データ取得スクリプトについてはかなり長めのインターバルを入れて作りましたが、割愛します。
関連書籍
ゼロから作るDeep Learning
詳解 ディープラーニング
はじめに
今回はDNNのチュートリアルみたいな物です。RNNではありませんので、ご容赦ください。
資料にあったkerasを使ってみて簡単だったので、時系列データのパターンを使った予測(回帰問題)で試してみようと思います。
データは沢山あるのですが、とりあえず今回は気象庁で公開されている過去のデータを利用させていただきます。
こういう時には助かります。
(今回は暑さで有名な熊谷を選択)
出典:気象庁ホームページ
kerasの使い方
入力層-隠れ層-出力層の作成
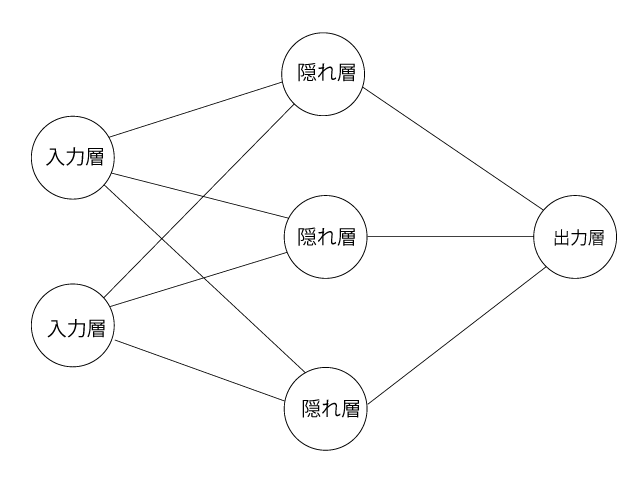
とりあえず、上記のような入力層に2、隠れ層に3、出力層に1となるニューラルネットワークを作ってみます。
# 入力層
n_in = 2
# 隠れ層
n_hidden = 3
# 出力層
n_out = 1
# モデルの作成
model = Sequential()
# 入力層 から 隠れ層
model.add(Dense(n_hidden, input_shape=(n_in,), kernel_initializer=TruncatedNormal(stddev=0.01)))
model.add(Activation('tanh'))
# 隠れ層 から 出力層 恒等関数の使用
model.add(Dense(n_out, kernel_initializer=TruncatedNormal(stddev=0.01)))
model.add(Activation('linear'))
kernel_initializerで重みの初期化を自動で行ってます。公式に説明があります。
推奨なので初心者の自分はそのままです。
隠れ層の活性化関数公式もreluとかtanhとか色々ありますが、とりあえずtanh
出力層はliner
隠れ層を追加する
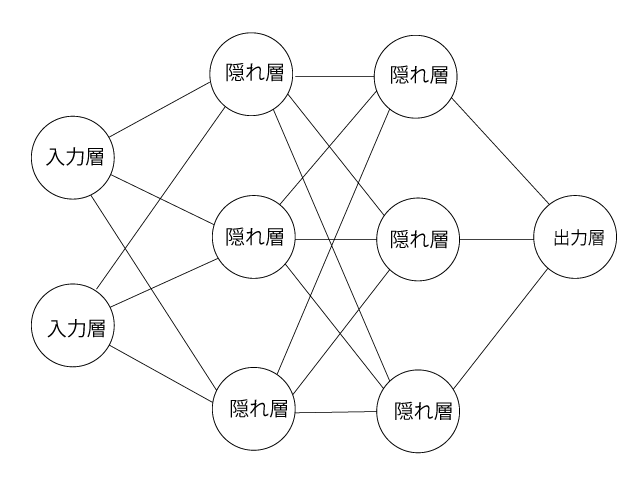
# モデルの準備
model = Sequential()
# 入力層 から 隠れ層
model.add(Dense(n_hidden, input_shape=(n_in,), kernel_initializer=TruncatedNormal(stddev=0.01)))
model.add(Activation('tanh'))
# 隠れ層から隠れ層
model.add((Dense(n_hidden, kernel_initializer=TruncatedNormal(stddev=0.01))))
model.add(Activation('tanh'))
# 隠れ層 から 出力層 恒等関数の使用
model.add(Dense(n_out, kernel_initializer=TruncatedNormal(stddev=0.01)))
model.add(Activation('linear'))
二層目以降は入力数の指定は必要ないです。
確率的勾配降下法と誤差関数を決めてモデルの設定
# 確率的勾配降下法 Adam
optimizer = Adam(lr=0.001, beta_1=0.9, beta_2=0.999)
# 損失関数 二乗平均誤差
model.compile(loss='mean_squared_error',
optimizer=optimizer)
ほぼテンプレです。
学習の実施!!
# 学習のエポック数
epoch = 1000
# バッチサイズ
batch_size = 50
# 学習の実施
history = model.fit(X_train, Y_train,
epochs=epoch,
batch_size=batch_size,
validation_data=(X_validation, Y_validation)
)
X_trainに学習用データ、Y_trainに正解データを渡します。
X_validation, Y_validationにはそれぞれ検証用に用意した学習用データとは違うデータを渡します。
batch_sizeを指定して、ミニバッチ学習を行います。
historyで返り値を取得しているのは、historyオブジェクトで学習の履歴を見るためですが、割愛します。
作成したモデルの使用
Y = model.predict(X)
Xに学習データと同じ、連続したデータを渡し、Yで予測された正解データに似たデータが取り出せます。
時系列データの準備
データの取得
気象庁の過去の気象データから年ごとの平均気温を取得します。
何度も取得する訳にもいかないので、ファイルに保存します。ファイル名、パスは任意の物へ変更してください。
データ取得スクリプトについてはかなり長めのインターバルを入れて作りましたが、割愛します。
FILE = 'weather_log.npz'
# 気温のリストを取得
def get_data():
# 一度ファイルを保存済みであれば、それを読み込む
if os.path.isfile(FILE):
result_list = np.load(FILE)['x']
else:
###################################
# 割愛します。
###################################
result_list = np.array(tmp_list)
# ファイルへ保存
np.savez(FILE, x=result_list)
return result_list
データの正規化、データセットの作成
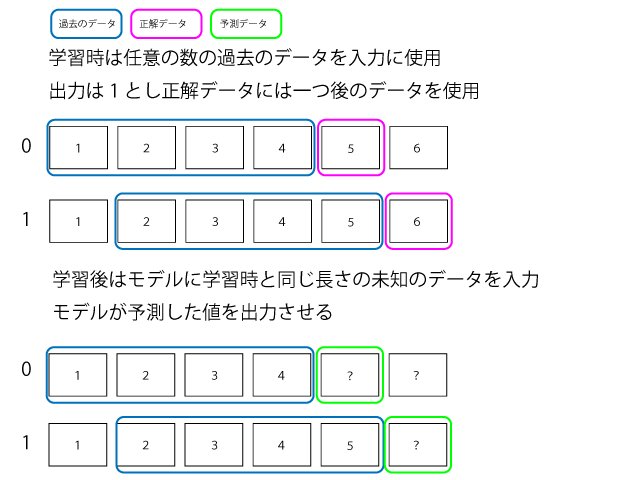
時系列データなので連続したデータのセットを入力、直後のデータを正解として作成し、連続したデータを与えると直後を予測したデータを返してくれるようにします。
例過去10個の連続したデータセットを与えて、次の結果を予測したい場合は入力層が10としてそこに過去10個のデータを与え、出力層を1とします。
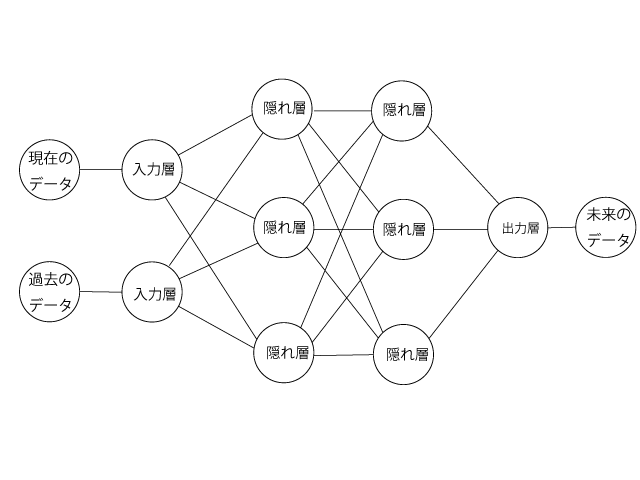
# データの正規化
def normalize(x):
result_list = (x - x.mean()) / x.std()
return result_list
# 気温データを取得
temp_list = get_data()
# 正規化を実施
normalize_data = normalize(temp_list)
# 入力層の次元数 学習で参考データとする過去の長さ
input_data_length = 10
data = []
target = []
# 学習で使用するデータの作成
for i in range(0, len(normalize_data) - (input_data_length + 1)):
data.append(normalize_data[i: i + input_data_length])
target.append(normalize_data[i + input_data_length])
X = np.array(data)
Y = np.array(target)
# 学習データから検証データを作成
X_train, X_validation, Y_train, Y_validation = \
train_test_split(X, Y, test_size=0.2)
気温データをそのまま使用せず一旦正規化を行っています。
input_data_lengthで参考とする過去のデータ数を決めています。これはニューラルネットワークの入力の数にもなります。
train_test_splitを使用して学習用のデータと検証データを8:2で分けています。
コード全体
非正規化の処理を入れたりとか取得したデータの後半をモデルのテストデータとして利用していますが基本的には説明したコードで構成されています。
import requests, bs4, re, time
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from keras.models import Sequential
from keras.layers import Dense, Activation
from keras.layers.core import Dropout
from keras.optimizers import Adam
from keras.initializers import TruncatedNormal
import os.path
FILE = 'weather_log.npz'
# 一部ゴミが入ってしまうので
# ゴミの削除のための関数
def remove_dust(x):
tmp_regex = re.compile(r'\d+.+\d')
tmp = []
for line in x:
tmp += tmp_regex.findall(line)
return tmp
# データの正規化
def normalize(x):
result_list = (x - x.mean()) / x.std()
return result_list
# 正規化したデータのリセット
def de_normalize(x, y):
result_list = y * x.std() + x.mean()
return result_list
# 気温のリストを取得
def get_data():
# 一度ファイルを保存済みであれば、それを読み込む
if os.path.isfile(FILE):
result_list = np.load(FILE)['x']
else:
###################################
# 割愛します。
###################################
result_list = np.array(tmp_list)
# ファイルへ保存
np.savez(FILE, x=result_list)
return result_list
# メイン
if __name__ == '__main__':
# 入力層の次元数 学習で参考データとする過去の長さ
input_data_length = 10
data = []
target = []
split_line = 1300
temp_list = get_data()
normalize_data = normalize(temp_list[:split_line])
# 学習で使用するデータの作成
for i in range(0, len(normalize_data) - (input_data_length + 1)):
data.append(normalize_data[i: i + input_data_length])
target.append(normalize_data[i + input_data_length])
X = np.array(data)
Y = np.array(target)
# 学習データから検証データを作成
X_train, X_validation, Y_train, Y_validation = \
train_test_split(X, Y, test_size=0.2)
# 隠れ層
n_hidden = 200
# 出力層
n_out = 1
# 学習のエポック数
epoch = 1000
# バッチサイズ
batch_size = 100
# モデルの作成
model = Sequential()
# 入力層 から 隠れ層
model.add(Dense(n_hidden, input_shape=(input_data_length,), kernel_initializer=TruncatedNormal(stddev=0.01)))
model.add(Activation('tanh'))
model.add(Dropout(0.5))
# 隠れ層の作成
model.add((Dense(n_hidden, kernel_initializer=TruncatedNormal(stddev=0.01))))
model.add(Activation('tanh'))
model.add(Dropout(0.5))
# 隠れ層 から 出力層 恒等関数の使用
model.add(Dense(n_out, kernel_initializer=TruncatedNormal(stddev=0.01)))
model.add(Activation('linear'))
# 確率的勾配法 Adam
optimizer = Adam(lr=0.001, beta_1=0.9, beta_2=0.999)
# 損失関数 二乗和誤差
model.compile(loss='mean_squared_error',
optimizer=optimizer)
# 学習の実施
history = model.fit(X_train, Y_train,
epochs=epoch,
batch_size=batch_size,
validation_data=(X_validation, Y_validation)
)
# テスト用データの作成
normalize_data = normalize(temp_list[split_line:])
data = []
target = []
for i in range(0, len(normalize_data) - (input_data_length + 1)):
data.append(normalize_data[i: i + input_data_length])
target.append(normalize_data[i + input_data_length])
X_test = np.array(data)
Y_test = np.array(target)
# 学習済みのモデルで
# テストデータを使って出力の確認
predicted = model.predict(X_test)
test_data = de_normalize(temp_list, Y_test)
result_data = de_normalize(temp_list, predicted)
# X軸のリスト作成
month_list = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]
tmp_ticks = []
for line in range(0,len(result_data)//12 + 1):
tmp_ticks.extend(month_list)
X_ticks = np.arange(0,len(result_data))
X_ticks_str = tmp_ticks[12-len(result_data)%12:]
# 実際のデータ
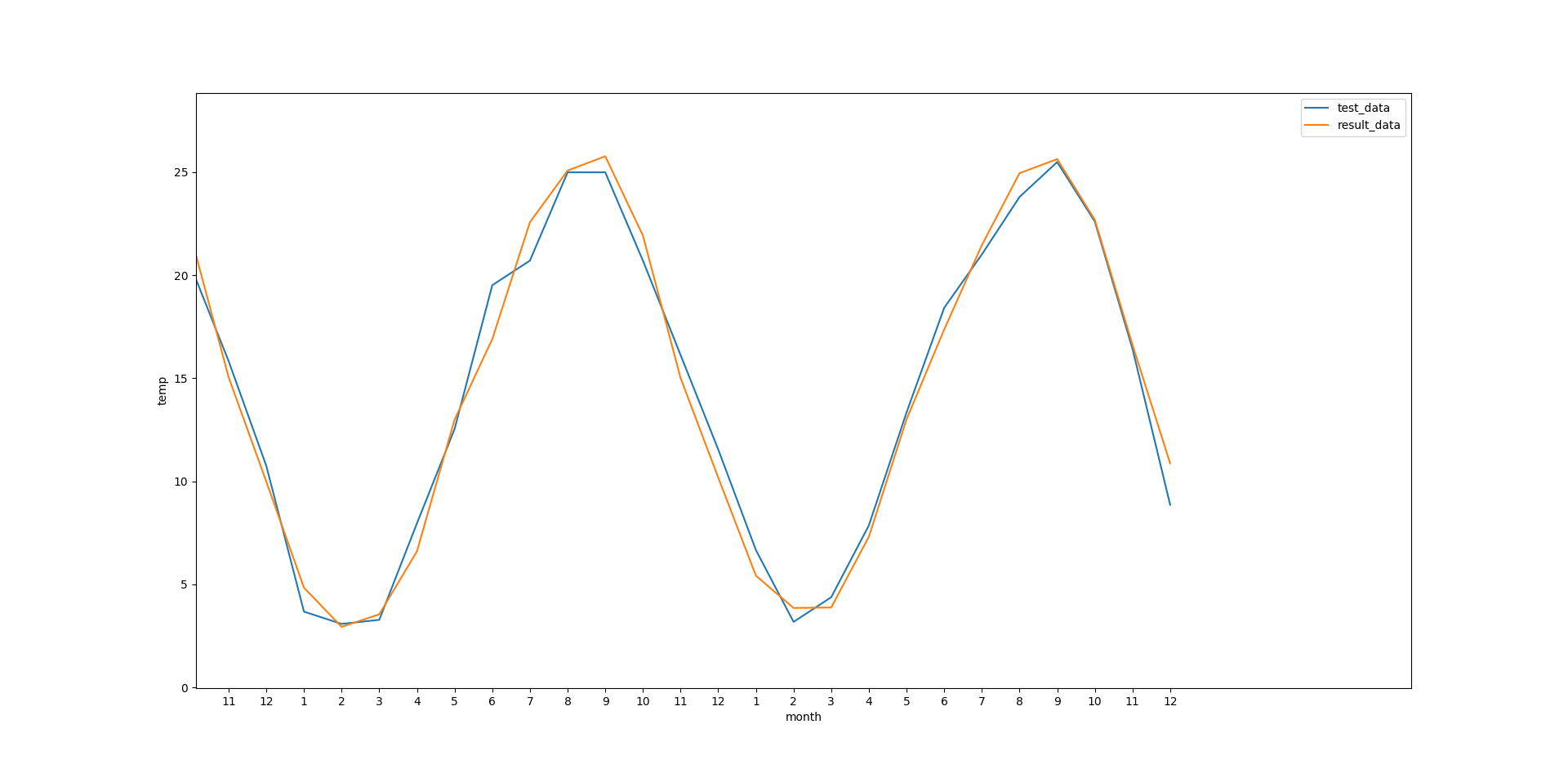
plt.plot(test_data, label='test_data')
# モデルが出力したデータ
plt.plot(result_data, label='result_data')
plt.xticks(X_ticks, X_ticks_str)
plt.legend()
plt.xlabel("month")
plt.ylabel("temp")
plt.show()
表示された結果の一部ですが、こんな感じです。
パターンが簡単なのでい一応予測できています。