まえがき
本格的にデータ分析にハマり始めて約一ヶ月。
元々競馬の予想モデルを作成してみたいと思っていましたが、スクレイピングや前処理のやり方がわからず、何度も断念していました、、、
そろそろチャレンジできるんじゃないか!ということで、今回は有馬記念に向けて予想モデルの作成を行ってみました。
改良した競馬予想モデルで予想ブログ運営しております。最新の予想はこちらから。
やったこと
モデル作成でやったことをさっくりと。
①課題の理解
②タスクと評価指標
③データ収集(スクレイピング)
④特徴量の作成
⑤モデルの作成・評価
①課題の理解
堅苦しいですがこの辺も大事ですよね。何を課題とするか定めないと、どうしても作業の途中で目的を見失ってしまいがちです。
競馬予測モデルで考えると、軸馬を決めたい、的中率を当てたい、回収率を上げたい、、、いろいろ思いつきますね。
今回、私の課題は 年内最後の大勝負、有馬記念をなんとしても当てること です!
となると妙味のある馬を探すというよりは、的中率を重視したモデルの作成に取り掛かる必要がありますね。
②タスクと評価指標
そもそも予想モデルって何の予想を行うの?
的中率を重視したモデルの作成を行うことは決まりましたが、具体的に何を予想するのか決めていませんね。
目的変数に何をとるのか。順位、走破タイム、連帯率など競馬の予想にもさまざまあります。
今回はいろんな観点でそれぞれモデルを作ってみたいと思うので、ここはいったんパスします。
データ収集(スクレイピング)
何が面倒ってここが面倒なんですよね。
kaggle等のコンペでは、あらかじめデータが用意されていますが、今回は自分で集める必要があります。
しかし、心優しい先駆者の方々が、ありがたいことにスクレイピングの方法やコードを載せているサイトがたくさんあります。私はこちらの記事を参考にしてデータ収集行いました。
「機械学習で競馬予想」をガチで作る〜「予測してみた」で終わらせないAI開発〜
net競馬からのスクレイピング方法について解説されています。
こちらを元に以下のようなデータを集めました。
・2006~2022年の有馬記念のレースデータ
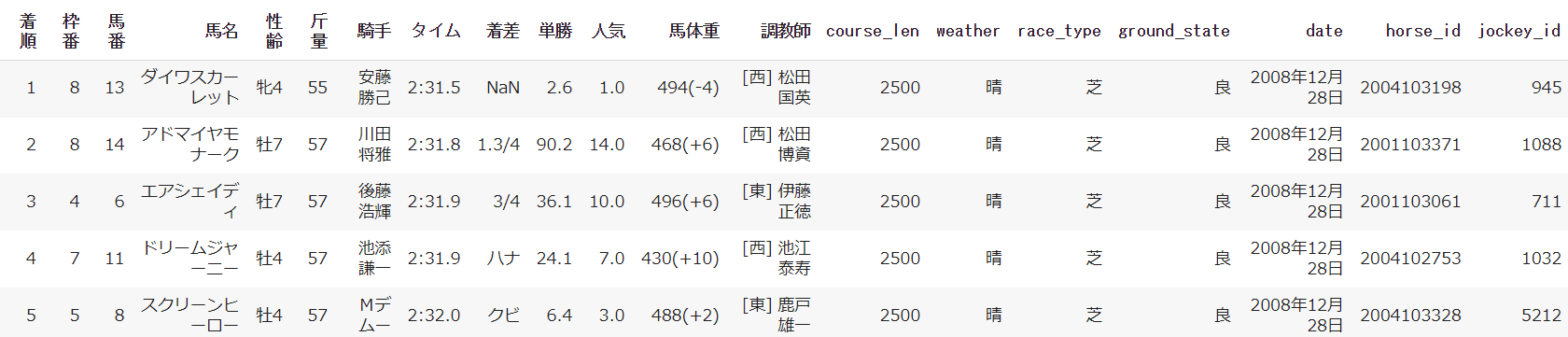
データ数:236
・2006~2022年の有馬記念に出走した馬のホースデータ
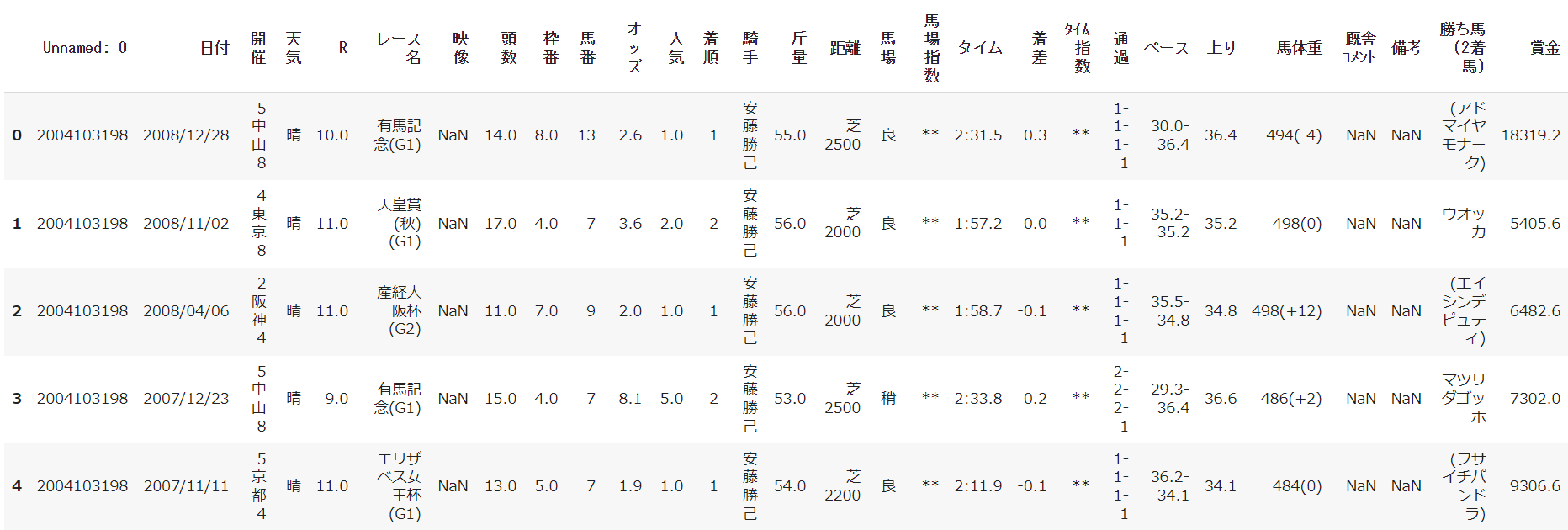
データ数:4171
本当はもう少しデータを集めたいところですが、今回は有馬記念のデータのみ抽出しました。
全レースの全データを集めようとしたところ、とても時間がかかりそうでした。
初めて作る予想モデルということで、このデータ数でモデル作成に挑戦したいと思います!
データに関しては表の通りです。ホースデータの方はUnnamedになっていますが、ここがhorse_idの値です。
このhorse_idを使用することで2つの表から特徴量を作成していきます。
④特徴量の作成
データが作成できたところで、いよいよデータ分析スタートです。
前処理も含めて、機械が学習できる形に成型していきます。
今回、特徴量として、以下のものを用意したいと思います。
| 変数名 | 説明 |
|---|---|
| waku | 枠 |
| No | 馬番 |
| hand | 斤量 |
| sex | 性別 |
| age | 年齢 |
| trainer_place | 栗東か美浦か |
| agari_saisoku | 近一年で一番早い上り3Fタイム |
| money_year | 近一年の獲得賞金 |
| jockey_foreigner | 外国人ジョッキーかどうか |
| race_interval | レース間隔何ヶ月か |
| pre_jockey | 前走から乗り替わりかどうか |
| kyakusitu | 逃げ・先行or差し・追い込み |
| weight | 馬体重 |
| weight_move | 馬体重増減値 |
| odds | 単勝オッズ |
| ninki | 人気 |
人気やオッズはあまり使いたくないですが一応用意しておきます。
今回はデータ数が少ないため、工夫して特徴量を作成しました。
下4つの特徴は現時点(2023/12/23)ではわからないため、後日検証用に作成しています。
枠、馬番、斤量、オッズ、人気
ここは元のデータのままでも特に問題なく処理できました。
性別、年齢、馬体重、馬体重増減値
元のデータは以下になります。
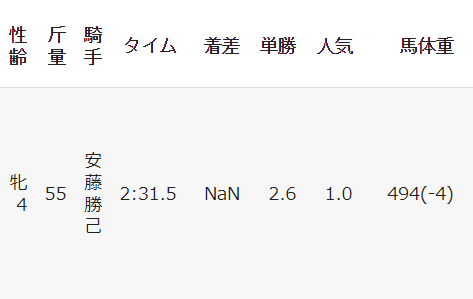
データを見ると、性齢、馬体重がありますが、どちらも文字列で格納されていて、このままでは使いにくい形になっています。
それぞれ扱いやすくなるように加工します。
R_result['sex']=R_result.性齢.str[:1]
R_result['age']=R_result.性齢.str[1:]
R_result['weight']=R_result.馬体重.str[:3]
R_result['weight_move']=s.str[-5:-1]
これで性別、年齢、馬体重、馬体重増減値を得ることができました。
栗東か美浦か
調教師について、それぞれの調教師でのデータを集めるのは時間がかかるため、今回は西か東かでわけました。昔は西が強かったというイメージがなんとなくありましたが、西と東で特徴がでるか、データを作成します。
R_result['trainer_place']=R_result.trainer_name.str[1:2]
近一年で一番早い上り3Fタイム
上り3Fでその馬の能力が出ると言われるほど大事な数値ですね。
今回は有馬記念から近一年のレースの中で一番早い上りタイムを抽出しました。
コースや距離、展開によって上りタイムの評価方法も変わると思いますが、細かいことはいつか考えましょう。
R_result['arima_year']=R_result.date.str[:4]
H_result['arima_year']=H_result.date.str[:4]
H_result['agari'].fillna(9999,inplace=True)
agari_saisoku=[]
for a in range(len(R_result.horse_id)):
s=9999
agari_list=[]
for c in range(len(H_result.horse_id)):
if H_result.horse_id[c]==R_result.horse_id[a]:
if R_result.arima_year[a]==H_result.arima_year[c]:
agari_list.append(H_result.agari[c])
s=min(agari_list[1:])#有馬の上り削除
agari_saisoku.append(s)
R_result['agari_saisoku']=agari_saisoku
時系列データの扱い方については勉強が必要ですね、、、
ともかくこれで各馬の近一年の上りタイムを取得することが出来ました。
近一年の獲得賞金
馬の能力へのアプローチとして、重賞勝利回数や連対回数などいろいろ候補はありますが、賞金の高いレースには能力の高い馬が集まるだろうということで、近一年の獲得賞金が有効なデータになると考えました。
H_result['money'].fillna(0,inplace=True)
money_year=[]
for a in range(len(R_result.horse_id)):
s=0
money_list=[]
for c in range(len(H_result.horse_id)):
if H_result.horse_id[c]==R_result.horse_id[a]:
if R_result.arima_year[a]==H_result.arima_year[c]:
money_list.append(H_result.money[c])
s=sum(money_list[1:])
money_year.append(s)
NaNの足し算はNaNになってしまうため、欠損値には0を代入しました。
レース間隔何ヶ月か
最近ではトライアルを挟まずにGⅠに挑戦する馬が増えましたね。今回は前走から有馬記念まで何ヶ月間隔があるかをデータとして集めます。
race_interval=[]
for a in range(len(R_result.horse_id)):
interval_list=[]
for c in range(len(H_result.horse_id)):
if H_result.horse_id[c]==R_result.horse_id[a]:
if R_result.arima_year[a]==H_result.arima_year[c]:
interval_list.append(12-int(H_result.date.str[5:7][c]))
s=interval_list[1]
race_interval.append(s)
外国人ジョッキーかどうか、前走から乗り替わりかどうか
結局ルメール買っときゃ当たんのよ。ってことをデータにしてあげます。
にしてもほんとに今年もルメール祭りでしたね、、、
また今回の有馬記念はソールオリエンス、ディープボンドを筆頭にかなり乗り替わりが多い印象がありますね。ダービーでは今年乗り替わりでレーン騎手が制しましたが、有馬記念は乗り替わり影響するのか見てみたいですね。
s=[]
for a in range(len(R_result.jockey_id)):
if R_result.jockey_id[a]==5212 or R_result.jockey_id[a]==432 or R_result.jockey_id[a]==5339 or R_result.jockey_id[a]==5271 or R_result.jockey_id[a]==5416 or R_result.jockey_id[a]==5471 or R_result.jockey_id[a]==5377 or R_result.jockey_id[a]==5366 or R_result.jockey_id[a]==5495 or R_result.jockey_id[a]==5473 or R_result.jockey_id[a]==5529 or R_result.jockey_id[a]==5527 or R_result.jockey_id[a]==5504 or R_result.jockey_id[a]==5538 or R_result.jockey_id[a]==5575 or R_result.jockey_id[a]==5568 or R_result.jockey_id[a]==5585 or R_result.jockey_id[a]==5626:
s.append(1)
else:
s.append(0)
R_result['jockey_foreigner']=s
pre_jockey=[]
for a in range(len(R_result.jockey_name)):
pre_jockey_list=[]
for c in range(len(H_result.jockey_name)):
if H_result.horse_id[c]==R_result.horse_id[a]:
if R_result.arima_year[a]==H_result.arima_year[c]:
pre_jockey_list.append(H_result.jockey_name[c])
s=pre_jockey_list[1]
if s==R_result.jockey_name[a]:
u=0
else:
u=1
pre_jockey.append(u)
R_result['pre_jockey']=pre_jockey
逃げ・先行or差し・追い込み
脚質も重要なファクターですよね。今回は逃げ・先行or差し・追い込みの二分割でわけました。
なんとなく中山だし逃げ・先行が好成績を残していそうですよね。
H_result['tuka'].fillna('9999',inplace=True)
kyakusitu=[]
s=0
for a in range(len(R_result.horse_id)):
tuka_list=[]
for c in range(len(H_result.horse_id)):
if H_result.horse_id[c]==R_result.horse_id[a]:
if R_result.arima_year[a]==H_result.arima_year[c]:
if int(H_result.tuka.str[0:2][c].replace("-",""))!=99:
tuka_list.append(int(H_result.tuka.str[0:2][c].replace("-","")))
s=sum(tuka_list)/len(tuka_list)
if s<=5:
kyakusitu.append(1)
else:
kyakusitu.append(0)
R_result['kyakusitu']=kyakusitu
脚質の判断として、近一年で最初のコーナー通過順位の平均が5番手以内かどうかで判別しました。
競馬新聞などに載っている脚質ってどのように判断しているんですかね?
作成したデータの確認
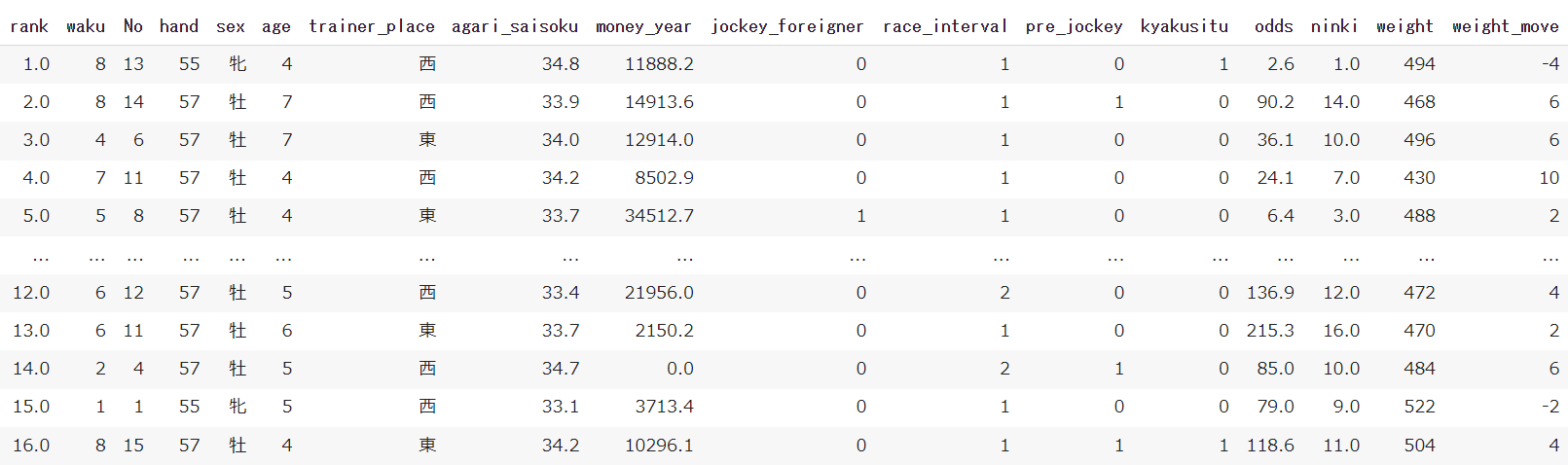
ようやくこれで欲しいデータが揃いました。
いよいよモデル作成に取り掛かります。
⑤モデルの作成・評価
目的変数に何をとるか後回しにしていましたが、今回は以下の2つでそれぞれモデルを作成して試してみます。
・5着以内率(3着以内率)
・走破タイム
5着以内率は二値分類,走破タイムは回帰分析となりますね。
どちらも GBDT (勾配ブースティング木)でモデルを作成します。
また、このモデル作成では人気、オッズ、馬体重については特徴量に用いずに作成しました。
それぞれモデルを作成して比較してみましょう。
5着以内率(二値分類)
# 訓練データとテストデータに分ける
train_set, test_set = train_test_split(train, test_size = 0.2)
# 説明変数と目的変数に分ける
x_train = train_set.drop('rank', axis = 1)
y_train = train_set['rank']
x_test = test_set.drop('rank', axis = 1)
y_test = test_set['rank']
# LightGBM用のデータセットに入れる
lgb_train = lgb.Dataset(x_train, y_train)
lgb.test = lgb.Dataset(x_test, y_test)
# 評価基準を設定する
params = {
'objective':'binary',
'metric' : 'binary_logloss',
'max_depth':7
}
# 訓練データから二値分類モデルを作る
gbm = lgb.train(params,
lgb_train)
# テストデータを用いて予測精度を確認する
test_predicted = gbm.predict(x_test)
loss=log_loss(y_test, test_predicted)
logloss:0.5657660335819108
loglossは小さいほど良い(小さすぎると過学習が疑われる)値です。
精度としては決して高くはありませんが、全く使い物にならないというわけでもなさそうです。
このモデルが重要だとした特徴量は以下になります。
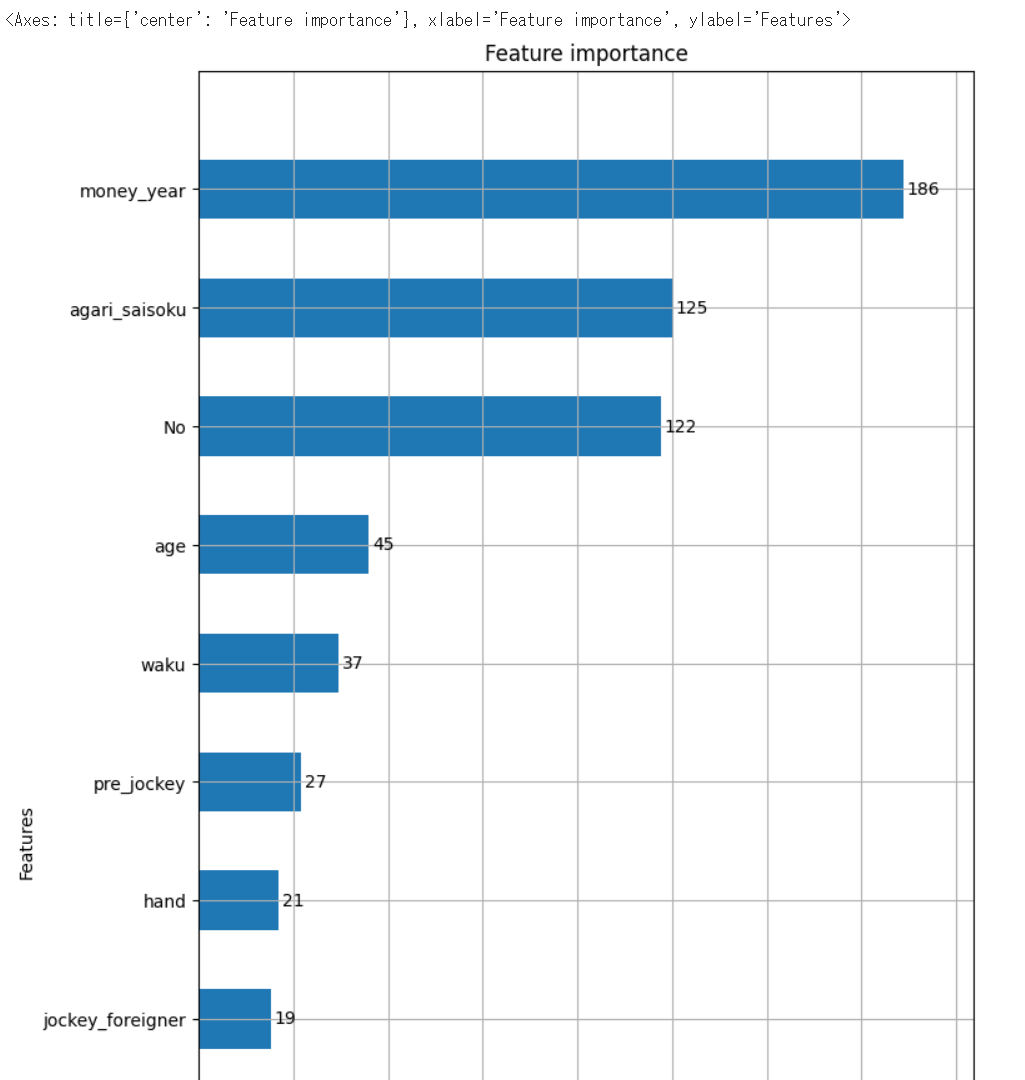
上位3つに近一年の獲得賞金、近一年の最速上りタイム、馬番が使われていました。
このモデルで予想させた2023有馬記念の結果は以下になります。
| 馬名 | 5着以内確率 |
|---|---|
| タスティエーラ | 96.5% |
| スターズオンアース | 94.3% |
| ソールオリエンス | 93.3% |
| ジャスティンパレス | 84.3% |
| ハーパー | 76.1% |
| スルーセブンシーズ | 74.7% |
| タイトルホルダー | 51.4% |
| ドウデュース | 50.8% |
| プラダリア | 30.6% |
| ディープボンド | 28.8% |
| ライラック | 24.1% |
| シャフリヤール | 16.7% |
| ウインマリリン | 9.2% |
| アイアンバローズ | 3.9% |
| ホウオウエミーズ | 1.4% |
| ヒートオンビート | 0.7% |
ちょっと値が大きすぎる気がしますが、上位人気になりそうな馬が高い確率で5着以内に入りそうだと出力されましたね。
趣旨とは離れますが、穴目だとハーパーが狙い目のように見えますね。
ついでに3着以内率を予想するモデルを作成して予測させてみました。
| 馬名 | 3着以内確率 |
|---|---|
| タスティエーラ | 94.7% |
| ソールオリエンス | 92.7% |
| スターズオンアース | 83.9% |
| ジャスティンパレス | 46.3% |
| ディープボンド | 39.7% |
| ドウデュース | 33.3% |
| タイトルホルダー | 23.1% |
| ライラック | 20.1% |
| スルーセブンシーズ | 15.7% |
| プラダリア | 9.5% |
| ハーパー | 4.8% |
| シャフリヤール | 3.0% |
| ホウオウエミーズ | 1.7% |
| アイアンバローズ | 1.0% |
| ウインマリリン | 0.4% |
| ヒートオンビート | 0.1% |
あら、先ほどはねらい目だったハーパーが随分と低い順位になってしまいました。
好走はするけど4、5着と馬券内には絡めないんですかね。
ただどちらの予想でもタスティエーラが一番高い確率で好走すると予想されました。
走破タイム(回帰分析)
やることは先ほどとあまり変わりません。
モデル作成時のパラメータを回帰分析に変更加えました。
まずはモデルの作成、評価です。
# 訓練データとテストデータに分ける
train_set, test_set = train_test_split(train, test_size = 0.2)
# 説明変数と目的変数に分ける
x_train = train_set.drop('min', axis = 1)
y_train = train_set['min']
x_test = test_set.drop('min', axis = 1)
y_test = test_set['min']
# LightGBM用のデータセットに入れる
lgb_train = lgb.Dataset(x_train, y_train)
lgb.test = lgb.Dataset(x_test, y_test)
# 評価基準を設定する
params = {
'metric' : 'rmse',
'max_depth':7
}
# 訓練データから回帰モデルを作る
gbm = lgb.train(params,
lgb_train)
# テストデータを用いて予測精度を確認する
test_predicted = gbm.predict(x_test)
r2_score(y_test, test_predicted)
$R^2=-0.0546$
決定係数は1に近いほど精度がよい値です。
こっちはちょっと予想モデルとしては、、、だいぶ出来が悪そうです。
一応こちらでも2023有馬記念を予想してみます。
| 馬名 | time |
|---|---|
| タスティエーラ | 2:32.1 |
| ソールオリエンス | 2:32.2 |
| タイトルホルダー | 2:32.5 |
| スターズオンアース | 2:32.6 |
| ホウオウエミーズ | 2:33.0 |
| ジャスティンパレス | 2:33.0 |
| ハーパー | 2:33.3 |
| スルーセブンシーズ | 2:33.4 |
| アイアンバローズ | 2:33.9 |
| ヒートオンビート | 2:33.9 |
| ディープボンド | 2:33.9 |
| プラダリア | 2:34.4 |
| ドウデュース | 2:34.5 |
| シャフリヤール | 2:34.5 |
| ライラック | 2:34.6 |
| ウインマリリン | 2:34.7 |
こちらのタイム予想でもタスティエーラが一番と予想されました。
穴目で気になるのはホウオウエミーズですね。こちらのモデルでは随分と評価が高いようです。
何かの縁だと思って紐に入れようかな、、、
まとめ
これだけじゃ使い物にならないモデルしか作れないかな、、、とも思っていましたが、思った以上にそれっぽい予想をができていそうなモデルが作成できました。
スピード指数なども取り入れられるともう少し精度が上がりそうな気もします。
なんとなく競馬の予想モデルの作成方法がわかったので、次はもっとデータ数も増やしてモデル作成にチャレンジしたいです。
というわけで今年の有馬記念は タスティエーラ から買いたいと思います!
最後までご覧いただきありがとうございます!!現在、日々改良した競馬予想モデルで予想ブログ運営しております。最新の予想はこちらから。