モチベーション
こちらで紹介されていた「Generative Agents: Interactive Simulacra of Human Behavior」という論文を読み、大変興味を持ちました。
AIによって生成された25名のエージェント(ChatGPT: gpt3.5-turbo)が人間の行動をシミュレートして、社会的な行動が創発されたそうです。
この論文での創発の定義は以下でした。
- 情報拡散(Information Diffusion)
- 関係性の記憶(Relationship memory)
- 調整(Coordination)
また、このような創発を起こすためのエージェントの仕組みは、以下あたりでと解釈しました。
- 外部記憶(Memory Stream)
- 計画と状況に応じた対応(Planning and Reacting)
- リフレクション(Reflection)
この論文の自分なりにサマリした一枚絵が以下のものです。
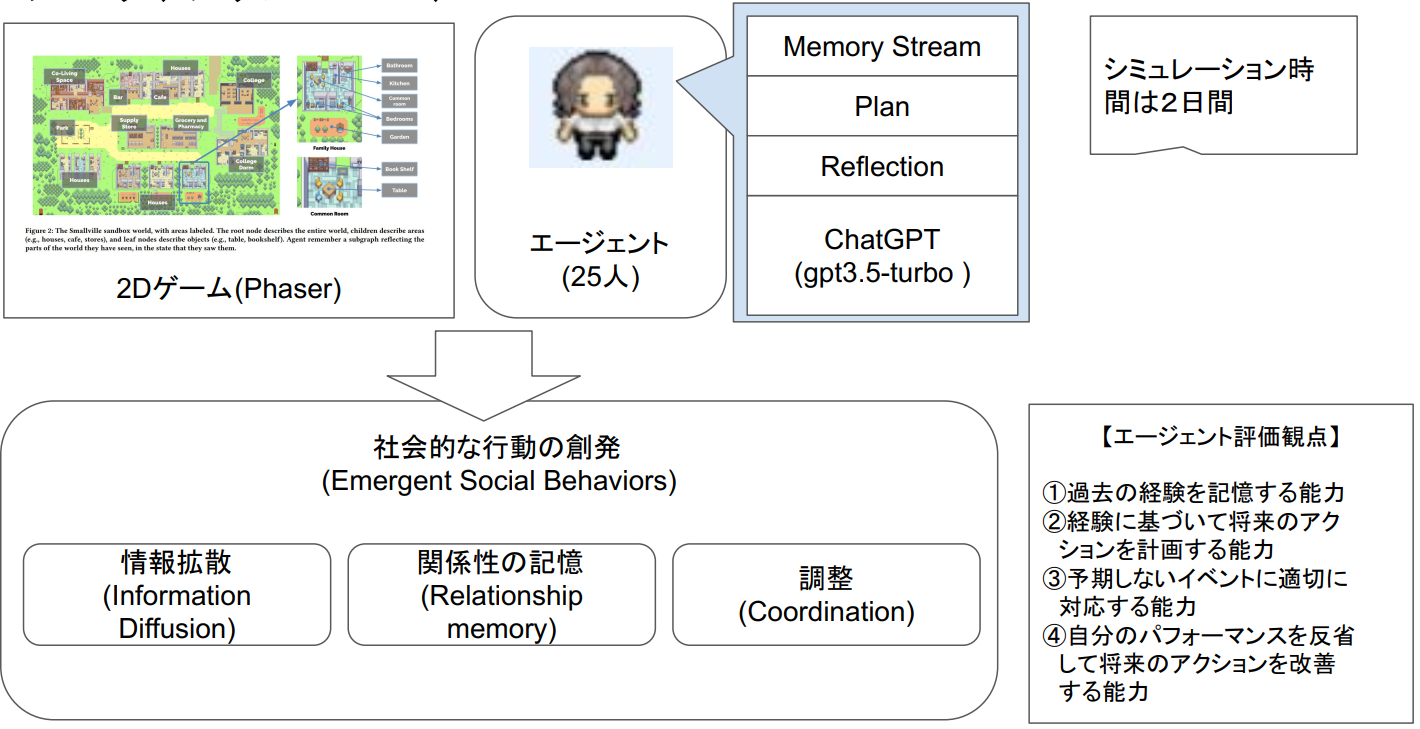
具体的には以下の現象が観測されたそうです。
- information diffusion(情報の拡散)
- サムの市長選への立候補
- 初期:4%(1人)→最後:32%(8人)
- イザベラのパーティ
- 初期:4%(1人)→最後:48%(12人)
- サムの市長選への立候補
- relationship formation(関係の形成)
- ネットワーク密度※各エージェントが約7割の人を知っている
- 初期:0.167→最後:0.74
- ネットワーク密度※各エージェントが約7割の人を知っている
- agent coordination(エージェントの調整)
- イザベラがパーティのイベントを企画
- 調整:
- 他のエージェントにゲスト参加や手助けを依頼
- 結果:
- Hobbsカフェでパーティを開催
- バレンタインデーに、12名の招待に対して5名が参加した
気づき
この論文を読んで、以下の2点が重要な気づきでした。
-
メモリストリームなどのアーキテクチャがエージェントのコンテキスト管理をしており、これがないと人間らしく振舞うことができない
- LLMだけあってもダメ。周辺を固めるプラットフォームが必要。
- (OSだけあっても役に立たないのと同じ)
-
より抽象度の高いレベルの洞察や思考に昇華された記憶がとても重要(Reflection)
- エージェントは、観察や既存のリフレクションに基づいて新たなリフレクションを生成し、それらをメモリストリームに追加する。このプロセスにより、エージェントは異なる状況や経験に対してより一般的な知識や理解を適用できるようになる。
応用
将来的には、TOPPERS/箱庭 に応用したいと考えています。箱庭を利用するエンジニアに AIエージェントを割り当てて、エンジニア間のコミュニケーションギャップを解消させたり、エンジニアのインスピレーションを加速する起爆剤にしたいと思っています。
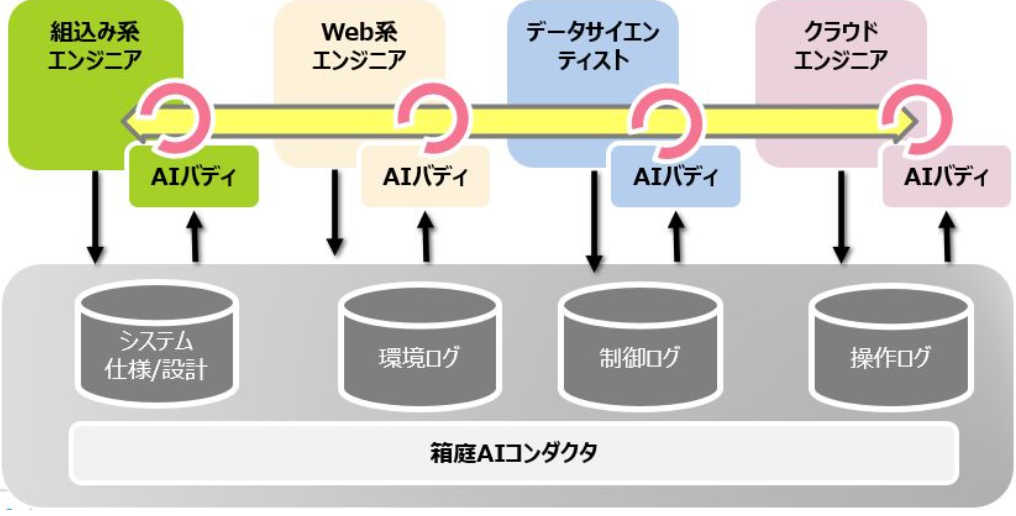
とはいえ、いきなりは難しいので、自分が今やっている仕事の延長上で考えて、沢山あるドキュメントの問い合わせシステムに、この仕組みをうまく活用したいと思い、トライしてみました。
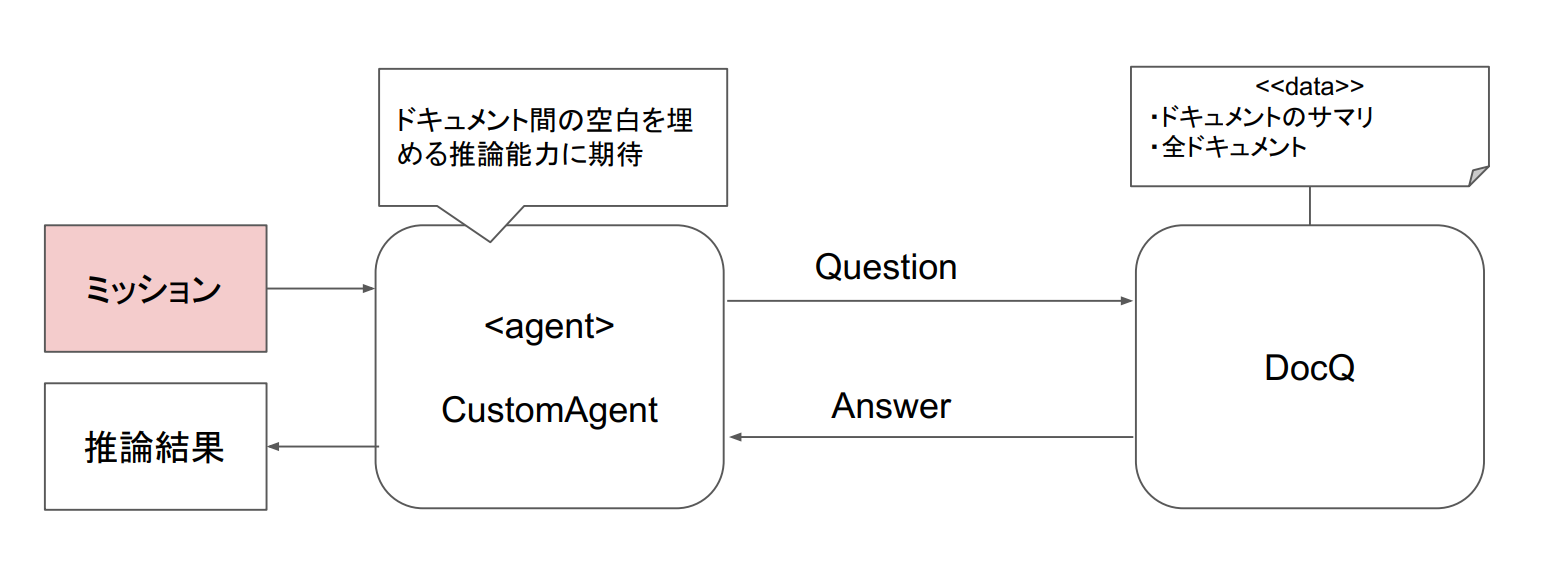
上記は、LangChain のカスタムエージェントを使う場合のアーキテクチャで、簡単にドキュメントの問い合わせシステムを作ることができたのですが、ドキュメントが複数ある場合は、以下の課題がありました。
- 複数のドキュメントを1個にまとめたDBを作成してしまうと、回答が薄まってしまう現象があった(具体的でない回答になってしまう)
- 一方で、ドキュメントを1個ずつDB化してしまうと、ドキュメント選定がうまくいかず、回答がそもそもされない
- そもそも、論文にあるリフレクションとかどうやって組み込めばよいかわからなかった
自作することにした
そういった経緯があり、論文の仕組みを組み込み可能なエージェントを作ってみました。
以下で一般公開しています。
できること
- 既存の複数のドキュメントを入力できます
- 入力したドキュメントに対して、質問することができます
- 質問を色々な角度で推察し、必要なドキュメント読み込んで、回答してくれます
対応しているドキュメントの種類
LangChain は、様々なドキュメントに対応したローダーがありますが、現時点では、以下のドキュメントをローディング出来るようにしています。
- CSV
- PPTX
- URL
- JSON
前提とする環境
- OS: Windows 10/11上の WSL2
- Python3がインストールされていること
- OpenAPI key を利用できること
インストール手順
以下をインストールしてください。
pip3 install openai
pip3 install chromadb
pip3 install tiktoken
pip3 install pypdf
pip3 install langchain
pip3 install unstructured
pip3 install tabulate
pip3 install scikit-learn
pip3 install matplotlib
pip3 install plotly
OpenAPIのAPIキーを環境変数として設定してください。
export OPENAI_API_KEY=<APIキー>
リポジトリをクローンします。
git clone https://github.com/tmori/generative-agents.git
既存ドキュメントを配置
generative-agentsと同じディレクトリ階層上で、documentsディレクトリを作成してください。
mkdir documents
$ ls
documents generative-agents
その後、doucments配下に以下の2つのディレクトリを作成します。
mkdir documents/docs
mkdir documents/dbs
documents/docs配下に、読み込ませたい PDF ファイルを配置してください。
配置例:自分のQiita記事をPDF化したものを置いてみました
ls documents/docs/
'ChatGPTのAPI使って、Unity上の箱庭ロボットを動かしてみた! - Qiita.pdf'
'Mac+Unity+Pythonで箱庭ロボットを強化学習できるようにするための手順書 - Qiita.pdf'
'Python使ってUnity上の箱庭ロボットのカメラデータを取得してみよう - Qiita.pdf'
'Ubuntuでも箱庭で機械学習するやつを動かそう - Qiita.pdf'
'Unity + Python + 箱庭でロボットを強化学習させてみよう! - Qiita.pdf'
'Unity 内の箱庭ロボットを動かすPython API仕様書 - Qiita.pdf'
'Unity+Python+箱庭で自作ドローンを動かしてみる! - Qiita.pdf'
'Windows+Unity+Pythonで箱庭ロボットを強化学習できるようにするための手順書 - Qiita.pdf'
配置完了後、以下のコマンドを実行してください。
bash generative-agents/tools/create_doclist.bash
成功するとこのようなログが出力されます。
DB_DIR =tmp/DB
DOC_DIR=tmp
INFO: Loading document=ChatGPTのAPI使って、Unity上の箱庭ロボットを動かしてみた! - Qiita.pdf
INFO: Storing Vector DB:tmp/DB
:
DB_DIR =tmp/DB
DOC_DIR=tmp
INFO: Loading document=Windows+Unity+Pythonで箱庭ロボットを強化学習できるようにするための手順書 - Qiita.pdf
INFO: Storing Vector DB:tmp/DB
質問用のディレクトリを作成する
cd generative-agents
mkdir query_dir
これで準備完了です。
質問するには
ドキュメントへの質問方法は、以下の通りです。
bash tools/query.bash "<質問内容>"
なお、OpenAPIの応答が遅いので、回答がでるまでに数分かかります..。
難しい質問の場合は耐えれますが、簡単なものなら、ドキュメント個別に質問した方が良いでしょう。
デモ
さっそく、箱庭について質問をしてみましょう。
bash tools/query.bash "Windows版の箱庭上でロボットを強化学習させようとしていますが、シミュレーション開始してもロボットが動きません。手順、ファイアウォール、設定等、考えられる原因を教えてください"
質問:
Windows版の箱庭上でロボットを強化学習させようとしていますが、シミュレーション開始してもロボットが動きません。手順、ファイアウォール、設定等、考えられる原因を教えてください
回答:
Windowsで強化学習とロボットのシミュレーションを行う場合には、いくつかの手順と要件を確認する必要があります。まずUnity、Pythonを正しく準備し、強化学習が可能な状態(Sandbox)を構築します。検証した結果では、Unityのバージョンが異なる場合でも問題ないことが示されています(Unityが適切に変換します)[ReinforcementLearning-RobotSimulation-WindowsUnityPython-SetupGuide-UnityVersionCompatibility]。
なお、Windows Defender FirewallによってUnity Editorがブロックされれば、ロボットは動きません。これを解決するためには、Windows Defender Firewallの設定を変更して、Unity Editorの通信を許可するよう設定する必要があります[ReinforcementLearning-RobotSimulation-WindowsUnityPython-SetupGuide-UnityVersionCompatibility]。
また、シミュレーションの動作自体には、Q-tableを使用した強化学習とロボットのモータ操作(前進、右折、左折)が含まれます[Unity-Python-Robotics-ReinforcementLearning-Implementation]。これを踏まえた上で、現状ではシミュレーションが開始してもロボットが動かない原因を特定するためには、まずは利用しているUnityとPythonのバージョン、そしてFirewallの設定やシミュレーションソフトウェアの設定を再確認することが必要と考えられます。さらに詳しい調査が必要な場合、ロボットの強化学習の具体的なプログラムを確認し、適切に設定・実行されているか確認することも考慮に入れられます。
ちなみに、こちらにトラブルシューティングの情報があって、それを読み込んでくれた結果としての回答だと思います。
Colab 対応
Colab対応しました。
補足情報
このシステムのアーキテクチャは下図の通りです。
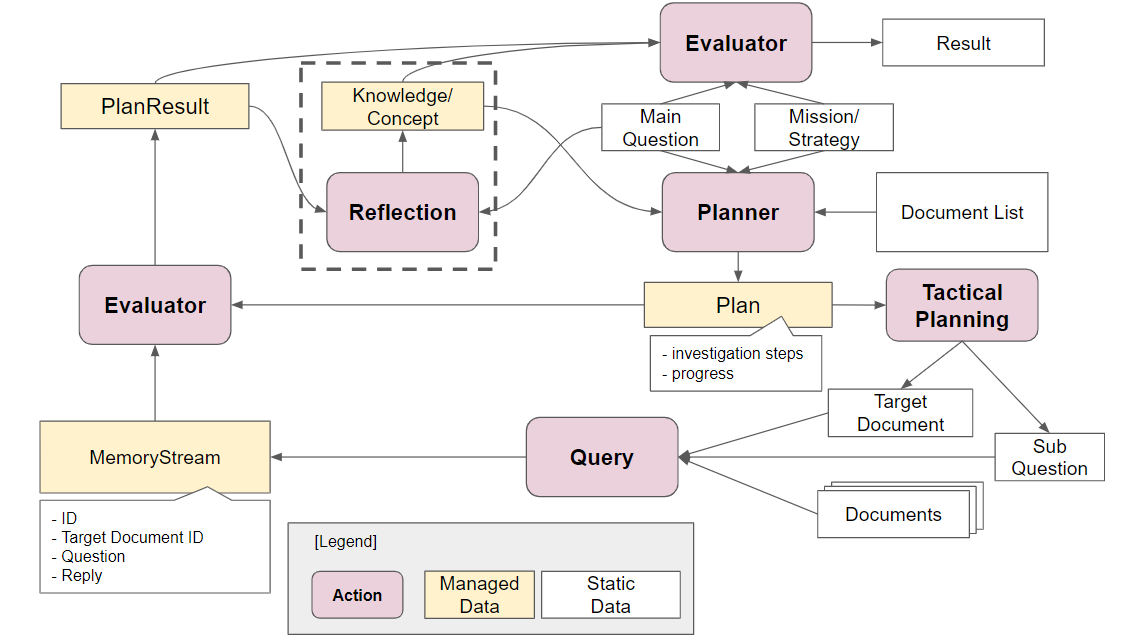
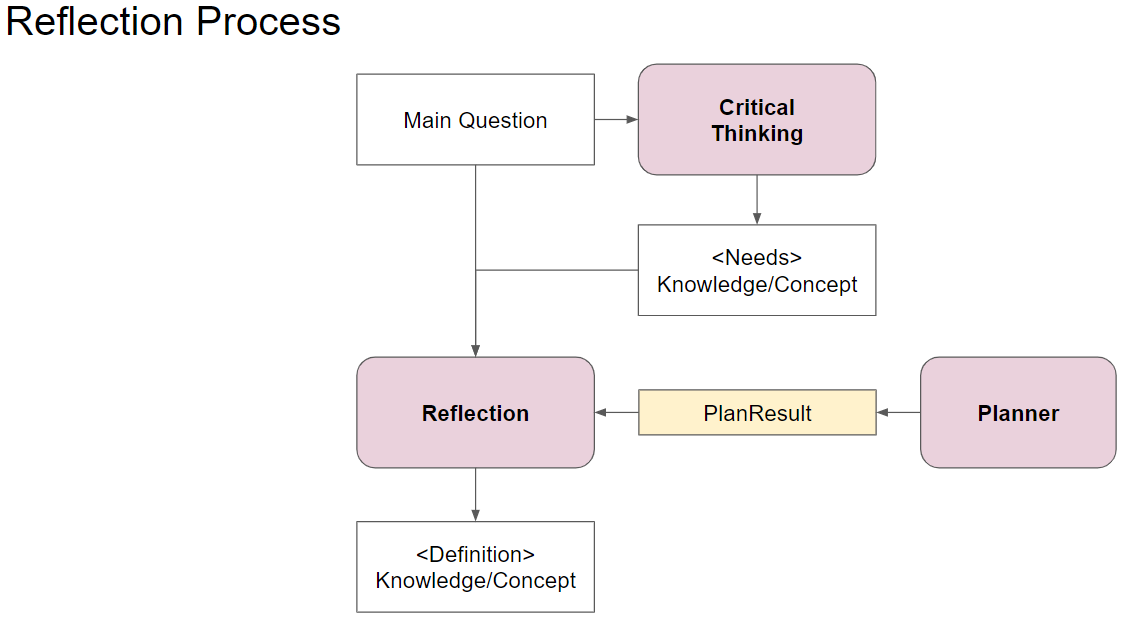
基本的な処理の流れは以下の通りで、現実装では、この処理を2回連続実行することで、リフレクションを洗練させています。
- 質問(MainQuestion)に対して、必要な知識や概念を
Knowledge/Conceptとして列挙します。 - その上で、Mission/StrategyおよびDocumentListを渡して、調査すべきと考えるドキュメントに対して、調査目的/観点を列挙していってもらいます。これをPlan(計画)として解釈しています。
- そして、計画に従って、1個ずつ質問をしていきます。結果は、MemoryStreamに保存され続けます。
- すべての質問が終了したら、PlanとMemoryStreamをマージして、リフレクションします。リフレクション結果として、1 の
Knowledge/Conceptをアップデートしてくれます。 - 最後に、3-4 の結果を Evaluatorに渡して、回答を作ります。