昨日までのはこちら
100日後にエンジニアになるキミ - 66日目 - プログラミング - 自然言語処理について
100日後にエンジニアになるキミ - 63日目 - プログラミング - 確率について1
100日後にエンジニアになるキミ - 59日目 - プログラミング - アルゴリズムについて
100日後にエンジニアになるキミ - 53日目 - Git - Gitについて
100日後にエンジニアになるキミ - 42日目 - クラウド - クラウドサービスについて
100日後にエンジニアになるキミ - 36日目 - データベース - データベースについて
100日後にエンジニアになるキミ - 24日目 - Python - Python言語の基礎1
100日後にエンジニアになるキミ - 18日目 - Javascript - JavaScriptの基礎1
100日後にエンジニアになるキミ - 14日目 - CSS - CSSの基礎1
100日後にエンジニアになるキミ - 6日目 - HTML - HTMLの基礎1
今回からは自然言語処理についてです。
形態素解析とは
形態素解析は形態素と呼ばれる最小単位の語句に文章を分かち書きし
それぞれの形態素の品詞等を判別する手法のことを言います。
分かち書き
英語のように言葉の区切りに空白を入れる書き方です。
ワタシ ガ ヘンタイ デス ワタシ ハ ド スケベ デス
英語の形態素解析
英語のように単語と単語の間がスペースで区切られる言語においては非常に簡単であり
英語の形態素解析の手順をまとめると以下のようになります。
1.文全体を小文字化し単語の位置により単語が区別されてしまうことを防ぐ
2.it's や don't 等の省略形を分割する(it's → it 's 、 don't → do n't)
3.文末のピリオドを前の単語と切り離す(Mr. などに使われる文末とは関係ないピリオドは切り離さない)
4.スペースで分割する
日本語の形態素解析
日本語は英語の場合と異なり、空白は余りなく、単語の切れ目が分かりません。
そのため専用の辞書を用いて辞書ベースで規則による分割を考える必要があります。
自前で形態素解析を行うのであれば、この分割のルールを自分で定めて実装する必要があります。
日本語の形態素解析に関してはいくつかのライブラリが開発されており
これを用いて形態素解析を行うのが一般的になっています。
代表的なライブラリだとMeCab(めかぶ)と言うものがあります。
Python言語ではjanomeと言うライブラリもあります。
こういったライブラリを用いて実装すれば、比較的簡単に形態素解析を主なうことができます。
本日はjanomeライブラリを用いた形態素解析を行います。
形態素とは
英:morpheme
言語学の用語で、意味をもつ表現要素の最小単位
それ以上分解したら意味をなさなくなる語句です。
例:どこまで分かち書きすれば良いか
行うは「動詞」であるが、それをさらに分けてしまうと
意味をなさなくなってしまう。
行う ⇒ 動詞 〇
行 ⇒ 名詞 ×
う ⇒ 感動詞 ×
そのため適切な所で分解をとどめておかないといけません。
日本語の品詞
日本語の品詞は以下のようなものがあります。
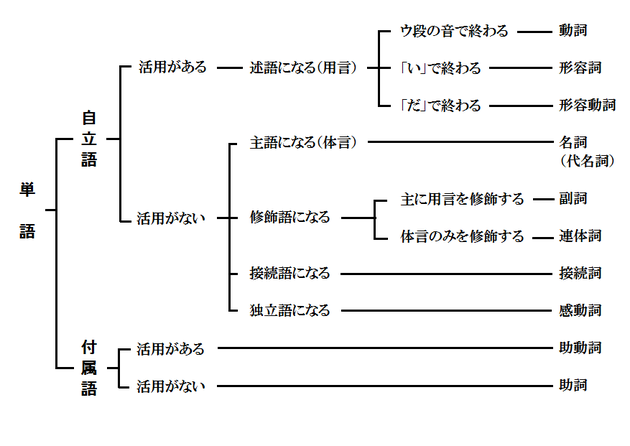
日本語の形態素解析における問題点
日本語を形態素解析する際においては、以下のような問題があります。
・単語の境界判別の問題
・品詞判別の問題
・未知語の問題
・ルーズな文法の問題
・修飾語の有無で意味が変わる問題
単語の境界判別の問題
例えばうらにわにはにわとりがいるという文には、文法的に正しい異なる読み方がいくつか存在しています。
・裏庭 / には / 鶏 / が / いる
・裏庭 / には / 二 / 羽 / トリ / が / いる
・裏 / に / ワニ / は / 鶏 / が / いる
・裏庭 / に / 埴輪 / 取り / が / いる
すもももももももものうちにおいても、どこで区切るかが問題となりますが
完璧な正解を得るにはその文がおかれている文脈や、書き手の意図等の背景をくみとらねばなりません。
品詞判別の問題
たとえば単語 「time」 は「時間」という名詞としての意味のほかにも
「 - 倍する」という動詞としての意味もあるため、これをどちらの意味にとるかによって
文の文法的構造や導かれる意味がまったく違うものになってしまいます。
品詞の種類は文の構造と密接に関連しているため、合わせて検討しないといけません。
未知語の問題
形態素解析は普通、その言語の単語を収めた辞書を用いておこなわれるため
解析対象の文中の辞書に含まれない単語は未知語と呼ばれています。
未知語をどう扱うかによっては、その後の解析の結果に大きく影響されます。
そのため、辞書は定期的に更新を行う必要があります。。
(特に固有名詞:人名、施設名、商品名、ギャグなど)
ルーズな文法の問題
SNSやメール、トークアプリなどの会話の内容は、ある特定のモデル化された日本語の文法からかけ離れたものも多いです。
こういった内容を解析するには文章や単語の表記ゆれ、校正の仕方を根本から検討しないといけません。
修飾語の有無で意味が変わる問題
修飾語は動詞や形容詞の意味を変えるように働くが、形態素解析をしてしまうと
単語では分かれてしまう。複数の単語の組み合わせで解釈しないと、意味が全く異なってしまうことになる。
janomeを用いた形態素解析
pythonのjanomeライブラリを用いて形態素解析を行いましょう。
インストールしていないと使うことはできないため、もしインストールしていなければ
下記のコマンドでインストールしてください。
pip install janome
簡単な形態素解析の例です。
from janome.tokenizer import Tokenizer
t = Tokenizer()
tokens = t.tokenize('甘からず辛からず旨からず')
for token in tokens:
print(token)
甘から 形容詞,自立,,,形容詞・アウオ段,未然ヌ接続,甘い,アマカラ,アマカラ
ず 助動詞,,,,特殊・ヌ,連用ニ接続,ぬ,ズ,ズ
辛から 形容詞,自立,,,形容詞・アウオ段,未然ヌ接続,辛い,カラカラ,カラカラ
ず 助動詞,,,,特殊・ヌ,連用ニ接続,ぬ,ズ,ズ
旨から 形容詞,自立,,,形容詞・アウオ段,未然ヌ接続,旨い,ウマカラ,ウマカラ
ず 助動詞,,,*,特殊・ヌ,連用ニ接続,ぬ,ズ,ズ
janomeのTokenizerを呼び出しインスタンス化しておきます。
from janome.tokenizer import Tokenizer
変数名 = Tokenizer()
変数名.tokenize('文章')で文章を形態素解析した結果を返す事ができます。
形態素解析の結果は
・単語
・品詞
・読み
に分かれています。
単語で分割された結果が返ってくるので1つ1つ処理したい場合は
for文などを用いて処理を繰り返します。
文章を変えてみます。
words = 'すもももももももものうち'
tokens = t.tokenize(words)
for token in tokens:
print(token)
すもも 名詞,一般,,,,,すもも,スモモ,スモモ
も 助詞,係助詞,,,,,も,モ,モ
もも 名詞,一般,,,,,もも,モモ,モモ
も 助詞,係助詞,,,,,も,モ,モ
もも 名詞,一般,,,,,もも,モモ,モモ
の 助詞,連体化,,,,,の,ノ,ノ
うち 名詞,非自立,副詞可能,,,*,うち,ウチ,ウチ
次の文章を形態素解析した場合はどうなるでしょうか?
日本テレビ東京
tokens = t.tokenize('日本テレビ東京')
for token in tokens:
print(token)
日本テレビ 名詞,固有名詞,組織,,,,日本テレビ,ニホンテレビ,ニホンテレビ
東京 名詞,固有名詞,地域,一般,,*,東京,トウキョウ,トーキョー
これは形態素解析用の辞書データに格納されているコストで算出した結果
より知名度のある方やより繋がりやすい単語の区切りでコストが小さいものが
選ばれる仕組みのため、こう言った結果になります。
最近できた固有名詞などは辞書が対応していないことの方が多いため
望ましくない結果になってしまうことがあります。
tokens = t.tokenize(u'とうきょうスカイツリー駅で魚を見てきました')
for token in tokens:
print(token)
とう 副詞,助詞類接続,,,,,とう,トウ,トウ
きょう 名詞,副詞可能,,,,,きょう,キョウ,キョー
スカイ 名詞,一般,,,,,スカイ,スカイ,スカイ
ツリー 名詞,一般,,,,,ツリー,ツリー,ツリー
駅 名詞,接尾,地域,,,,駅,エキ,エキ
で 助詞,格助詞,一般,,,,で,デ,デ
魚 名詞,一般,,,,,魚,サカナ,サカナ
を 助詞,格助詞,一般,,,,を,ヲ,ヲ
見 動詞,自立,,,一段,連用形,見る,ミ,ミ
て 助詞,接続助詞,,,,,て,テ,テ
き 動詞,非自立,,,カ変・クル,連用形,くる,キ,キ
まし 助動詞,,,,特殊・マス,連用形,ます,マシ,マシ
た 助動詞,,,*,特殊・タ,基本形,た,タ,タ
本来はとうきょうスカイツリー駅としたかったのですが、辞書にはこのような単語はありませんので、適切な単語に分割されてしまいます。
このような場合はユーザー辞書を用いて対応します。
辞書ファイルを作成しておいて読み込みします。
変数名 = Tokenizer('辞書ファイル名', udic_enc='文字コード')
東京スカイツリー,1288,1288,4569,名詞,固有名詞,一般,*,*,*,東京スカイツリー,トウキョウスカイツリー,トウキョウスカイツリー
東京スカイツリー駅,1288,1288,4143,名詞,固有名詞,一般,*,*,*,東京スカイツリー駅,トウキョウスカイツリーエキ,トウキョウスカイツリーエキ
東武スカイツリーライン,1288,1288,4700,名詞,固有名詞,一般,*,*,*,東武スカイツリーライン,トウブスカイツリーライン,トウブスカイツリーライン
とうきょうスカイツリー駅,1288,1288,4143,名詞,固有名詞,一般,*,*,*,とうきょうスカイツリー駅,トウキョウスカイツリーエキ,トウキョウスカイツリーエキ
t = Tokenizer("userdic.csv", udic_enc="utf8")
tokens = t.tokenize(u'とうきょうスカイツリー駅で魚を見てきました')
for token in tokens:
print(token)
とうきょうスカイツリー駅 名詞,固有名詞,一般,,,,とうきょうスカイツリー駅,トウキョウスカイツリーエキ,トウキョウスカイツリーエキ
で 助詞,格助詞,一般,,,,で,デ,デ
魚 名詞,一般,,,,,魚,サカナ,サカナ
を 助詞,格助詞,一般,,,,を,ヲ,ヲ
見 動詞,自立,,,一段,連用形,見る,ミ,ミ
て 助詞,接続助詞,,,,,て,テ,テ
き 動詞,非自立,,,カ変・クル,連用形,くる,キ,キ
まし 助動詞,,,,特殊・マス,連用形,ます,マシ,マシ
た 助動詞,,,*,特殊・タ,基本形,た,タ,タ
userdic.csvに登録してある固有名詞が反映されるようになりました。
未知語は辞書を作成して対応を行います。
token.surfaceで単語部分が取得できます。
for token in tokens:
print(token.surface)
とうきょうスカイツリー駅
で
魚
を
見
て
き
まし
た
token.part_of_speechで品詞部分だけを抽出できます。
品詞部分は,区切りで細分化されているため
細分化したものを取得する際は,で分割して取り出します。
for token in tokens:
print(token.part_of_speech)
名詞,固有名詞,一般,*
助詞,格助詞,一般,*
名詞,名詞,一般,*
助詞,格助詞,一般,*
動詞,自立,,
助詞,接続助詞,,
動詞,非自立,,
助動詞,,,*
助動詞,,,*
token.readingで読みが確認できます。
for token in tokens:
print(token.reading)
トウキョウスカイツリーエキ
デ
サカナ
ヲ
ミ
テ
キ
マシ
タ
for文の中で品詞や読みなどを使い分け、後続の処理を行います。
まとめ
形態素解析は言語の解析の中でも基本になります。
ライブラリも多数あるので、いろいろ試してみると良いでしょう。
新しい単語に対応するには辞書を作成するしか無いので
形態素解析を正しく行いたい場合は未知語のための辞書の整備が不可欠です。
君がエンジニアになるまであと33日
作者の情報
乙pyのHP:
http://www.otupy.net/
Youtube:
https://www.youtube.com/channel/UCaT7xpeq8n1G_HcJKKSOXMw
Twitter:
https://twitter.com/otupython