昨日までのはこちら
100日後にエンジニアになるキミ - 76日目 - プログラミング - 機械学習について
100日後にエンジニアになるキミ - 70日目 - プログラミング - スクレイピングについて
100日後にエンジニアになるキミ - 66日目 - プログラミング - 自然言語処理について
100日後にエンジニアになるキミ - 63日目 - プログラミング - 確率について1
100日後にエンジニアになるキミ - 59日目 - プログラミング - アルゴリズムについて
100日後にエンジニアになるキミ - 53日目 - Git - Gitについて
100日後にエンジニアになるキミ - 42日目 - クラウド - クラウドサービスについて
100日後にエンジニアになるキミ - 36日目 - データベース - データベースについて
100日後にエンジニアになるキミ - 24日目 - Python - Python言語の基礎1
100日後にエンジニアになるキミ - 18日目 - Javascript - JavaScriptの基礎1
100日後にエンジニアになるキミ - 14日目 - CSS - CSSの基礎1
100日後にエンジニアになるキミ - 6日目 - HTML - HTMLの基礎1
今回は機械学習についてのお話の続きです。
機械学習の流れについて
前回のでざっくりどんなことをやるのか、出来るのかをやりましたので
本日は具体的にどうすればいいのかをやっていきたいと思います。
まずは機械学習の流れについてです。
業務で行っている機械学習はどのような手順で行われているのかを解説していきます。
機械学習を取り入れる際の業務としては次のような流れになっていきます。
0.目的を決める
1.データ取得
2.データ理解・選択・加工
3.データマート(データセット)作成
4.モデル作成
5.精度検証
6.システム実装
具体的な内容をみていきましょう。
0.目的を決める
一番大事な所だと思います。
何のために機械学習をするのか、何をやりたいのか
という目的を決めます。
機械学習で出来ることはただ一つ予測です。
その予測も
回帰:数値を予測する
分類:男女などのカテゴリを予測する
クラスタリング:いい感じに分ける
という3つの事柄しか行うことはできません。
機械学習の目的として何を予測するのかをまずは決めてあげないといけません。
良い例としては:
ユーザーの離脱率を下げたいのでユーザーの離脱率を予測したい。
売り上げを伸ばしたいのでユーザーが購買するかどうかを予測したい。
〇〇のためにそれにつながるXXを予測する
というのが正しい機械学習の導入方法になるだろうと思います。
基本的には
売上と利益
ここに直結するかどうかだと思います。
ここにつながるかどうか分からない、判断が難しいようなことを
機械学習にさせるのはあまり得策ではないということになります。
そもそも、機械学習ではこの後の作業に非常に大きな工数がかかるので
ぶっちゃけお金が掛かるのです。
開発費は概算で3000万円だけど生み出す利益はほとんどない
であれば、やるだけ無駄なのでやらないと言う判断をするのが賢明なのです。
機械学習をしたらどれくらいの精度になるのか検証したい。
これはこれでOKです。
POCとしての検証までであれば実験がうまくいこうがうまく行かなかろうが
検証結果を持って成果とすれば良いので、目的がゆるいのであれば
検証をすると言う目的でもいいと思います。
大体はお金をドブに捨てるだけにはなりますが。
1.データ取得
目的が決まったら、それに応じたデータを作り込む必要があります。
既にデータを取得していて、それを使うのであればデータの授受だけで
非常に口数が少なくなります。
しかし、まだデータは無く、これからデータを取得し始めるとなると大変です。
どのようなデータを取ればうまくいくのか、データ設計をしっかりとやり
過不足なくデータを取得できるような仕組みを作るところから始めないといけません。
まずはクライアントや自分たちががちゃんとしたデータを持っているかどうかを確認するところから始まり、データがあればデータの送受信の方法を決めるだけ。
データが無い場合はデータ取得の設計検討からです。
データの送受信に関しては、HDDやSSDで受け取ったり、クラウドストレージ経由で受け取ったりです。最近ではほぼほぼクラウドストレージ経由だろうと思います。
2.データ理解・選択・加工
いわゆるデータの前処理と呼ばれるものの前工程です。
どう言うデータが有って、どう言うデータ構成比率でどのくらいの量があって
など、基礎的な集計処理を行いデータの分析・可視化を行います。
その上で使えそうなデータを選定していきます。
大きなデータになるとデータの把握だけで何日も掛かることになるのですが
ここできちんとデータの特性を把握しておかないと、作業は出戻りになります。
3.データマート(データセット)作成
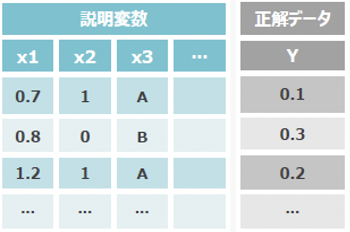
さて、ここから機械学習用のデータを作っていきます。
ある程度使えそうなデータの候補を絞りこんだ上で、機械学習に使えるデータにしていきます。
機械学習に使うことができるのは表形式のデータでひとまとまりにしておかないといけません。
教師ありの機械学習では学習に使うための説明変数と正解を表すための正解ラベルのデータが必要になります。
何を予測したいのかと言う部分を正解ラベルの列にするような加工が必要になります。
また説明変数として用いるデータは全て数値に変換しないといけません。
ここらへんの作業がデータの前処理という工程になります。
機械学習のプロジェクトではなかなか綺麗なデータ、と言うものは少ないです。
前処理をほとんどしなくていいデータと言うものは少なく
余程データ取得の段階で綺麗にデータ取りをすると言う設計がなされていない限りは
データの加工に時間を費やされます。
機械学習では1つの表形式のデータにまとめ上げていきます。
データの種類が多いと、ひとまとめにするにも工夫が必要です。
通常、最終的に数千-数万列のデータまとまっていくことが多いと思います。
行数に関しては、業種やデータ取得の仕組みによってだいぶ変わるため
あまり気にする必要はありませんが、行数が少ない場合には
精度に影響する可能性はあります。
前処理した結果、使える行数が20行ですと言うのと200万行あります
では、さすがに精度に差が出ます。
4.モデル作成

モデルの作成は基本的にはそこまで多くの工数を必要とはしません。
たくさんのモデルを作ったとしても、全てのモデルが利用される訳ではありません。
精度が良くて、使えるモデルを1個作れれば良いのです。
モデルを作成するにはたくさんの手法を試す必要がありますが
ある程度やっていると、この手法が良いだろうと言うのが大体決まってきてしまいますし、そもそも機械的に手法を選択する場合は10種類の手法を一気に試して結果を待つだけなのであまり労力もかかりません。
DataRobotのようなサービスではデータが手元にある場合
そのデータを用いて様々なモデルを自動で作成してくれます。
モデルを作ること自体は現在ではすごく容易で時間が掛かるところでは無いので
機械学習の工数からすると比較的少ない部分となります。
5.精度検証

モデル作成とセットで行われる形になりますが、モデルを作ったらどれくらいの精度になっているのかを検証しながら作っていきます。
精度検証の手法もいくつか存在しますが、一般的にはどれだけ誤差が出たかをみます。
誤差が少ないものが良いモデルと言うことになるので、誤差の少ない順番でモデルを並べていき、最終的には上位の精度のモデルの中から1つが採択されることになるかと思います。
機械学習の流れとしては良いものができるまで
2.データ理解・選択・加工
3.データマート(データセット)作成
4.モデル作成
5.精度検証
を繰り返すこととなり、それでも納得の行く精度にならなければ
1.データ取得
からやり直さなければならないこともあります。
良いモデルは良いデータからしか生まれません。
ゴミデータはなにしてもゴミでしかないのです。
ゴミデータの中に宝の山が混じっていることはかなり稀です。
6.システム実装
データの整備も終わり、そこそこの精度がでることが分かりましたとなったら最後にそのモデルをシステムに組み込んでいきます。
一般的にはWEBのサービスであれば、バックエンド側の機能の一部として提供するように組み込んだりします。
どう運用するか、いくらかけるのか、システム用件と合わせて検討しながらシステム構築をすると言う形になります。
AWS sagemakerの用な機械学習のサービスだと
エンドポイントとしてすぐに提供可能になるものもあるので
そういったサービスを用いると実装面の口数が減ります。
まとめ
機械学習で何ができるのかを学んだ後は機械学習をするには何をするのかを学ぶのが良いでしょう。
だいたいの流れは一緒なので、いろいろな企業のやりかたを参考にするのが良いと思います。
君がエンジニアになるまであと23日
作者の情報
乙pyのHP:
http://www.otupy.net/
Youtube:
https://www.youtube.com/channel/UCaT7xpeq8n1G_HcJKKSOXMw
Twitter:
https://twitter.com/otupython