はじめに
・登山が好きプログラミング初心者が衛星データを利用して山探しする企画です。
・こう書いた方がより良いなどありましたら、勉強になりますのでぜひコメントください。
・人工衛星のデータはオープンデータとして無料で利用できるものが多くあり、初心者でも比較的簡単に楽しめるため、実際に使ってみて初学者のプログラミング学習にもおすすめだと感じました。
・本企画は以下の4部構成を予定しており、随時リリース予定です。
①日本の山リスト作成編
②衛星データで周囲で一番高い山を探してみる編
③衛星データで山周辺の地域の晴天率を調べてみる編
④衛星データで眺望の良い、山頂がひらけている山を探してみる編
・この企画を参考に、自分の趣味と衛星データを繋げてみてもらえたら嬉しいです。
Google Earth Engine(GEE)とGoogle Colabを使った衛星データ活用
今回利用するGoogle Earth Engine(GEE)とGoogle Colabについて紹介します。
GEEは、Googleが提供する人工衛星画像をサーバー上で解析をすることが出来るサービスです。研究・教育・非営利目的であれば無償で利用することができ、複雑なデータフォーマットへの対応や前処理が不要となり、初学者でも簡単に衛星データを扱うことができます。
Google ColabはGoogleが提供するブラウザからPython を実行できるサービスです。Google ColabからGEEのデータを扱うこともできます。
GEEとGoogle Colabを用いた衛星データの解析に関する記事は多数出ていますが、筆者は下記の記事を参考にしました。手順通り実行していけば、簡単に衛星画像が取得でき楽しい上、少し書き換えることで自分の扱いたい衛星データも取得できるため、初学者の方はまずはこちらを参考に遊んでみることをオススメします。
Google Earth EngineとGoogle Colabによる人工衛星画像解析 〜無料で始める衛星画像解析(入門編)〜
https://qiita.com/takubb/items/518e860a1d7c336d8f3d
【続編】Google Earth EngineとGoogle Colabによる人工衛星画像解析 〜無料で始める衛星画像解析(実践編)〜
https://qiita.com/takubb/items/a98e2cab6f66d2f9c507
衛星データとプログラミング
筆者は衛星データに関する知識もPythonによるプログラミングも初心者でした。
衛星データに関する知識は「宙畑」というサイトでたくさんの事例が紹介されています。そ宙畑で紹介されているのは、GEEではなく、Tellusという衛星データプラットフォームのため、公開されているコードをそのまま使うことはできませんが、衛星データでどのようなことができるのかイメージが湧きやすくなるのでオススメです。
Pythonによるプログラミングは、個人的には以下のサイトがオススメです。
Pythonの基本〜画像処理まで一通り勉強することができます。
初心者向けTellus学習コース
https://tellusxdp.github.io/start-python-with-tellus/index.html
登りたい山の条件を考えてみる
筆者らは登山ガチ勢ではありません。筆者らのうちの一人は普通にスニーカーで岩山を登ってしまう人でしたし、もう一人もウルトラライトダウンのみで登山に向かうような人でした。さすがに危険なので今はそれぞれ最小限のアイテムは持っていますが…笑
そんな私たちが登りたい山の条件を挙げてみた結果、4つに絞られました。
①標高2000m以上
まずは、登山においてその山の標高はとても大事です。
一概には言えませんが、眺望も登る大変さも標高は大きく影響してきます。
あまり深い理由はありませんが、個人的にはやはり「2000m以上」は一つ大きな指標の一つなので、これを条件にします。
②周辺で最も高い山
山を決める際に最も重要視しているのが、「眺望」です。
苦労して頂上に着いたときの、「見渡せば広がる自然や街並み、見上げれば無限の青い空」は格別です。
せっかく登ったのに、近くに自分がいる位置より高い山があったらなんか悔しいですよね。
そのため、「周辺で最も高い山」を登りたい山の条件にします。
③天気が崩れにくい
せっかく立てた登山の予定が、雨で中止になることほど悲しいことはありません。
そのため、なるべく雨が降らないような場所にいく予定を立てれば、予定が中止になりにくいのではないでしょうか。
天気が崩れにくいに越したことはないので、これも条件にします。
④山頂に木がない(森林限界となっている)
低山ではよくあるのですが、せっかく頂上に着いたのに高い木がたくさん生えていて、景色が見えないなんてことも…
良い眺望を求めているので、これも条件にします。
扱う衛星データと本企画の概要
上で決めたように4つの条件を基に4部構成で記事を書いていこうと思います。
①登りたい山の条件を考えてみる〜日本の山リスト作成
②衛星データで周囲で一番高い山を探してみる。
③衛星データで山周辺の地域の晴天率を調べてみる。
④衛星データで眺望の良い、山頂に木がない山を探してみる。
それぞれの記事で扱うデータを下の表にまとめます。
| 記事 | 衛星データ |
|---|---|
| ②周囲で一番高い山を探してみる | ALOS/DSM:標高データ(*1) |
| ③山周辺の地域の晴天率を調べてみる。 | GSMaP:降水量データ(*2) |
| ④山頂に木がない山を探してみる | Sentinel-2:植生指数(*3) |
スクレイピングによる日本の山リスト作成
本企画では、事前に作成した日本の山リストから、衛星データを使って登りたい山の条件で絞っていき、最終的に登りにいく山を決めます。
本記事ではまずスクレイピングによって日本の山リストを作成します。
国土地理院に日本の主な山岳一覧が公開されているため、ここから日本の山リストを取得します。
https://www.gsi.go.jp/kihonjohochousa/kihonjohochousa41140.html
筆者は下記サイトを見ながら、BeautifulSoupでスクレイピングをしてみました。
下記サイトではJリーグの順位をスクレイピングしていますが、同じ要領で進めていくと山のリストを取得でき、それをcsvファイルに出力しました。
https://atmarkit.itmedia.co.jp/ait/articles/1910/18/news015_2.html
from urllib.request import urlopen
from bs4 import BeautifulSoup
import ssl
import csv
ssl._create_default_https_context = ssl._create_unverified_context
# URLの指定
html = urlopen("https://www.gsi.go.jp/kihonjohochousa/kihonjohochousa41140.html")
Obj = BeautifulSoup(html, "html.parser")
# テーブルを指定
table = Obj.findAll("div", {"class":"base_txt"})[0]
rows = table.findAll("tr")
# スクレイピング
with open("/content/drive/My Drive/mountain_list.csv", "w", encoding='utf-8_sig') as file:
writer = csv.writer(file)
for row in rows:
csvRow = []
for cell in row.findAll(['td', 'th']):
csvRow.append(cell.get_text())
writer.writerow(csvRow)
取得したcsvはこの様になっています。
無事リストを取得出来ましたが、標高のセルに「m」の文字が含まれていたり、緯度経度が同じセルが含まれていたり、いらない情報が多かったり、扱いづらい状態になっているので、ここから少しいじって必要な情報を扱いやすいように整えます。

まずは以下のコードでいらない列を削除します。
このようなcsvデータを扱う際にはpandasというライブラリがとても便利です。
山名、標高、緯度経度があれば問題ないので、今回はpandasを用いてそれ以外の情報の列を削除します。
import pandas as pd
df = pd.read_csv("/content/drive/My Drive/mountain_list.csv")
# いらない列の削除
df.drop("備考", axis=1, inplace=True)
df.drop("都道府県", axis=1, inplace=True)
df.drop("所在等", axis=1, inplace=True)
df.drop("三角点名等", axis=1, inplace=True)
次に以下の標高列に含まれている「m」の文字列を削除します。この後の解析で標高値を参照する際に文字列が入っていると厄介なためです。
# 標高セルに含まれる"m"を削除
df['標高'] = df['標高'].str.strip("m")
次に、緯度経度のセルの編集をしていきます。
まずは緯度経度が同じセルに入っているため、「秒」の文字の後ろ側で分割し、それぞれ緯度経度列に代入します。
その後、元々の緯度経度列は削除します。
# 緯度経度の分割
df['緯度'] = df['緯度経度'].str.split(pat='秒', expand=True)[0]
df['経度'] = df['緯度経度'].str.split(pat='秒', expand=True)[1]
df.drop("緯度経度", axis=1, inplace=True)
次に、度分秒表記になっている緯度経度を10進法に変換します。GEEなどでは緯度経度は10進法で扱われているので、この変換は覚えておくと良いかもしれません。
変換の流れは、まず「度」「分」「秒」を「。(ピリオド)」に直します。次に「。」で分割して、「度」「分」「秒」で扱われていた数値を以下の式を基に10進法に変換します。
10進経緯度 = 度 + (分 ÷ 60) + (秒 ÷ 3600)
# 度分秒をピリオドに置換
df['緯度'] = df['緯度'].str.replace("度", ".")
df['緯度'] = df['緯度'].str.replace("分", ".")
df['緯度'] = df['緯度'].str.replace("秒", ".")
df['経度'] = df['経度'].str.replace("度", ".")
df['経度'] = df['経度'].str.replace("分", ".")
df['経度'] = df['経度'].str.replace("秒", ".")
# 度分秒を10進法に変換
lat_list = df['緯度'].values
lon_list = df['経度'].values
lat_2 = []
lon_2 = []
for i, lat in enumerate (lat_list):
lat_2 = lat.split('.')
lat = float(lat_2[0]) + float(lat_2[1]) / 60 + float(lat_2[2]) / 60 / 60
df.at[i, "緯度"] = lat
for i, lon in enumerate (lon_list):
lon_2 = lon.split('.')
lon = float(lon_2[0]) + float(lon_2[1]) / 60 + float(lon_2[2]) / 60 / 60
df.at[i, "経度"] = lon
最後にcsvとして出力します。
この後csvの結果をGoogleMapに表示する際に、”<>”などの特殊文字があると読み込みできませんと言われてしまうので、列名を変更しておきます。
# 列の名前に<>があってはいけないらしいので変更
# Google Mapにマッピングしない場合は不要
df.rename(columns={'山名<山頂名>': '山名'}, inplace=True)
# 保存
df.to_csv("/content/drive/My Drive/mountain_list_fin.csv")
出力されたcsvは以下のようになっています。
無事に必要な情報がまとまったcsvが作れました。
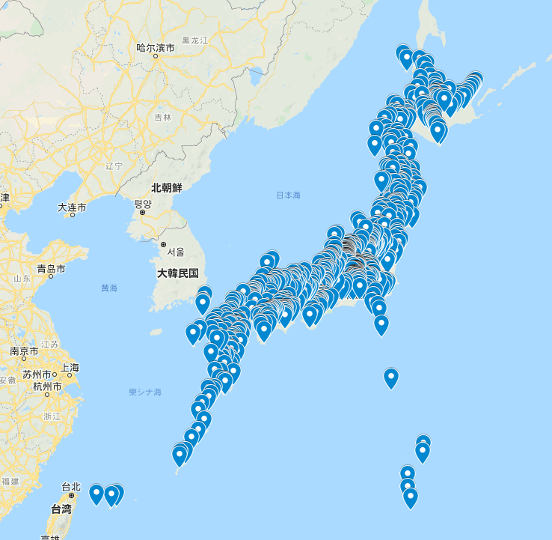
このcsvの結果を試しにGoogle Mapに表示してみました。コードで行う方法もあると思いますが、今回は手動で行っています。方法を以下の記事で紹介しておきます。
https://qiita.com/oz_oz/items/e796bb1a66e883e4fa3c
日本に山ってこんなにたくさんあるんですね…
次回はこのたくさんの山から、自分たちの登りたい山を絞っていきたいと思います!
まとめ
今回は企画の説明と、前準備として国土地理院のwebサイトからスクレイピングによって日本の山リストを取得するまでを紹介しました。
次回からはGEEの衛星データを使って、自分たちの登りたい山を探していきます。
②衛星データで周囲で一番高い山を探してみる編
参考文献
*1:ALOS DSM Global 30m
https://developers.google.com/earth-engine/datasets/catalog/JAXA_ALOS_AW3D30_V3_2
*2:GSMaP Operational: Global Satellite Mapping of Precipitation
https://developers.google.com/earth-engine/datasets/catalog/JAXA_GPM_L3_GSMaP_v6_operational?hl=en
*3:Sentinel-2 MSI: MultiSpectral Instrument, Level-2A
https://developers.google.com/earth-engine/datasets/catalog/COPERNICUS_S2_SR
[Python入門]Beautiful Soup 4によるスクレイピングの基礎
https://atmarkit.itmedia.co.jp/ait/articles/1910/18/news015_2.html
Google Earth EngineとGoogle Colabによる人工衛星画像解析 〜無料で始める衛星画像解析(入門編)〜
https://qiita.com/takubb/items/518e860a1d7c336d8f3d
【続編】Google Earth EngineとGoogle Colabによる人工衛星画像解析 〜無料で始める衛星画像解析(実践編)〜
https://qiita.com/takubb/items/a98e2cab6f66d2f9c507