はじめに
この記事は 2020 年の RevComm アドベントカレンダー 1 日目の記事です。
皆さん、はじめまして株式会社Revcommの彭(ホウ)です。
アニメ声優の演技が昔から好きで、それをきっかけに声に興味を持ち始め、
現在は音声合成の仕事に携わっています。。
声の秘密についてどれほど知っていますか?
音声の特徴を変えてみて、どのような声になるか試してみたいと思ったことはないですか?
この記事では、抑揚の強さを変えてみて、どのような音声を生成できるかを紹介したいと思います。
この記事で扱うこと
- 波形図の作成
- スペクトログラムの作成
- 基本周波数(F0)抽出
- 基本周波数(F0)の分散調整・再合成
- 基本周波数(F0)の補間・再合成
この記事でしないこと
音声音響の基本概念の紹介
音声音響の基本概念はここでは割愛しますが、ご興味をお持ちの方はこちらをご参照ください。
音声の音響分析の「いろは」
事前準備
使ったのは自分が録音した16kHzの音声ファイルで、音声内容が「アイウエオ」です。
import pyworld as pw
import numpy as np
import matplotlib.pyplot as plt
import soundfile as sf
from scipy.interpolate import interp1d
from scipy.io import wavfile
Pyworld:Python-Wrapper-for-World-Vocoder
Pyworldを使うことで、音声から三つの特徴量(基本周波数F0、スペクトル包絡sp、非周期性成分ap)を抽出することができます。
今回は主に基本周波数F0を巡って、、F0の途切れた箇所を補間したり、分散を調整したりすることで、音声を変えます。
F0を編集した後、Pyworldを使うことで、三つの特徴量から音声を合成します。
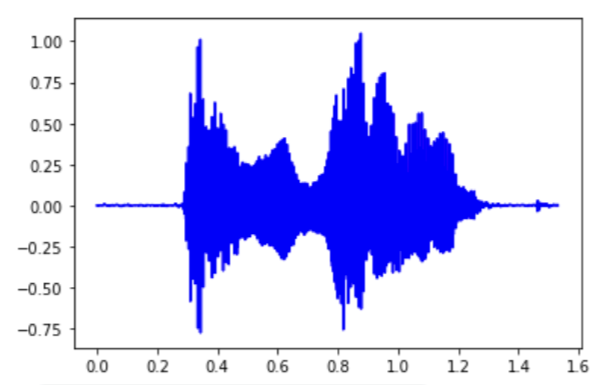
波形図を描く
sr, y = wavfile.read(filename) # 周波数と振幅値の抽出
x = [q/sr for q in np.arange(0, len(y), 1)]
plt.plot(x,y, color="blue")
plt.show()
スペクトログラムを描く
plt.specgram(y,Fs=sr) # スペクトログラムを描く
plt.xlabel('Time')
plt.ylabel('Frequency')
plt.show()
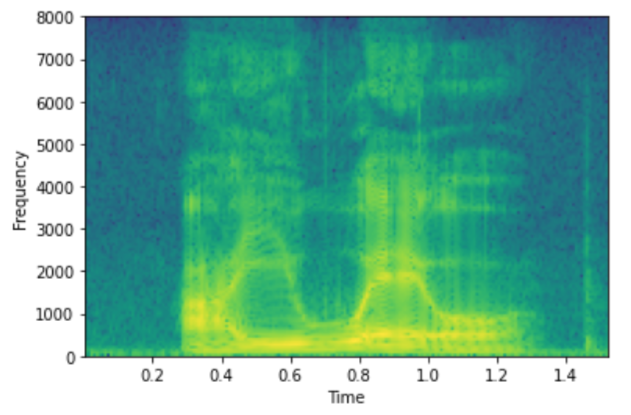
言い伝えによりますと、真の音声処理マスターはスペクトログラムから音声の内容を理解できます。
私は無理ですが、あなたはどうですか?
基本周波数(F0)抽出
y = y.astype(np.float)
_f0, _time = pw.dio(y, sr)
f0 = pw.stonemask(y, _f0, _time, sr)
plt.plot(f0, linewidth=3, color="green", label="F0 contour")
plt.legend(fontsize=10)
plt.show()
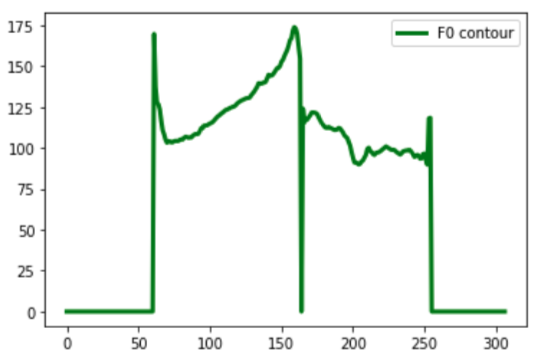
横軸は時間で、縦軸は周波数です。
基本周波数(F0)の調整
F0の平均値を保つまま分散を調整することで、音声の抑揚を変えられます。
今回はパラメーター「-4.5」にします。
すると、抑揚が抑えられ、より平坦な音声になります。
もし更に小さい数値にしますと、音声はより機械音っぽく聞こえます。
F0分散が小さくなった音声
f0_scaler = -4.5 ## 抑揚を強める場合、プラスに、弱める場合、マイナスにします
f0_mean = np.mean([x for x in f0 if x!=0])
f0_std = np.std([x for x in f0 if x!=0])
f0_modified = []
for i in f0:
# print(i)
if i != 0:
if f0_scaler > 0:
if i > f0_mean:
single_f0_new = i + f0_std * f0_scaler * ((i-f0_mean)/f0_mean)
elif i < f0_mean:
i_new = i - f0_std * f0_scaler * ((f0_mean-i)/f0_mean)
if i_new > 0:
single_f0_new = i_new
else:
single_f0_new = 1
else:
single_f0_new = i
else:
if i > f0_mean:
i_new = i + f0_std * f0_scaler * ((i-f0_mean)/f0_mean)
if i_new > f0_mean:
single_f0_new = i_new
else:
single_f0_new = f0_mean
elif i < f0_mean:
i_new = i - f0_std * f0_scaler * ((f0_mean-i)/f0_mean)
if i_new < f0_mean:
single_f0_new = i_new
else:
single_f0_new = f0_mean
else:
single_f0_new = i
else:
single_f0_new = i
f0_modified.append(single_f0_new)
plt.plot(f0_modified, linewidth=3, color="red", label="F0_modified contour")
plt.legend(fontsize=10)
plt.show()
f0_array = np.asarray(f0_modified)
synthesized = pw.synthesize(f0_array, sp, ap, sr)
synthesized_normalized = synthesized/(np.nanmax(np.abs(synthesized)))
sf.write("./output.wav",synthesized_normalized,16000)
修正後のF0は以下の図に示します。
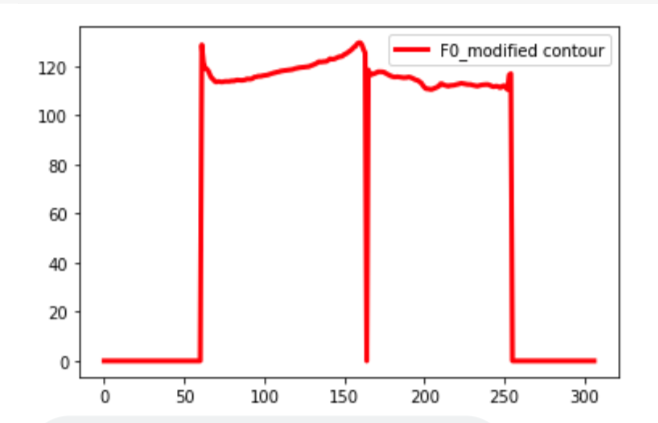
上手くF0平均値(120くらい)とF0折り線の形を保ったまま分散を減らしました
基本周波数(F0)の補間
実際、(騒音などの原因で)Pyworldによって抽出されたF0が常に連続しているわけではありません。
F0系列には推定できない部分もあります。
その場合、音声があるのに、F0の一部は「0」になってしまいます。
その部分に当たって、合成音声には雑音が入ってきます
それを解決するにはF0を補間する必要があります。
次はオリジナルF0系列の一部を「0」にすることで、シミュレーションします。
pre_inter_file = "pre-interpolation.wav"
pre_interf0 = f0
for i in range(150, 170):
pre_interf0[i] = 0
for i in range(210, 230):
pre_interf0[i] = 0
plt.plot(pre_interf0, linewidth=3, color="blue", label="pre-interpolation_F0 contour")
plt.legend(fontsize=10)
plt.show()
sp = pw.cheaptrick(y, pre_interf0, _time, sr)
ap = pw.d4c(y, pre_interf0, _time, sr)
synthesized = pw.synthesize(pre_interf0, sp, ap, sr)
synthesized_normalized = synthesized/(np.nanmax(np.abs(synthesized)))
sf.write(pre_inter_file,synthesized_normalized,16000)
すると、途切れのあるF0系列は以下になります。
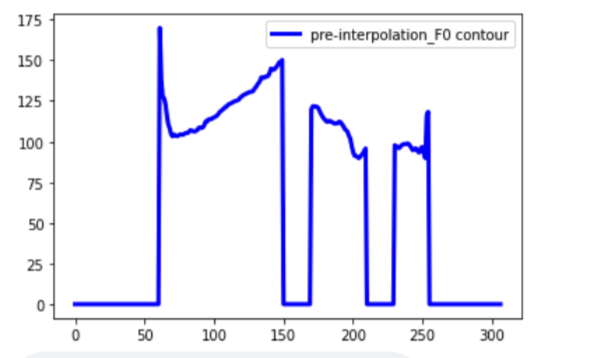
非連続F0によって合成された音声
F0系列に途切れた部分がある場合、F0、SP、APにより再合成された音声に騒音が聞こえます。
やはりF0の補間は必要不可欠ですね。
ここでscipyの補間関数interp1dで補間します。
補間種類には線形補間、最近傍補間、一次スプライン補間・二次スプライン補間・三次スプライン補間などがあります。
ここでは一次スプライン補間(slinear)を例にします。
手順は以下になります。
class Interpolator():
def __init__(self, y_array):
self.x_observed = []
self.y_observed = []
self.x_valid = []
self.y_valid = []
self.x_to_inter = []
self.y_to_inter = []
self.start_flag = 0
self.end_flag = -1
self.y_interpolated = []
for i in range(len(y_array)):
self.x_observed.append(i)
self.y_observed.append(y_array[i])
# get start position (first non-0)
for i in range(len(y_array)):
if y_array[i] == 0:
continue
else:
self.start_flag = i
break
# get end position (last non-0)
y_array_ = y_array[::-1]
for i in range(len(y_array)):
if y_array_[i] == 0:
continue
else:
self.end_flag = -i - 1
break
self.x_valid = self.x_observed[self.start_flag : len(y_array) + self.end_flag]
self.y_valid = self.y_observed[self.start_flag : len(y_array) + self.end_flag]
def pre_interpolate_points(self):
self.x_to_inter = []
self.y_to_inter = []
for i in range(len(self.y_valid)):
if self.y_valid[i] == 0:
continue
else:
self.x_to_inter.append(self.x_valid[i])
self.y_to_inter.append(self.y_valid[i])
def ip_curve(self):
inter_func = interp1d(self.x_to_inter, self.y_to_inter, kind='slinear')
# print(type(inter_func(self.x_valid).flatten()))
self.y_interpolated = [0]*self.start_flag + inter_func(self.x_valid).flatten().tolist()
self.y_interpolated = self.y_interpolated +[0]*(-self.end_flag)
return self.y_interpolated
def clear(self):
self.x_observed = []
self.y_observed = []
self.x_valid = []
self.y_valid = []
self.x_to_inter = []
self.y_to_inter = []
self.start_flag = 0
self.end_flag = -1
self.y_interpolated = []
pro_inter_file = "./pro-interpolation.wav"
a = Interpolator(pre_interf0.tolist())
a.pre_interpolate_points()
pro_interf0 = np.array(a.ip_curve())
a.clear()
plt.plot(pro_interf0, linewidth=3, color="red", label="pro-interpolation_F0 contour")
plt.legend(fontsize=10)
plt.show()
pro_intersp = pw.cheaptrick(y, pro_interf0, _time, sr)
pro_interap = pw.d4c(y, pro_interf0, _time, sr)
synthesized = pw.synthesize(pro_interf0, pro_intersp , pro_interap, sr)
synthesized_normalized = synthesized/(np.nanmax(np.abs(synthesized)))
sf.write(pro_inter_file,synthesized_normalized,16000)
補間されたF0系列は以下になります。
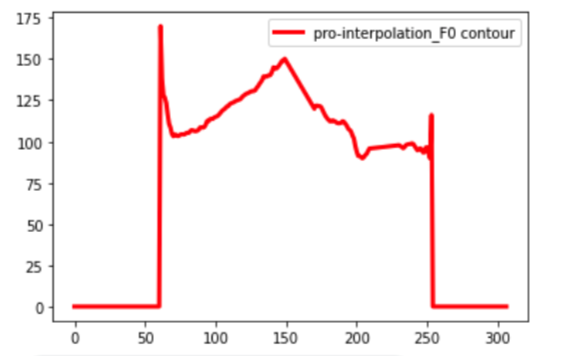
補間されたF0、sp、apは順次に計算されます。
三つの特徴量によって合成された音声は騒音が消えて、綺麗な音声になります。
補間されたF0による合成音声
最後に
これで、音声の解析と再合成は完了しました。
音声合成(Text-To-Speech)において、F0,sp,apは音響モデルを作るのに重要な特徴量です。
この三つの特徴量を調整することで、合成音声を幅広くチューニングできます。
例えば、合成する際にF0を高くする場合、合成音声は高くなって男性声を女性声っぽく変えられます。
この度、F0だけを対象にしていましたが、機会があれば今度spとapの調整効果もシェアしたいです。
明日は、515hikaruさんの「ワンライナー仕事術: 日常業務におけるシェルコマンド活用法」です。お楽しみに!
ではでは〜!