これから、真面目にDeep Learningの勉強を始めたいと思います。
その前に、学習に必要の大量なデータがどこから入手でするかを考えないといけないです。
思付いた方法の一つはTwitter画像botから画像を収集します。
もう一つはGoogle、Bingなどの画像検索エンジンを利用します。
良いbotを見つけるには時間かかりそうなので、まず検索APIを使ってみます。
Bing検索APIは今年年末に終了するようですから、今回はGoogleを選択します。
検索エンジンの設定
カスタム検索で新し検索エンジンを作成。
設定は以下になります。
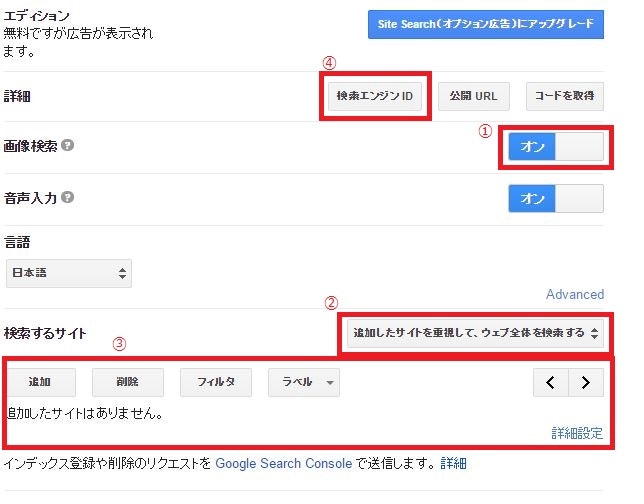
①画像検索をオンにして
②「ウェブ全体を検索する」を選択
③検索サイトを削除
④検索エンジンIDからIDを獲得
IDは「数字列:英字列」の型になっています。
数字列はユーザID、英字列はエンジンIDらしいです。
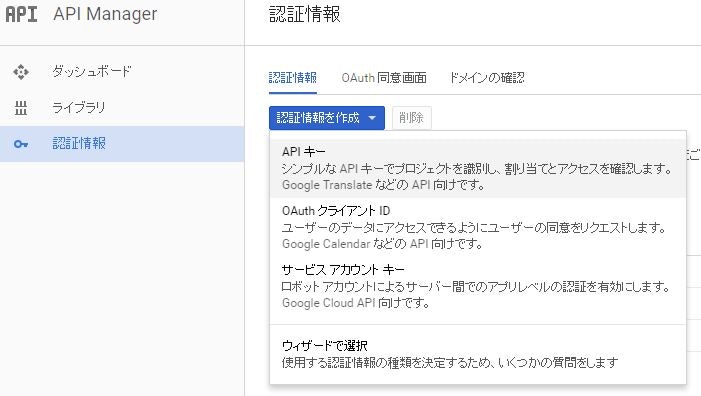
Custom Search APIを獲得
Google Cloud Platform ConsoleでCustom Search APIを有効にして、認証情報でAPIキーを作成します。
Python Scriptの作成
https://www.googleapis.com/customsearch/v1?key=[API_KEY]&cx=[CUSTOM_SEARCH_ENGINE]&q=[search_item]
で検索できます。
画像を検索するため、searchType=imageを追加して、
num=xx&start=yyは大量画像を取得するためのページネーションです。
リファレンスによると、numは1~10の整数になります。
つまり、一回で最大10個を検索できます。
スクリプトはtukiyo3さんのコードを参考しました。
# -*- coding:utf-8 -*-
# onlyzs1023@gmail.com 2016/11/21
import urllib.request
from urllib.parse import quote
import httplib2
import json
import os
API_KEY = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
CUSTOM_SEARCH_ENGINE = "12345648954985648968:xxxxxxxxx"
def getImageUrl(search_item, total_num):
img_list = []
i = 0
while i < total_num:
query_img = "https://www.googleapis.com/customsearch/v1?key=" + API_KEY + "&cx=" + CUSTOM_SEARCH_ENGINE + "&num=" + str(10 if(total_num-i)>10 else (total_num-i)) + "&start=" + str(i+1) + "&q=" + quote(search_item) + "&searchType=image"
print (query_img)
res = urllib.request.urlopen(query_img)
data = json.loads(res.read().decode('utf-8'))
for j in range(len(data["items"])):
img_list.append(data["items"][j]["link"])
i=i+10
return img_list
def getImage(search_item, img_list):
opener = urllib.request.build_opener()
http = httplib2.Http(".cache")
for i in range(len(img_list)):
try:
fn, ext = os.path.splitext(img_list[i])
print(img_list[i])
response, content = http.request(img_list[i])
with open(search_item+str(i)+ext, 'wb') as f:
f.write(content)
except:
print("failed to download images.")
continue
if __name__ == "__main__":
img_list = getImageUrl("犬", 5)
print(img_list)
getImage("dog", img_list)
コードはそんなにきれいじゃないですけど、共有します。
Githubにも入れました。
おわり
Google Custom Search APIは便利だけど、無料使用枠は100リクエスト/日で、スクリプトのテストだけで7割りを使いました。
実際に使うと、お金を払わないといけませんね。
やっぱり、無料で画像を収集したいので、ほかの方法(Twitterとか)で少し工夫してみます。
2016/11/24 更新
いい画像収集の方法を見つかりました!↓
http://d.hatena.ne.jp/shi3z/20160309/1457480722
上記リンク中のpythonスクリプトをpython3対応に修正しました。 → GitHub