![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()

はじめに
落葉が風に踊り、夕暮れが一段と深みを増す今日この頃、皆様いかがお過ごしでしょうか?
六花 牡丹(りっか ぼたん)と申します ![]()
本記事は、SLC2という独自モジュールを使用することで、学習時間30分・コスト$10以上削減し、かつ推論コストも削減したモデルを構築できるリポジトリを開発したため、そのご紹介記事となります。
また、日本語・英語バイリンガルモデルの構築も可能なリポジトリも公開しています。
詳しい数学的背景は、Advent Calendar 2025の他の記事で説明するため、本記事は初心者向けの紹介という位置づけです。
Nanochatとは?
NanochatはAndrej Karpathyさんが公開したオープンソース・リポジトリで、たった100ドルでChatGPTのような言語モデルを構築することができます。
特に、事前学習・中間学習・事後学習までをたった数コマンドで実行してくれるため、教育目的での使用に適しています。
🌸リポジトリ
英語モデル:
日本語・英語バイリンガルモデル:
🌸 Saint Iberis の構造
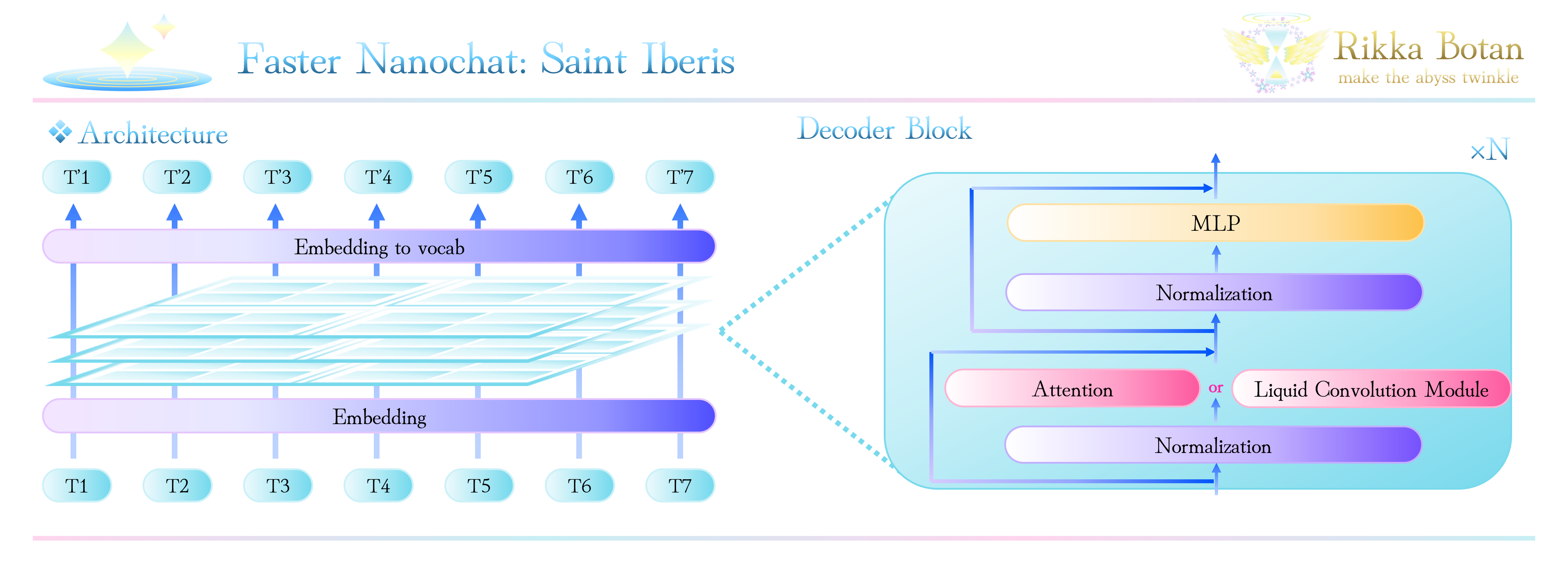
| Property | Saint Iberis d20 | Remarks |
|---|---|---|
| Total parameters | 542,035,200 (542M) | n_layer: 20, n_head: 10, n_kv_head: 10, n_embd: 1280 |
| Layers | 20 (13 slc2 + 7 attn) | attn layers: 1, 4, 7, 10, 13, 16, 19 |
| Vocabulary size | 65,536 | - |
| Training budget | 100B tokens | Fineweb edu |
| License | MIT | - |
Attention層が約30%程度となっているのは、LFM2などの複合モデルを参考に決定しています。
私の実験でも、この割合が最もパフォーマンス・コストのバランスが良かったため採用しています。
🌸 SLC2 Formulation
y = B \odot \Pi_{i=j}^{j+k} A_i \cdot x_i
詳しい挙動・数学的背景については、他の記事で解説を行う予定です。
🌸 SLC2 擬似コード
----------------------------------------
Algorithm: SLC2
----------------------------------------
Input: x: (B, S, E)
Output: y: (B, S, E)
1: alpha, A, B, x₁ <- Linear(x)
2: x₂: (B, S, E) <- Convolution1D(E, E)(SiLU(alpha)*A*x₁)
3: x₃: (B, S, E) <- B*SiLU(x₂)
4: y: (B, S, E) <- Linear(x₃)
5: return y
----------------------------------------
🌸 使い方
本記事のリポジトリは、nanochatと同様にLambda Cloudでの使用を推奨しています。(GPUサーバーの料金が低いため)
下記のような画面で、まず、Settingsからアカウント設定や支払い方法の設定等を済ませておきます。
終わったらInstancesから使用したいGPUを選択します。
このリポジトリは8×H100 GPUを使用するため、この場合は一番上を選択します。
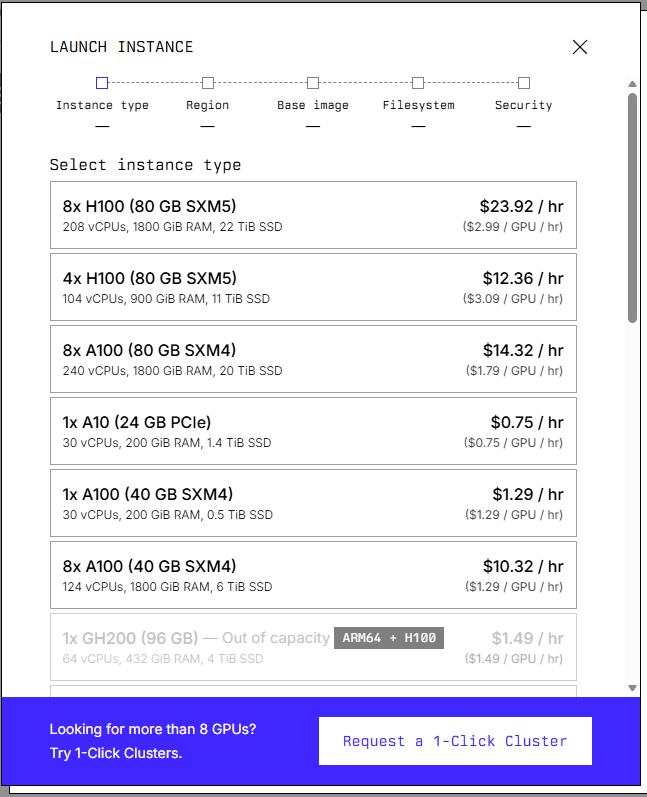
Regionはこだわりがなければ適当でも問題ありません。
(ファイルシステムを使用する場合は、設定してください)
Image familyはデフォルトのまま、このリポジトリを使用するだけであれば、ファイルシステムも必要ありません。
10分ほどするとbootingからLaunchに変わり、GPUが使用可能になります。
次に、リポジトリをインストールします。
git clone https://github.com/Rikka-Botan/Liquid_Time_nanochat.git
次に、下記のコマンドで学習・評価を実施します。
下記のコマンドでは、事前学習・中間学習・事後学習が一連の流れで行われ、約3.5時間実行されます。
cd
cd Liquid_Time_nanochat
pwd
bash speedrun.sh
学習が終了したら、下記コマンドでUIを開いて試すことができます。
source .venv/bin/activate
python -m scripts.chat_web

もし、jupiter notebookで実行した場合は、下記のコードでHugging Faceリポジトリに重みや評価結果一覧を保存できます。
適宜リポジトリ名等は変更してください。
from huggingface_hub import login, upload_folder
login(token="your token")
upload_folder(
folder_path="/home/ubuntu/.cache/nanochat/chatsft_checkpoints/d20",
path_in_repo="model", # Default model checkpoint name
repo_id="RikkaBotan/nanochat_d20_saint_iberis", # Replace with your username/repo name
repo_type="model"
)
upload_folder(
folder_path="/home/ubuntu/.cache/nanochat/tokenizer",
path_in_repo="tokenizer", # Default model checkpoint name
repo_id="RikkaBotan/nanochat_d20_saint_iberis", # Replace with your username/repo name
repo_type="model"
)
upload_folder(
folder_path="/home/ubuntu/.cache/nanochat/report",
path_in_repo="report", # Default model checkpoint name
repo_id="RikkaBotan/nanochat_d20_saint_iberis", # Replace with your username/repo name
repo_type="model"
)
🌸 ダウンストリームタスクのパフォーマンス
| Metric | BASE | MID | SFT | RL |
|---|---|---|---|---|
| CORE | 0.1796 | - | - | - |
| ARC-Challenge | - | 0.2910 | 0.2782 | - |
| ARC-Easy | - | 0.3792 | 0.3864 | - |
| GSM8K | - | 0.0341 | 0.0455 | - |
| HumanEval | - | 0.0732 | 0.0549 | - |
| MMLU | - | 0.3146 | 0.3166 | - |
| ChatCORE | - | 0.2348 | 0.2322 | - |
| Total wall clock time: 3h15m |
🌸 nanoGPTとの比較
| Metric | GPT(karpathy/nanochat) | Saint Iberis |
|---|---|---|
| Total wall clock time | 3h51m | 3h15m |
| ARC-Challenge | 0.2807 | 0.2782 |
| ARC-Easy | 0.3876 | 0.3864 |
| HumanEval | 0.0854 | 0.0549 |
| MMLU | 0.3151 | 0.3166 |
| ChatCORE | 0.0844 | 0.2322 |
| Task Average | 0.1998 | 0.2190 |
タスクの平均はnanoGPTより若干高く、学習に必要な時間は削減されています。
🌸 トレーニング結果
Base Training
- Minimum validation bpb: 0.8287
- Final validation bpb: 0.8287
Mid Training
- Minimum validation bpb: 0.4116
SFT Training
- Training loss: 0.5825
- Validation loss: 1.0657
🌸 モデルの使用方法
このリポジトリで学習後の重みは公開しています。
モデルは下記のコードで推論できます。
なお、torch.compile()を使用して学習した場合は、prefixに_orig_mod.が含まれるため削除する必要があります。
import os
import sys
import torch
import json
import time
from huggingface_hub import hf_hub_download
if not os.path.exists("Liquid_Time_nanochat"):
os.system("git clone https://github.com/Rikka-Botan/Liquid_Time_nanochat")
os.chdir("Liquid_Time_nanochat")
sys.path.append(os.getcwd())
from nanochat.gpt import GPT, GPTConfig
from nanochat.tokenizer import RustBPETokenizer
repo_id = "RikkaBotan/nanochat_d20_saint_iberis"
model_file = "model_000700.pt"
meta_file = "meta_000700.json"
tokenizer_file = "tokenizer.pkl"
local_pt_path = hf_hub_download(repo_id=repo_id, filename=model_file)
local_meta_path = hf_hub_download(repo_id=repo_id, filename=meta_file)
local_tokenizer_path = hf_hub_download(repo_id=repo_id, filename=tokenizer_file, local_dir=os.getcwd())
with open(local_meta_path, "r", encoding="utf-8") as f:
meta_data = json.load(f)
model_config = GPTConfig(**meta_data["model_config"])
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = GPT(model_config).to(device)
state_dict = torch.load(local_pt_path, map_location=device)
state_dict = {k.removeprefix("_orig_mod."): v for k, v in state_dict.items()}
model.load_state_dict(state_dict, strict=True)
model.eval()
tokenizer = RustBPETokenizer.from_directory(os.getcwd())
try:
tokenizer.bos_token_id = tokenizer.enc.encode_single_token("<|bos|>")
except KeyError:
tokenizer.bos_token_id = tokenizer.enc.encode_single_token("<|endoftext|>")
tokenizer.user_start_id = tokenizer.enc.encode_single_token("<|user_start|>")
tokenizer.user_end_id = tokenizer.enc.encode_single_token("<|user_end|>")
tokenizer.assistant_start_id = tokenizer.enc.encode_single_token("<|assistant_start|>")
tokenizer.assistant_end_id = tokenizer.enc.encode_single_token("<|assistant_end|>")
tokenizer.stop_tokens = {tokenizer.assistant_end_id, tokenizer.bos_token_id}
def format_conversation(tokenizer, history):
tokens = [tokenizer.bos_token_id]
for message in history:
role = message["role"]
content = message["content"]
content_tokens = tokenizer.encode(content)
if role == "user":
tokens.extend([tokenizer.user_start_id, *content_tokens, tokenizer.user_end_id])
elif role == "assistant":
tokens.extend([tokenizer.assistant_start_id, *content_tokens, tokenizer.assistant_end_id])
tokens.append(tokenizer.assistant_start_id)
return tokens
def generate_reply(prompt, conv_history, temperature=0.7, top_k=20, top_p=0.8,
repetition_penalty=1.15, max_new_tokens=64):
conv_history.append({"role": "user", "content": prompt})
tokens = format_conversation(tokenizer, conv_history)
input_ids = torch.tensor(tokens, dtype=torch.long).unsqueeze(0).to(device)
stream = model.generate(
input_ids,
max_new_tokens=max_new_tokens,
temperature=temperature,
top_k=top_k,
top_p=top_p,
repetition_penalty=repetition_penalty,
)
buffer_text = ""
for token_id in stream:
text_piece = tokenizer.decode([token_id])
if text_piece == "<|assistant_end|>":
break
buffer_text += text_piece
conv_history.append({"role": "assistant", "content": buffer_text})
return buffer_text
if __name__ == "__main__":
print("🌸 NanoChat - Saint Iberis CLI")
print("Type 'exit' to quit.\n")
conv_history = []
while True:
prompt = input("You: ")
if prompt.lower() in {"exit", "quit"}:
print("Goodbye!")
break
reply = generate_reply(prompt, conv_history)
print(f"AI: {reply}\n")
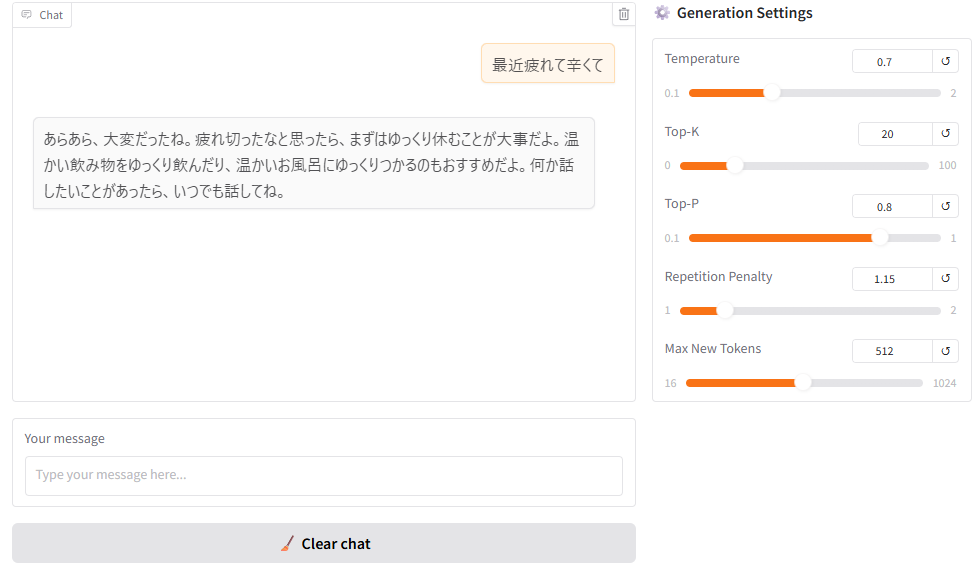
🌸 日本語・英語バイリンガルモデル
共感と寄り添う姿勢をモデルに与えるために独自のSFTデータセットを作成し、学習させています。
これにより、知識だけではなく、ユーザーに寄り添うことを可能にします。
下記は出力例です。
参考
執筆者:六花 牡丹(りっか ぼたん)
おさげとハーフツイン・可愛いお洋服が好きで、基本的にふわふわしている変わり者。
結構ドジで何もないところで転ぶタイプ。
人工知能に関しては独学のみ。
最近、展示会などで人見知り過ぎてうまく仲良くなれないので、もっと頑張って話しかけないと!という気持ちになっている。
