はじめまして
こんにちは。カトウです。この記事は、機械学習が気になるけど研究するほど詳しくない人が独学で成果物作るまで頑張った記録です。
そういえば、前に頭がおかしい時に書いたgo getの記事はおかげさまでSEO 4位(11/26)なので引き続き頑張ります。
今回のテーマは
ツイートの類似度を評価するシステムを1週間で作ってみました!!
です!
というわけで、モデル選定から成果物を出すまでのフローを共有したいと思います。
ツイートについて
ツイートは140字以内でテキストデータだけであると仮定しまっす。
ツイートを分解する
ツイート(文書)は単語によって構成されています。今回は、ツイートを単語単位で分解します。
ツイートをどうやって評価するか?
単語のベクトル(あとで説明する)を足し合わせて単語の数で割り、ベクトルの平均値をツイートのベクトルにします。
比較したい2つのツイートベクトルをコサイン類似度の式(あとで説明する)に当てはめて、ざっくり0~1の数値(たまに-0.0…や1.02…などの値も検出することもある)を得ます。
0に近ければ、ツイート間の類似度が低く、1に近ければツイート間の類似度が高いことになります。
単語のベクトルとは?
単語のベクトルってなんだよ???

こんなやつ↓ 雑
単語のベクトルを求めるために、word2vecというモデルを使います。
gensimというPythonのライブラリを使い、単語ベクトルの次元を引数として与えて、N次元のベクトルを得ます。
word2vecとは?
word2vecは単語をベクトルで表現することで単語の意味みたいなものを表現するモデル。
word2vecの詳細を説明すると長くなりそうなので、学習済みのword2vecのインターフェイスだけ説明すると、インプットが単語(Ex: ご飯)で、アウトプットがベクトル(Ex: [0.22, 0.12, 0.21, 0.56])となりまっす。
このアウトプットの単語ベクトルを扱うことで、単語同士の意味の近さを比べたり、また王様ー男+女=王妃のような計算をすることができる。
すごーい٩( ᐛ )و
どうやって単語ベクトルを求める?
まずは、膨大な日本語のテキストデータをGETします。
なぜなら、一度学習した単語ではないと単語ベクトルの値を求めることはできないからです。
では、この世の多くの言葉を偏りなく扱っている媒体はなんだろう。
広辞苑?新聞?
デジタルの媒体で一番扱いやすいものは、Wikipediaだと思います。
自然言語処理をやり始めて感じるWikipediaの有能さよ。
— 加藤ゆう (@yukato7777) May 22, 2019
実際、多くの言語の学習済みのWikipediaのモデルがネット上に公開されてあります。
学習済みword2vecモデル一覧
しかし、Wikipediaの学習済みモデルは、Python2系のみの対応であったり、最新の単語に対応していなかったり。。。
Twitterという最新の情報が飛びかうメディアには適していないと感じたので、Wikipediaの学習済みモデルを自分で作るという結論に至りました泣
Wikipediaの全記事で学習する
日本語版Wikipediaの全記事を取得できるサイトがあるので、そこからxml形式のデータを取得します。(12GBぐらい)
xml形式のWikipediaのデータをテキストにするためにwikiextractorというツールを使います。
結果として、textディレクトリに大量のテキストデータが生成されます。
これをwiki.txtにまとめます。(やり方はGGR)
Word2vecにテキストデータを突っ込むには、テキストデータが単語ごとに、分割された状態でなければならないです。
分割するために、MeCabというオープンソースの形態素解析エンジンを使いまっす。
MeCabを使うと
(処理後)目 に 見える もの が 真実 と は 限ら ない。
このように、文章を分割することができます。
また、単語ごとの品詞を取得することもできます。(あとで使う)
MeCabでwiki.txt→wiki_wakati.txt(わかち書きされたテキストデータ)の変換を行います。
単語単位で分割したテキストデータ(wiki_wakati.txt)をgensimのword2vecの関数にぶち込みます。単語の次元数を300に設定します。
そして数時間待つと、.modelというファイルが生成されます。
https://twitter.com/yukato7777/status/1131422691741773824授業中にword2vecの学習し始めたら、pcのファンが爆音で音を立て始めて死にたい😊
— 加藤ゆう (@yukato7777) May 23, 2019
これを他のファイルで読み込み、単語を入力することで、あら不思議、単語ベクトルを求めることができます。
[-0.01494294 -0.1509463 0.06123272 ..., 0.01335443 0.03439184
0.05130962]
MeCabを使ってツイートを分解する
ツイートの中で必要な情報とはなんでしょうか?
上のツイートで内容を表しているのは、Go言語とGopherでしょう。
いえ…い!さいこお…!はいらないです。
そこで、MeCabは単語ごとの品詞を取得することができるので、特定の品詞のみの単語(固有名詞と一般)を取得します。
word2vecに単語をぶち込む
word2vecに特定の品詞の単語をインプットとして、単語ベクトルを取得します。そして、その和を単語の数で割ります。
以下コード
# coding: utf-8
import MeCab
import numpy as np
import glob
from gensim.models.word2vec import Word2Vec
from utils.cos_sim import cos_sim
# load model
model_path = 'model/wiki.model'
model = Word2Vec.load(model_path)
mecab = MeCab.Tagger('-d /usr/local/lib/mecab/dic/mecab-ipadic-neologd')
test_folder = glob.glob('test/*')
sentence_vectors = []
for test_file in test_folder:
word_number = 0
sentence_vector = np.zeros(300)
f = open(test_file, 'r')
for line in f:
node = mecab.parseToNode(line)
while node:
# get word
word = node.surface
# get part of speech(POS)
pos = node.feature.split(',')[1]
if pos == '固有名詞' or pos == '一般':
try:
vector_value = model.wv[word]
word_number += 1
sentence_vector += vector_value
except KeyError:
pass
# go to next word
node = node.next
sentence_vectors.append(sentence_vector/word_number)
print(cos_sim(sentence_vectors[0], sentence_vectors[1]))
コサイン類似度でTweet間の類似度を評価
コサイン類似度↓
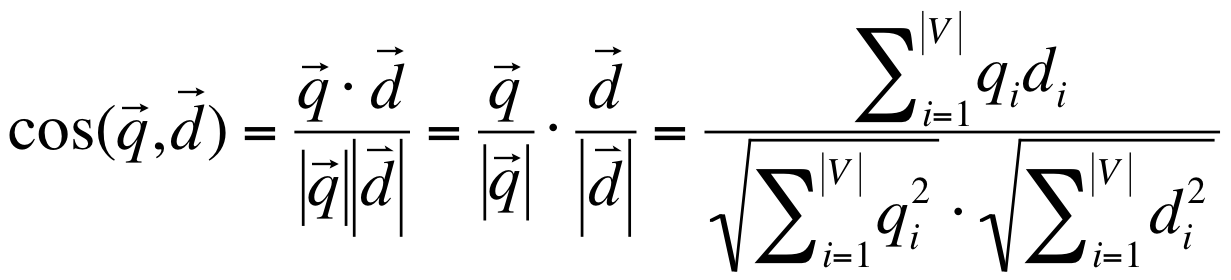
今回はツイート1がベクトルq、ツイート2がベクトルdとして計算が行われるようなイメージ。
計算については、数式を書いたらいいので、具体例などは出しません。
類似性を検証してみる
実験1
[Tweet1]
[Tweet2]
[結果]
[メモ]
アーティストが異なるけど、’好き’とミュージシャンの名前が含まれているからそこそこの値がでた。
実験2
[Tweet1]
[Tweet2]
[結果]
[メモ]
内容が全く違うので、-0.06..というかなり低い値が出た。
実験3
[Tweet1]
[Tweet2]
[結果]
[メモ]
お世話になってるCTOが書いた名文たち(迷文)は0.666..とかなり高い数値が出た。
考察
まだ実験のサンプリング数が少ないので肌感でしかないが、数値としては0.5~1.0の間だとツイートの類似性があることがわかりました。
まとめ(これからどうしよか)
今回は、ツイートを単語単位に分解して、単語ベクトルの平均値を評価することで、類似性を比較しました。
精度を上げるためには、単語の重要さを考慮することや、単語のクラスタリングが有効かもしれないです。
というわけで、現在、以下の2つのモデルを実装中です。
word2vecとTF-IDF(単語の重要さを加味するやつ)を組み合わせたモデル(現在実装中)
SCDV(単語のクラスタリングをするやつ)を使ったモデル
また、ツイートも今回はただTweetを単語単位で分解しただけですが、ツイートにリンクを含んでいたら、リンクのOGPの情報を取得をすることで、より正確にツイートを評価することができるかもしれません。
ソースコード
https://github.com/yukato7/vectrizing_tweet_system
まだまだビギナーなので、こんな工夫をしたら精度が上がったなど教えてもらえると嬉しいです!!!
Twitter
https://twitter.com/yukato777