この記事はCAMPHOR- Advent Calendar 2018の18日目の記事です。
はじめに
Webサービス開発にハマっている@p1assです。
最近、クソアプリと言われても仕方ないレベルのしょうもなさを持つ「えもじっく」というサービスをリリースしました😄
https://emojic.ch
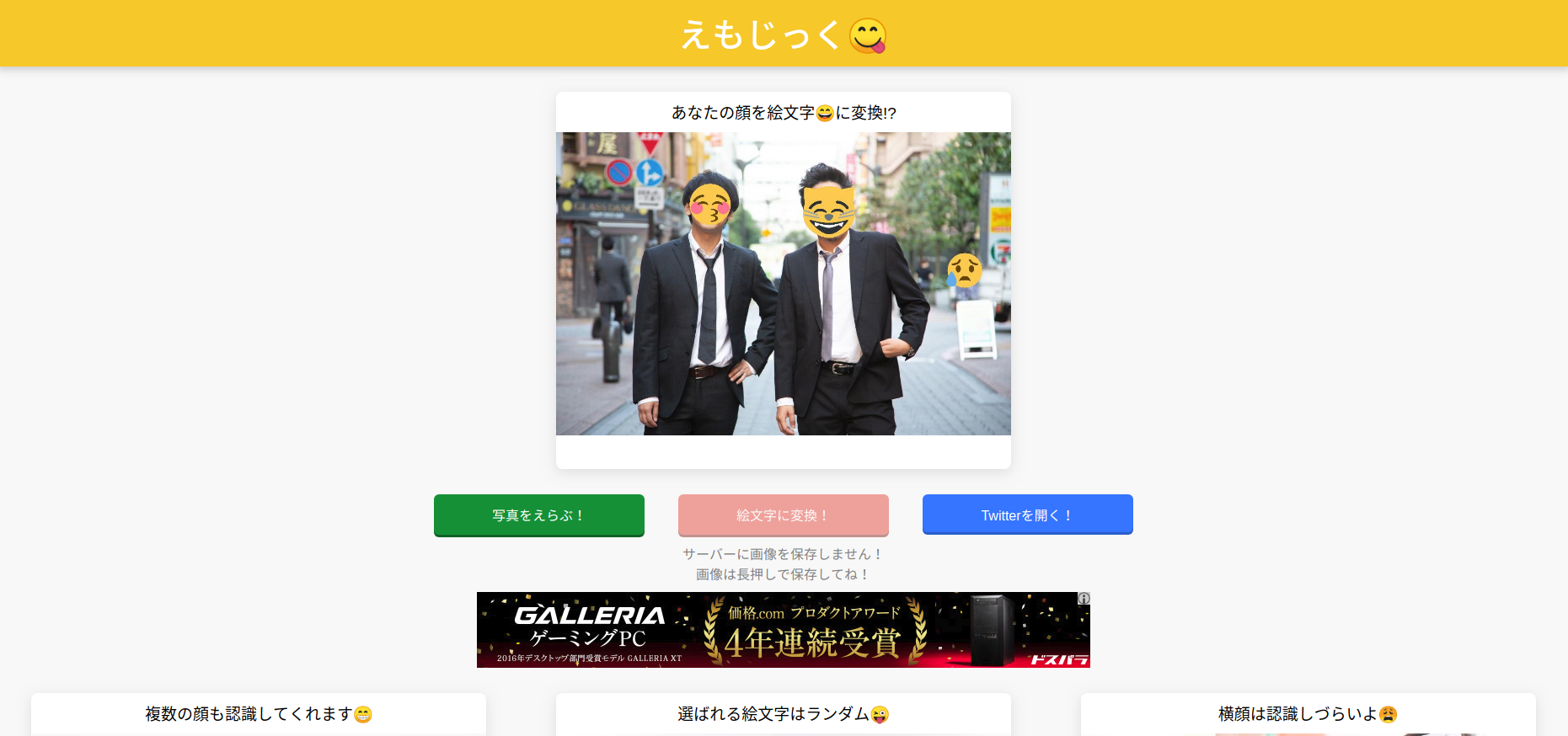
えもじっくは**「顔写真の上に絵文字のスタンプ😄を合成してくれるWebサービス」**です。
 (↑画像を選ぶとこんな感じの画像が返ってきます)
(↑画像を選ぶとこんな感じの画像が返ってきます)
顔認識はかなり高精度なので、是非みなさんも一度試してみてください!💪
https://emojic.ch
さて、今回はえもじっくを作る上で用いたAmazon RekognitionやServerless Framework、CircleCIについての知見をピックアップしながら紹介したいと思います。
また、ソースコードはすべてGitHubにて公開されているので、興味がある方はそちらもご覧ください。
tl;dr
- 人の顔を絵文字😇にするWebサービス**「えもじっく」**を作った
- AWS Rekognitionを使って顔認識をやってみた
- バックエンドAPIをServerless Frameworkで構築した
- フロントエンドのビルドとServerless FramworkのデプロイフローをCircleCIで自動化した
全体の要件とアーキテクチャの確認
まずは、サービスに必要な機能をリストアップしてみます。
- PCやスマホの写真をアップロードする
- サーバー側で顔認識を使って、顔の上に絵文字を貼り付ける
- 変換した画像をクライアント側に返して表示する
以上の要件を満たすために、次のようなアーキテクチャで構築しました。
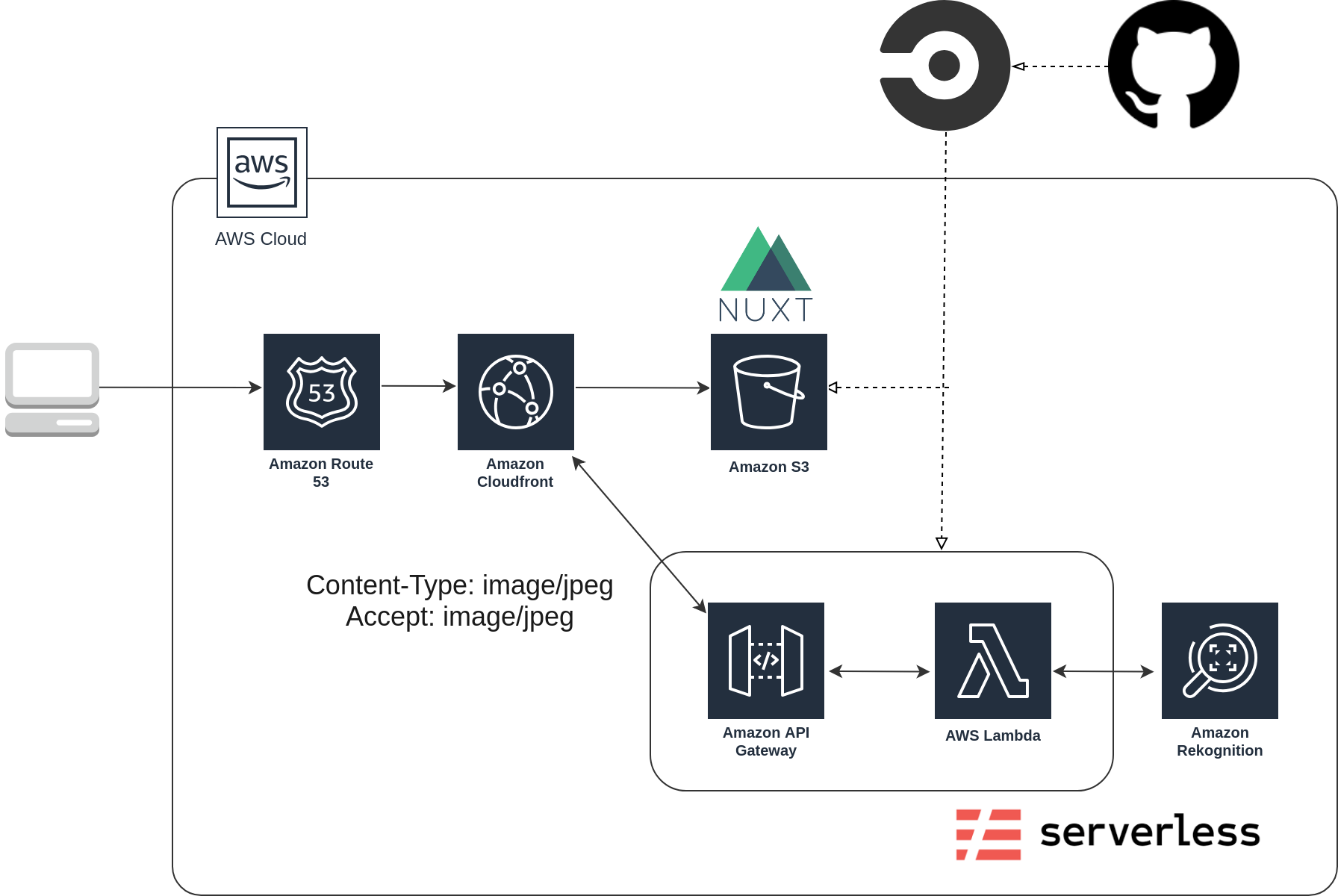
通常バイナリデータを扱う際には、multipart/form-dataを使ったり、Base64にエンコードして通信を行うことが多いらしいです。しかし今回は、「プライバシーの都合からS3等にアップロードされた画像を保存したくない」ということで、直接バイナリをアップロードする方式を取りました。
なお、フロントエンドに関しては、Nuxt.jsを使っており、CircleCI上で動く自作スクリプトで静的に書き出して、S3にホスティングしています。
参考 : WebAPI でファイルをアップロードする方法アレコレ
Amazon Rekognitionを使った顔認識😄を実装する
それでは、このサービスの要でもある顔認識の部分について紹介したいと思います。
今回は、抜粋したコードを載せますので、詳しいコードがみたい方はGitHubをご覧ください。
依存関係のインストール
pip install -r requirements.txt
顔認識を行う
def detectFacesByRekognition(image_binary: bytes) -> List[List[float]]:
client = boto3.client('rekognition')
response = client.detect_faces(
Image={'Bytes': image_binary}, Attributes=['ALL'])
faces = list()
for face_info in response["FaceDetails"]:
faces.append(face_info["BoundingBox"])
print(face_info["BoundingBox"])
return faces
簡単にAmazon Rekognitionについて説明すると、**AWSが提供する機械学習モデルを用いて、画像が動画の分析が行えるサービスです。**今回使った顔認識だけでなく、感情分析や、物体検出、顔認証といったサービスを提供しています。
https://aws.amazon.com/jp/rekognition/
boto3からAmazon RekognitionのAPIに画像のバイナリを投げて、顔の座標を取得しています。
バイナリデータをOpenCVで扱える配列に変換する
def convertBinaryToImageArray(binary: bytes) -> np.ndarray:
# 一旦Pillow用の画像データにする
pil_image = Image.open(io.BytesIO(binary))
# PIL.JpegImagePlugin.JpegImageFile -> numpy.ndarray(RGB)に変換
image_array = np.asarray(pil_image)
return image_array
顔認識はAmazon Rekognitionで行いますが、絵文字との合成はOpenCVを使って行います。。そのため、送られてきたバイナリデータをOpenCVで扱える配列に変換する必要がありますが、バイナリから直接OpenCVで使える形式に変換することはできません。
そこで、一旦Pillowでバイナリデータを読み込んでから、再度OpenCVで扱える配列に変換しています。
参考 : Python・OpenCVでバイナリデータを扱う場合
参考 : Pythonの画像読み込み: PIL, OpenCV, scikit-image
写真と絵文字の画像を合成する
def pasteEmoji(image: np.ndarray, face: List[float]) -> np.ndarray:
height, width, _ = image.shape[:3]
face_top = round(height * face["Top"])
face_left = round(width * face["Left"])
face_height = round(height * face["Height"])
face_width = round(height * face["Width"])
# 顔の枠を正方形にする
face_size = round(max(face_height, face_width))
# 絵文字が顔の真ん中にくるように座標を調整
if face_height > face_width:
face_left -= round((face_size - face_width)/2)
elif face_width > face_height:
face_top -= round((face_size - face_height)/2)
# 顔が画像からはみ出しそうなときはサイズを小さくする
if face_top + face_size > height or face_left + face_size > width:
face_size = min(height - face_top, width - face_left)
# -1 : アルファチャンネルで読み込む
emoji = cv2.imread(
"emoji/{:0=3}.png".format(random.randrange(1, 71, 1)), -1)
# BGRA -> RGBAに変換
emoji = cv2.cvtColor(emoji, cv2.COLOR_BGRA2RGBA)
# 絵文字の画像サイズを顔の大きさに揃える
resized_emoji = cv2.resize(
emoji, (face_size, face_size))
# 透過処理
# https://blanktar.jp/blog/2015/02/python-opencv-overlay.html
mask = resized_emoji[:, :, 3]
mask = cv2.cvtColor(mask, cv2.COLOR_GRAY2BGR)
mask = mask / 255.0
# 予め型キャストしておく
image = image.astype("float64")
# 顔に画像を貼り付け
image[face_top:face_top + face_size,
face_left:face_left + face_size] *= 1 - mask
image[face_top:face_top + face_size,
face_left:face_left + face_size] += mask * resized_emoji[:, :, 0:3]
return image
-
Amazon Rekognitionは顔認識の結果を、画像のサイズに対して相対的に返します(0.0~1.0)。そのため、顔のピクセルを特定するために、それぞれ幅と高さをかけています。
-
絵文字は正方形ですが、顔認識結果は長方形です。絵文字を長方形に引き伸ばしても、あまり見栄えが良くないので、座標の微調整を行っています。
-
OpenCVで絵文字画像を読み込む時、配列の順番がRGBAではなくBGRAとなってしまうので、RGBAに変換してから画像の合成を行っています。
-
絵文字画像はアルファチャンネルのあるPNG画像のため、普通に貼り付けると四角い枠が出来てしまうので、マスクをつかって透過処理を施しています。
参考 : python/OpenCVで透過pngをオーバレイする
Lambdaから読み出される関数を作成
def lambda_handler(event, context):
binary_image = base64.b64decode(event["body"])
faces = detectFacesByRekognition(binary_image)
image = convertBinaryToImageArray(binary_image)
for face in faces:
image = pasteEmoji(image, face)
# レスポンス用のバイナリイメージを作成
# 参考 : https://stackoverrun.com/ja/q/7582988
response_image = io.BytesIO()
Image.fromarray(image.astype('uint8')).save(
response_image, "JPEG")
body = base64.b64encode(response_image.getvalue()).decode('utf-8')
# 204で顔が検出されなかったことを表現
statusCode = 200
if len(faces) == 0:
statusCode = 204
response = {
"statusCode": statusCode,
"headers": {
"Content-Type": "image/jpeg",
"Access-Control-Allow-Origin": os.environ["EMOJIC_ORIGIN"]
},
"body": body,
"isBase64Encoded": True
}
return response
後は、これまで作った関数を呼び出す親元を作成すれば終わりです。
API Gatewayはバイナリデータをサポートしていますが、Lambdaへは、**Base64でエンコードされたものが送られます。**また、レスポンスもBase64でエンコードして返す必要があります。"isBase64Encoded": Trueを忘れずレスポンスに追加しましょう。
その他注意すべき点として、**CORSのヘッダーをレスポンスに含めることが挙げられます。**API GatewayのLambda プロキシ統合の使用をオンにする都合上、Lambda側でAccess-Control-Allow-Originを追加する必要があります。
Serverless Frameworkを使ったデプロイ
次に、Serverless Frameworkを使ったデプロイをしていきます。

「Serverless Frameworkとはなんぞや?🤔」という方に向けて簡単に説明すると、AWSやGCPといったクラウドサービス上に簡単にサーバーレス構成のアプリケーションをデプロイできるフレームワークです。
設定ファイルを書けば、コマンド一発でデプロイすることができ、サービス構成の変更も、設定ファイルを書き換えるだけで対応できます。
詳しくは公式サイトをご覧ください。
https://serverless.com
その設定ファイルであるserverless.ymlですが、いくつかポイントとなる点を抜粋して紹介していきます。
完全なファイルはGitHubからご覧ください。
https://github.com/p1ass/emojic.ch/blob/master/lambda/serverless.yml
ステージング環境によって設定を変える
# 抜粋
provider:
stage: ${opt:stage, self:custom.defaultStage}
apiKeys:
- emojic_api_key_${self:provider.stage}
custom:
defaultStage: dev
origin:
dev: http://localhost:3000
prod: https://emojic.ch
needApi:
dev: false
prod: true
functions:
upload:
environment:
EMOJIC_ORIGIN: ${self:custom.origin.${self:provider.stage}}
events:
- http:
private: ${self:custom.needApi.${self:provider.stage}}
cors:
origin: ${self:custom.origin.${self:provider.stage}}
Serverless Frameworkはデプロイする際に、serverless deploy -s [stage_name]でステージ名を指定できます。
今回は、devとprodの2つの環境を指定できるようにし、APIキーの設定を切り替えたり、CORSの設定を変更できるようにしました。
プラグイン
plugins:
- serverless-python-requirements
- serverless-apigw-binary
- serverless-prune-plugin
1つ目のserverless-python-requirementsですが、Lambdaにアップロードするzipに、pipでインストールするライブラリを内包するために使っています。
2つ目のserverless-apigw-binaryはAPI Gatewayでバイナリをサポートするために使っています。
apigwBinary:
types:
- 'image/jpeg' #image/jpegのレスポンス、リクエストをバイナリで返す
3つ目のserverless-prune-pluginはデプロイするたびにどんどん積まれていく過去のバージョンのデプロイパッケージをS3から削除するために使っています。
prune:
automatic: true
number: 3
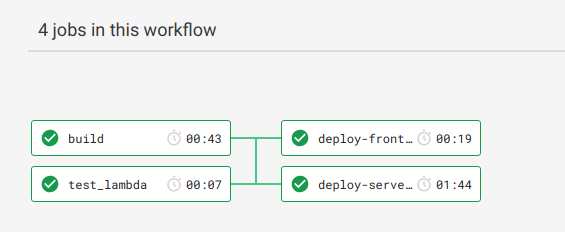
デプロイフローをCircleCIで自動化する

最後にデプロイフローの自動化について紹介したいと思います。
今回は、CircleCIを用いて、masterにプルリクがマージされた時点で、デプロイコマンドが走るようにしました。
こちらも抜粋して紹介するので、すべてご覧になりたい方はGitHubをご覧ください。
https://github.com/p1ass/emojic.ch/blob/master/.circleci/config.yml
Serverless Frameworkのデプロイを実行する
# 抜粋
version: 2
jobs:
deploy-serverless:
docker:
- image: shinsukeabe/circleci-serverless-python3
steps:
- checkout
- restore_cache:
keys:
- v1-{{ checksum "lambda/package-lock.json" }}
- run:
name: Install Packages
command: |
cd lambda
npm install --save serverless-python-requirements serverless-prune-plugin serverless-apigw-binary
- save_cache:
paths:
- lambda/node_modules
key: v1-{{ checksum "lambda/package-lock.json" }}
- run:
name: Deploy lambda function in production environment
command: |
cd lambda
serverless deploy -v -s prod
必要なプラグインをインストールして、serverless deploy -v -s prodでプロダクション環境にデプロイしています。
なお、Docker Imageはshinsukeabeさんのものを使用させていただきました。
Serverless Frameworkプロジェクトと開発者アセットのCDを回す
Nuxt.jsのデプロイ
# 抜粋
version: 2
jobs:
deploy-frontend:
docker:
- image: cdssnc/aws-cli
steps:
- checkout
- attach_workspace:
at: .
- deploy:
name: Deploy web page
command: |
cd frontend
./deploy_to_s3.sh
# !/bin/sh
aws s3 sync ./dist s3://$EMOJIC_BUCKET/ --delete
aws cloudfront create-invalidation --distribution-id $EMOJIC_DISTRIBUTION --paths '/*'
Nuxt.jsのビルドされたファイルは事前にpersist_to_workspaceで保存しているので、それを読み込んでいます。また、フロントエンドはServerless Frameworkを使わず、aws-cliでデプロイしています。
workflows
# 抜粋
workflows:
version: 2
build-and-deploy:
jobs:
- test-lambda
- build
- deploy-frontend:
requires:
- build
- test-lambda
filters:
branches:
only: master
- deploy-serverless:
requires:
- build
- test-lambda
filters:
branches:
only: master
CircleCI2.0のworkflowsを使って、ブランチによって処理を切り替えたり、ビルドが終わってからデプロイされるようにしています。
デプロイ処理はmasterのみで発火するようにし、テストやビルドはすべてのブランチで行っています。
まとめ
- バイナリデータを扱うのは大変😵
- CloudFrontやRoute53の構築も自動化したい🙌
- Amazon Rekognition最強!!!!💪💪💪💪💪💪💪
最後にAmazon Rekognitionを使った感想ですが、**"こんなに高精度のモデルが誰でも使える時代になった"**という驚きが一番大きかったです。
非機械学習エンジニアでも訓練済みのモデルを使えば顔認識くらい簡単にできるというのは、技術の進歩を感じます。機械学習エンジニアには頭が上がりません🙇
皆さんも一度、Amazon Rekognitionを使ってみてはいかがでしょうか?
最後までご覧いただきありがとうございました。
【お知らせ】人の顔を絵文字😄に変換するWebサービス「えもじっく」の顔認識が超絶パワーアップしました!!
— ぷらす (@p1ass) 2018年12月14日
今まで認識しなかった顔も認識してくれると思うので、是非試してみてください😁#えもじっく https://t.co/4rfepRHMnB pic.twitter.com/fsMYTeGKBh