昨日までのはこちら
100日後にエンジニアになるキミ - 76日目 - プログラミング - 機械学習について
100日後にエンジニアになるキミ - 70日目 - プログラミング - スクレイピングについて
100日後にエンジニアになるキミ - 66日目 - プログラミング - 自然言語処理について
100日後にエンジニアになるキミ - 63日目 - プログラミング - 確率について1
100日後にエンジニアになるキミ - 59日目 - プログラミング - アルゴリズムについて
100日後にエンジニアになるキミ - 53日目 - Git - Gitについて
100日後にエンジニアになるキミ - 42日目 - クラウド - クラウドサービスについて
100日後にエンジニアになるキミ - 36日目 - データベース - データベースについて
100日後にエンジニアになるキミ - 24日目 - Python - Python言語の基礎1
100日後にエンジニアになるキミ - 18日目 - Javascript - JavaScriptの基礎1
100日後にエンジニアになるキミ - 14日目 - CSS - CSSの基礎1
100日後にエンジニアになるキミ - 6日目 - HTML - HTMLの基礎1
今回はデータベースの話の続きでHadoopについてです。
ビッグデータについて
データベースに関する話としては
100日後にエンジニアになるキミ - 36日目 - データベース - データベースについて
でもやっているのですがデータに関する話として
まずビッグデータという言葉があります。
ビッグデータの定義は割と曖昧で、ちょっとでも大きければビッグデータとか
言ってしまうメディアもあるようですが
2012年の定義では大体数10テラバイトから数ペタバイトの範囲のデータを
ビッグデータというようです。
1TB程度のデータはビッグデータとは言いません。
このくらいではマシン1台で十分です。
近年ではデータそのものが肥大化し、1つのマシンで取り扱える量を超える
ビッグデータが存在しています。
そうなると、マシンにインストールしたデータベース1つでは足りなくて
何台ものマシンが必要になります。
そんな問題を解決するために出てきたのが大規模なビッグデータを処理するための
プラットフォームです。
Hadoopの概要
Hadoopはテキスト,画像,ログなどのデータを
高速に処理するオープンソースの分散処理プラットフォームです。
Hadoopは複数のマシンで行う分散処理が特徴で
はデータも複数台のマシンに分散させる事で
容易にスケールアウト出来るようになっています。
大規模なデータを複数台のマシンで一斉に処理することで
高速化も実現しています。
Hadoop登場の背景
Hadoopは、もともとGoogle社が論文として公開した、
Google社内の基盤技術をオープンソースとして実装したものです。
Google社が抱える大量のデータをどう処理するのか
という技術体系の論文が元になっています。
Google File System(GFS) : Google社の分散ファイルシステム
Google MapReduce : Google社での分散処理技術
Hadoop自体はJavaベースで開発されており
今でも開発が進められており、トレードマークはゾウです。

Hadoopの仕組み
Hadoopは、主に以下の2つの要素から構成されています。
HDFS : Hadoop分散ファイルシステム
Hadoop MapReduce : 分散処理フレームワークである
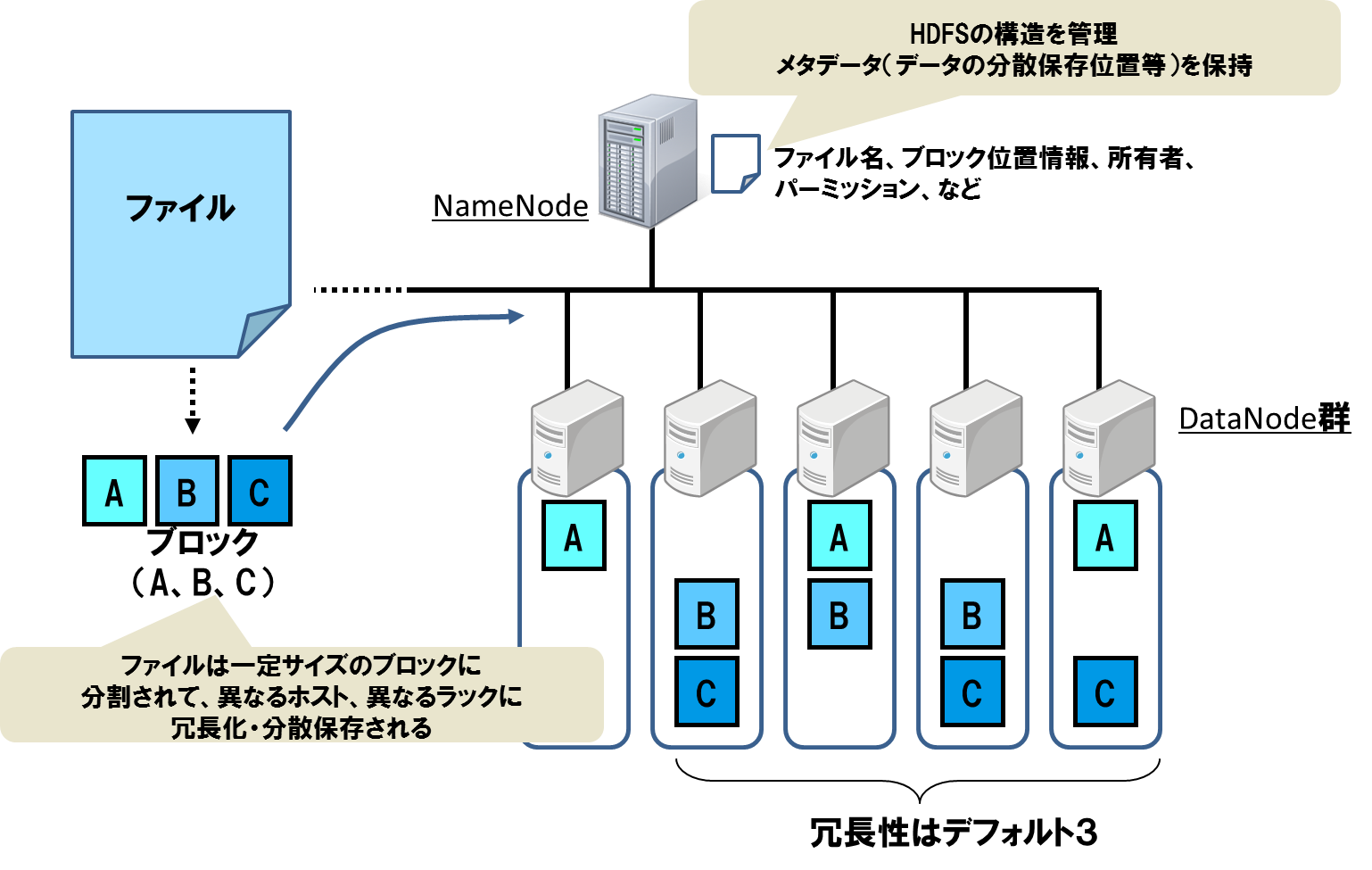
HDFS(Hadoop分散ファイルシステム)
HDFSではマスターとスレーブ、2つのノードによって構成されます。
マスターノード:NameNode
スレーブノードで:DataNode
NameNodeはファイルシステムのメタ情報を管理し
DataNodeはデータの実体を保存します。
ファイルを格納する際に一定サイズで分割したデータ(ブロック)
としてDataNodeに保存します。
そして、どこかのDataNodeが故障してデータが消失しないように
複数のDataNodeにブロックのレプリカを保存します。
これによりデータの欠損を防ぐ仕組みになっています。
デフォルトではレプリカ数は3なので、2つのサーバーが故障しても
データは消失しない形になります。
参考:NTTデータ・分散処理技術「Hadoop」とは
https://oss.nttdata.com/hadoop/hadoop.html
NameNodeに関しては単一ノードの場合は故障すると使用できなくなりますが
Active-Standby構成にしておくことで冗長化が図れます。
サーバーの台数を増やすことで、データの保存量も増やせます。
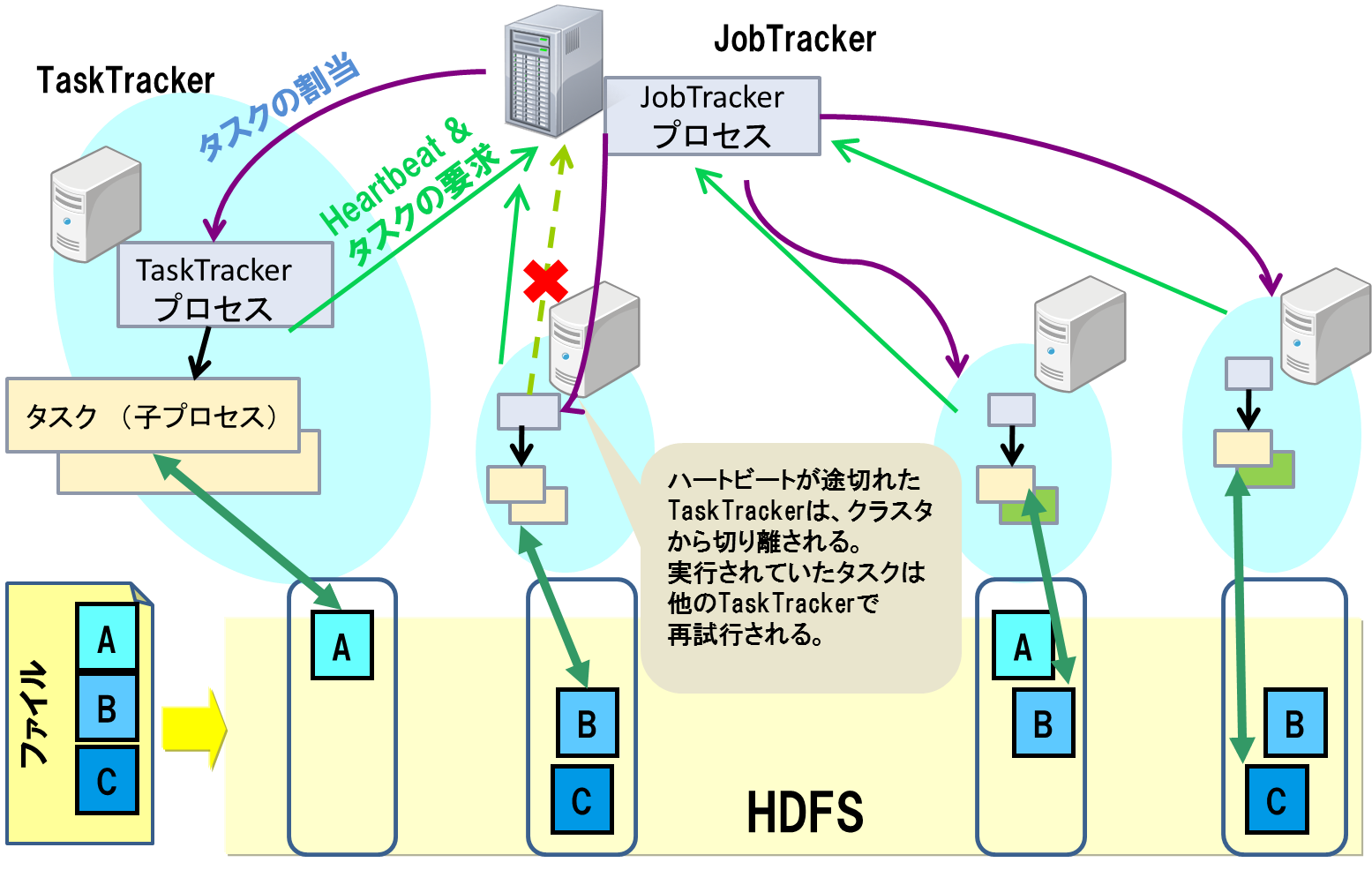
Hadoop MapReduce(分散処理フレームワーク)
もう一つの構成要素としてMapReduceがあります。
これはデータを分割して並列処理し、より迅速に結果を得るための仕組みです。
MapReduceではマスターとスレーブ、2つのノードによって構成されます。
マスターノード:JobTracker
スレーブノードで: TaskTracker
JobTrackerは、MapReduceジョブの管理やTaskTrackerへの
タスクの割り当てとリソース管理を行います。
TaskTrackerはタスクの実行を行います。
TaskTrackerが故障しても、JobTrackerが
他のTaskTrackerに同じタスクを割り当て
最初からやり直す必要なく、継続実行が可能です。
参考:NTTデータ・分散処理技術「Hadoop」とは
https://oss.nttdata.com/hadoop/hadoop.html
MapReduceアプリケーションは以下の処理を行なっています。
ジョブ定義 : mapとreduceを処理するための情報を定義
map処理 : 入力データに対してキーバリュー形式でデータを意味づけ
reduce処理 : map処理のキーごとに集約されたデータに対して処理を実行
MapReduceの処理が終わると、最終的な結果が出力されます。
処理を行うサーバーの台数が増えるほど、高速に処理が終わることにもなるので
計算可能な台数が多いと有利になります。
Hadoopの特徴
主なHadoopの特徴としては以下の3点が挙げられると思います。
サーバーのスケーラビリティー
HDFSにより、リソース不足に陥った場合はサーバーを増やすことで
データ容量を確保したり、計算資源を確保できます。
耐障害性
一般的に市販されているサーバーにソフトウェアをインストールすれば
Hadoop環境を構築できるため、専用のハードウェアなどは不要になります。
加えてHDFSやTaskTracker等の仕組みにより
数台までであれば故障してもシステムは稼働します。
処理の柔軟性
従来型のデータベース等と異なる点は、HDFSにデータを格納する際に
スキーマ定義が不要であるということです。
データを取り出す際に意味づけをすれば良いので
とりあえずデータを格納しておくということができます。
どういう企業で導入されているのか?
自分がHadoopを知ったのは2012年です。
その当時ではセミナーなどでも取り入れている企業さんはほぼ無く
我々は導入していたので、なかなか珍しい方だったと思います。
台数としてはマスターのネームノードが3台構成
データノードが20台だったかと思います。
データ量は月間で1行100列くらいのログデータが50億行くらいです。
これくらいの規模のデータになると数TBになっていたので
1台では収まりきりませんし、集計時のメモリも足りません。
自分のPCでやったことのある作業のMAXは
200GBくらいのファイルの集計くらいですので
目安としては数TBを超えるデータになったら
分散処理を考えるという感じでしょうか。
このくらいのデータを取り扱っている所は
ほぼほぼ分散処理の基盤を利用していると思います。
ただし、大量のデータを抱えており、かつHadoopを使いこなせるだけの
人的・金銭的リソースがある企業なら使う価値がありますが
そんなのはごく一部に過ぎないかもしれません。
お金があって、データもある企業でなければ
導入は難しいし、意味がないです。
その昔公表していたところで行くと
Yahoo
サイバーエージェント
NTTデータ
日立ソリューションズ
リクルートテクノロジーズ
大企業さんばかりですねーー
Hadoopなどの分散処理系の技術を身に付けたい場合は
ここら辺の企業さんで仕事をしないと
身につかないかもしれませんね。
ちなみに、自分は今は1ミリも利用しておりませんwww
まとめ
分散処理はビッグデータの取り扱いが当たり前になった今では
必要不可欠なものです。
分散処理を世間一般に広めた立役者として
Hadoopというものの存在はかなり大きいと思いますので
知識として是非抑えておきましょう。
君がエンジニアになるまであと14日
作者の情報
乙pyのHP:
http://www.otupy.net/
Youtube:
https://www.youtube.com/channel/UCaT7xpeq8n1G_HcJKKSOXMw
Twitter:
https://twitter.com/otupython