を指定します。
# temperatureが大きい場合は確率分布が平坦化され(トークン間の確率の差が小さくなり)、より多様な語が生成されやすくなります。
# 逆に小さい場合はより確からしいトークンしか生成されなくなります。
# 簡単に言えばトークンのバリエーションをどうしたいかを指定できます。
top_k = 1, # このパラメータは生成される確率の高い順上位⚪︎個のうちからトークンをランダムで生成することを表します。
# このパラメータによって生成されるトークンの選択肢が制限され、より品質の高い文を生成できるようになります。
top_p = 1.0, # このパラメータは生成される累積確率が一定値を超えたトークンのうちからランダムで生成することを表します。
# top_kと同様に品質の良い文を生成することにつながります。
repetition_penalty = 1.2 # この値が1より大きい場合、同じトークン(単語)が繰り返し生成されるのを防ぎます。
# 言語モデルでは確率に従ってトークンを生成するため、確率の高いトークンのみを繰り返し生成してしまう
# ということが稀に起きます。そのため、このパラメータで繰り返し生成を防止し、より「良い」出力を得ます。
# もし同じ単語が繰り返すようなことがあればこのパラメータを大きくしてみてください。
)
# トークンはtokensの中のsequencesの0番目のテンソルに格納されているため、これをデコードします。
output = tokenizer.decode(tokens.sequences[0])
print(output)
<s> 慶應義塾大学とは、日本の私立学校法人である。略称「慶早」(けいそう)、「早慶」とも呼ばれる[1]
下記にコードの実行確認をした際のライブラリバージョン一覧を示します。もしエラーが生じた場合はどこかのライブラリのバージョンが異なる場合がございますので、ご確認よろしくお願いいたします。
動作確認の取れた際のライブラリバージョン一覧
absl-py==1.4.0
accelerate==0.27.2
aiohttp==3.9.3
aiosignal==1.3.1
alabaster==0.7.16
albumentations==1.3.1
altair==4.2.2
annotated-types==0.6.0
anyio==3.7.1
appdirs==1.4.4
argon2-cffi==23.1.0
argon2-cffi-bindings==21.2.0
array-record==0.5.0
arviz==0.15.1
astropy==5.3.4
astunparse==1.6.3
async-timeout==4.0.3
atpublic==4.0
attrs==23.2.0
audioread==3.0.1
autograd==1.6.2
Automat==22.10.0
Babel==2.14.0
backcall==0.2.0
beautifulsoup4==4.12.3
bidict==0.23.0
bigframes==0.21.0
bleach==6.1.0
blinker==1.4
blis==0.7.11
blosc2==2.0.0
bokeh==3.3.4
bqplot==0.12.42
branca==0.7.1
build==1.0.3
buildtools==1.0.6
CacheControl==0.14.0
cachetools==5.3.2
catalogue==2.0.10
causal-conv1d==1.1.3.post1
certifi==2024.2.2
cffi==1.16.0
chardet==5.2.0
charset-normalizer==3.3.2
chex==0.1.85
click==8.1.7
click-plugins==1.1.1
cligj==0.7.2
cloudpathlib==0.16.0
cloudpickle==2.2.1
cmake==3.27.9
cmdstanpy==1.2.1
colorcet==3.0.1
colorlover==0.3.0
colour==0.1.5
community==1.0.0b1
confection==0.1.4
cons==0.4.6
constantly==23.10.4
contextlib2==21.6.0
contourpy==1.2.0
cryptography==42.0.3
cufflinks==0.17.3
cupy-cuda12x==12.2.0
cvxopt==1.3.2
cvxpy==1.3.3
cycler==0.12.1
cymem==2.0.8
Cython==3.0.8
dask==2023.8.1
dataclasses==0.6
datascience==0.17.6
db-dtypes==1.2.0
dbus-python==1.2.18
debugpy==1.6.6
decorator==4.4.2
defusedxml==0.7.1
distributed==2023.8.1
distro==1.7.0
dlib==19.24.2
dm-tree==0.1.8
docopt==0.6.2
docutils==0.18.1
dopamine-rl==4.0.6
duckdb==0.9.2
earthengine-api==0.1.390
easydict==1.12
ecos==2.0.13
editdistance==0.6.2
eerepr==0.0.4
einops==0.7.0
en-core-web-sm @ https://github.com/explosion/spacy-models/releases/download/en_core_web_sm-3.7.1/en_core_web_sm-3.7.1-py3-none-any.whl#sha256=86cc141f63942d4b2c5fcee06630fd6f904788d2f0ab005cce45aadb8fb73889
entrypoints==0.4
et-xmlfile==1.1.0
etils==1.7.0
etuples==0.3.9
exceptiongroup==1.2.0
fastai==2.7.14
fastcore==1.5.29
fastdownload==0.0.7
fastjsonschema==2.19.1
fastprogress==1.0.3
fastrlock==0.8.2
filelock==3.13.1
fiona==1.9.5
firebase-admin==5.3.0
Flask==2.2.5
flatbuffers==23.5.26
flax==0.8.1
folium==0.14.0
fonttools==4.49.0
frozendict==2.4.0
frozenlist==1.4.1
fsspec==2023.6.0
furl==2.1.3
future==0.18.3
gast==0.5.4
gcsfs==2023.6.0
GDAL==3.6.4
gdown==4.7.3
geemap==0.31.0
gensim==4.3.2
geocoder==1.38.1
geographiclib==2.0
geopandas==0.13.2
geopy==2.3.0
gin-config==0.5.0
glob2==0.7
google==2.0.3
google-ai-generativelanguage==0.4.0
google-api-core==2.11.1
google-api-python-client==2.84.0
google-auth==2.27.0
google-auth-httplib2==0.1.1
google-auth-oauthlib==1.2.0
google-cloud-aiplatform==1.42.1
google-cloud-bigquery==3.12.0
google-cloud-bigquery-connection==1.12.1
google-cloud-bigquery-storage==2.24.0
google-cloud-core==2.3.3
google-cloud-datastore==2.15.2
google-cloud-firestore==2.11.1
google-cloud-functions==1.13.3
google-cloud-iam==2.14.1
google-cloud-language==2.13.1
google-cloud-resource-manager==1.12.1
google-cloud-storage==2.8.0
google-cloud-translate==3.11.3
google-colab @ file:///colabtools/dist/google-colab-1.0.0.tar.gz#sha256=d928d5388ae74699834b6ed38534f830236b359d9fe8b3cd17a085c968e43d3a
google-crc32c==1.5.0
google-generativeai==0.3.2
google-pasta==0.2.0
google-resumable-media==2.7.0
googleapis-common-protos==1.62.0
googledrivedownloader==0.4
graphviz==0.20.1
greenlet==3.0.3
grpc-google-iam-v1==0.13.0
grpcio==1.60.1
grpcio-status==1.48.2
gspread==3.4.2
gspread-dataframe==3.3.1
gym==0.25.2
gym-notices==0.0.8
h5netcdf==1.3.0
h5py==3.9.0
holidays==0.42
holoviews==1.17.1
html5lib==1.1
httpimport==1.3.1
httplib2==0.22.0
huggingface-hub==0.20.3
humanize==4.7.0
hyperlink==21.0.0
hyperopt==0.2.7
ibis-framework==7.1.0
idna==3.6
imageio==2.31.6
imageio-ffmpeg==0.4.9
imagesize==1.4.1
imbalanced-learn==0.10.1
imgaug==0.4.0
importlib-metadata==7.0.1
importlib-resources==6.1.1
imutils==0.5.4
incremental==22.10.0
inflect==7.0.0
iniconfig==2.0.0
intel-openmp==2023.2.3
ipyevents==2.0.2
ipyfilechooser==0.6.0
ipykernel==5.5.6
ipyleaflet==0.18.2
ipython==7.34.0
ipython-genutils==0.2.0
ipython-sql==0.5.0
ipytree==0.2.2
ipywidgets==7.7.1
itsdangerous==2.1.2
jax==0.4.23
jaxlib @ https://storage.googleapis.com/jax-releases/cuda12/jaxlib-0.4.23+cuda12.cudnn89-cp310-cp310-manylinux2014_x86_64.whl#sha256=8e42000672599e7ec0ea7f551acfcc95dcdd0e22b05a1d1f12f97b56a9fce4a8
jeepney==0.7.1
jieba==0.42.1
Jinja2==3.1.3
joblib==1.3.2
jsonpickle==3.0.2
jsonschema==4.19.2
jsonschema-specifications==2023.12.1
jupyter-client==6.1.12
jupyter-console==6.1.0
jupyter-server==1.24.0
jupyter_core==5.7.1
jupyterlab_pygments==0.3.0
jupyterlab_widgets==3.0.10
kaggle==1.5.16
kagglehub==0.1.9
keras==2.15.0
keyring==23.5.0
kiwisolver==1.4.5
langcodes==3.3.0
launchpadlib==1.10.16
lazr.restfulclient==0.14.4
lazr.uri==1.0.6
lazy_loader==0.3
libclang==16.0.6
librosa==0.10.1
lightgbm==4.1.0
linkify-it-py==2.0.3
llvmlite==0.41.1
locket==1.0.0
logical-unification==0.4.6
lxml==4.9.4
malloy==2023.1067
Markdown==3.5.2
markdown-it-py==3.0.0
MarkupSafe==2.1.5
matplotlib==3.7.1
matplotlib-inline==0.1.6
matplotlib-venn==0.11.10
mdit-py-plugins==0.4.0
mdurl==0.1.2
miniKanren==1.0.3
missingno==0.5.2
mistune==0.8.4
mizani==0.9.3
mkl==2023.2.0
ml-dtypes==0.2.0
mlxtend==0.22.0
more-itertools==10.1.0
moviepy==1.0.3
mpmath==1.3.0
msgpack==1.0.7
multidict==6.0.5
multipledispatch==1.0.0
multitasking==0.0.11
murmurhash==1.0.10
music21==9.1.0
natsort==8.4.0
nbclassic==1.0.0
nbclient==0.9.0
nbconvert==6.5.4
nbformat==5.9.2
nest-asyncio==1.6.0
networkx==3.2.1
nibabel==4.0.2
ninja==1.11.1.1
nltk==3.8.1
notebook==6.5.5
notebook_shim==0.2.4
numba==0.58.1
numexpr==2.9.0
numpy==1.25.2
oauth2client==4.1.3
oauthlib==3.2.2
opencv-contrib-python==4.8.0.76
opencv-python==4.8.0.76
opencv-python-headless==4.9.0.80
openpyxl==3.1.2
opt-einsum==3.3.0
optax==0.1.9
orbax-checkpoint==0.4.4
orderedmultidict==1.0.1
osqp==0.6.2.post8
packaging==23.2
pandas==1.5.3
pandas-datareader==0.10.0
pandas-gbq==0.19.2
pandas-stubs==1.5.3.230304
pandocfilters==1.5.1
panel==1.3.8
param==2.0.2
parso==0.8.3
parsy==2.1
partd==1.4.1
pathlib==1.0.1
patsy==0.5.6
peewee==3.17.1
pexpect==4.9.0
pickleshare==0.7.5
Pillow==9.4.0
pins==0.8.4
pip-tools==6.13.0
platformdirs==4.2.0
plotly==5.15.0
plotnine==0.12.4
pluggy==1.4.0
polars==0.20.2
pooch==1.8.0
portpicker==1.5.2
prefetch-generator==1.0.3
preshed==3.0.9
prettytable==3.9.0
proglog==0.1.10
progressbar2==4.2.0
prometheus_client==0.20.0
promise==2.3
prompt-toolkit==3.0.43
prophet==1.1.5
proto-plus==1.23.0
protobuf==3.20.3
psutil==5.9.5
psycopg2==2.9.9
ptyprocess==0.7.0
py-cpuinfo==9.0.0
py4j==0.10.9.7
pyarrow==14.0.2
pyarrow-hotfix==0.6
pyasn1==0.5.1
pyasn1-modules==0.3.0
pycocotools==2.0.7
pycparser==2.21
pyct==0.5.0
pydantic==2.6.1
pydantic_core==2.16.2
pydata-google-auth==1.8.2
pydot==1.4.2
pydot-ng==2.0.0
pydotplus==2.0.2
PyDrive==1.3.1
PyDrive2==1.6.3
pyerfa==2.0.1.1
pygame==2.5.2
Pygments==2.16.1
PyGObject==3.42.1
PyJWT==2.3.0
pymc==5.7.2
pymystem3==0.2.0
PyOpenGL==3.1.7
pyOpenSSL==24.0.0
pyparsing==3.1.1
pyperclip==1.8.2
pyproj==3.6.1
pyproject_hooks==1.0.0
pyshp==2.3.1
PySocks==1.7.1
pytensor==2.14.2
pytest==7.4.4
python-apt @ file:///backend-container/containers/python_apt-0.0.0-cp310-cp310-linux_x86_64.whl#sha256=b209c7165d6061963abe611492f8c91c3bcef4b7a6600f966bab58900c63fefa
python-box==7.1.1
python-dateutil==2.8.2
python-louvain==0.16
python-slugify==8.0.4
python-utils==3.8.2
pytz==2023.4
pyviz_comms==3.0.1
PyWavelets==1.5.0
PyYAML==6.0.1
pyzmq==23.2.1
qdldl==0.1.7.post0
qudida==0.0.4
ratelim==0.1.6
redo==2.0.4
referencing==0.33.0
regex==2023.12.25
requests==2.31.0
requests-oauthlib==1.3.1
requirements-parser==0.5.0
rich==13.7.0
rpds-py==0.18.0
rpy2==3.4.2
rsa==4.9
safetensors==0.4.2
scikit-image==0.19.3
scikit-learn==1.2.2
scipy==1.11.4
scooby==0.9.2
scs==3.2.4.post1
seaborn==0.13.1
SecretStorage==3.3.1
Send2Trash==1.8.2
sentencepiece==0.1.99
shapely==2.0.3
simplejson==3.19.2
six==1.16.0
sklearn-pandas==2.2.0
smart-open==6.4.0
sniffio==1.3.0
snowballstemmer==2.2.0
sortedcontainers==2.4.0
soundfile==0.12.1
soupsieve==2.5
soxr==0.3.7
spacy==3.7.4
spacy-legacy==3.0.12
spacy-loggers==1.0.5
Sphinx==5.0.2
sphinxcontrib-applehelp==1.0.8
sphinxcontrib-devhelp==1.0.6
sphinxcontrib-htmlhelp==2.0.5
sphinxcontrib-jsmath==1.0.1
sphinxcontrib-qthelp==1.0.7
sphinxcontrib-serializinghtml==1.1.10
SQLAlchemy==2.0.27
sqlglot==19.9.0
sqlparse==0.4.4
srsly==2.4.8
stanio==0.3.0
statsmodels==0.14.1
sympy==1.12
tables==3.8.0
tabulate==0.9.0
tbb==2021.11.0
tblib==3.0.0
tenacity==8.2.3
tensorboard==2.15.2
tensorboard-data-server==0.7.2
tensorflow==2.15.0
tensorflow-datasets==4.9.4
tensorflow-estimator==2.15.0
tensorflow-gcs-config==2.15.0
tensorflow-hub==0.16.1
tensorflow-io-gcs-filesystem==0.36.0
tensorflow-metadata==1.14.0
tensorflow-probability==0.23.0
tensorstore==0.1.45
termcolor==2.4.0
terminado==0.18.0
text-unidecode==1.3
textblob==0.17.1
tf-keras==2.15.0
tf-slim==1.1.0
thinc==8.2.3
threadpoolctl==3.3.0
tifffile==2024.2.12
tinycss2==1.2.1
tokenizers==0.15.2
toml==0.10.2
tomli==2.0.1
toolz==0.12.1
torch @ https://download.pytorch.org/whl/cu121/torch-2.1.0%2Bcu121-cp310-cp310-linux_x86_64.whl#sha256=0d4e8c52a1fcf5ed6cfc256d9a370fcf4360958fc79d0b08a51d55e70914df46
torchaudio @ https://download.pytorch.org/whl/cu121/torchaudio-2.1.0%2Bcu121-cp310-cp310-linux_x86_64.whl#sha256=676bda4042734eda99bc59b2d7f761f345d3cde0cad492ad34e3aefde688c6d8
torchdata==0.7.0
torchsummary==1.5.1
torchtext==0.16.0
torchvision @ https://download.pytorch.org/whl/cu121/torchvision-0.16.0%2Bcu121-cp310-cp310-linux_x86_64.whl#sha256=e76e78d0ad43636c9884b3084ffaea8a8b61f21129fbfa456a5fe734f0affea9
tornado==6.3.2
tqdm==4.66.2
traitlets==5.7.1
traittypes==0.2.1
transformers==4.36.2
triton==2.1.0
tweepy==4.14.0
Twisted==23.10.0
typer==0.9.0
types-pytz==2024.1.0.20240203
types-setuptools==69.1.0.20240217
typing_extensions==4.9.0
tzlocal==5.2
uc-micro-py==1.0.3
uritemplate==4.1.1
urllib3==2.0.7
vega-datasets==0.9.0
wadllib==1.3.6
wasabi==1.1.2
wcwidth==0.2.13
weasel==0.3.4
webcolors==1.13
webencodings==0.5.1
websocket-client==1.7.0
Werkzeug==3.0.1
widgetsnbextension==3.6.6
wordcloud==1.9.3
wrapt==1.14.1
xarray==2023.7.0
xarray-einstats==0.7.0
xgboost==2.0.3
xlrd==2.0.1
xxhash==3.4.1
xyzservices==2023.10.1
yarl==1.9.4
yellowbrick==1.5
yfinance==0.2.36
zict==3.0.0
zipp==3.17.0
zope.interface==6.2
2.工夫点・注意点・応用に向けた改良点
推論コードを構築する上で最も障害となったのは、Mamba公式さんの提供するMambaLMHeadModelではconfigが固定されており、使用したいモデルのconfigが読み込めないために、そこで齟齬が生じて、エラーとなってしまうという点でした。
特に、"return_dict"が定義されていなく、"unexpected"となってしまいます。
そのため、このコードでは、Kotoba Technologiesさんが改良した"mamba_ssm"からモジュールをインポートして使っています。
(以上の点から今のところ、kotomambaからgit cloneしている部分は変更しないようお願いします。)
(Mamba公式さんには是非configが自由に指定可能となるように改善をお願いしたいところです...)
このコードでは機械学習を用いた経験が浅い方でも出力の工夫ができるように、主要なパラメータの説明を付記しています。パラメータによって微妙に出力が異なりますので、是非ご自身で工夫してみてください。
応用へ向けた点としては、①各種量子化(モデルの軽量化)を試みること、②出力されたトークンをそのままデコードするのではなく他のモデルへの入力とすること、③中間層の特徴量を取り出して何らかの処理に利用することなどが挙げられると思います。
①と③は少し敷居が高いですが、②に関しては比較的簡単に行えると思います。(コードを数行くらい削減する意味しかないかもしれません...)
今回の試みの意味としては、推論コード作成・改善の障害となっている点を明らかにし、後の開発の助けとすることだと考えています。
3.謝辞
この記事を書くにあたって、まずMambaを開発してくださったAlbert Gu, Tri Daoには深く感謝いたします。また、kotomambaを開発し、さらに各種コードまで公開してくださったKotoba Technologiesさんに深く感謝いたします。Mambaは素晴らしいモデルですが、このモデルを実装できているのは多くの先人の方が作ってきてくださったライブラリやデバイスがあってのことです。先人たちの営みに深い敬意を表すとともに感謝いたします。最後にここまで読んでくださった読者の皆様に感謝いたします。
4.最後に
Mambaがさらに注目されつつあり、今後もより応用的な研究開発が加速していくと考えています。kotomambaようなモデルを公開してくださる組織の方には頭が上がりません。微力ではありますが、今後も日本国の研究開発に少しでも寄与できるように精進していきたいと感じます。
参考論文・記事等(リンク)
*1 'Mamba: Linear-Time Sequence Modeling with Selective State Spaces', https://arxiv.org/pdf/2312.00752.pdf
Mambaの原論文です。
*2 'Mamba', https://github.com/state-spaces/mamba
Mambaのgithubリポジトリです。
*3 'kotomamba', https://github.com/kotoba-tech/kotomamba
kotomambaのgithubリポジトリです。
*4 'Kotomamba: mamba-2.8B 学習知見, https://zenn.dev/kotoba_tech/articles/f15b2495d44c4f
Kotoba Technologiesさんがkotomamba作成の際の工夫点などを説明している記事です。
*5 'kotoba-tech/kotomamba-2.8B-CL-v1.0, https://huggingface.co/kotoba-tech/kotomamba-2.8B-CL-v1.0
kotomamba-2.8B-CL-v1.0を公開しているページです。
*6 'kotoba-tech/kotomamba-2.8B-v1.0', https://huggingface.co/kotoba-tech/kotomamba-2.8B-v1.0
kotomamba-2.8B-v1.0を公開しているページです。
書いた人:六花牡丹(りっかぼたん)
某総合電機メーカに務める謎の人物(自称)。
おさげとハーフツインが好きで、基本的にふわふわしている変わり者。
結構ドジで何もないところで転ぶタイプ。
人工知能に関しては独学のみ。