はじめに
Google Cloudの認定資格「Professional Machine Learning Engineer」の勉強にあたり、BigQuery MLを実際に使うことで理解を深めたいというモチベがありました。
kaggleのPlaygroundのコンペで丁度シンプルな購入数予測タスクが開催されていたので、BigQuery MLを使って取り組んでみました。
BigQuery
BigQueryはデータ分析を行うことを目的としたGoogle Cloudのデータウェアハウスサービスの一つで、格納したデータに対してクエリを実行することで多彩な処理を行うことができます。
サーバーレスなフルマネージドサービスであり、データに応じて自動でスケーリングが行われます。
要点を絞ると、データを蓄積し、データを分析できる機能です。
BigQuery ML
BigQueryのデータに対して、SQLクエリで機械学習モデルを作成、実行できる機能です。
機械学習モデルの作成や前処理を行うステートメントを利用することができます。
大規模なデータセットを利用して機械学習を行う場合、高度なプログラミング技術と知識が必要になります。データをよく理解しているがプログラミングの経験が少ないデータアナリストは、機械学習を利用することが難しいです。BigQuery MLは、そのようなユーザーに対して既存のSQLツールやスキルで機械学習を行えるようなサービスとなっています。
BigQueryのデータを利用してクエリを実行できる環境であれば、基本的にはBigQuery MLは利用可能です。
- Google Cloud Console
-
bqコマンド - BigQuery REST API
- BIツール、Lupyter notebookなどの外部ツール
BigQuery MLの利用
本記事ではkaggleの売り上げ予測タスクのデータを使ってBigQuery MLの実行を行います。
GCPのプロジェクトは作成していることを前提とし、Google Cloud Console上で作業を行っています。
データセットの準備
kaggleの売り上げ予測タスクは学習用データとテスト用データとしてtrain.csvとtest.csvが与えられます。
あらかじめローカルに落としてきた2つのファイルをBigQueryに移していきます。
データセットを作成
はじめにBigQueryのページに遷移し、新しいデータセットを作成します。今回はkaggle_PS_3_19という名前でデータセットを作成しており、それ以外の設定についてはデフォルトのままとしています。
テーブルを作成、データのインポート
先ほど作成したデータセット上でテーブルを作成します。
テーブル作成時は、ローカルに落としてきたcsvファイルをアップロードするように設定しています。
以下の画像はtrain.csv用のテーブルを作成したときの設定となります。
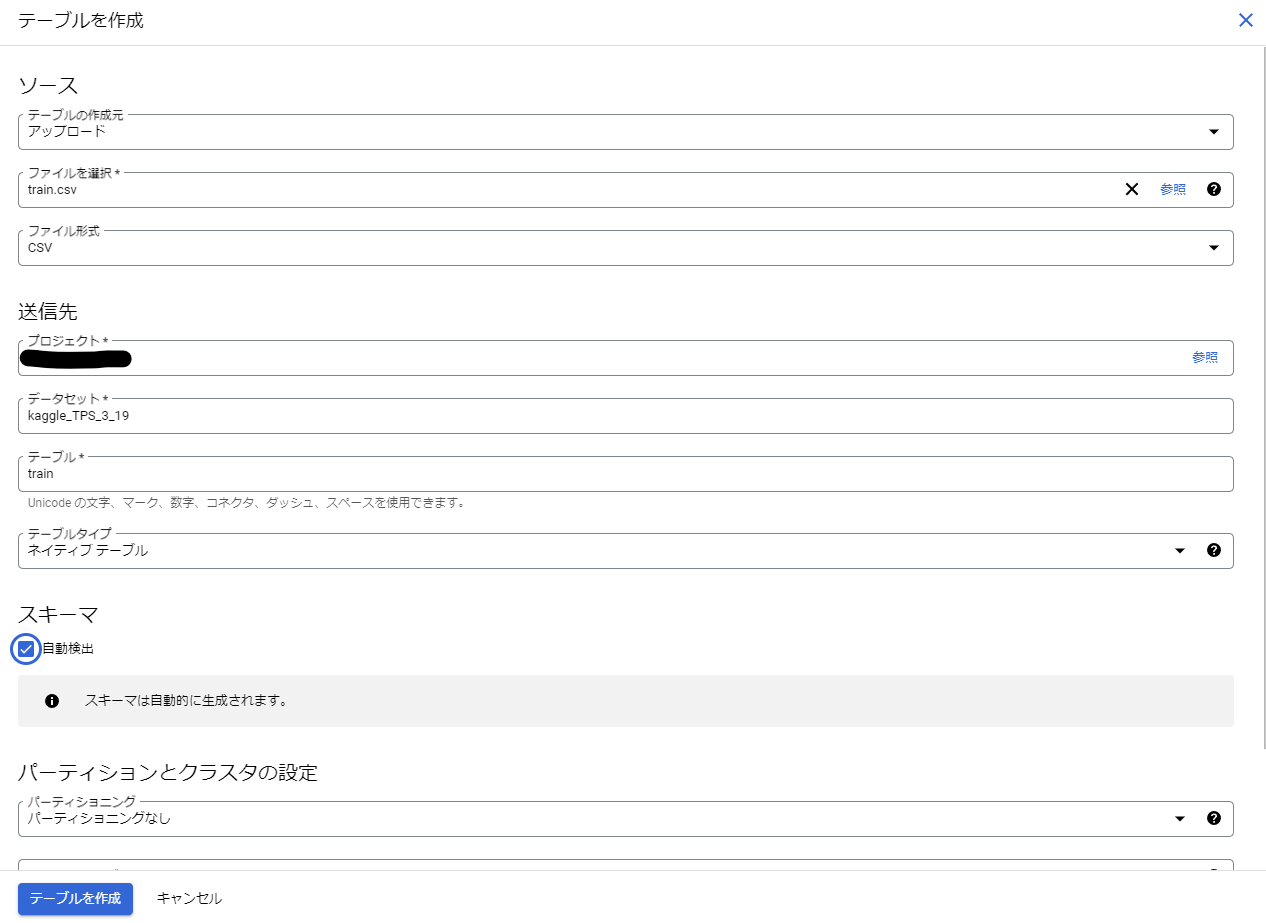
スキーマの自動検出がデフォルトではオフになっているのでチェックをつけています。
プロジェクト名、データセット名、テーブル名は作成されたものを入力し、それ以外の設定はデフォルトのままにしています。
テーブルを作成ボタンを押すとテーブルの作成が完了します。
train.csvから作成されたtrainテーブルのスキーマは以下の通りです。
- id : プライマリーキー
- date : 日にち
- country : 国(カテゴリ変数)
- store : 店名(カテゴリ変数)
- product : 製品名(カテゴリ変数)
- num_sold : 今回の予測タスクの目的変数
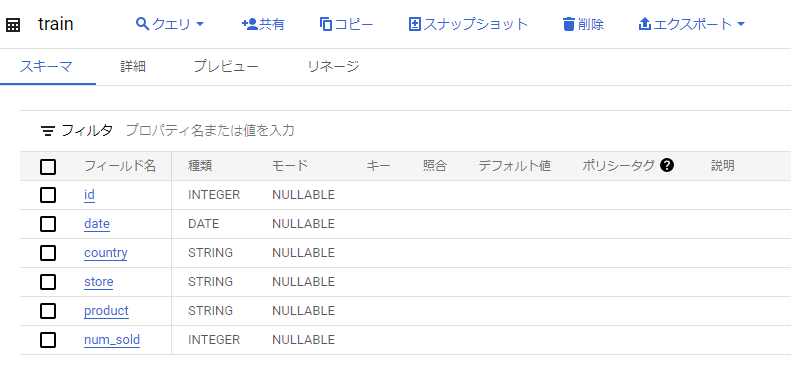
スキーマを自動検出にした場合に意図しないスキーマになることがあるので、後から修正するか、手動でスキーマを作成しましょう。
test.csvについても同様にテーブルを作成しました。
testテーブルはtrainテーブルからnum_soldカラムを除いたカラム構成となっています。
シンプルな線形回帰モデルを構築
モデルの作成、学習
カラムをそのまま使用したシンプルな線形回帰モデルの学習を行います。(※idカラムなどは本来不要なカラムです)
機械学習モデルの作成にはCREATE MODELステートメントを使用します。
-- standardSQL
CREATE MODEL `kaggle_TPS_3_19.simple_linear_reg_model`
OPTIONS(model_type='LINEAR_REG', INPUT_LABEL_COLS=['num_sold']) AS
SELECT
id,
date,
country,
store,
product,
num_sold
FROM
`kaggle_TPS_3_19.train`
クエリの詳細について解説します。
CREATE MODEL `kaggle_PS_3_19.simple_linear_reg_model`
kaggle_PS_3_19データセットにsimple_linear_reg_modelを作成します。
既に存在するモデルを上書きする場合はCREATE OR REPLACE MODELとしてください。
モデルが存在しないときだけ新しいモデルを作成する場合はCREATE MODEL IF NOT EXISTSとしてください。
OPTIONS(MODEL_TYPE='LINEAR_REG', INPUT_LABEL_COLS=['num_sold'])
OPTIONSでモデルの設計を行います。
ここで使用しているオプション以外にも多くのオプションがあるので、詳しくはドキュメントを参考にしてください
-
MODEL_TYPE : モデルのタイプを指定します
- LINEAR_REG : 線形回帰モデル
- RANDOM_FOREST_REGRESSOR : XGBoostを利用したランダムフォレストによる回帰モデル
- DNN_REGRESSOR : ディープニューラルネットワークによる回帰モデル
- AUTO_ML_REGRESSOR : AutoMLを利用した回帰モデル
- LOGISTIC_REG : ロジスティック回帰を利用した分類モデル
- KMEANS : K-means法を利用したクラスタリング
- etc…
- INPUT_LABEL_COLS : 目的変数となるカラムを配列の形式で指定します
… AS
SELECT
id,
date,
country,
store,
product,
num_sold
FROM
`kaggle_TPS_3_19.train`
AS以降にモデルに使用するデータを指定します。目的変数もここに含めるようにしてください
モデルの評価
クエリの実行が完了すると、データセット内にモデルが作成されます。
作成されたモデルを選択すると、どのようなモデルが作られたかこちらで確認することができます。

評価を選択すると学習の損失の結果を確認することができます。
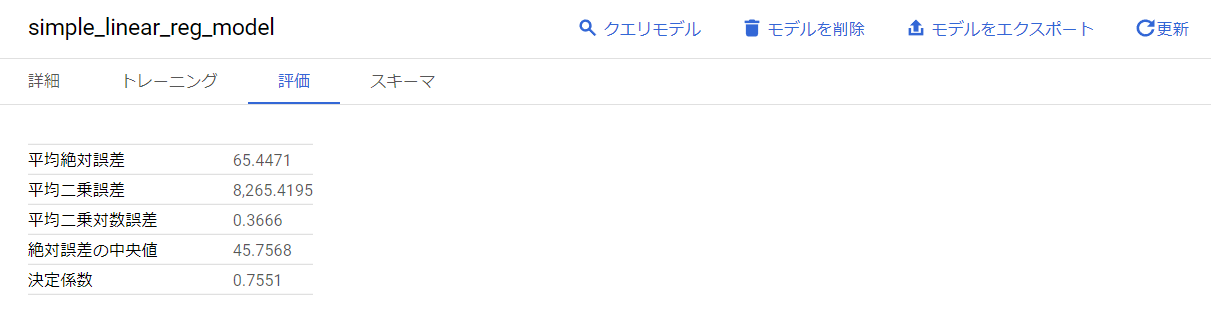
また、ML.EVALUATEを使用して、クエリで特定のデータに対しての精度を確認することができます。
ML.EVALUATEでは複数の評価指標を出力します。
-- standardSQL
SELECT
*
FROM
ML.EVALUATE(MODEL `kaggle_TPS_3_19.simple_linear_reg_model`, (
SELECT
id,
date,
country,
store,
product,
num_sold
FROM
`kaggle_TPS_3_19.train`
))
クエリの実行結果はこのようになります。

モデルのテスト
testデータに対する予測結果を確認する場合はML.PREDICTを使用します。
この関数は元のデータと予測結果を出力します。
もともとの目的変数はnum_soldだったため、ここでは予測結果はpredicted_num_soldというカラム名で出力されます。
-- standardSQL
SELECT
id,
predicted_num_sold
FROM
ML.PREDICT(MODEL `kaggle_TPS_3_19.simple_linear_reg_model`, (
SELECT
id,
date,
country,
store,
product,
FROM
`kaggle_TPS_3_19.test`
))
ORDER BY id
上のクエリを実行すると以下のように出力されます。

クエリ結果を別の場所に保存してもいいし、モデルをGoogle Cloud Storageに保存することもできます。
タスクに応じて必要な処理を行ってください。
ここまでが機械学習の一連の流れになります。
BigQuery MLの概要でも説明したとおり、クエリのみで機械学習ができるようになっています。
より細かいオプションを使っていくことで、精度をさらに高めていくことが可能です。
カラムの前処理
自動で実行される前処理と、ユーザーが手動で設定できる前処理の2つの方法が存在します。
自動前処理の仕組み
BigQuery MLではカラムの型に応じて学習、評価、推論のいずれにおいても同じ前処理が自動で実行されるようになっています。
モデルの入力として与えられた各カラムの値(特徴量)は型に応じて自動で特定の前処理が実行されます。
各型に応じた変換が実行されます。
- 数字型 : 決定木を利用したモデルを除いて、平均が0になるよう標準化します
- その他のカラム : One-hotカラムに変換します
- ARRAY : Multi-hotカラムに変換します
- TIMESTAMP型 : Unix時間、分、日、週、月、年、一年の何週目、時間のカラムを作成(※STRING型に変換されるものがあるので注意)
- STRUCT型 : 内部の各フィールを展開してカラムを作成します。
欠損データは以下のように処理されます。
- 数字型 : NULLのデータはそのカラムの平均値を代わりに使用します
- One-hot化カラム : NULLをカテゴリの一つの値として扱います。学習時に観られなかったカテゴリは重み0として計算されます
- TIMESTAMP型 : TIMESTAMP型は自動前処理で複数のカラムに変換されますが、UNIX時間はデータの平均値を代わりに使用し、それ以外のカラムはカラムの型に応じた欠損処理が実行されます。
- STRUCT型 : STRUCT型の各フィールドはフィールドの型に応じて欠損処理が実行されます。
それぞれの仕組みを理解しておかないと、学習に失敗することがあります。
例えば、学習データとテストデータにTIMESTAMP型のカラムが存在し、学習データの値の範囲が2017年~2022年、テストデータの値の範囲が2023年のだったとします。
自動前処理によってTIMESTAMP型のデータから年カラムが作成されます。
この年カラムはSTRING型のためさらに変換によって**2017~2022年のone-hotが生成されます。
しかし、2023年は存在しないため、テストデータの2023年は予測時に欠損データとして扱われてしまいます。
このようなことを防ぐためには手動で前処理を行う必要があります。
手動前処理の仕組み
モデル作成時のCREATE MODELステートメントでTRANSFORM句を使用することで手動で前処理を設定することができます。
TRANSFORM句で定義されたデータに対してさらに自動前処理を実行するという流れになることに注意してください。
-- standardSQL
CREATE OR REPLACE MODEL `kaggle_TPS_3_19.fixed_linear_reg_model`
TRANSFORM(
EXTRACT(YEAR FROM CAST(date AS TIMESTAMP)) AS year,
EXTRACT(MONTH FROM CAST(date AS TIMESTAMP)) AS month,
EXTRACT(DAY FROM CAST(date AS TIMESTAMP)) AS day,
country,
store,
product,
num_sold
)
OPTIONS(model_type='LINEAR_REG', INPUT_LABEL_COLS=['num_sold']) AS
SELECT
*
FROM
`kaggle_TPS_3_19.train`
使用するデータから、さらにどのようなカラムを使用するかを選択することができます。
ここでは以下の設計になるようTRANSFORMの処理を作成しています。
- idは使用しない
- dateカラムの年、月、日をint型のカラムとして使用
- dateカラムそのものは使用しない
- それ以外のカラムは元のデータのまま使用
また、BigQueryでは、ML用の変換関数も多数定義されています。
以下は一例ですが、他の関数について気になる方はドキュメントを見てください。
- ML.MAX_ABS_SCALER() : 値の範囲が-1~1になるように変換
- ML.MIN_MAX_SCALER() : 値の範囲が0~1になるように変換
- ML.FEATURE_CROSS() : 特徴クロスを行い、複数のカラムの組み合わせカラムを作成します
まとめ
クエリを利用してモデルを作成、学習が行えるBigQuery MLについて利用例も含めて紹介させていただきました。
簡潔に作れる分、精度を上げるためには前処理の方法やハイパーパラメータの選定などを適切に行っていく必要があります。
前処理のためのデータの分析を行う場合は、Looker Studioなどのサービスを併用していくとよいかと思います。