Chainer Advent Calendar 2016の12日目です。
現在、11日の午後6時、ようやく実装を終えAWSで学習を回し始めたら、あと14時間かかるとの事\(^o^)/
NEW コード公開しました!(注:いろいろリファクタリングしたので、動かなかったらごめんなさい。隙を見て動作確認予定。ドキュメントが無いです、すみません。)
https://github.com/peisuke/vin
記事について
本記事では、機械学習のTop-ConferenceであるNIPSの2016年開催分(先週!)において、Best Paper Awardをとった論文の解説と、それをChainerで実施してみた結果について書きます。
しかしながら、Awardを取ったのを知ってから論文を読み始めたので、上にありますようにギリギリスケジュールでして、まだ実験結果が出ていません・・・。なので、論文の内容を多めに・・・。また、ちょっと遅れる事になりますが、必ず実験結果を載せます、多分。
なんとか実験結果を載せました!
背景
論文で扱う問題は下図にあるような、ロボットが環境内を移動するにあたり、地図上のスタートとゴールを決めておき、その最短パスを見つけるというものです。もちろん、そのような問題は古くからやられていますが、過去の研究は環境とロボットのモデルが既知であるという前提が必要です。実際はロボットのモデルを完全に記述することはできないので、その辺を学習でやってしまうことでモデル化無しに経路探索ができるようになることが狙いです。

ロボットが環境内で動作する時に、次に取るべく行動は将来の環境変化を加味して考えないといけません。Value Iteration(価値反復)とは、現在の状態の報酬値(目的を達成した、ゴールに近づいた、等)に加え、仮に動作を1ステップ進めた次の状態の報酬値を加え、この処理を反復する事で、将来的にロボットの現状がどのくらい良い状態か、どのように次に動けば良いかなどが分かる、というものです。
ただし、現在の状態の真の報酬値を事前計算する事は容易な事ではありません。なぜなら、ゴールしてようやく報酬値を得られるため、ゴールまでの全動作手順を計算する必要があるからです。環境の全状況変化、ロボットのモデルなどが完璧にシミュレーションでき、かつ大量の計算処理を実行すれば実現できますが、これが可能なケースは非常に少ないです。そこで、Deep Learningを利用し、状況に対して適切な将来報酬を学習してやることで、上記シミュレーションや大量の計算を避けることができると考えられ、様々な手法が研究されてきました。
特に有名な方法としてはDeep Q-Networkが挙げられます。これは強化学習という方法を使い、ロボットが自ら環境内での動作を施行錯誤し、どのような状況で、どのような行動を取れば良かったかを記憶するものです。ところがDeep Q-Networkは所定の環境に対して施行錯誤するため、環境が変わると学習結果を転用できないという問題がありました。なお、施行錯誤を別環境にまで広げれば解決できるのではないか?という事も考えられますが、今回の論文内で実験を通して精度が上がらない事が報告されていました。さて、別の手段としては、Imitation Learning(マネによる学習)が挙げられます。こちらは施行錯誤せず、エキスパートの動作を直接真似ることで、取るべき行動を学習するものです。余計な施行錯誤をしないで済む分、学習は容易になります。一方で、やはりこちらも環境変化に対して上手く適用できないという問題が残ります。
そもそも、ロボットや環境のモデルを人手で与えず、新しい環境なのに関わらず将来を見越して学習ベースで動作を決定するというのは、情報が少ない中で周囲を適切に予測する必要があるため、結構難しいのです。そんな事がもし出来るならば、学習レス・プログラミングレスで空気を読んで動作するロボットが実現できてしまいます。
なんと、できてしまったらしい。
という事で。読みました。
Aviv Tamar, Yi Wu, Garrett Thomas, Sergey Levine, and Pieter Abbeel, "Value Iteration Networks", NIPS 2016.
そして著者もそうそうたる面子、S. Levine, and P. Abbeel
Value Iteration Networksについて
すみません、前置きが長くなりました。この研究、僕もトライして失敗していたので悔しかったもので。さて、Value Iteration Networkとは、簡単に言うと、(1)入力状態からCNNで報酬を推定、(2)自身の取った動作に応じて報酬をweight shareingなCNN伝播させ、(3)推定したい注目位置の報酬のみ切り取って、(4)全結合により動作を決定する、という構造になっています。なお、式は書くのが大変なので、省略します。

論文中の上図で言えば、観測$\phi(s)$が入力画像に対してCNNをかけた結果、これを推定報酬$\bar{R}$に入れてやります。なお、$\bar{P}$は状態$s$に対し、行動$a$を与えたらどのように状態が変わるかの変換なのですが、今回の問題では状態の変化は既知として無視します。VIモジュールは、与えられた推定報酬マップからどちらに動いたらどのくらい報酬が貯まっていくかを計算するもので、後述します。次の枠の「Attention」とは、画像のどの辺に注目しようか、という切り出し部となります。普通のDeep Learningでは画面全体からFC層に繋げる事が多いのですが、パラメータが増えてしまい大変です。これに対し、画面のどの辺に欲しい情報が詰まっているかがわかるならば、その領域だけターゲットにすることで、計算を容易にできます。この場合は、ロボットの自己位置に次の移動方向を決めるための、報酬情報が足し合わさっているので、ロボットの位置$s$をターゲットとします。最後に、その報酬情報から行動情報にFC層を使って繋ぎ合わせます。結果として、どの行動を取れば良いか(右、左、上、下など)がわかるので、softmax cross entropyで真の移動方向と比較、逆誤差伝搬を計算します。
さて、VIモジュールは下記のようになります。

まず、入力として与えられた報酬$\bar{R}$に畳み込みを行い、$\bar{Q}$を計算します。$\bar{Q}$はロボットが動作$a$を選択した時に、動作$a$に対して現時点での報酬と合わせてどのくらいの報酬になっているかを計算します。最後に、チャンネル単位でのMAXを取ることで、最も良かった動作に関する報酬値$\bar{V}$が得られます。この報酬を元に再度VIモジュールを計算することで、順々に報酬を伝播させていくことができます。
実装
さて、全体を説明したので、実装に移っていきましょう。本論文はデータの準備、学習、結果表示、それぞれが別のプログラムで構成されます。ここでは学習と予測の部分のみ記載します。~~近々、githubにアップします。~~アップしました。
まずはネットワークの初期化について。
class VIN(chainer.Chain):
def __init__(self, k = 10, l_h=150, l_q=10, l_a=8):
super(VIN, self).__init__(
conv1=L.Convolution2D(2, l_h, 3, stride=1, pad=1),
conv2=L.Convolution2D(l_h, 1, 1, stride=1, pad=0, nobias=True),
conv3=L.Convolution2D(1, l_q, 3, stride=1, pad=1, nobias=True),
conv3b=L.Convolution2D(1, l_q, 3, stride=1, pad=1, nobias=True),
l3=L.Linear(l_q, l_a, nobias=True),
)
self.k = k
self.train = True
conv1、conv2がマップデータから推定報酬への変換の重みとなります。入力が2次元なのは、マップ上の障害物を記載した画像を1チャンネルに、ゴール位置を記載した画像を2チャンネルに割り当てています。出力はマップの各位置における報酬値であり、1次元となります。conv3は報酬値からの、conv3bはVIによって伝播してきた報酬値から、それぞれ位置×動作に対応した予測報酬値に変換するための重みとなります。l3はAttentionによって得た、ロボットの位置における将来予測報酬値から、最終的な動作に変換するための重みとなります。次にネットワークを下に記載します。
def __call__(self, x, s1, s2):
h = self.relu(self.conv1(x))
r = self.conv2(h)
q = self.conv3(r)
v = F.max(q, axis=1, keepdims=True)
for i in xrange(self.k - 1):
q = self.conv3(r) + self.conv3b(v)
v = F.max(q, axis=1, keepdims=True)
q = self.conv3(r) + self.conv3b(v)
t = s2 * q.data.shape[3] + s1
q = F.reshape(q, (q.data.shape[0], q.data.shape[1], -1))
q = F.rollaxis(q, 2, 1)
t_data_cpu = chainer.cuda.to_cpu(t.data)
w = np.zeros(q.data.shape, dtype=np.float32)
w[six.moves.range(t_data_cpu.size), t_data_cpu] = 1.0
if isinstance(q.data, chainer.cuda.ndarray):
w = chainer.cuda.to_gpu(w)
w = chainer.Variable(w, volatile=not self.train)
q_out = F.sum(w * q, axis=1)
return self.l3(q_out)
一気に書くと追いづらいので、以下に分割しながら再掲します。まずは、入力画像を報酬値に変換します。ここは、ごく普通のCNNです。
h = self.relu(self.conv1(x))
r = self.conv2(h)
次にVIモジュールです。畳み込み層conv3によって$\bar{Q}$を求め、動作チャンネル(axis=1)に対してMAXを取ることで、マップ内の各位置において最良の動作を選択します。その時の報酬値がvとなります。for文中はマップから直接推定した報酬値と伝播してきた報酬値を足し合わせるようにして、最初と同様の計算を行います。
q = self.conv3(r)
v = F.max(q, axis=1, keepdims=True)
for i in xrange(self.k - 1):
q = self.conv3(r) + self.conv3b(v)
v = F.max(q, axis=1, keepdims=True)
得られた報酬マップの中から自分の位置に近い部分のみ使うことでパラメータの個数を減らすAttentionの部分が下記となります。まず、報酬マップとして動作ごとの報酬値を出力する$\hat{Q}$を利用することとして、rとvを足し合わせます。次に、バッチ内の各データについて、自分の位置に対応するマップ上の数値を取り出します。chainerではFancy Index的な事ができないので、少しトリッキーですが、取り出したい位置に1を、それ以外に0を入れた行列wを用意して、要素ごとに積を取ることで不要な要素を消し、縮退させることで所定の報酬値を取得しています。
q = self.conv3(r) + self.conv3b(v)
t = s2 * q.data.shape[3] + s1
q = F.reshape(q, (q.data.shape[0], q.data.shape[1], -1))
q = F.rollaxis(q, 2, 1)
t_data_cpu = chainer.cuda.to_cpu(t.data)
w = np.zeros(q.data.shape, dtype=np.float32)
w[six.moves.range(t_data_cpu.size), t_data_cpu] = 1.0
if isinstance(q.data, chainer.cuda.ndarray):
w = chainer.cuda.to_gpu(w)
w = chainer.Variable(w, volatile=not self.train)
q_out = F.sum(w * q, axis=1)
最後に報酬から動作に変換して出力します。
return self.l3(q_out)
次にデータセットクラス(本コードはchainer1.10以降に対応します)
class MapData(chainer.dataset.DatasetMixin):
def __init__(self, im, value, state, label):
self.im = np.concatenate(
(np.expand_dims(im, 1), np.expand_dims(value,1)),
axis=1).astype(dtype=np.float32)
self.s1, self.s2 = np.split(state, [1], axis=1)
self.s1 = np.reshape(self.s1, self.s1.shape[0])
self.s2 = np.reshape(self.s2, self.s2.shape[0])
self.t = label
def __len__(self):
return len(self.im)
def get_example(self, i):
return self.im[i], self.s1[i], self.s2[i], self.t[i]
残りはCIFAR-10のサンプルとほぼ同じです。データ生成も含め、~~近々githubにアップロードします。~~アップしました。
実験結果
さて、実験です。実験は本論文と同じパラメータで試してみました。データ数はマップの種類5000個、マップに対して、ランダムにスタートを7種類決め、ゴールはマップに対して1種類のみ。ゴール数が少ないのは正解データを計算するために計算時間が沢山必要そうだったためです。5000種類のうち、1/5をテスト用データとして実験を行いました。実験はAWS上で行い、30エポックで数時間程度です。文頭で14時間と表示されていたのは、理由はよく分かりませんでしたが、別途cudnnを入れたら数時間で実行できるようになりました。
まずは、テストケース1を示します。壁が黒、動ける範囲を白で示します。下の青い点がスタート、上の水色の点がゴールとなります。認識した経路は黄色で表示しています。途中に遮るブロックがあっても、ちゃんと迂回してゴールにたどり着けているのがわかります。

次に、推定した報酬マップを示します。壁の領域の報酬が下がっているのがわかります。一方、広い領域も壁から離れた領域の方が報酬が高そうです。
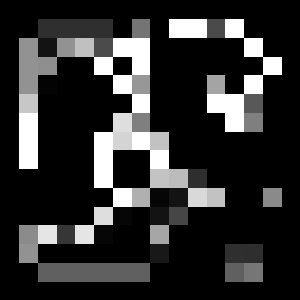
最後が、VIモジュールが出力した将来報酬の図です。ゴール付近の報酬が高くなっていることが分かります。経路を選択するときは、報酬が高い方に進むことでゴールにたどり着くことができます。

続いて、テストケース2です。あまり変わらないので、軽く説明します。こちらは、少し大きめに迂回する必要があるコースですが、きちんと経路を認識できているようです。

報酬マップも、将来報酬マップもちゃんと認識できていそうですね。
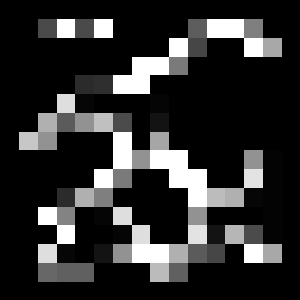

まとめ
もう少し定量的な実験もしたかったのですが、時間がなくなってしまったので、ひとまずこれにて終了します。感想としては、VINめっちゃ凄い、の一言です。初めて見るマップなのにも関わらず、ちゃんと経路が推定できている!どのくらい大きな問題にスケールできるかは、現時点では何とも言えませんが、とても面白い手法だと感じました。あと、一発で上手くいって良かった。
chainerは相変わらず使いやすい!ただ、やはり特殊な事例に対応するためには、Fancy Index的なのをもう少し拡充するか、自動微分してくれるかして欲しいかも・・・。
さて、残った疑問点は下記2点です。
- 学習データは最短経路のみなのに、壁など未学習の領域の報酬まで学習できた
- 価値反復に合わせたため、VIMには非線形の活性化関数を入れていないのに学習できた
これらは、通常のDeep Learningでは無くてはならない条件な気がするのですが、何故か上手くいくのが非常に不思議でした。
ちなみに、作者がTheanoベースで実装しているバージョンもgithubには上がっているようです。