はじめに
AnythingLLMは、コードやインフラストラクチャの煩わしさなしにRAGやAIエージェントなどを実行できる、オールインワンなAIアプリです。ローカルLLMに対応しているため、Ollamaなどを用いてRAGを手軽に試すことができます。
セットアップ
インストール
インストール方法は以下から選べます。
- 公式からDesktop版をダウンロードする
- Docker版 Imageをダウンロードする
- Docker版 Imageをビルドする
Desktop版とDocker版では機能に若干の違いがあります。
今回は3番目の方法を試します。
公式ドキュメントの通りに、以下のコマンドでdocker imageを作成して実行します。
git clone https://github.com/Mintplex-Labs/anything-llm.git
cd anything-llm
touch server/storage/anythingllm.db
cp .env.example .env
docker compose up -d --build
なお、 .env を環境に合わせて変更する必要はありません。後でWebUIから設定できます。
また、 docker-compose.yml に以下の様に追記してOllamaが同時に立ち上がる様にしておくと便利です。
services:
# ... (中略) ...
ollama:
image: ollama/ollama
container_name: ollama
ports:
- 11434:11434
volumes:
- $HOME/.ollama:/root/.ollama
networks:
- anything-llm
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
初期設定
dockerが立ち上がったら、 http://localhost:3001 にアクセスします。
初回は以下の様に表示されるので、Get started から先に進みます。
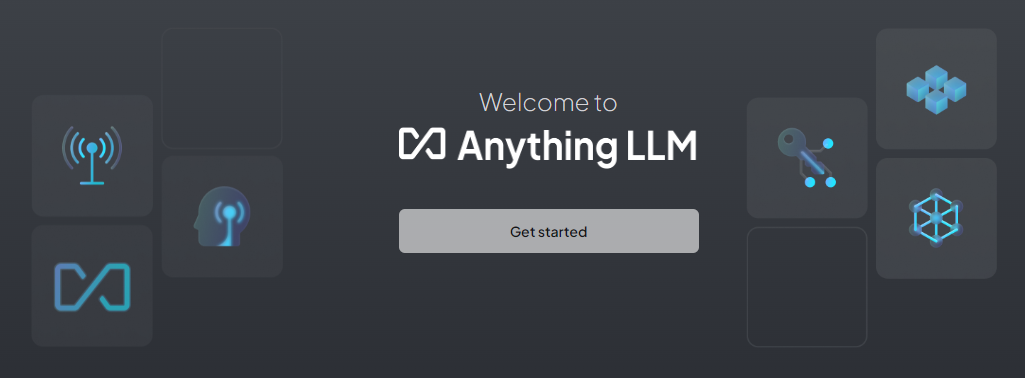
次は、LLMの選択画面です。今回は、Ollamaを使用するので選択して、Ollama Base URLを設定すると、利用可能なモデル一覧がChat Model Selectionに表示されますので、AnythingLLMで使用したいモデルを選択します。また、Token context windowsに値を設定します。
設定ができたら、→ を押して先に進みます。
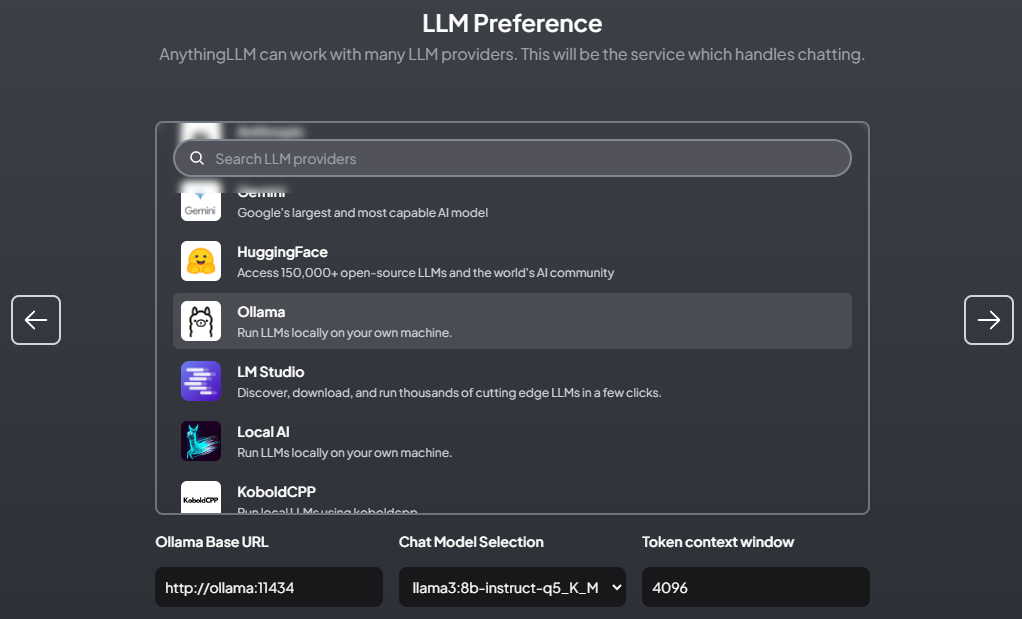
Docker版のAnythingLLMはマルチユーザーやパスワードによる保護に対応しているので、必要な場合は設定します(今回は個人利用のパスワード無し)。
以上で初期設定は完了です。以下の様にLLMとEmbeddingとVectorDBが設定されたことが確認できます。EmbeddingとVectorDBを変更したい場合は、後から設定することになります。
アンケートの様なものがありますが、何も入力しなくても先に進めます。
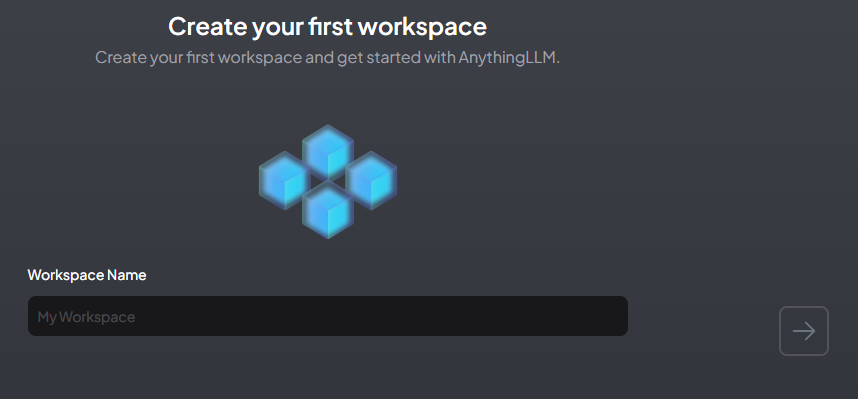
ワークスペースの名前を入力すると、通常画面に進めます。
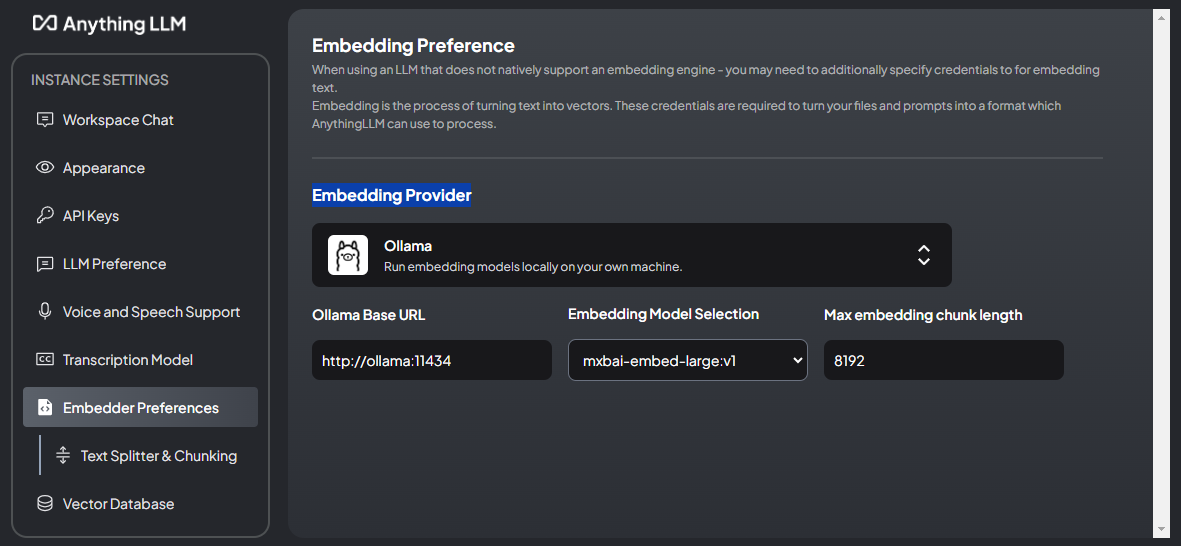
左下の工具アイコンから設定画面に進み、Embeddingのモデルをアプリ埋め込みモデルからOllamaのモデルに変えることもできます。
RAG実行
準備が整ったので、RAGを試してみます。
埋め込み
まず、ドキュメントを追加します。 upload a document や 左側のアイコンからドキュメント管理画面に遷移します。
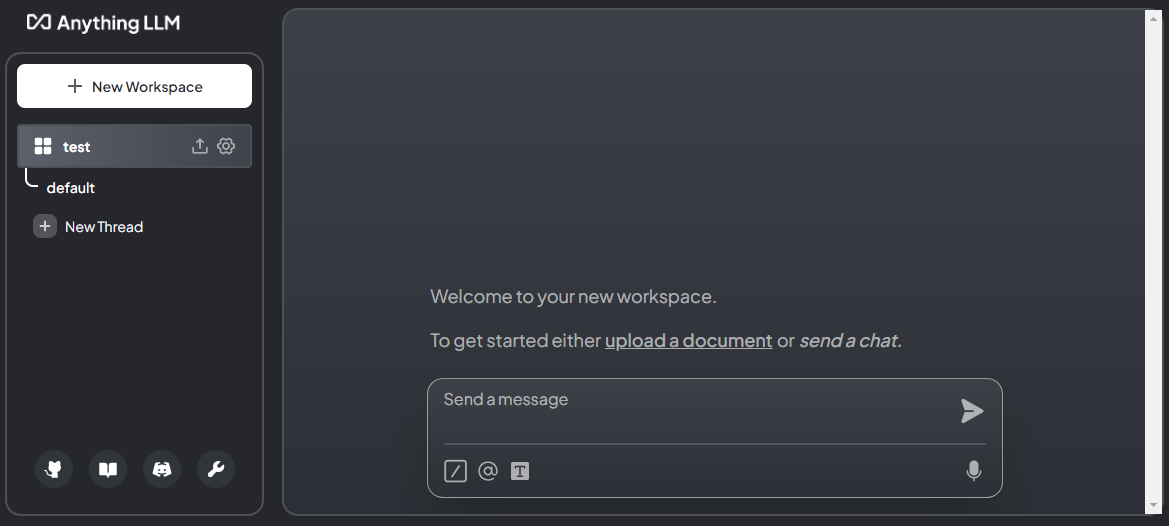
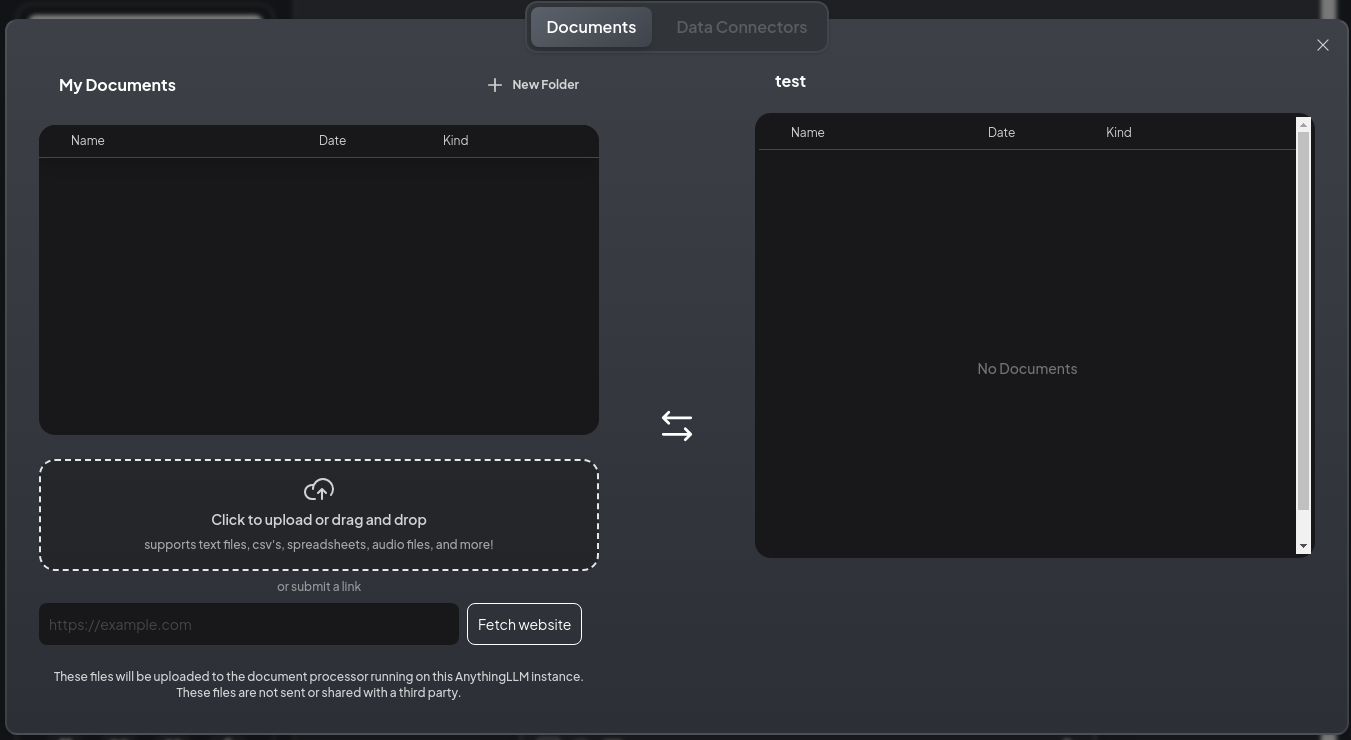
今回は、webから情報を取り込みたいので、 Data Connectors タブに移ります。
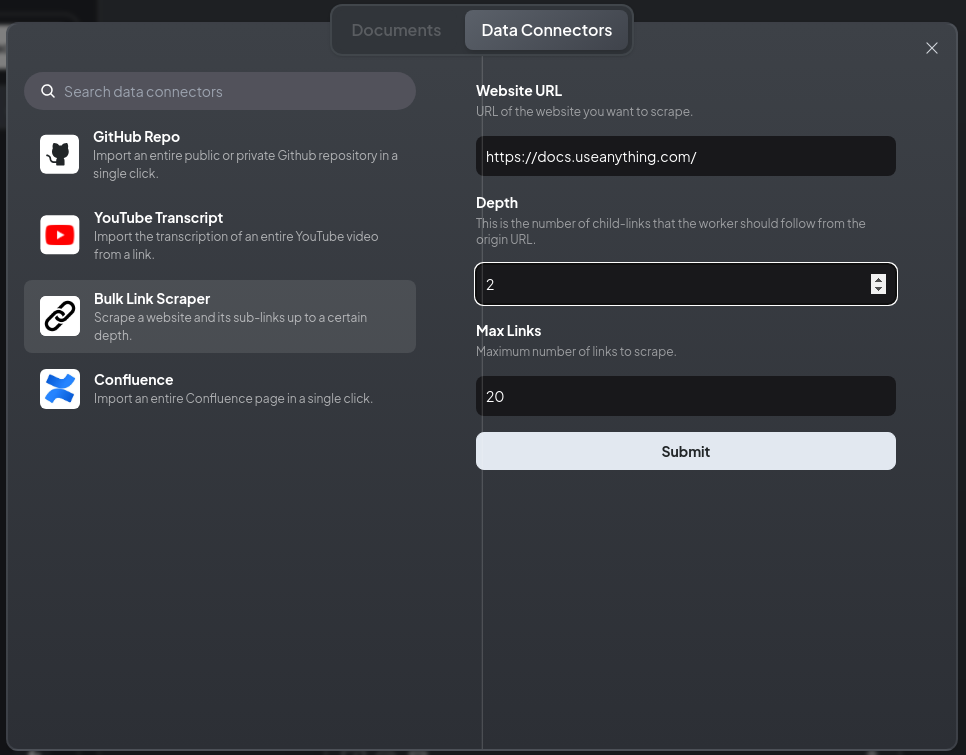
Bulk Link Scraper を選択し、対象のURL (今回は AnythingLLM のドキュメントサイト) などを設定して、Submitを押すと、Webに情報を取りに行ってくれます。
ダウンロードが終わると Documents タブの MyDocuments にファイルが追加されているので、 Move to Workspace を押して、workspaceに追加します。
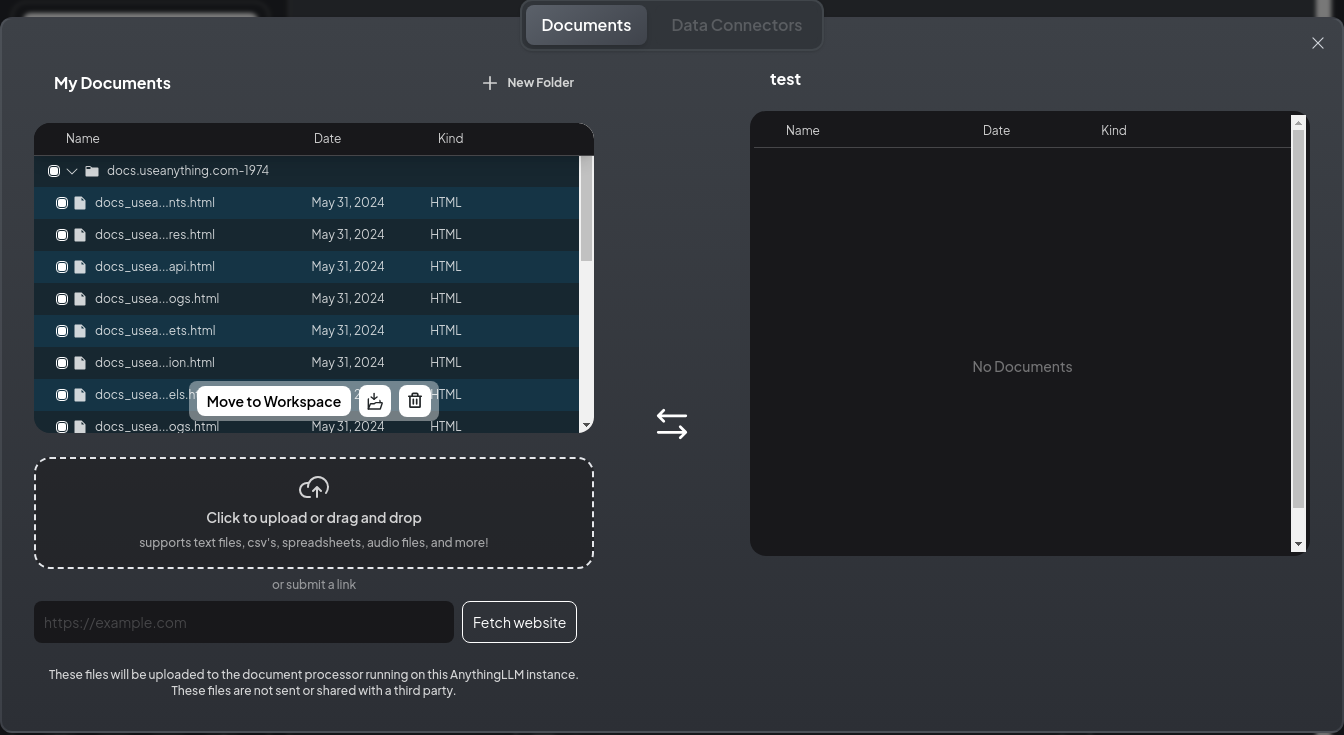
その後、右下の Save and Embed を押すと、情報の埋め込みが行われます。
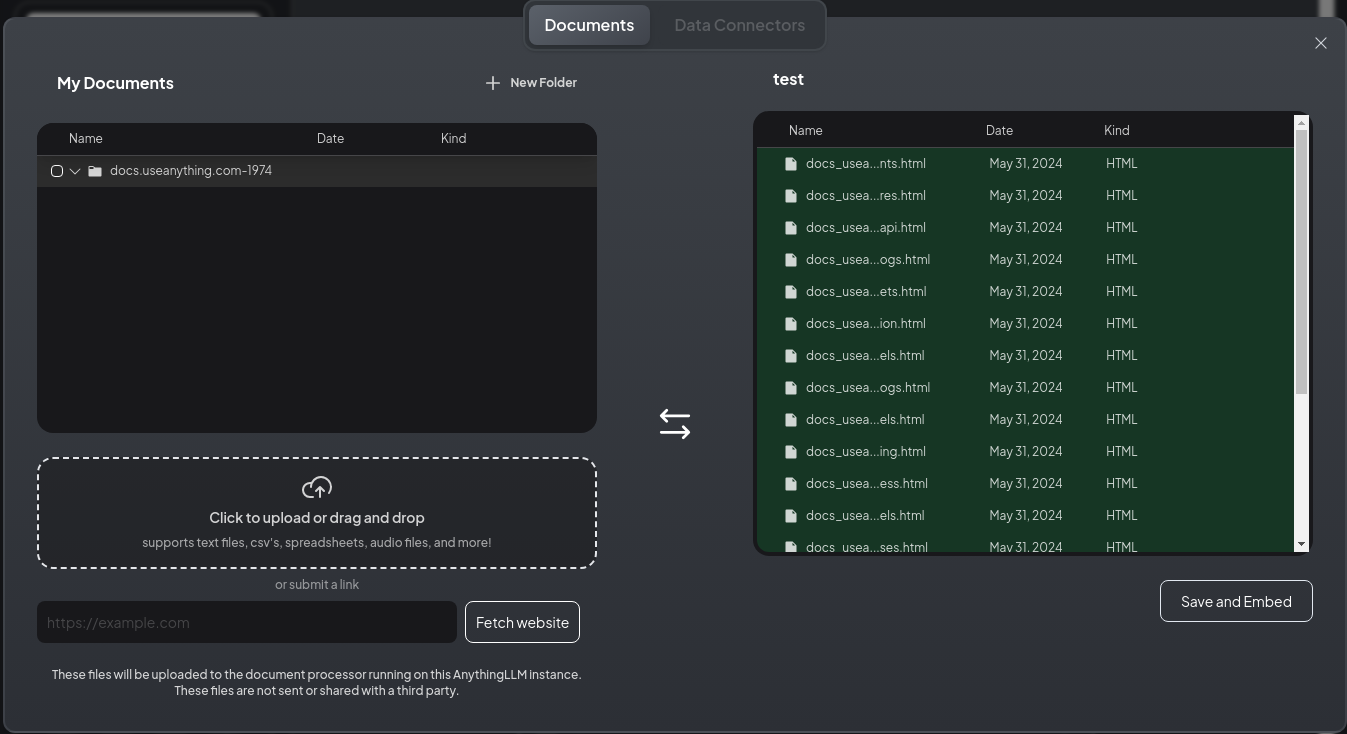
埋め込みが完了すると、以下の様な画面になります。
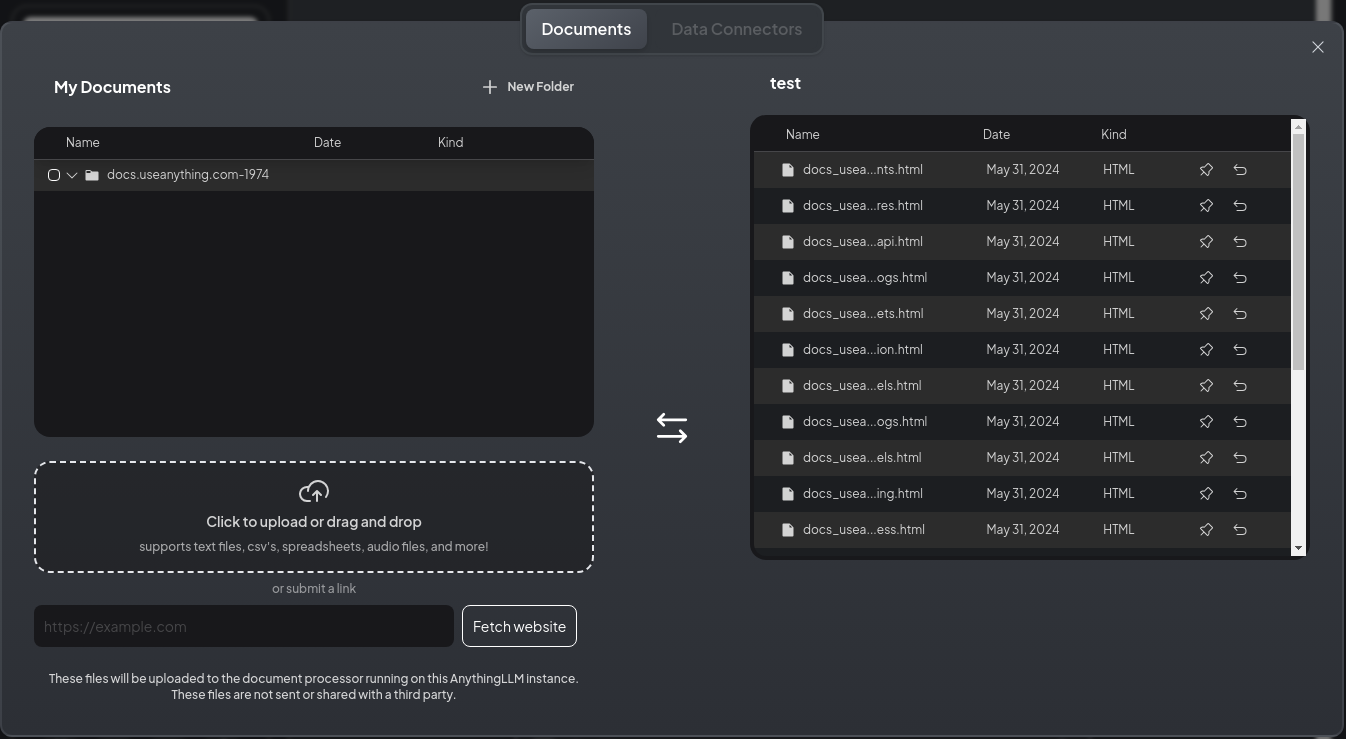
チャット
チャット画面に戻り、「どのモデルプロバイダが(AnythingLLMで)使えるのか」を聞いてみました。
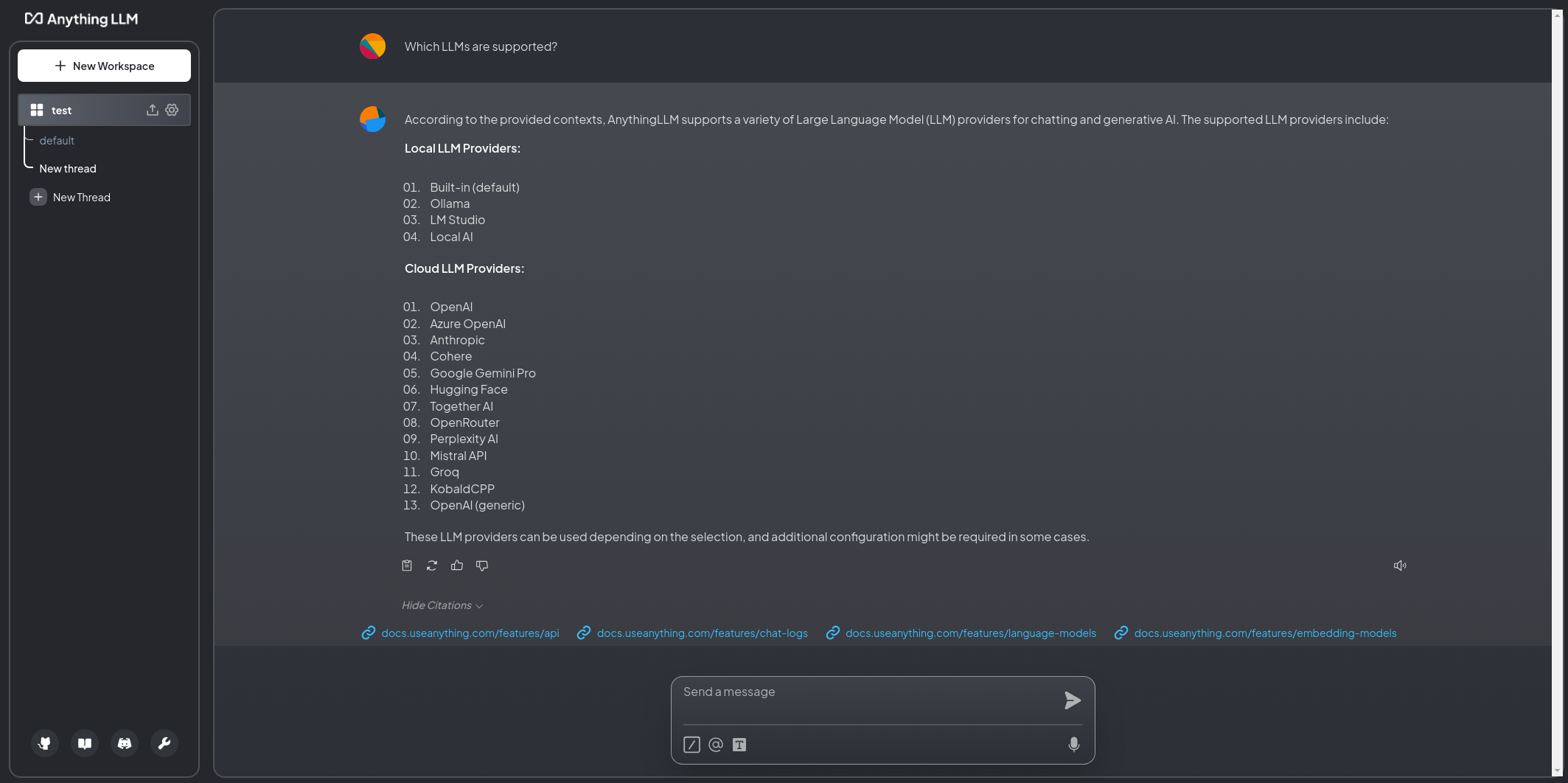
KoboldCPP が Local LLM ではなく Cloud LLM になってしまった以外は正しく答えてくれました。
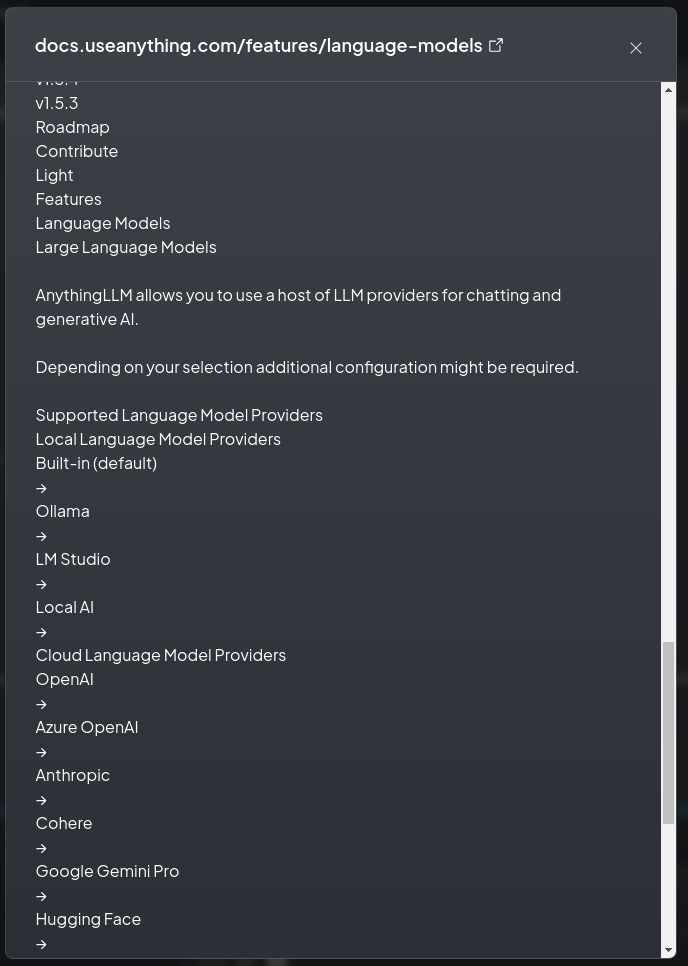
参照したドキュメントも表示されおり、その内容も確認できます。合わせて、元のwebへのリンクも上部にあります。
まとめ
AnythingLLMとOllamaでwebから情報を取得してRAGを実行してみました。一切コードを書かずに利用できるのは便利ですね。ローカルLLMを使うとEmbeddingモデルの用意に悩むこともありますが、最初からアプリに組み込まれているのも楽です (all-minilm-l6-v2 なので日本語は厳しいですが…)。