エイチーム引越し侍・エイチームコネクト Advent Calendar 2019 、22日目は@hinoraが担当します!2回目!
🖥 デモ
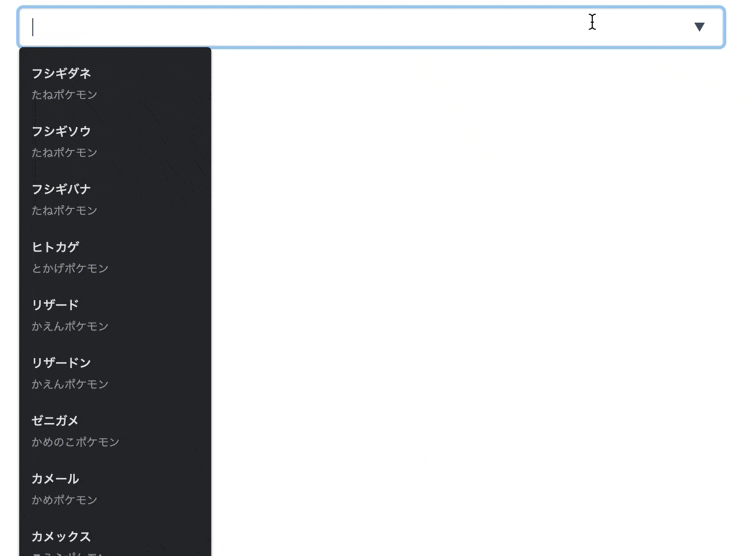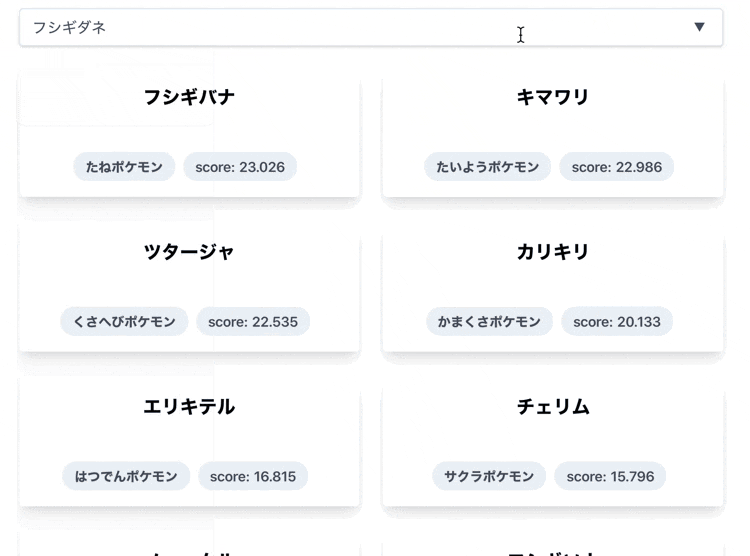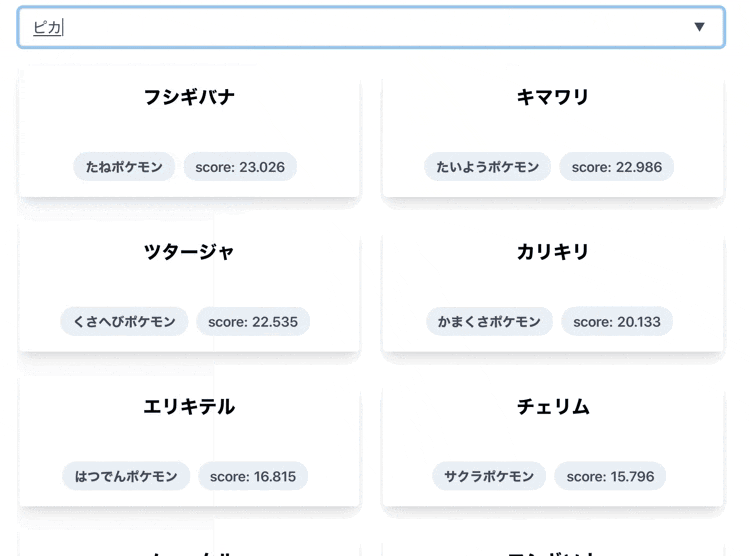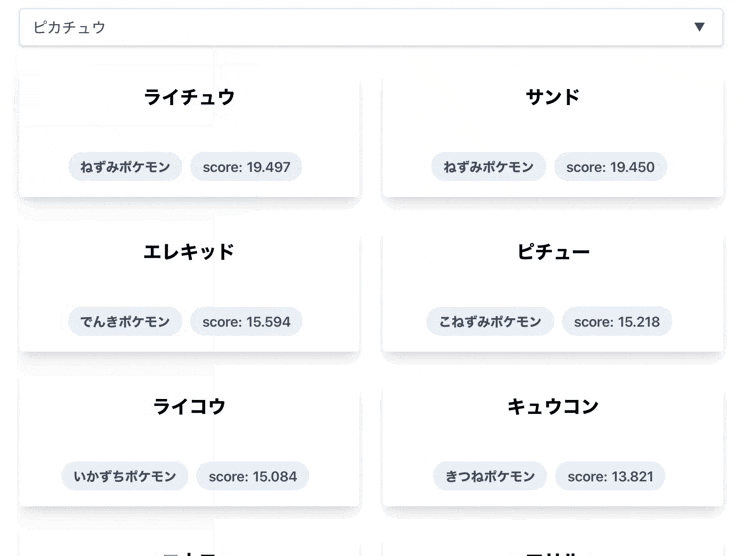
🧐 なにこれ?
名前を入力したポケモンに似ているポケモンを類推して表示します。
デモでは下記のような結果になっています。
| IN | OUT |
|---|---|
| ピカチュウ | ライチュウ, エレキッド, ピチュー |
⚙️ 仕組み
ElasticsearchのMore Like This Queryを利用します。
More Like This Queryを使うと「指定したドキュメントやキーワードから同類のものを抽出」することができます。
レコメンドとしては機械学習などを利用したものに精度は劣りますが、「おすすめの記事」や「おすすめの商品」などをそれなりの精度で手軽に実装したいケースにぴったりです!
✊ 実際にやってみる
1. ElasticsearchとKibana準備
docker-composeで立ち上げます、結構メモリを食うのでお気をつけください。
一緒にkuromojiも入れておきます。
ボリューム用のディレクトリなどはよしなに作ってください。
docker-compose.yml
version: '2'
services:
elasticsearch:
build: elasticsearch
volumes:
- ./docker/es/data:/usr/share/elasticsearch/data
- ./docker/es/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml
ports:
- 9200:9200
environment:
- discovery.type=single-node
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
kibana:
image: docker.elastic.co/kibana/kibana:7.5.1
ports:
- 5601:5601
volumes:
elasticsearch-data:
driver: local
FROM docker.elastic.co/elasticsearch/elasticsearch:7.5.1
RUN elasticsearch-plugin install analysis-kuromoji
2. データの取得と流し込み
今回はポケモンごとの以下のパラメータを利用していきます。
| パラメータ名 | 説明 | 例 |
|---|---|---|
| name | 名前 | オオタチ |
| color | 色 | 茶色 |
| flavorText | 説明文 | ははおやは ほそながい からだでこどもを... |
| eggGroup | タマゴグループ | りくじょう |
| genus | ○○ポケモン | どうながポケモン |
データセットがあればよかったですが、いい感じのものがなかったのでPokeAPIをクローンしてdocker-composeで立ち上げて、APIから持ってきます。
取得する
JSでfetchします。
/** 指定したIDのポケモンの情報を取得する
* - これを800くらいまで取ってきます
* - jsonのArrayをJSON.stringifyしながらjoin("\n")するとあとで使いやすいです
*/
const fetchPokemonById = async id => {
const res = await fetch(`http://localhost/api/v2/pokemon-species/${id}`).then(res => res.json());
const { flavor_text: flavorText } = findByLanguage(res.flavor_text_entries);
const { name } = findByLanguage(res.names);
const { genus } = findByLanguage(res.genera);
return {
id,
name,
flavorText,
genus,
color: res.color.name,
eggGroup: res.egg_groups[0].name,
};
};
整形して流し込む
インポートに対応する形式はJSONとCSVがありますが、今回はJSONで。
JSONと言っても普通のJSONファイルではなく、Newline-delimited JSONと呼ばれるものです。
この形式はその名の通り、改行で区切られた複数のJSONから構成されています。
{"id":1,"name":"フシギダネ","flavorText":"~~~~~~~","genus":"たねポケモン","color":"green","eggGroup":"plant"}
{"id":2,"name":"フシギソウ","flavorText":"~~~~~~~","genus":"たねポケモン","color":"green","eggGroup":"plant"}
// ...
KibanaのMachine Learning -> Data Visualizer -> Import dataへ移動して、先ほど作ったJSONファイルをインポートします。
ファイルを選択してImportを押すと、Indexをどうするかと聞かれるのでpokemonというindexを作成します。
これで準備は完了です!
3. 類推するクエリを投げる
試しに「フシギソウ」に似たポケモンを取得してみます。
先にKibanaのDiscoverなどで、ドキュメントのIDを控えておきます。
ドキュメントのIDをコピーしたら、KibanaのDev ToolsからMore Like This Queryを投げてみます。
類推するクエリ
fieldsに比較するパラメータ名を、likeで類推元を指定します。
GET pokemon/_search
{
"_source": "name",
"query": {
"more_like_this": {
"fields": [
"name",
"flavorText",
"color",
"eggGroup",
"genus"
],
"like": [
{
"_id": "Th1ALW8BEmAvY9Q5hJWt" // フシギソウのドキュメントID
}
]
,
"min_term_freq": 1,
"max_query_terms": 12
}
}
}
結果
{
// ~ 省略 ~
"hits" : [
{
"_index" : "pokemon",
"_type" : "_doc",
"_id" : "UB1ALW8BEmAvY9Q5hJWt",
"_score" : 23.025995,
"_source" : {
"name" : "フシギバナ"
}
},
{
"_index" : "pokemon",
"_type" : "_doc",
"_id" : "DR1ALW8BEmAvY9Q5hJa0",
"_score" : 22.985844,
"_source" : {
"name" : "キマワリ"
}
},
// ...
これで「ポケモンを類推する検索エンジン」の完成です!
Webサービスなどで使う場合は好きなクライアントからリクエストして表示すればOKです。
ちなみに業務ではRailsのChewyというGemを使ってやっています。
とっても使いやすいのでオススメ!
おまけ:ビュー側
今回はフロントから直接叩く実装にしましたが、公式クライアントがあったので思ったより簡単でした。
const es = require('elasticsearch');
const client = new es.Client({
host: 'localhost:9200',
});
// 全てのドキュメントを取得するクエリを投げる
function fetchAll() {
return client.search({
index: 'pokemon',
body: {
size: 50,
query: { match_all: {} },
},
});
}
完成品

サンドとピカチュウは同じねずみポケモンだから、こねずみポケモンのピチューよりスコアが高くなっちゃってますね笑
タイプを比較パラメータ対象に入れておけば、より高精度だったかもしれません!
まとめ
レコメンデーションと聞くと難しい印象がありますが、More Like This Queryを利用すればとっても簡単に実装できます。
また、より精度をあげるためのチューニングもmax_query_termsなどのパラメータを変更する事で一定可能です。
ぜひやってみてくださいね!
明日は@halktさんです!お楽しみに〜!