
AIが世の中にだいぶ普及してきていることもあり、
「Pythonで競馬AIを作ったら儲かるのか?」
「ディープラーニングで競馬予想したら回収率100%超えた」
などの話題が注目を集めているのを度々目にします。
僕も 「機械学習の技術を使って実際に何か作りたい」 という動機から競馬予想AIの開発を始め、 「その様子を動画にしたら面白そう」 ということで、次のようなYouTubeチャンネルをやってきました。
登録者も増え、エラーが出た時のフォローや改善アイデアを議論し合うコミュニティを作るにまで至ったのですが、実際の運用を考えたり、処理を追加して精度を改善しようと思うと、かなり煩雑で分かりにくいコードになっていってしまうことに悩んでいました。
そこで、一回きりのアドホック1的な「予測してみた」で終わらせず、継続的に開発・運用していけるような機械学習モデルを作るには、GCPなどのクラウドツールによるデータや実行フローの管理、オブジェクト指向プログラミングやgitを使ったソースコードの最適化など、様々な技術を連携させる必要があることを知ります。(いわゆる「MLOps2」という概念です。)
その中でもまずは、比較的取り組みやすい 「ソースコードの最適化」 の部分についてある程度完成したので(なかなか大変でした)、そのソースコードを公開しようと思います。
まだまだ改善の余地はあると思いますが、「機械学習で競馬予想」を始める時の「定番」のような存在になれたら良いな・・・と、密かに思っております。
この記事の概要
改めて、この記事では「機械学習で競馬予想」をガチで(=一回きりの「予測してみた」で終わらせず、継続的に開発・運用していけるように)開発するために、どのようなソースコードを実装をしたのかをまとめてみようと思います。
この記事を読むことで、競馬予想AIの作り方を把握するのと同時に、例えば次のようなあるあるを解決するきっかけになれば良いなと思っています。
Jupyter Notebook/Labで機械学習をする時のあるある
-
特徴量を追加してみよう
↓
元々のコードも変えたくないから、セルをコピーして新しい処理を書く
↓
セルが無限に増えていき、 「どのセルを実行すればどの特徴量ができるのか」もはや分からない -
notebookを再起動後、セルを実行
↓
「×××が定義されていません」とエラー
↓
×××を定義したセルどこだっけ?
↓
探して全て実行し直さなければならない -
実行コードが長く、実行コードを見て「どのような処理が行われているのか」一目で把握しづらい
↓
「結局、どのコードを実行すれば、最後の予測まで使えるようになるの?」 -
ちょっと一旦データを保存しよう
↓
data1.csv, data2.csvなどが.ipynbと同じディレクトリに量産されていく
↓
数日後、 「data2.csvって何だ?」
それでは、前置きが長くなりましたが、作った競馬予想AIについて解説していきたいと思います。
どんな予測モデル?
netkeiba.comからデータをスクレイピングし、機械学習モデルLightGBMを使って3着以内に入る馬を予測します。
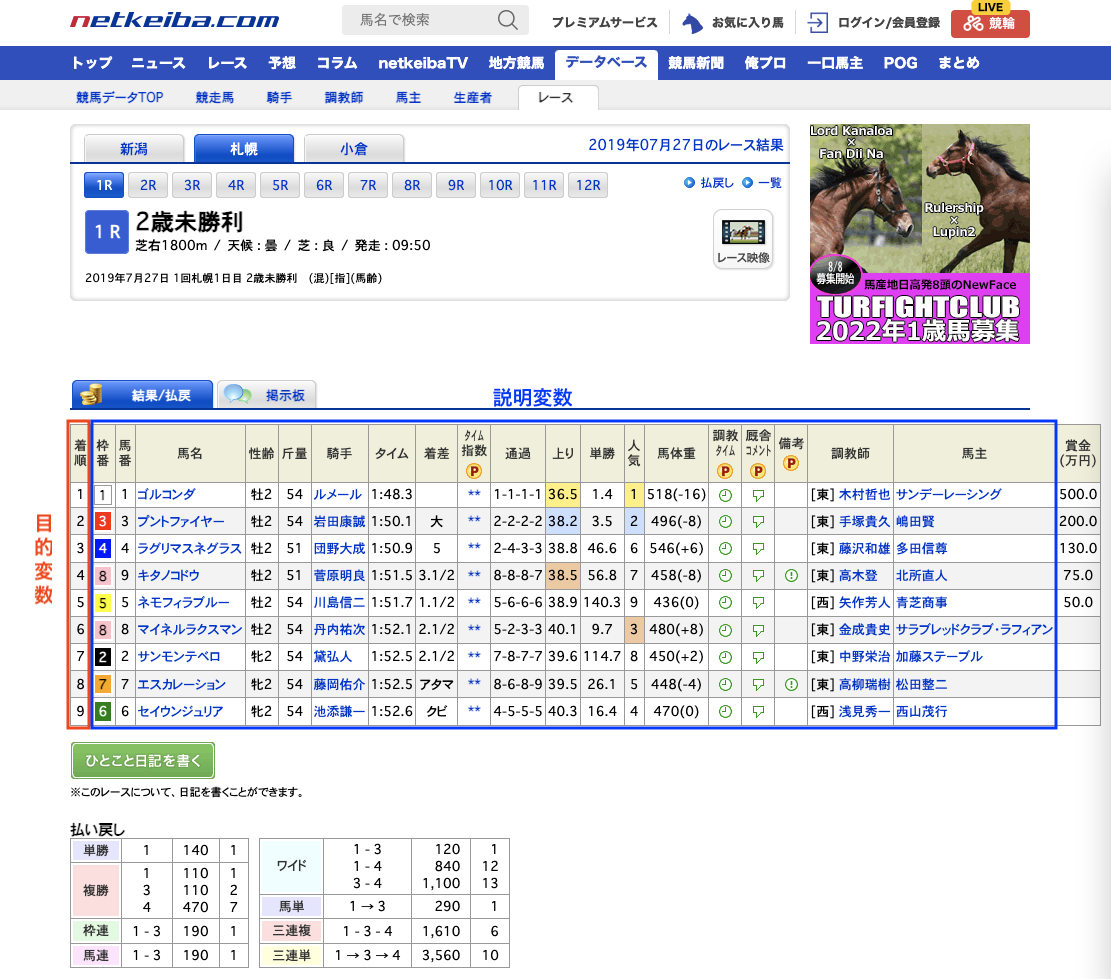
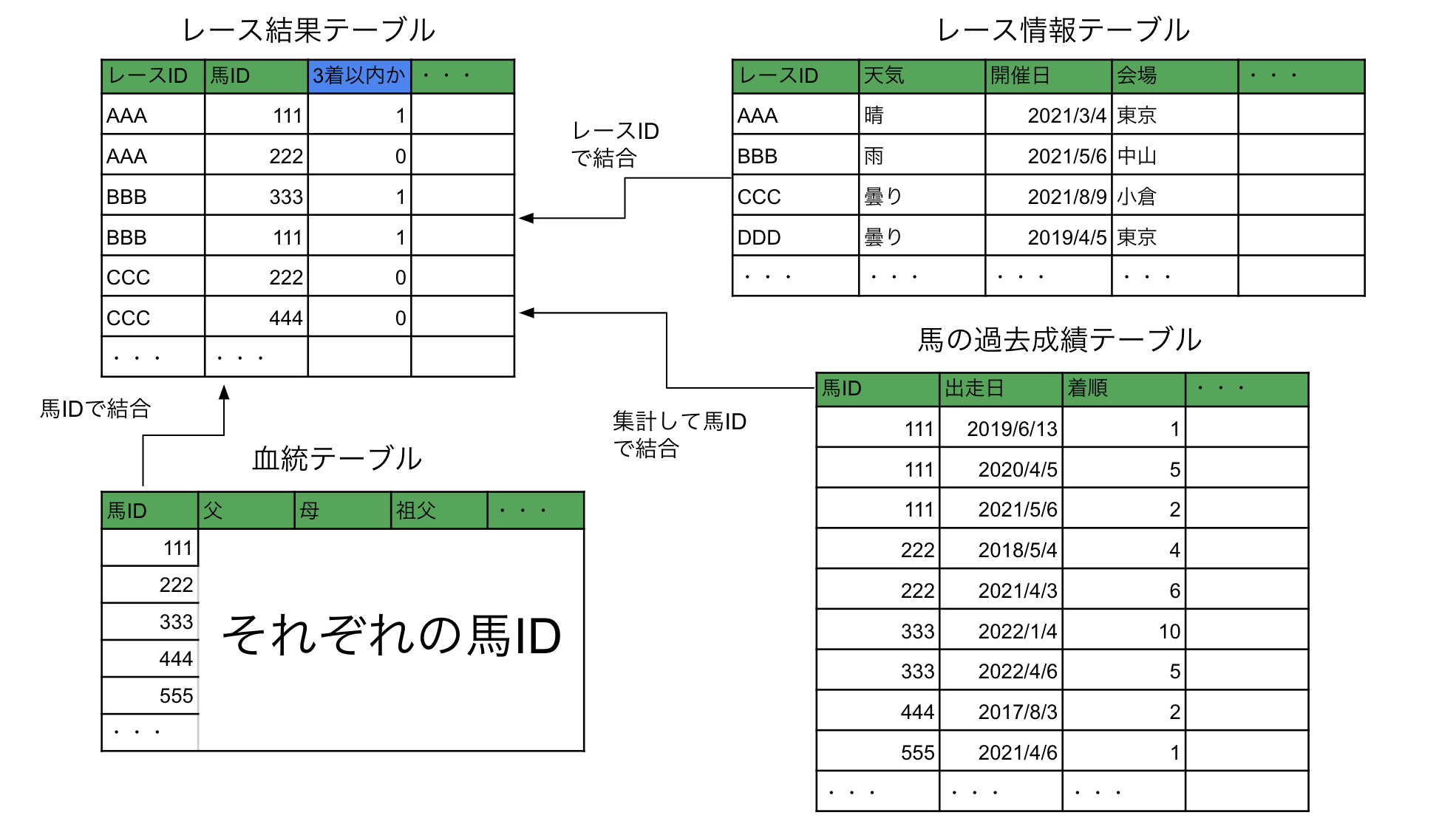
上のレース結果テーブルに含まれる馬体重や騎手などの情報に加えて、レース情報・馬の過去成績・血統などを取得し、それらの変数をもとに「3着以内に入るかどうか」を0or1の二値分類で予測するモデルを作成しました。
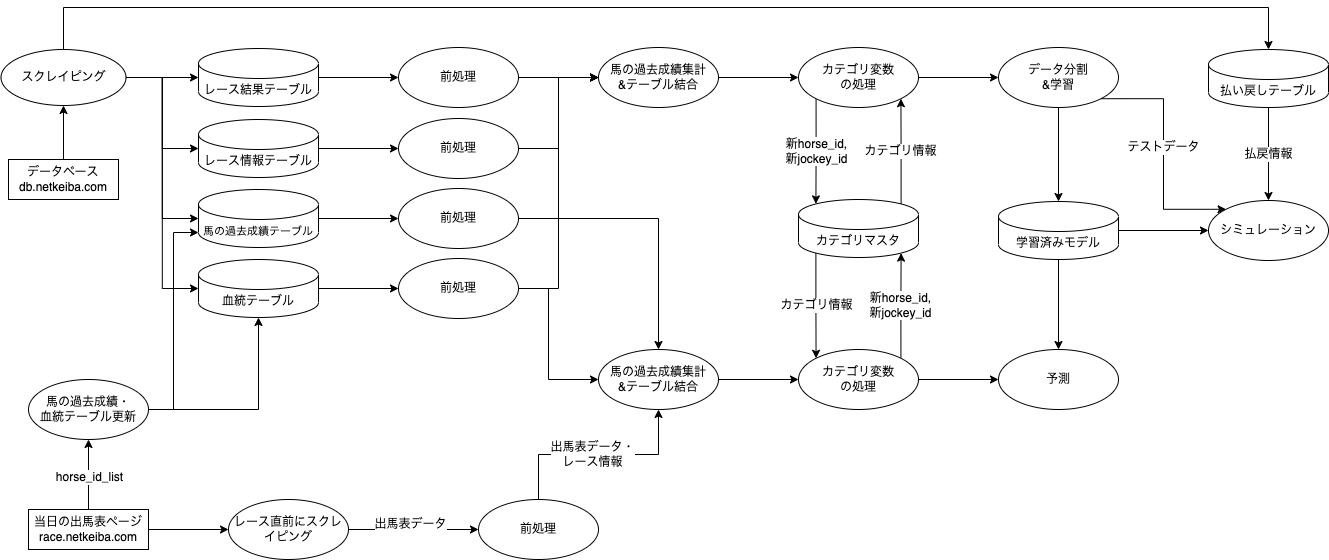
全体像
以下のようなディレクトリ構成になっています。
.
├── main.ipynb ・・・実行コード
├── data ・・・データを保存するディレクトリ
│ ├── html
│ │ ├── horse ・・・horseページからスクレイピングしたhtmlを保存
│ │ ├── ped ・・・pedページからスクレイピングしたhtmlを保存
│ │ └── race ・・・raceページからスクレイピングしたhtmlを保存
│ ├── master ・・・マスタテーブルを保存
│ ├── raw
│ │ ├── results.pickle ・・・レース結果テーブル
│ │ ├── horse_results.pickle ・・・馬の過去成績テーブル
│ │ ├── race_info.pickle ・・・レース情報テーブル
│ │ ├── peds.pickle ・・・血統テーブル
│ │ └── return_tables.pickle ・・・払い戻しテーブル
│ └── tmp ・・・一時的なファイルを保存
├── models ・・・学習済みモデルを保存
└── modules ・・・モジュール(ソースコードが書かれている部分)
├── constants ・・・定数
├── preparing ・・・スクレイピング〜rawデータの作成
├── preprocessing ・・・前処理
├── training ・・・訓練
├── policies ・・・予測スコアの算出ロジックや、馬券購入戦略
└── simulation ・・・回収率シミュレーション
- ソースコード本体をモジュールに分けることで、実行コードであるmain.ipynbをなるべく短くスッキリさせ、「どんな処理が行われているのか」がmain.ipynbを見れば一目で分かるように心がけました。
- そのためにも、クラス名や関数名にはこだわり、名前で処理内容が分かるようにします。
- データやモジュールはディレクトリに分けて整理し、ファイル名はなるべく具体的なものにします。
例えば、data.pickleだと何のことか分かりませんが、data/raw/results.pickleとすることで、初見であっても少なくとも 「何かの結果を表すrawデータが保存されているんだな」 と分かると思います。
処理の全体像を貼っておきますので、この後の解説を追いながら適宜参照してください。クリックで拡大できます。
ソースコード解説
それでは、各ステップについて、どのような実装をしたか解説していきます。
ソースコードの詳細部分(各モジュールの中身)は、以下の電子書籍で全て公開しています。
ここでは、メインとなる実行コード(main.ipynb)を見ながら
- どんなデータを使って、どんな実装をしたのか
- どんなポイントを意識して作ったか
を解説していきます。
ステップ1. データ取得
例として、2020年のデータを取得する場合を考えます。まずは、自作したモジュールも含めてインポートします。
import pandas as pd
import glob
import os
from tqdm.notebook import tqdm
from modules.constants import LocalPaths
from modules.constants import HorseResultsCols
from modules import preparing
from modules import preprocessing
from modules import training
from modules import simulation
from modules import policies
ステップ1-1. レースIDの取得
まずはスクレイピング対象ページの一覧を取得します。
# to_の月は含まないので注意。
kaisai_date_2020 = preparing.scrape_kaisai_date(
from_="2020-01-01",
to_="2021-01-01"
)
# 開催日からレースIDの取得
race_id_list = preparing.scrape_race_id_list(kaisai_date_2020)
netkeiba.comでは、"https://db.netkeiba.com/race/201901010101"のように、
"https://db.netkeiba.com/race/ + (race_id)"
という構造をしたURLに、過去行われたレース結果が入っているので、
- 1行目でカレンダーページから、レースが開催されている日の一覧を取得
- 2行目で開催レース一覧ページからレースidを取得
することによって、スクレイピング対象race_idの一覧を作成しています。
ステップ1-2. raceページからのデータ取得
スクレイピング対象race_idが取得できたので、raceページ: https://db.netkeiba.com/race/(race_id) のスクレイピングを実行します。
# db.netkeiba.com/race/のhtmlをスクレイピングし、data/html/race/に保存
html_files_race = preparing.scrape_html_race(race_id_list, skip=True)
# htmlを受け取って、PandasのDataFrame型に変換
# レース結果テーブルの作成
results_new = preparing.get_rawdata_results(html_files_race)
# レース情報テーブルの作成
race_info_new = preparing.get_rawdata_info(html_files_race)
# 払い戻しテーブルの作成
return_tables_new = preparing.get_rawdata_return(html_files_race)
# テーブルの更新。元々のテーブルが存在しない場合は、新たに作成される。
# LocalPathsに、ファイルパスが定数として定義されている。
preparing.update_rawdata(
filepath=LocalPaths.RAW_RESULTS_PATH,
new_df=results_new
)
preparing.update_rawdata(
filepath=LocalPaths.RAW_RACE_INFO_PATH,
new_df=race_info_new
)
preparing.update_rawdata(
filepath=LocalPaths.RAW_RETURN_TABLES_PATH,
new_df=return_tables_new
)
raceページのhtmlからは、各種preparing.get_rawdata_hogehoge()によって、3種類のテーブル
- レース結果テーブル「
results_new」 - レース情報テーブル「
race_info_new」 - 払い戻しテーブル「
return_tables_new」
がDataFrame型で作成されます。

例えばresults_newには次のようなDataFrameが入っています。
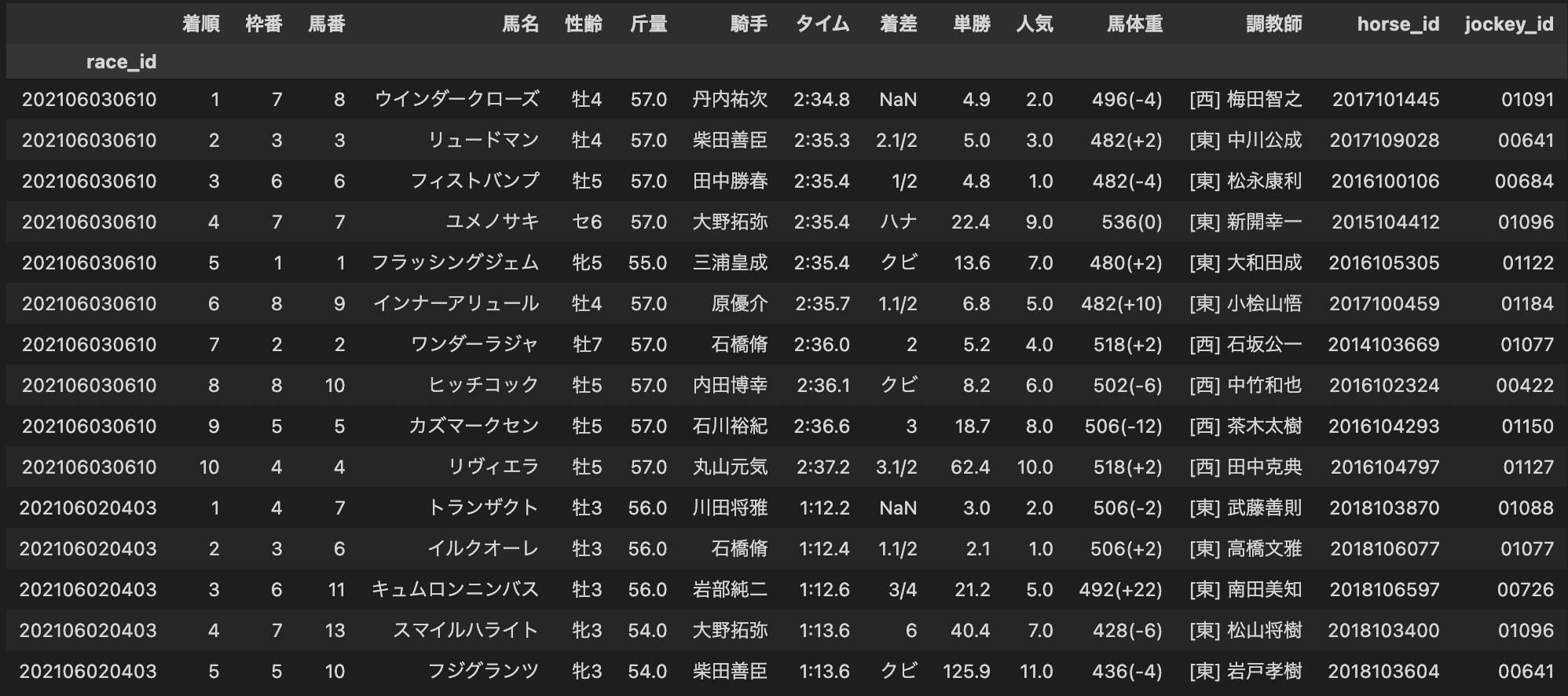
update_rawdata()により、元々保存してあったテーブルに新しくスクレイピングしたデータが追加され、それぞれのpickleファイルが更新されます。
ポイント
- スクレイピングしたhtmlをテーブルデータに保存する前に、一度htmlの形で保存します。作っていくと分かりますが、精度を改善するために「rawテーブルに新しい列を追加したい」という場面が頻繁に出てきます。その際、htmlを保存しておらず、テーブルデータのみ保存していると、もう一度全てのデータをスクレイピングする必要があります。
- ファイルパスは
constants.LocalPathsに定数としてまとめて定義しておくことで、誤ったファイルパスが入力されることを防ぐなどのメリットがあります。
ステップ1-3. horseページからのデータ取得
horseページをスクレイピングし、馬の過去成績テーブルを作成します。
# スクレイピング対象のhorse_idを取得
horse_id_list = results_new['horse_id'].unique()
# htmlをスクレイピング
# すでにスクレイピングしてある馬をスキップしたい場合はskip=Trueにする
# すでにスクレイピングしてある馬でも、新たに出走した成績を更新したい場合はskip=Falseにする
html_files_horse = preparing.scrape_html_horse_with_master(
horse_id_list, skip=True
)
# 馬の過去成績テーブルの作成
horse_results_new = preparing.get_rawdata_horse_results(html_files_horse)
# テーブルの更新。元々のテーブルが存在しない場合は、新たに作成される。
preparing.update_rawdata(LocalPaths.RAW_HORSE_RESULTS_PATH, horse_results_new)
同様に、馬の過去成績テーブルがDataFrame型で作成され、/data/raw/horse_results.pickleに保存されます。
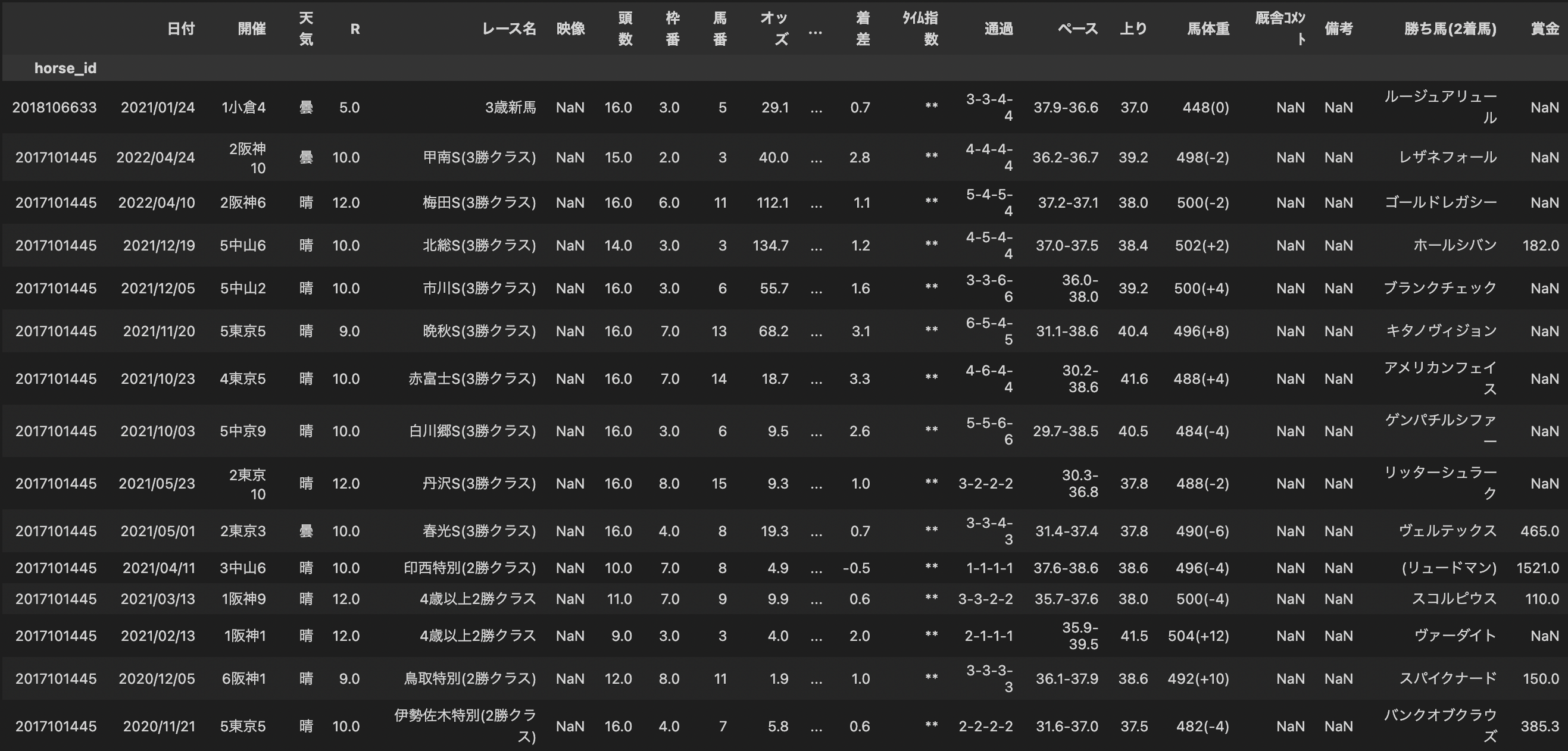
ステップ1-4. pedページからのデータ取得
pedページをスクレイピングし、血統テーブルを作成します。
# htmlをスクレイピング
html_files_peds = preparing.scrape_html_ped(horse_id_list, skip=True)
# 血統テーブルの作成
peds_new = preparing.get_rawdata_peds(html_files_peds)
# テーブルの更新。元々のテーブルが存在しない場合は、新たに作成される。
preparing.update_rawdata(LocalPaths.RAW_PEDS_PATH, peds_new)
これで、必要な5つのテーブル
- レース結果テーブル(
results.pickle) - レース情報テーブル(
race_info.pickle) - 払い戻しテーブル(
return_tables.pickle) - 馬の過去成績テーブル(
horse_results.pickle) - 血統テーブル(
peds.pickle)
が揃いました。
ステップ2. データ加工
次に、作成した5つのテーブルを加工して、機械学習モデルにインプットできる形にします。
ステップ2-1. 前処理
# レース結果テーブルの前処理を実行
results_processor = preprocessing.ResultsProcessor(
filepath=LocalPaths.RAW_RESULTS_PATH)
# レース情報テーブルの前処理を実行
race_info_processor = preprocessing.RaceInfoProcessor(
filepath=LocalPaths.RAW_RACE_INFO_PATH)
# 払い戻しテーブルの前処理を実行
return_processor = preprocessing.ReturnProcessor(
filepath=LocalPaths.RAW_RETURN_TABLES_PATH)
# 馬の過去成績テーブルの前処理を実行
horse_results_processor = preprocessing.HorseResultsProcessor(
filepath=LocalPaths.RAW_HORSE_RESULTS_PATH)
# 血統テーブルの前処理を実行
peds_processor = preprocessing.PedsProcessor(
filepath=LocalPaths.RAW_PEDS_PATH)
それぞれ、preprocessed_dataに前処理済みデータが入ります。
# 確認
results_processor.preprocessed_data
ステップ2-2. 集計・テーブル結合
馬の過去成績を集計しつつ、前処理の済みの全てのテーブルを結合します。
# ターゲットエンコーディング時に「馬の成績」として扱う項目
TARGET_COLS = [
HorseResultsCols.RANK,
HorseResultsCols.PRIZE,
HorseResultsCols.RANK_DIFF,
'first_corner',
'final_corner',
'first_to_rank',
'first_to_final',
'final_to_rank'
]
# horse_id列と共に、ターゲットエンコーディングの対象にする列
# horse_id列と共に、groupbyの中に入るイメージ
GROUP_COLS = [
'course_len',
'race_type',
HorseResultsCols.PLACE
]
# 前処理済みデータをセット
data_merger = preprocessing.DataMerger(
results_processor,
race_info_processor,
horse_results_processor,
peds_processor,
target_cols=TARGET_COLS,
group_cols=GROUP_COLS
)
# 処理実行
data_merger.merge()
このとき、レース情報テーブルに記載されている日付より過去のデータに絞って成績を集計しなければいけません。
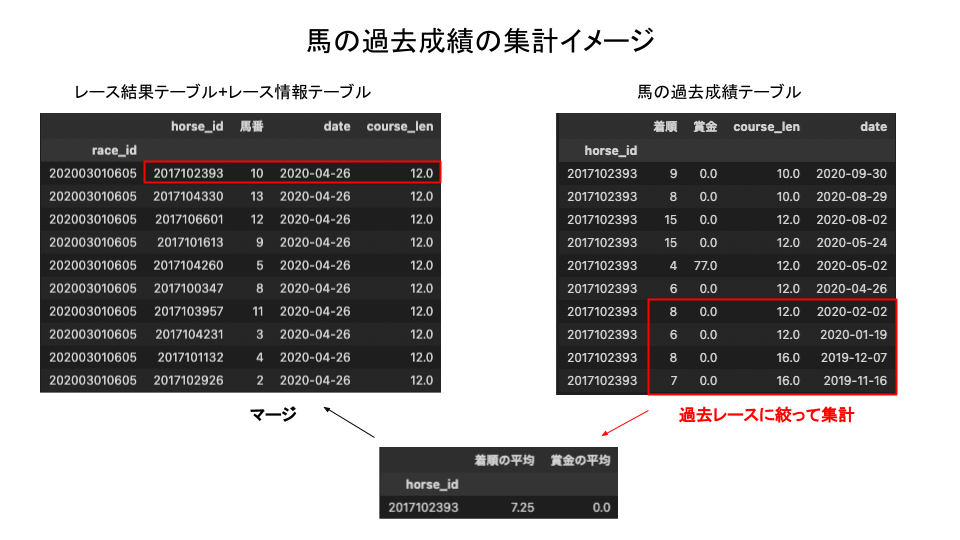
例えば、図の例ではhorse_id='2017102393'の馬はhorse_resultsテーブル上は2020年9月30日までのデータが存在しますが、今考えているのは「2020年4月26日のレースを予測する時に、どのような特徴量を作るか」ということなので、4月26日より未来の情報を使ってはいけないことになります。
もし使ってしまった場合、本来は予測時に使えないデータを参照してしまっていることになり、機械学習の用語で言うと 「リーク」 している状態になります。
また、horse_idごとに成績を集計するだけではなく、「その馬にとって、これから走るコースがどのくらい得意か」の指標として、コースの長さや開催場所ごとの成績集計も行なっています。

上の実行コードにおいて、GROUP_COLSを指定した列に対してcourse_lenと同様に集計を行います。また、「着順」「賞金」などの集計対象列に関しても、TARGET_COLSで指定した列について同様に集計を行なっています。
ステップ2-3. カテゴリ変数の処理
テーブルをマージした後、カテゴリ変数の処理や前走からの経過日数の追加などの、集計を必要としない処理を行います。
feature_enginnering = preprocessing.FeatureEngineering(data_merger)\
.add_interval()\
.dumminize_ground_state()\
.dumminize_race_type()\
.dumminize_sex()\
.dumminize_weather()\
.encode_horse_id()\
.encode_jockey_id()\
.dumminize_kaisai()\
.dumminize_around()\
.dumminize_race_class()
featured_dataに、処理後のデータが格納されています。
# 確認
feature_engineering.featured_data
horse_idとjockey_id(騎手id)はラベルエンコーディング3していて、それ以外のカテゴリ変数についてはダミー変数化しています。
ここでは詳しくは解説しないですが、学習データと実際に賭ける時のデータ(図の「出馬表データ」)でカテゴリを対応させる必要があります。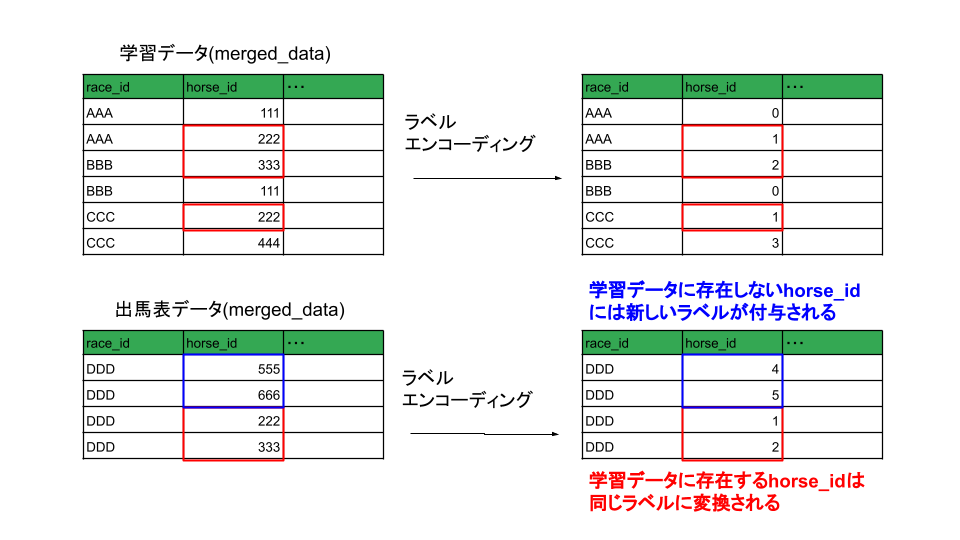
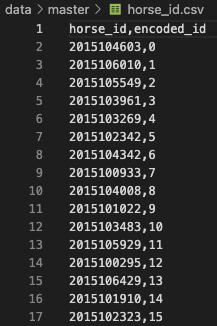
そのため、horse_idとjockey_idそれぞれdata/master/にマスタテーブルを作成し、対応関係を記録しています。
また、通常ダミー変数化は次のようにカテゴリ列を一括で指定して行われることが多いと思います。
pd.get_dummies(df, subset=['race_type', 'ground_state', 'weather'])
しかし、コード中では各種dumminize_×××()にメソッドを分けています。
これは例えば今後「weather列についてはダミー変数化をせずに、ラベルエンコーディングを採用したい」などの変更があった時に、なるべく既存のメソッドを書き換えずに新たなメソッドを作って対応したいという意図があります。特に、他の列に関しての処理を記述したメソッドに手を付けたくないです。
同じメソッドに複数列の処理が書かれていると、例えばweather列の処理を変更する際に、race_type列やground_state列の処理にも影響を及ぼすことになり、保守性の低いコードになってしまいます。
列ごとにメソッドを分けておけば、「dumminize_weather()メソッドはそのままにしておいて、新たにencode_weather()メソッドを追加し、dumminize_weather()メソッドは使用しない」などの対応もできます。
共同開発を見越して、変更に対する影響範囲がなるべく小さくなるように工夫しています。
ステップ3. 学習
これでLightGBMのモデルにインプットできるデータが作成できたので、いよいよ予測モデルを作成します。
# データを訓練データ、検証データ、テストデータに分割し、予測モデルを作成
keiba_ai = training.KeibaAIFactory.create(
feature_enginnering.featured_data,
test_size=0.3,
valid_size=0.3
)
# ハイパーパラメータチューニングをして学習
keiba_ai.train_with_tuning()
モデルの学習、予測、賭ける馬券の決定などを行う競馬AIの本体をKeibaAIクラスで定義していますが、KeibaAIクラスのオブジェクトを作成するKeibaAIFactoryクラスを別途用意しています。
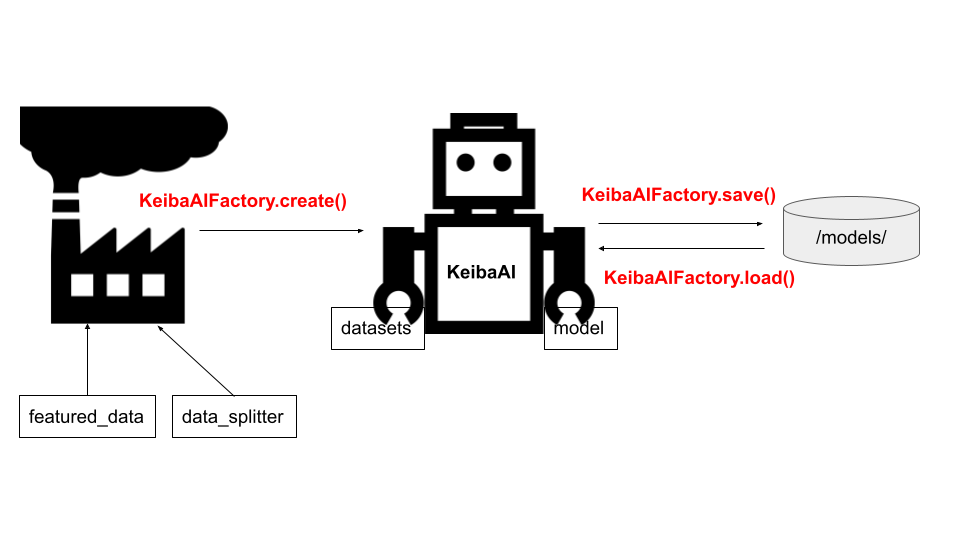
KeibaAIFactoryクラスに、モデルのセーブ・ロード機能も実装しています。
# モデル保存
# models/(実行した日付)/(version_name).pickleに、モデルとデータセットが保存される
training.KeibaAIFactory.save(keiba_ai, version_name='model_2018_2021')
# モデルをロード(セーブした日付が2022年8月9日の場合)
loaded_ai = training.KeibaAIFactory.load(
'models/20220602/basemodel_2018_2021.pickle'
)
例えばセーブした日付が2022年8月9日の場合、以下のパスにモデルを保存したpickleファイルが生成されます。
models
└── 20220809
└── basemodel_2018_2021.pickle
この時、pickleファイルに保存されているのは、分割されたデータセットとハイパーパラメータ付きのLightGBMモデルを保持した、KeibaAIクラスのオブジェクトです。モデル・データセット・ハイパーパラメータを紐づけて管理することによって、精度向上に向けた実験モデルを複数作成して検証・比較しつつ、すぐに本番運用ができるバージョンも残す、などの対応がしやすくなります。
このような「オブジェクトの生成に特化した機能」を持つクラスをFactoryといい、オブジェクトの生成と具体的な処理を分離することで、より柔軟にオブジェクトを利用することができます。(厳密には「Factory Methodパターン」と言うそうです)
「予測にどの変数が効いているか」を示す、特徴量の重要度を見てみましょう。
# 特徴量の重要度を表示
keiba_ai.feature_importance()
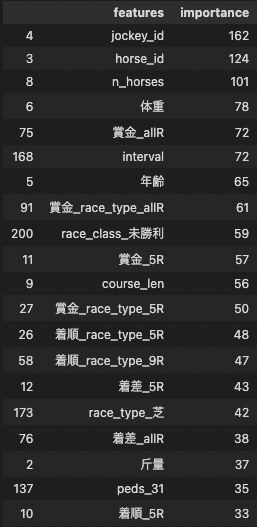
ラベルエンコーディングした騎手idや馬id、出走頭数(n_horses)、馬体重、過去にゲットした賞金、出走間隔(interval)などが効いているようです。race_type(芝orダート)ごとの過去成績も効いていますね。
ステップ4A. 実際に賭ける
例として2022年1月8日に開催されるレースを実際に予想する場合を考えます。
ステップ4A-1. 事前準備
出走する馬が発表されたら、馬の過去成績テーブルと血統テーブルを更新します。前日などにやっておくのが良いでしょう。
# レースidを取得
race_id_list = preparing.scrape_race_id_list(['20220108'])
# 出走するhorse_idの取得
horse_id_list = preparing.scrape_horse_id_list(race_id_list)
# 馬の過去成績テーブルの更新
# 直近レースが更新されている可能性があるので、skip=Falseにして上書きする
html_files_horse = preparing.scrape_html_horse_with_master(
horse_id_list,
skip=False
)
horse_results_20220108 = preparing.get_rawdata_horse_results(html_files_horse)
preparing.update_rawdata(
LocalPaths.RAW_HORSE_RESULTS_PATH,
horse_results_20220108
)
# 血統テーブルの更新
html_files_peds = preparing.scrape_html_ped(
horse_id_list,
skip=True
)
peds_20220108 = preparing.get_rawdata_peds(html_files_peds)
preparing.update_rawdata(
LocalPaths.RAW_PEDS_PATH,
peds_20220108
)
# processorの更新
horse_info_processor = preprocessing.HorseInfoProcessor(
filepath=LocalPaths.RAW_HORSE_INFO_PATH
)
horse_results_processor = preprocessing.HorseResultsProcessor(
filepath=LocalPaths.RAW_HORSE_RESULTS_PATH
)
peds_processor = preprocessing.PedsProcessor(
filepath=LocalPaths.RAW_PEDS_PATH
)
ステップ4A-2. レース当日
学習済みモデルをロードしてスタンバイしておきます。
# 学習済みモデルをロード
keiba_ai = training.KeibaAIFactory.load('models/(日付)/(version_name).pickle')
レース直前に馬体重が発表されたら、出馬表を取得します。学習の際にスクレイピングしたraceページは、過去のレース結果が記録されているページなので、これから出走する馬の情報やレースの情報は、raceページとは別の出馬表ページからスクレイピングする必要があります。
# 一時的に出馬表を保存するパスを指定
filepath = 'data/tmp/shutuba.pickle'
# 出馬表の取得
preparing.scrape_shutuba_table(race_id_list[0], '2022/1/8', filepath)
学習データと同様の処理を行ってモデルにインプットするデータを作成します。
# 出馬表の加工
shutuba_table_processor = preprocessing.ShutubaTableProcessor(filepath)
# テーブルのマージ
shutuba_data_merger = preprocessing.ShutubaDataMerger(
shutuba_table_processor,
horse_results_processor,
peds_processor,
target_cols=TARGET_COLS,
group_cols=GROUP_COLS
)
shutuba_data_merger.merge()
# カテゴリ変数の処理
feature_enginnering_shutuba = preprocessing.FeatureEngineering(shutuba_data_merger)\
.add_interval()\
.dumminize_ground_state()\
.dumminize_race_type()\
.dumminize_sex()\
.dumminize_weather()\
.encode_horse_id()\
.encode_jockey_id()\
.dumminize_kaisai()\
.dumminize_around()\
.dumminize_race_class()
# 最終的にインプットするデータ
X = feature_enginnering_shutuba.featured_data.drop(['date'], axis=1)
学習済みモデルに入れると、予測スコアが出力されます。
keiba_ai.calc_score(
X,
policies.StdScorePolicy
).sort_values('score', ascending=False)
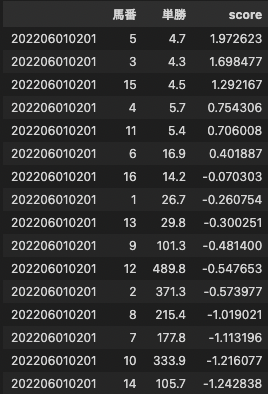
ここで、LightGBMによる予測スコア(=3着以内に入る確率)は、シンプルにその行のインプットから予測した絶対評価ですが、競馬はレースなので「その馬が勝ちやすいか」は本来、他の馬のスコアとの比較で決まるはずです。
そこで、StdScorePolicyではレース内で予測スコアを標準化し、「他の馬の予測スコアに比べてどの程度高いか」相対評価を行います。
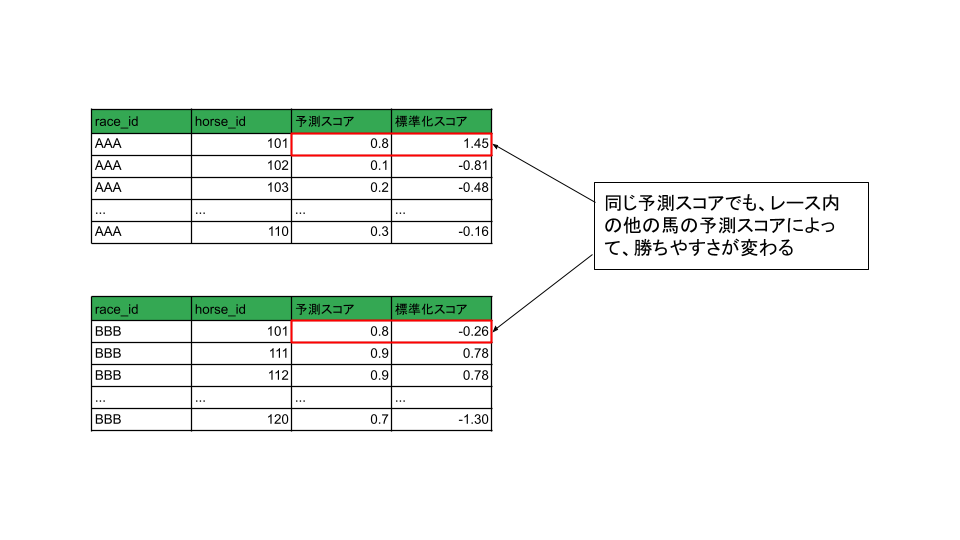
標準化とは次のような演算のことを言います
$$
(標準化スコア) = \frac{(予測スコア) - (予測スコアのレース内平均)}{(予測スコアのレース内標準偏差)}
$$
このように、スコアの計算方法には様々なものが考えられるため、次のようなmodules/polices/に次のようなモジュールを置いて計算ロジックを追加できるように設計しています。
from abc import ABCMeta, abstractstaticmethod
import pandas as pd
from modules.constants import ResultsCols
class AbstractScorePolicy(metaclass=ABCMeta):
@abstractstaticmethod
def calc(model, X: pd.DataFrame):
raise NotImplementedError
class BasicScorePolicy(AbstractScorePolicy):
"""
LightGBMの出力をそのままscoreとして計算。
"""
@staticmethod
def calc(model, X: pd.DataFrame):
score_table = X[[ResultsCols.UMABAN, ResultsCols.TANSHO_ODDS]].copy()
score = model.predict_proba(X.drop([ResultsCols.TANSHO_ODDS], axis=1))[:, 1]
score_table['score'] = score
return score_table
class StdScorePolicy(AbstractScorePolicy):
"""
レース内で標準化して、相対評価する。「レース内偏差値」のようなもの。
"""
@staticmethod
def calc(model, X: pd.DataFrame):
score_table = X[[ResultsCols.UMABAN, ResultsCols.TANSHO_ODDS]].copy()
score = model.predict_proba(X.drop([ResultsCols.TANSHO_ODDS], axis=1))[:, 1]
score_table['score'] = score
# レース内でスコアを標準化
standard_scaler = lambda x: (x - x.mean()) / x.std(ddof=0)
score_table['score'] = score_table['score'].groupby(level=0).transform(standard_scaler)
return score_table
class MinMaxScorePolicy(AbstractScorePolicy):
"""
省略
"""
ここで、抽象クラスAbstractScorePolicyにより、スコア計算ロジックを記述するクラスの型だけを決めており、その型に則って開発者が計算ロジックを追加していくことができる設計にしています。
抽象クラスとは「クラスの型決めるクラス」のようなもので、これを作ることによって以下のようなメリットがあります。
- 処理が統一化され、何の処理をしているか分かりやすくなる
- 共有の処理を全てのクラスに書き込む必要が無くなる
- 共同開発で開発者がクラスを定義した際に、メソッドの実装忘れやメソッド名のミスを防ぐことができる
ステップ4B. シミュレーション
テストデータを使って回収率や的中率のシミュレーションを行います。
simulator = simulation.Simulator(return_processor)
T_RANGE = [0.5, 3.5]
N_SAMPLES = 100
returns = {}
#「馬の勝ちやすさスコア」の閾値を変化させた時の成績を計算
for i in tqdm(range(N_SAMPLES)):
# T_RANGEの範囲を、N_SAMPLES等分して、thresholdをfor分で回す
threshold = T_RANGE[1] * i / N_SAMPLES + T_RANGE[0] * (1-(i/N_SAMPLES))
try:
# 賭ける馬券を決定
actions = keiba_ai.decide_action(
keiba_ai.datasets.X_test, # テストデータ
policies.StdScorePolicy, #「馬の勝ちやすさ」スコアを決める方針を選択
policies.BetPolicyTansho, # 賭け方の方針を選択
threshold=threshold #「馬の勝ちやすさスコア」の閾値
)
returns[threshold] = simulator.calc_returns(actions)
except Exception as e:
print(e)
break
returns_df = pd.DataFrame.from_dict(returns, orient='index')
returns_df.index.name = 'threshold'
# 回収率をプロット
simulation.plot_single_threshold(returns_df, N_SAMPLES, label='tansho')
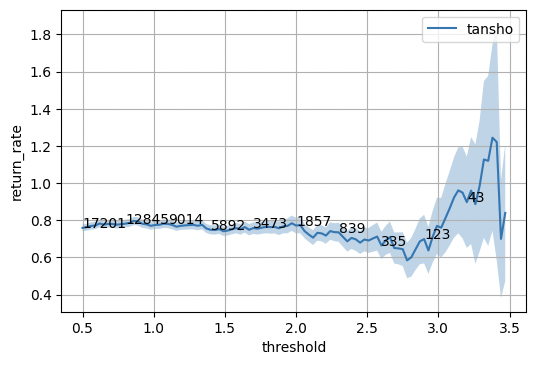
それぞれ、
- 横軸:「馬の勝ちやすさスコア」の閾値。閾値を超えた馬に賭ける。
- 縦軸:回収率
- 薄く塗られたエリア:は回収率の統計的なぶれ幅(標準偏差)
- 線上の数字:何枚の馬券を賭けることになるか
を示しています。(例えば「スコア2.0を超えた馬に単勝で賭ける」という戦略を取ると、1857枚くらいの馬券を購入することになり、回収率は80%程度になる)
閾値を厳しく設定して、賭ける馬を絞って単勝を購入すれば、回収率100%を超えているエリアがあることが分かります。
ただし、その分賭ける枚数が少ないため、統計的なぶれも大きくなっています。また、これは「100レース予測して3枚だけ賭ける」というような賭け方になってしまうことを表しており、「コンスタントに勝ち続ける」モデルにするにはもう少し改善が必要なようです。
まとめ
この記事では、競馬予想AIの作り方を解説する同時に、一回きりの「予測してみた」で終わらせず、継続的に開発・運用していけるような機械学習モデルを作るためにどのようなソースコードの実装を心がけたか、見てきました。最後にもう一度、記事中に出てきたポイントをまとめておきます。
ポイントまとめ
- ソースコード本体をモジュールに分けることで、実行コードをなるべく短くスッキリさせ、「どんな処理が行われているのか」が実行コードを見れば一目で分かるように心がけた。
- そのためにも、クラス名や関数名にはこだわり、名前で処理内容が分かるようにする。
- データやモジュールはディレクトリに分けて整理し、ファイル名はなるべく具体的なものにする。
- スクレイピングの際は、テーブルデータに変換する前に、一度htmlの形で保存する。
- ファイルパスは定数としてまとめて定義しておく。
- メソッド同士はなるべく依存関係を持たないようにし、変更に対する影響範囲が小さくなるようにする。
- Factoryを使うことで、オブジェクトの生成と具体的な処理を分離し、より柔軟にオブジェクトを利用することができる。
- 抽象クラスによってクラス定義を型化し、可読性や保守性を上げる
少しでも参考になれば幸いです。
これを機に「競馬予想AI作ってみよう」となった人や、ソースコードの詳細を知りたい方は、是非以下の書籍を見ていただければと思います。
(補足)回収率の標準偏差の計算方法
まず、期待値$\mu$は、1レースで平均して払い戻し金額が何円かを表します。
$$
\mu = \frac{1}{n}(X_1 + X_2 + \dots + X_n)
$$
Xが$\mu$から「どのくらいばらついているか」を表す分散$V[X]$は次の式で表されます。
$$
V[X] = \frac{1}{n}\left[ (X_1-\mu)^2 + (X_2-\mu)^2 + \dots + (X_n-\mu)^2 \right]
$$
これの平方根を取ったものが標準偏差です。
$$
\sigma[X] = \sqrt{V[X]}
$$
次に、「nレース分の回収率」の標準偏差を求めます。まず、払い戻し金額の合計を$G$、購入金額を$b$とすると回収率の標準偏差$\sigma[X]$は
$$
\sigma[X] = \sigma\left[\frac{G}{b}\right] = \frac{\sigma[G]}{b} = \frac{\sqrt{V[G]}}{b}
$$
となります。ここで、$X_1, X_2, \dots, X_n$がそれぞれ独立のとき、
$$
V[G] = V[X_1] + V[X_2] + \dots + V[X_n]
$$
と和に分解することができます。独立とは、例えば「$X_1$がわかっても$X_2$に影響しない」ということです。次に、$X_1, X_2, \dots, X_n$が同一分布に従う(平均、標準偏差が全て同じ)と仮定します。すると、
$$
V[G] = V[X] + V[X] + \dots + V[X] = nV[X]
$$
となるので、回収率の標準偏差は
$$
\sigma[r] = \frac{\sqrt{nV[X]}}{b} = \frac{\sqrt{n}\sigma(X)}{b}
$$
となります。
-
「その場限りの」「単発的に行われる」といった意味。 ↩
-
「機械学習チーム(Machine Learning)/開発チーム」と「運用チーム(Operations)」がお互いに協調し合うことで、機械学習モデルの実装から運用までのライフサイクルを円滑に進めるための管理体制(機械学習基盤)を築くこと、またはその概念全体を指す。(引用元:https://atmarkit.itmedia.co.jp/ait/articles/1911/21/news018.html ) ↩
-
カテゴリ変数を整数に変換すること ↩