背景
作業中に論文や教科書を読んでもらいたいので、以下のような条件をみたす text-to-speech のソフトウェアを探していた。
- 従量課金でない(論文や教科書は文字数が多いので)
- コマンドラインで実行できる
- 声に不自然さがない
VOICEPEAK 彩澄りりせ がこれらの条件をみたしていたので、これを購入した。ただしコマンドラインは正式版として提供されているのではないらしい。参照:Voicepeak コマンドのオプションと使用例
出力した音声はスマホなどで聞くことを想定している。スマホは、音声ファイルよりも動画ファイルのほうが扱いやすいことも多い(例:YouTube の非公開動画として上げておく)ので、今回は動画の作成まで行う。
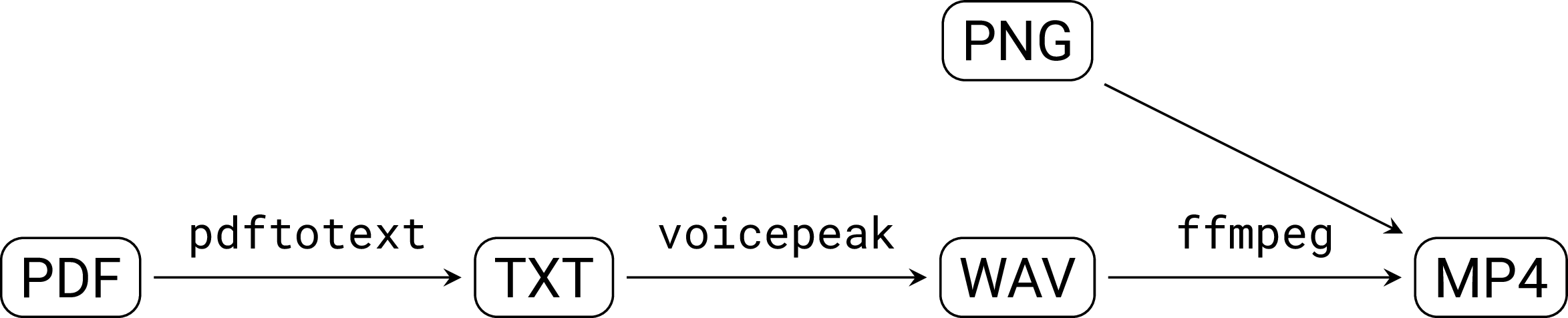
検証環境
- WSL2 上の Ubuntu 20.04
- Homebrew をインストール済み
準備
必要に応じて poppler や ffmpeg をインストールする。
brew install poppler # PDFからテキストファイルを作成する場合に必要
brew install ffmpeg # 動画にする場合に必要
また動画化する場合に立ち絵を使用したい場合は 公式ページ からダウンロードしておく。WSL 側で使いやすいようにコピーしておく。
cp /mnt/c/Users/USER/Downloads/ririse_seihuku_illust/ririse_seihuku_illust/彩澄りりせ_制服イラスト/001.png .
chmod -x 001.png
手順
-
PDFからテキストを抜き出す。
pdftotext -f FIRST_PAGE -l LAST_PAGE PDF_FILENAME TEXT_FILENAME -
必要に応じてテキストを編集する。特に日本語以外が苦手なので、日本語読みしたカタカナ表現などに置き換える。もしこの処理を本格的にやりたければ cmudict を使うといい。
-
VOICEPEAK を使って、テキストファイルから WAV ファイルを作成する。
/mnt/c/Program\ Files/VOICEPEAK/voicepeak.exe -t TEXT_FILENAME -o WAV_FILENAME -
WAV ファイルが複数の場合は1つにまとめる。
sox INPUT_WAV_FILENAME1 INPUT_WAV_FILENAME2 OUTPUT_WAV_FILENAME -
WAV ファイルを元に動画 (MP4) を作成する。参照:FFmpegで音声ファイルと画像1枚から動画を作成してみた
ffmpeg \ -loop 1 \ -r 30000/1001 \ -i 001.png -i WAV_FILENAME \ -vcodec libx264 \ -acodec aac \ -strict experimental \ -ab 320k -\ ac 2 -\ ar 48000 \ -pix_fmt yuv420p \ -shortest \ VIDEO_NAME
出力例
感想
日本語に限れば十分なクオリティだと思う。一方で、繰り返しになるが、日本語以外は難があり、前処理で頑張る必要がある。日本語以外が出てこない論文や教科書というのは少数派だと思うので、小説などのほうが向いているかもしれない。