概要
表題の通り
Visual Studio 2019のPythonにて、Jpeg画像をそのままPDFに変換する。
コードのサンプルでございます。
画像を扱うためにOpenCVを取り込んでいる以外は
特段、NuGetなどで他のプラグインや
別途外部dllを必要としないようにしています。
過去に書きました
Visual Studio 2019のC#にて、画像をそのままPDFに変換する。コードのサンプルです。
https://qiita.com/oyk3865b/items/20e1bf40a728671e7647
のPython版ですが
私自身は、Pythonに不慣れなため
Pythonの勉強を兼ねて書いているコードの為
いつもより汚いことをご容赦ください。
また、過去のC#での記事と異なり
Jpeg画像のみを扱う方法に変更しています。
今回の記事のコードでは、
バイナリを以下のように、直接叩いています。
1.PDFのヘッダーの記述
2.ファイルパスから画像のサイズを読み込んで記述
3.PDFファイルに画像情報と共に、画像バイナリも埋める。
4.PDFのフッターの記述。
※私は素人ですし
今回のコードは、あくまで最低限の動作する部分にとどめていますので、汚いです。
例外処理や、解放など至らぬ点が、多々ございます。ご了承ください。
もし実際に参考にされる際は、必要個所を必ず訂正してからにしてください。
下の画像は、今回コードでの作成例です。

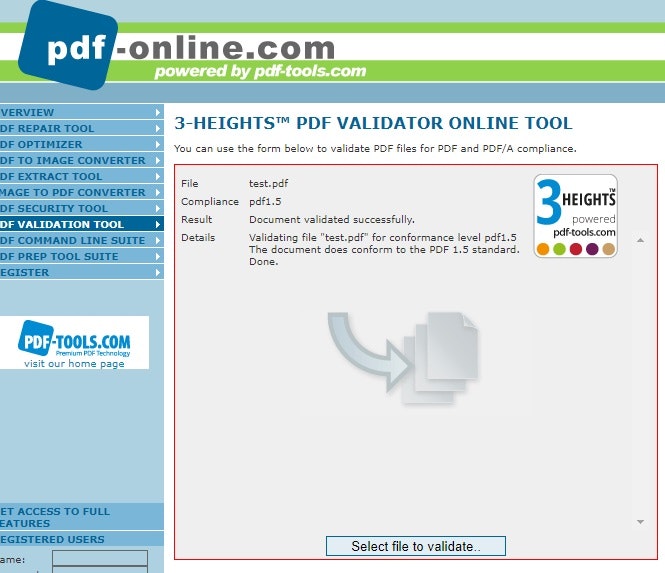
そして、この作成PDFを
『PDF Tools Online - Validate PDF』
https://www.pdf-online.com/osa/validate.aspx
にて検証した結果正常のようです。
参考ページ
今回のコードを記述するにあたり
・Python:処理ファイルをGUIから選択する方法 - Qiita
・Python OpenCV の cv2.imread 及び cv2.imwrite で日本語を含むファイルパスを取り扱う際の問題への対処について - Qiita
以上のサイト様の内容を参考にいたしました。
※尚、以下のリンク先は、私の参考としてのブログや動画です。気を付けてください。
・特に、dllを使わず、、バイナリを直接叩いて、PDFを作れないか、やってみた。結果報告・1
http://oyk3865b.blog13.fc2.com/blog-entry-1127.html
・自力で、JPEG画像から、PDFに変換してみた - ニコニコ動画
https://www.nicovideo.jp/watch/sm19664272
本題
今回は、私にとってはPythonが不慣れで
また、Pythonのデータ型の管理がよくわかっていないので
強引なコードだと思います。予めご注意ください。
# モジュールのインポート
#参考URL https://qiita.com/666mikoto/items/1b64aa91dcd45ad91540
import os, tkinter, tkinter.filedialog, tkinter.messagebox
import numpy as np
import cv2
# jpeg画像ファイル選択ダイアログの表示
root = tkinter.Tk()
root.withdraw()
fTyp = [("jpg","*.jpg")]
read_files = tkinter.filedialog.askopenfilenames(filetypes = fTyp)
#書き込む先PDFの指定
write_file_path = "test.pdf"
write_file = open(write_file_path,'wb')
# PDFヘッダ関係
vbCrLf = "\r\n";
pdf_header_start = ("%PDF-1.5" + vbCrLf + "%TageSP" + vbCrLf).encode(encoding='utf-8')
write_file.write(pdf_header_start)
#出力pdfの各オブジェクトの開始位置を格納。
ary_pdf_byte_head = list()
#1オブジェクトの開始位置を格納
ary_pdf_byte_head.append(write_file.tell())
#オブジェクト1
pdf_1st_obj = ("1 0 obj" + vbCrLf +
"<<" + vbCrLf + "/Type /Catalog" + vbCrLf +
"/Pages 2 0 R" + vbCrLf +
">>" + vbCrLf + "endobj" + vbCrLf).encode(encoding='utf-8')
write_file.write(pdf_1st_obj)
#2オブジェクトの開始位置を格納
ary_pdf_byte_head.append(write_file.tell())
pdf_2nd_obj_Kids =("2 0 obj" + vbCrLf + "<<" +
"/Type /Pages" + vbCrLf + "/Kids [ ").encode(encoding='utf-8')
#オブジェクト2
write_file.write(pdf_2nd_obj_Kids);
pdf_indicate_obj = "NO 0 R "
pdf_obj_Name = "CC 0 obj"
#ページ数だけ、子オブジェクトを指定・追加する。
for num in range(len(read_files)):
#子オブジェクトの位置の指定用
pdf_2nd_obj_Kids_Set = pdf_indicate_obj.replace('NO', str(num * 3 + 3))
write_file.write(pdf_2nd_obj_Kids_Set.encode(encoding='utf-8'))
#ページ数を格納する。
pdf_2nd_obj_Count = ("]" + vbCrLf + "/Count ").encode(encoding='utf-8')
write_file.write(pdf_2nd_obj_Count);
write_file.write(str(len(read_files)).encode(encoding='utf-8'))
pdf_2nd_obj_End = (vbCrLf + ">>" + vbCrLf + "endobj" + vbCrLf).encode(encoding='utf-8')
write_file.write(pdf_2nd_obj_End);
#各ページ用の、子オブジェクトの作成
for num in range(len(read_files)):
#今回の、子オブジェクトの番号を指定
obj_No = num * 3 + 3
#3オブジェクトの開始バイト位置を格納
ary_pdf_byte_head.append(write_file.tell());
pdf_obj_String = pdf_obj_Name.replace("CC", str(obj_No))
write_file.write(pdf_obj_String.encode(encoding='utf-8'))
#キャンバス・サイズを指定
pdf_3rd_obj_Start =(vbCrLf + "<<" + vbCrLf + "/Type /Page" + vbCrLf +
"/Parent 2 0 R" + vbCrLf + "/MediaBox [ 0 0 ").encode(encoding='utf-8')
write_file.write(pdf_3rd_obj_Start)
#tkinter.messagebox.showinfo('確認', read_files[num])
#なぜか以下で不具合が出るので一旦ここで相対パスにする。
filepath = os.path.relpath(read_files[num], os.getcwd())
#パスに日本語があるとcv2.imreadが出来ないので、一旦読み込みする
#↓参考サイト様
#https://qiita.com/SKYS/items/cbde3775e2143cad7455
img_st = np.fromfile(filepath, np.uint8)
#画像を読み込む
img = cv2.imdecode(img_st, cv2.IMREAD_COLOR)
#画像サイズの指定
pdf_obj_String = "WW HH ]"
pdf_obj_String = pdf_obj_String.replace("WW", str(img.shape[1] * 0.75)) #幅
pdf_obj_String = pdf_obj_String.replace("HH", str(img.shape[0] * 0.75)) #高さ
write_file.write(pdf_obj_String.encode(encoding='utf-8'))
#▼画像の配置指定の設定
pdf_3rd_obj_Resources = (vbCrLf + "/Resources << /ProcSet [ /PDF /ImageB ]" + vbCrLf).encode(encoding='utf-8')
write_file.write(pdf_3rd_obj_Resources)
pdf_3rd_obj_XObject = "/XObject << /Im0 XX 0 R >>" + vbCrLf + ">>"
pdf_obj_String = pdf_3rd_obj_XObject.replace("XX", str(obj_No + 1))
write_file.write(pdf_obj_String.encode(encoding='utf-8'))
#▼画像の配置指定の設定2
pdf_3rd_obj_Contents = (vbCrLf + "/Contents ").encode(encoding='utf-8')
write_file.write(pdf_3rd_obj_Contents)
pdf_obj_String = pdf_indicate_obj.replace("NO", str(obj_No + 2))
pdf_obj_String = pdf_obj_String.rstrip() #右端のスペースは、消す
write_file.write(pdf_obj_String.encode(encoding='utf-8'))
pdf_3rd_obj_End = (vbCrLf + ">>" + vbCrLf +
"endobj" + vbCrLf).encode(encoding='utf-8')
write_file.write(pdf_3rd_obj_End)
#4オブジェクトの開始バイト位置を格納
ary_pdf_byte_head.append(write_file.tell());
pdf_obj_String = pdf_obj_Name.replace("CC", str(obj_No + 1))
write_file.write(pdf_obj_String.encode(encoding='utf-8'))
pdf_4th_obj_Start = (vbCrLf + "<<" + vbCrLf + "/Type /XObject" + vbCrLf +
"/Subtype /Image" + vbCrLf + "/").encode(encoding='utf-8')
write_file.write(pdf_4th_obj_Start)
#▼画像本体のサイズ指定
pdf_4th_obj_ImageSize = "Width AA /Height BB"
pdf_obj_String = pdf_4th_obj_ImageSize.replace("AA", str(img.shape[1]))
pdf_obj_String = pdf_obj_String.replace("BB", str(img.shape[0]))
write_file.write(pdf_obj_String.encode(encoding='utf-8'))
pdf_4th_obj_Filter = (vbCrLf + "/BitsPerComponent 8" + vbCrLf +
"/ColorSpace /DeviceRGB" + vbCrLf +
"/Filter /DCTDecode" + vbCrLf).encode(encoding='utf-8')
write_file.write(pdf_4th_obj_Filter)
#▼画像本体の、バイトサイズを指定
pdf_4th_obj_Length = "/Length LLLLL" + vbCrLf + ">>" + vbCrLf + "stream" + vbCrLf
pdf_obj_String = pdf_4th_obj_Length.replace("LLLLL", str(os.path.getsize(filepath)));
write_file.write(pdf_obj_String.encode(encoding='utf-8'))
#jpg画像のバイナリを、挿入
jpg_file = open(filepath, 'rb')
write_file.write(jpg_file.read())
jpg_file.close()
#streamを閉じる
pdf_4th_obj_End = (vbCrLf + "endstream" + vbCrLf + "endobj" + vbCrLf).encode(encoding='utf-8')
write_file.write(pdf_4th_obj_End)
#5オブジェクトの開始バイト位置を格納
ary_pdf_byte_head.append(write_file.tell());
pdf_obj_String = pdf_obj_Name.replace("CC", str(obj_No + 2))
write_file.write(pdf_obj_String.encode(encoding='utf-8'))
#▼画像の表示サイズの指定
pdf_5th_obj_ShowSize = "q WW 0 0 HH 0 0 cm /Im0 Do Q"
pdf_obj_String = pdf_5th_obj_ShowSize.replace("WW", str(img.shape[1] * 0.75));
pdf_obj_String = pdf_obj_String.replace("HH", str(img.shape[0] * 0.75));
#とりあえず、stream内部のバイト数を、数えるために、pdf_write_binaryに、移しておく
pdf_write_binary = pdf_obj_String
#5オブジェクトのstream内部のバイト数を格納
pdf_5th_obj_Length = vbCrLf + "<< /Length LLLLL >>" + vbCrLf + "stream" + vbCrLf
pdf_obj_String = pdf_5th_obj_Length.replace("LLLLL", str(len(pdf_write_binary.encode(encoding='utf-8'))))
write_file.write(pdf_obj_String.encode(encoding='utf-8'))
#5オブジェクトのstream本体を格納
write_file.write(pdf_write_binary.encode(encoding='utf-8'))
#◆子オブジェクトを、閉める
pdf_5th_obj_End = (vbCrLf + "endstream" +
vbCrLf + "endobj" + vbCrLf).encode(encoding='utf-8')
write_file.write(pdf_5th_obj_End)
#▼フッター
#xrefの開始バイト位置を格納
xref_start_pos = write_file.tell()
pdf_xref_Start = ("xref" + vbCrLf).encode(encoding='utf-8')
write_file.write(pdf_xref_Start)
#全オブジェクト数を格納
pdf_xref_objCount = "0 MM" + vbCrLf
pdf_obj_String = pdf_xref_objCount.replace("MM", str(len(ary_pdf_byte_head) + 1))
write_file.write(pdf_obj_String.encode(encoding='utf-8'))
#0位置指定。
pdf_xref_ZERO = ("0000000000 65535 f" + vbCrLf).encode(encoding='utf-8')
write_file.write(pdf_xref_ZERO)
#各・子オブジェクトのバイト位置を、 各10桁で指定していく
pdf_xref_objStartPos = "QQQQQQQQQQ 00000 n" + vbCrLf
for num in range(len(ary_pdf_byte_head)):
pdf_obj_String = str(ary_pdf_byte_head[num]).zfill(10)
pdf_obj_String = pdf_xref_objStartPos.replace("QQQQQQQQQQ",pdf_obj_String)
write_file.write(pdf_obj_String.encode(encoding='utf-8'))
#trailerを格納
pdf_trailer = ("trailer" + vbCrLf + "<<" + vbCrLf +
"/Size MM" + vbCrLf +
"/Root 1 0 R" + vbCrLf +
">>" + vbCrLf)
pdf_obj_String = pdf_trailer.replace("MM", str(len(ary_pdf_byte_head) + 1))
write_file.write(pdf_obj_String.encode(encoding='utf-8'))
#startxref~%%EOFを格納
pdf_startxref_EOF = ("startxref" + vbCrLf + "TTT" + vbCrLf +
"%%EOF" + vbCrLf)
pdf_obj_String = pdf_startxref_EOF.replace("TTT", str(xref_start_pos))
write_file.write(pdf_obj_String.encode(encoding='utf-8'))
#初期化
ary_pdf_byte_head = []
write_file.close()
tkinter.messagebox.showinfo('確認', 'PDF作成作業が終わりました')
以上のコードを実行すると
指定した画像ファイルが、そのまま
PythonApplication1.pyと同階層のフォルダに、
PDFに変換されてあると思います。