はじめに
こんにちは!
any 株式会社でエンジニアをしている @othelloman です。
この記事は any プロダクトチーム Advent Calendar 2025、23日目の記事です!
今回は以前話題になって気になっていたけど、なかなか触れずにいた Generative Agents を触って記事にしてみました。
本記事は業務とは直接関係なく、個人として Generative Agents を触ってみた記録です。any のプロダクトや公式な技術検証を示すものではありません。
Generative Agents とは
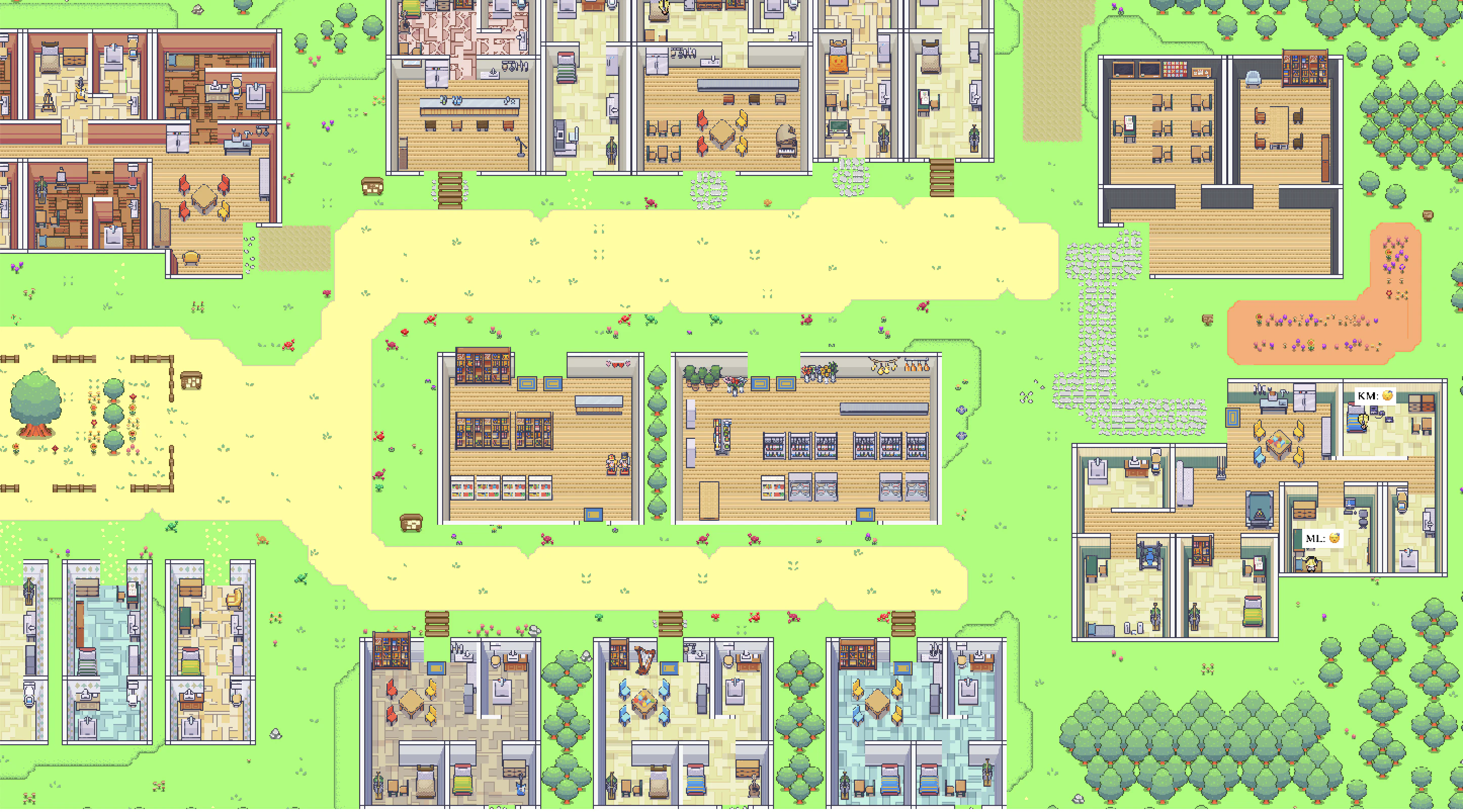
Generative Agents は、スタンフォード大学と Google Research の研究者が提案した
「仮想の街で人間らしく生活するエージェント」を扱う研究プロジェクトです。
大規模言語モデルを使って、エージェントが記憶・計画・会話・振り返りを繰り返しながら
暮らしていく様子をシミュレートします。
公式実装は以下のリポジトリで公開されています。
この記事では、このリポジトリをローカルで動かしつつ、ハマりどころやコードをざっくり読んで分かったことをメモしていきます。
とりあえず動かしてみる
インストール
git clone https://github.com/joonspk-research/generative_agents
cd generative_agents
pip install -r requirements.txt
設定ファイルの用意
reverie/backend_server/utils.py を新規作成。
open_ai_api_key だけ自身のものに書き換えてください。
# Copy and paste your OpenAI API Key
openai_api_key = "<Your OpenAI API>"
# Put your name
key_owner = "<Name>"
maze_assets_loc = "../../environment/frontend_server/static_dirs/assets"
env_matrix = f"{maze_assets_loc}/the_ville/matrix"
env_visuals = f"{maze_assets_loc}/the_ville/visuals"
fs_storage = "../../environment/frontend_server/storage"
fs_temp_storage = "../../environment/frontend_server/temp_storage"
collision_block_id = "32125"
# Verbose
debug = True
環境の起動
cd environment/frontend_server/
python manage.py runserver 0.0.0.0:8000
localhost:8000 を開くとブラウザで確認できます。
シミュレーションの起動
別のコンソールで
cd generative_agents/reverie/backend_server
python reverie.py
どのシミュレーションの続きから開始するか聞かれるので以下のように入力します。
(後述のシミュレーションの保存後はそれを入力することで続きから再開できる)
# Enter the name of the forked simulation:
base_the_ville_isabella_maria_klaus
次に今回のシミュレーションの新規保存フォルダ名を README の通り指定します。
(かぶっていなければなんでもいい)
# Enter the name of the new simulation:
test-simulation
コンソールに "Enter option: " と表示されていれば OK です。
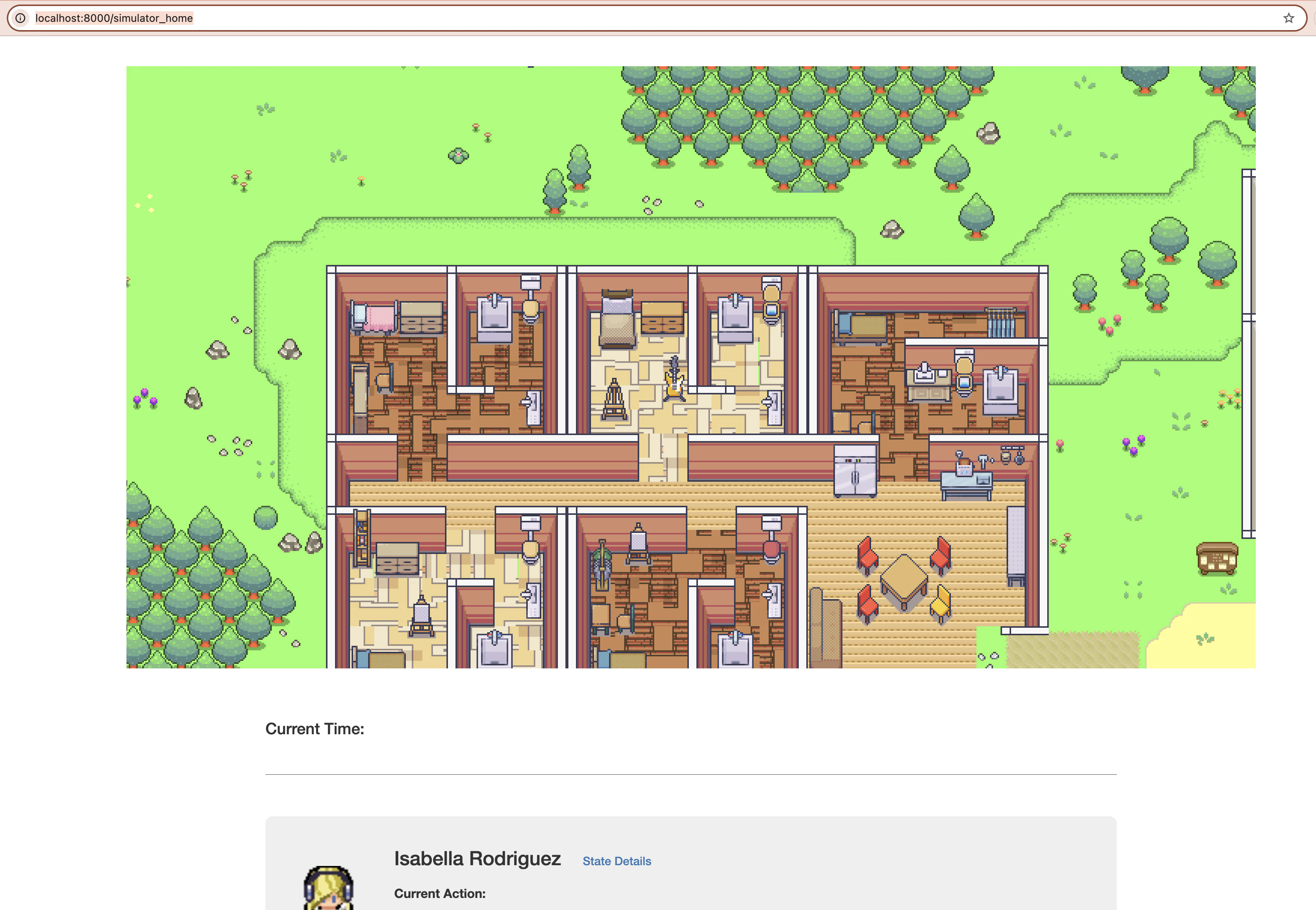
ブラウザで http://localhost:8000/simulator_home にアクセスすると以下のような画面でマップとエージェントが確認できます。
このままだと動かなかったので修正する
TOKEN LIMIT EXCEEDED エラー
コンソールに表示されていた Enter option: に run 1 と入力することでステップ実行できるのですが、このまま動かすと TOKEN LIMIT EXCEEDED エラーになりました。
調べてみると AI のエラーを TOKEN LMIT EXCEEDED で握りつぶしていました。
TOKEN 数の問題ではなく、もう使えない model の text-davinci-002 と text-davinci-003 を使おうとしてエラー発生していたので model 指定箇所を修正します。
以下を追記
openai_model = "gpt-3.5-turbo-instruct"
以下を修正
response = openai.Completion.create(
# model=gpt_parameter["engine"],
model=openai_model,
movement フォルダがないよエラー
以下のように追記部分を書いてフォルダを作成します。
create_folder_if_not_there(f"{sim_folder}/movement") # 追記
curr_move_file = f"{sim_folder}/movement/{self.step}.json"
with open(curr_move_file, "w") as outfile:
outfile.write(json.dumps(movements, indent=2))
動かす
さっき Enter option: となっていたコンソールに run 1 などを入力すると step 実行されるようになります。
1 step はシミュレータ内の 10秒なので 1時間進ませたい場合は run 360 です。
とりあえず動くようになりました。
Enter otion: のコマンド
-
run <step-count>- 1 などの数値を入れるとシミュレータの世界の時間が進む(1 につき10秒)
-
save- 保存して続行
-
fin- 保存して終了
-
exit- 保存せずに終了
続きから開始する
先に入力した新規保存フォルダ名を起動直後の以下の入力時に入力する(例えばさっき起動した test-simulation を入力する場合は以下)
# Enter the name of the forked simulation:
test-simulation
この場合も新規保存フォルダが必要なので新規命名します。
# Enter the name of the new simulation:
test-simulation-2
まだ動かないときは以下もチェック
- ブラウザで
/simulator_homeを開いていない(ブラウザを開いていないときはログも進まない) - 処理が重いときよく止まる
- 処理しているのでブラウザ側から見て止まっているように見えるけどログは進んでいたりする
- LLM の生成に時間がかかっているだけかもしれない
- ブラウザリロードする
行動ログや会話を日本語化してみる
前項で動くようになるかと思いますが、せっかくなので少し変更を加えてみたいと思います。
ただ動いているだけでも面白いのですが、行動ログや会話が日本語の方が理解しやすいので日本語化してみます。
失敗も含めて日本語化の過程を記載します。
prompt に「日本語で説明してください」を追加する
response = openai.Completion.create(
# model=gpt_parameter["engine"],
model=openai_model,
prompt="日本語で説明してください。\n"+prompt,
まずは素直に、prompt の先頭に「日本語で説明してください。」を足してみました。
ですが、ほとんど効かず失敗でした。
# IMPORTANT: など、強めに効きそうなプロンプトも試したのですがそれでもダメ。
どうやら 会話のテンプレとして渡している英文の例文の影響が強すぎるようです。
(おそらくこれが few-shot として効いている)
task_decomp_v1.txt の例文を日本語に変更してみる
そこで、LLM に渡されていそうな「アウトプット例」を書き換えてみます。
1) Samはイーゼルとキャンバスを準備している(所要時間: 15分, 残り時間: 255分)
このように、英語だった例文を日本語に書き換えたところ、
一部の出力が日本語になりました。
この方法で、すべての例文を日本語化すれば、かなりの部分まで日本語化できそうです。
ただ、例文の量がそれなりにあるので「もう少し楽な方法がないかな」と思い、別アプローチも試すことにしました。
Competion.create じゃなくて ChatCompletion.create を使うようにして role: system で日本語化用のプロンプトを入れる
OpenAI API の Completion.create は、最近のモデルのように role を渡すことができません。
「強めの命令(system メッセージ)が使えないから効きが悪いのでは?」と思い、ChatCompletion を使うように修正してみました。
すでに ChatCompletion 用の実装も存在していたのですが、ひとまず元の箇所を直接書き換えています。
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[
{"role": "system", "content": "日本語で説明してください"},
{"role": "user", "content": prompt}
],
この変更を入れたところ、ログが少しずつ日本語混じりになり始めました。
いけそうな気配があります。

内部でパース用に使われている英文が日本語されて壊れるので修正
当時は response_format: { type: "json_schema" } のような指定が存在せず、
すべてテキスト出力前提で、
- 決まった英文のフォーマットで出してもらう
-
split()でテキストを分割してパースする
という実装が各所に書かれています。
そのため、出力予定の英文が日本語化されてしまうと、
パース用の split("...") が壊れてクラッシュするようになってしまいました。
k = [j.strip() for j in i.split("(duration in minutes:")]
このような箇所を、日本語化後のフォーマットでも動くようにちまちま修正していきます。
数が多いのでここでは割愛しますが、このあたりは Copilot にかなり頼りました。
AI 便利。
とりあえずいけた 
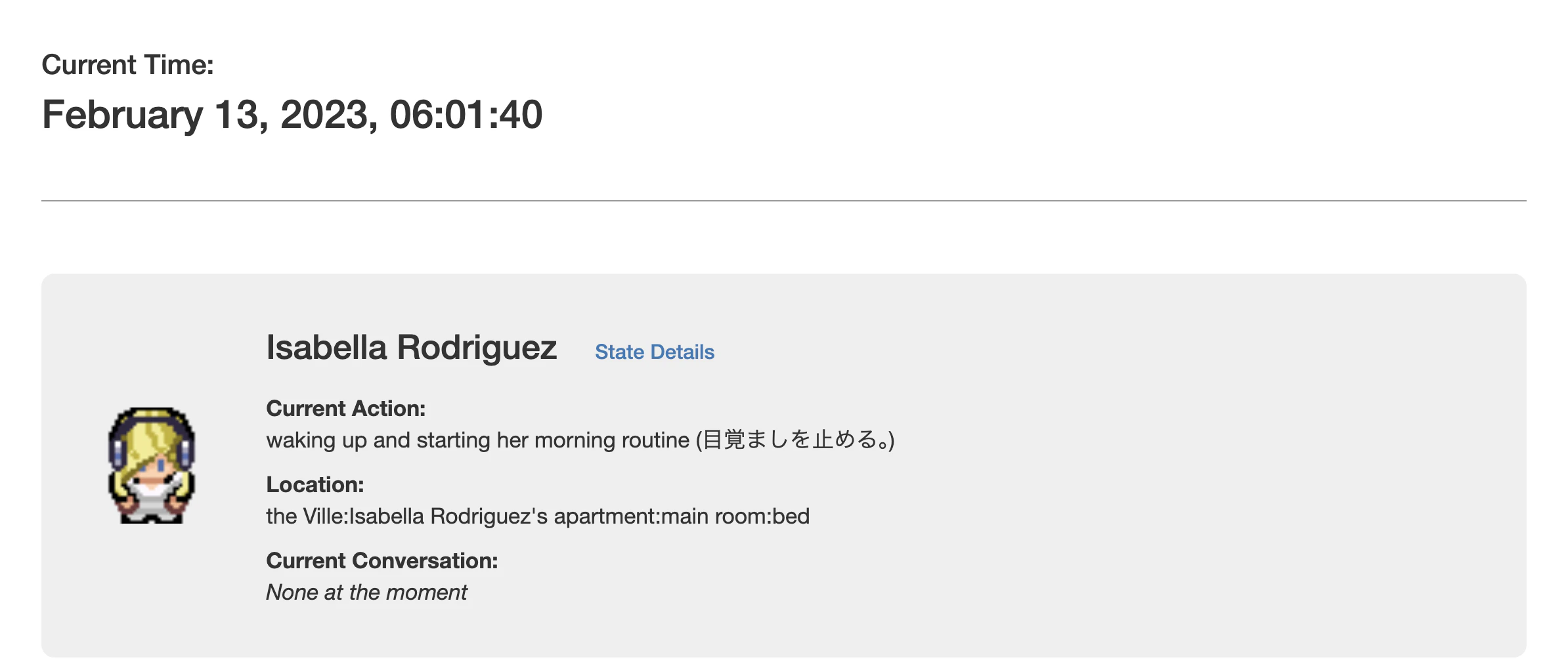
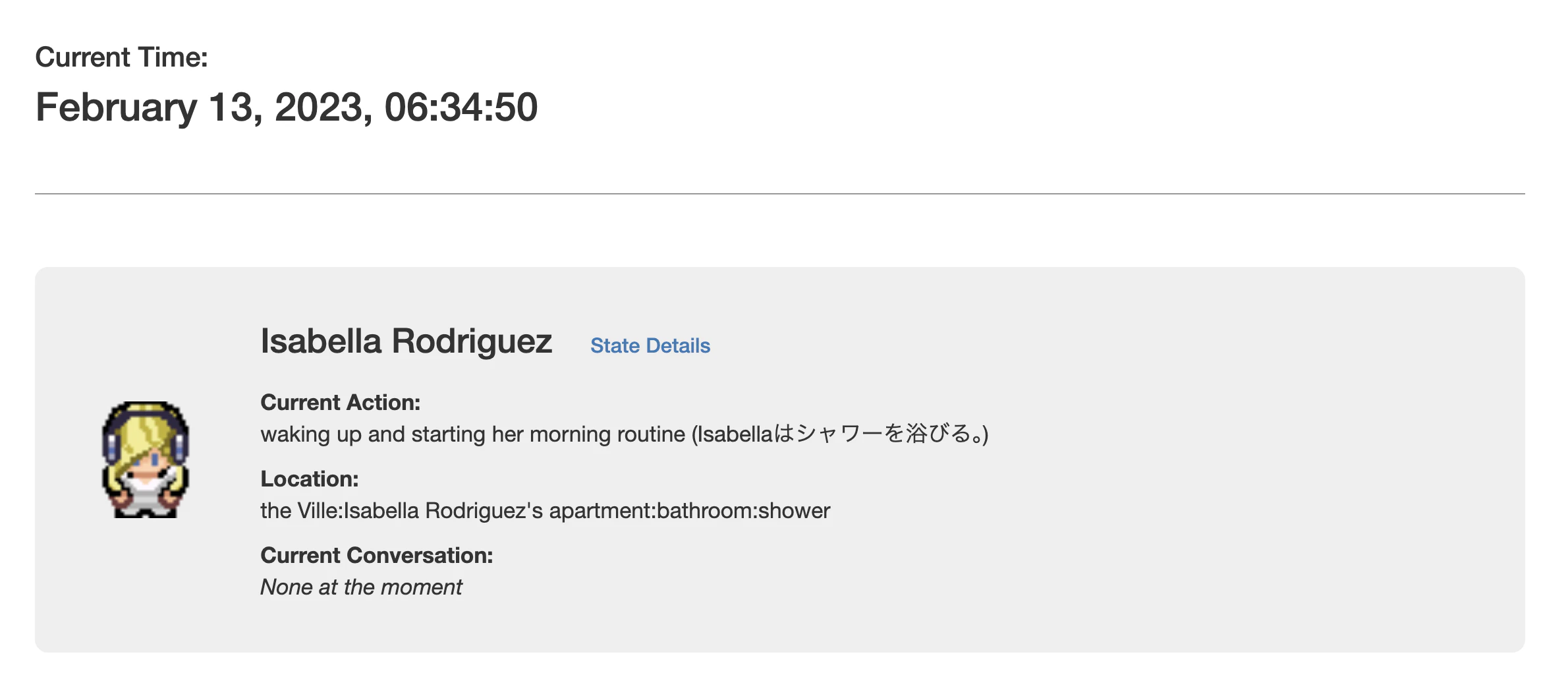
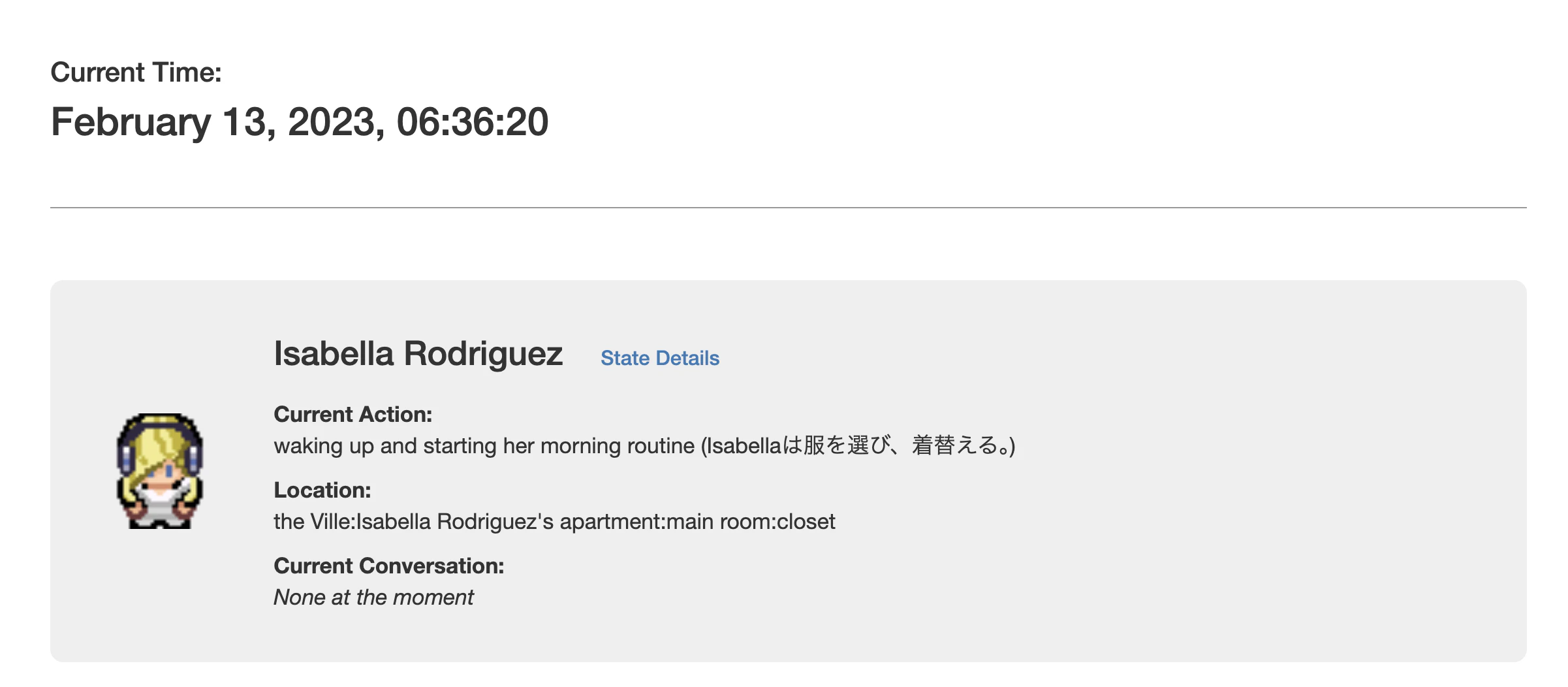
OpenAI を叩いている箇所は他にもいくつかあり、そこも同様に role: system で日本語化用のプロンプトを挟んだり、プロンプト文を少し調整することで、日本語が出るようになりました。
左側の waking up ... のようなログと、右側の (目覚ましを止める) のような吹き出しで モデルの呼ばれ方が違うらしく、現状では左側が英語のまま残っている部分もあります。
それでも、「住人が今何をしているのか」がだいたい日本語で追える状態 にはなったので、ひとまずここまでで良しとしています。

どのように動いているかを調べる
何をやっているかわかるようになったのでどのような仕組みで動いているか調べていきます。
シミュレーション起動用スクリプトの reverie.py を読んでいきます。
ReverieServer.init
# Enter the name of the forked simulation:
base_the_ville_isabella_maria_klaus
# Enter the name of the new simulation:
test-simulation
最初に入力したこれらの入力を以下で使っています。
前者を後者にコピーしているようです。
copyanything(fork_folder, sim_folder)
コピー後に以下のように meta.json を読み込んでいます。
with open(f"{sim_folder}/reverie/meta.json") as json_file:
reverie_meta = json.load(json_file)
{
"fork_sim_code": "base_the_ville_isabella_maria_klaus",
"start_date": "February 13, 2023",
"curr_time": "February 13, 2023, 00:00:00",
"sec_per_step": 10,
"maze_name": "the_ville",
"persona_names": [
"Isabella Rodriguez",
"Maria Lopez",
"Klaus Mueller"
],
"step": 0
}
fork_sim_code はコピー元のフォルダ。
sec_per_step は 1 ステップを何秒にするかですかね。
10秒毎で遅いと感じるならもっと速度を上げることもできそうです。
次に住人のロードをしています。
curr_persona = Persona(persona_name, persona_folder)
Persona 内で個々人の記憶用のファイルを読み込んでいます。
"the Ville": {
"Ryan Park's apartment": {
"bathroom": [
"shower",
"bathroom sink",
"toilet"
],
"main room": [
"bed",
"computer desk",
"cooking area",
"kitchen sink",
"closet",
"refrigerator"
]
},
場所の記憶です。
システムとして空間の設定を読み込むのではなくそれぞれの住人が空間の記憶を持つ仕組みになっているんですね。
{
...
"daily_plan_req": "Maria Lopez spends at least 3 hours a day Twitch streaming or gaming.",
"name": "Maria Lopez",
"first_name": "Maria",
"last_name": "Lopez",
"age": 21,
"innate": "energetic, enthusiastic, inquisitive",
"learned": "Maria Lopez is a student at Oak Hill College studying physics and a part time Twitch game streamer who loves to connect with people and explore new ideas.",
"currently": "Maria Lopez is working on her physics degree and streaming games on Twitch to make some extra money. She visits Hobbs Cafe for studying and eating just about everyday.",
"lifestyle": "Maria Lopez goes to bed around 2am, awakes up around 9am, eats dinner around 6pm. She likes to hang out at Hobbs Cafe if it's before 6pm.",
"living_area": "the Ville:Dorm for Oak Hill College:Maria Lopez's room",
...
"f_daily_schedule": [
[
"sleeping",
540
],
[
"waking up and completing her morning routine (getting out of bed)",
5
],
...
住人の特徴の元データのようなものも読み込んでいました。
f_daily_schedule にもスケジュールが書かれていますが、これは実行されるロジックそのものというよりは、LLM に渡すサンプルとして使われていそうな雰囲気でした。
ReverieServer.open_server
while True:
sim_command = input("Enter option: ")
elif sim_command[:3].lower() == "run":
int_count = int(sim_command.split()[-1])
rs.start_server(int_count)
ここで run 1 のようなコマンドを受け取り、最後の数値を int_count として start_server に渡しています。
ソースを眺めていると、こんな文字列も見つかりました。
"print all persona schedule"
気になったので実際に叩いてみます。
Isabella Rodriguez
---
Maria Lopez
---
Klaus Mueller
---
run 1 の前に叩いたときは、こんな出力でした。
まだ何もスケジュールが決まっていないようです。
次に、run 1 を実行したあとにもう一度叩いてみると、以下のようにその日のスケジュールがずらっと出力されました。
Isabella Rodriguez
06:00 || sleeping
06:05 || 起きて、朝のルーティンを始めます (目覚ましを止める)
06:10 || 起きて、朝のルーティンを始めます (Isabellaはベッドから起き上がる)
06:15 || 起きて、朝のルーティンを始めます (Isabellaは顔を洗う)
06:20 || 起きて、朝のルーティンを始めます (Isabellaは歯を磨く)
06:35 || 起きて、朝のルーティンを始めます (Isabellaはシャワーを浴びる)
06:45 || 起きて、朝のルーティンを始めます (Isabellaは服を選び、着替える)
06:55 || 起きて、朝のルーティンを始めます (Isabellaは朝食を作る)
07:00 || 起きて、朝のルーティンを始めます (Isabellaは朝食を食べる)
08:00 || Hobbs Cafeを開ける準備をしています
09:00 || Hobbs Cafeでカウンター業務を開始します
12:00 || Hobbs Cafeでお客様を接客しています
13:00 || ランチを取っています
19:00 || Hobbs Cafeでお客様を接客しています
20:00 || Hobbs Cafeの閉店準備をしています
21:00 || Hobbs Cafeを閉店します
22:00 || バレンタインデーのパーティーの準備をしています
23:00 || リラックスして一日を振り返ります
24:00 || 寝ています
24:00 || sleeping
どうやら 1 step 目(run 1)のタイミングで、その日のスケジュール作成しているようです。
他にも print persona spatial など便利そうなコマンドがありましたが、run コマンドの中身の方が気になるので続きを追っていきます。
ReverieServer.start_server
while (True):
if int_counter == 0:
break
ループで始まります。
curr_env_file = f"{sim_folder}/environment/{self.step}.json"
ここでは、現在の step に対応する環境ファイル(例:0.json, 1.json …)を読み込んでいます。
0.json は、フォーク元からコピーした時点ですでに存在していました。
next_tile, pronunciatio, description = persona.move(
self.maze, self.personas, self.personas_tile[persona_name],
self.curr_time)
ぱっと見「移動用の関数」っぽいですが、返り値に next_tile 以外も含まれているので、単なる移動以上のことをまとめてやっていそうです。
この関数以外深そうなものがなかったのでこれを追うことにします。
Persona.move
perceived = self.perceive(maze)
この関数では
- 住人の現在位置の周りのタイル情報を取得
- イベントが追加されているタイルがある場合、そのイベントのスコア付けを LLM に依頼
- 結果を記憶として保存
しています。
引数は住人とイベント情報です。
住人の会話に関しても会話イベントとして扱われているようです。
会話も「会話イベント」として扱われており、同じ仕組みでスコア付きのイベントとして蓄積されます。
戻り値は、スコアを含んだイベント情報のリストのような構造になっていました。
_long_term_planning(persona, new_day)
new_day 引数が False 以外だった場合("First day" / "New day" など)、
long_term_planning が呼ばれ長めの計画を立てられます。
まずは「起きる時間」を LLM に決めてもらいます。
generate_first_daily_plan(persona, wake_up_hour)
引数が First day だった場合、その日のざっくりとしたスケジュールを LLM に決めてもらいます。
起きる時間は単体で聞き、他のスケジュールはまとめて聞いてるのがちょっと面白いです。
generate_hourly_schedule(persona, wake_up_hour)
その後ざっくりした1日のプランをさらに細かい「時間ごとのスケジュール」に LLM で分解しています。
- 最初に「1 日の大枠」を作り、
- その後で「時間ごとの詳細」を作る
という二段階構成なのが面白いですね。
今なら一発で作ってもらっても良さそうな気もします。
_determine_action(persona, maze)
次に、今のアクションが期限切れの場合、次のアクションを決定します。
流れとしては
- 先ほど決めたスケジュールから「現在時刻に対応するタスク」を取得
- そのタスクを、LLM によってさらに細かいアクションに分解(※睡眠中以外)
といった形で、「1時間の予定」を「数分単位の具体的行動」にしていきます。
アクションが決まったら、続いて
- どこで(場所)
- 誰に対して(対象)
- 吹き出しのアイコン(何をしているかの簡易表現)
といった情報も LLM に決めてもらい、それらを「住人の現在のアクション」としてセットしています。
focused_event = _choose_retrieved(persona, retrieved)
ここまでで
- そのステップでの「自分の行動」はだいたい固まり
- さらに
perceiveの結果を整形したretrievedが手元にある
状態になります。
この retrieved をもとに、どのイベントにフォーカスするか を _choose_retrieved で決めています。
reaction_mode = _should_react(persona, focused_event, personas)
フォーカスするイベントが決まったら、そのイベントに対して どのタイプの反応をするか を LLM に決めてもらいます。
chatwait- 反応しない場合は
False
のいずれかが返ってくるようです。
_chat_react(maze, persona, focused_event, reaction_mode, personas)
reaction_mode が chat の場合、ここで会話の内容を生成します。
- 会話相手との「関係の要約」を LLM に生成させる
- その要約をもとに、発言を LLM に生成させる
- さらに、相手側の視点から見た関係の要約と、その視点からの発言も生成させる
という流れになっていました。
- 毎回その場で関係要約を作り直し、
- 主体ごとに異なる関係要約が存在する
という設計を面白いと感じました。
(「A から見た B」と「B から見た A」が別々に保存されていく)
会話が決まったあと、
- 必要なら移動を行い
- 最後に、今起きたやりとりを踏まえてスケジュールの修正
もしているようでした。
focal_points = generate_focal_points(persona, 3)
今の状態で、
- この人は今、何にフォーカスすべきか?
という 振り返り用の視点(問い)を LLM に生成してもらいます。
thoughts = generate_insights_and_evidence(persona, nodes, 5)
そのうえで、住人の現在の状況から得られる 「気づき」を LLM で生成し、それぞれにスコアを付けて、住人のデータとして保存します。
planning_thought = generate_planning_thought_on_convo(persona, all_utt)
memo_thought = generate_memo_on_convo(persona, all_utt)
会話が終了したタイミングではこの会話から
- 興味を持ったこと
- 覚えておきたいこと
を LLM に生成させ、その結果にもスコア付けをしたうえで保存しています。
react 後ここまで、その反応での変化を生成して保存していたようです。
ここまでが run の中で回っている 1サイクル です。
- 「知覚 > 計画 > 行動の決定 > 反応 > 計画の修正 > 反省 」
というサイクルをループさせて住民の行動をシミュレートしていることがわかりました。
このようなサイクルを行うことで行動の連続性を実現しているんですね。
まとめ
Generative Agents は当時話題になっていたときに「触ってみたいな」と思っていたのですが、なかなか手を出せていなかったプロジェクトでした。今回ようやくちゃんと触ってみてとても楽しかったです。
普段の開発でも AI に触れる機会は多いのですが、「住民」としての AI を扱う今回のケースでは、
- 各エージェントごとに「空間記憶」を持たせる
- 各エージェントごとに「対象人物との関係性の記憶」を持たせる
といった仕組みが新鮮で、とても面白く感じました。
また、最初は「現在の状況をまとめて LLM に渡して、一発で次の行動を決めている」のだと勝手に想像していたのですが、実際には
- サイクルの中で状態を少しずつ更新しながら
- かなり細かく、何度も LLM を呼び出している
という構成になっていて、その設計も非常に興味深かったです。
今回コードを読み込んで自分なりに改善したい点も出てきたのでもうしばらく Generative Agents で遊んでみたいと思います。
読んで頂いた方が少しでも楽しんで頂けたり、興味を持って頂けたら幸いです。
参考
今回実装について調べてみましたが下記の記事が背景や仕組みなどについて詳しいので興味を持った方は読んでみると理解が深まり面白いと思います。